在现实生活中,很多场景都需要ID生成器,比如说电商平台的订单号生成、银行的叫号系统等。针对不用的业务需求,ID生成策略也不一样,比如电商平台的订单号可以由时间序列组成,银行的叫号系统则是自然数自增序列。对于自增序列的ID生成器,在多并发环境下,为保证严格的自增,常常可以通过锁来保证。

设想一下,如果我们想在应用层面自己实现一个自增序列的ID生成器(其实本质上我们需要实现的是一个getNextValue方法),怎么做?对很多人来说,可能首先想到的是直接用i++这样语法层面的语句,但是必须要对方法加锁才行,因为i++不是一个原子操作。还有另外一个办法,就是利用java的AtomicInteger类,AtomicInteger的实现不是基于锁,而是基于CAS(Compare and Swap),在某些场景下,效率要比加锁的方式高,参考(漫画:什么是 CAS 机制?)。
上面介绍的语言层面的支持更多的是一些理论层面的东西,常常适用于单机系统,如果要应用到实际的软件系统中,还需要考虑很多其他方面,比如说自增序列的持久化、分布式系统中如何生成自增序列。
在分布式系统中,如何实现ID生成器,有很多办法,有兴趣的童鞋可以自行网上搜索。下面主要分析JPA的ID生成器是如何依赖于数据库的锁实现的。
其实很多分布式场景下的需求和功能,都还是依赖于数据库的基本功能来实现,之前写的一篇文章(liquibase和flyway中分布式锁实现的区别?)就介绍了在flyway中如何利用数据库的排他锁实现分布式锁。然而,大量依赖数据库也可能导致数据库成为一个单点性能瓶颈,这时候往往就需要考虑一些方案来减轻这个瓶颈,比如说分库分表(现在流行的微服务架构就是一个High-level的分库分表的实践)。
JPA的@GeneratedValue和@TableGenerator两个Annotation可以直接用来生成自增序列,并且会把当前的序列存在数据库中,JPA现在流行的两个provider(eclipselink和hibernate)在实现上,有异曲同工之处,都是依赖的数据库的排他锁。
那么eclipselink是如何实现的呢?就像上面提到的,本质上就是实现了一个getNextValue方法,只是这里加的锁是数据的排他锁,而不是语言层面的锁,如下图所示。
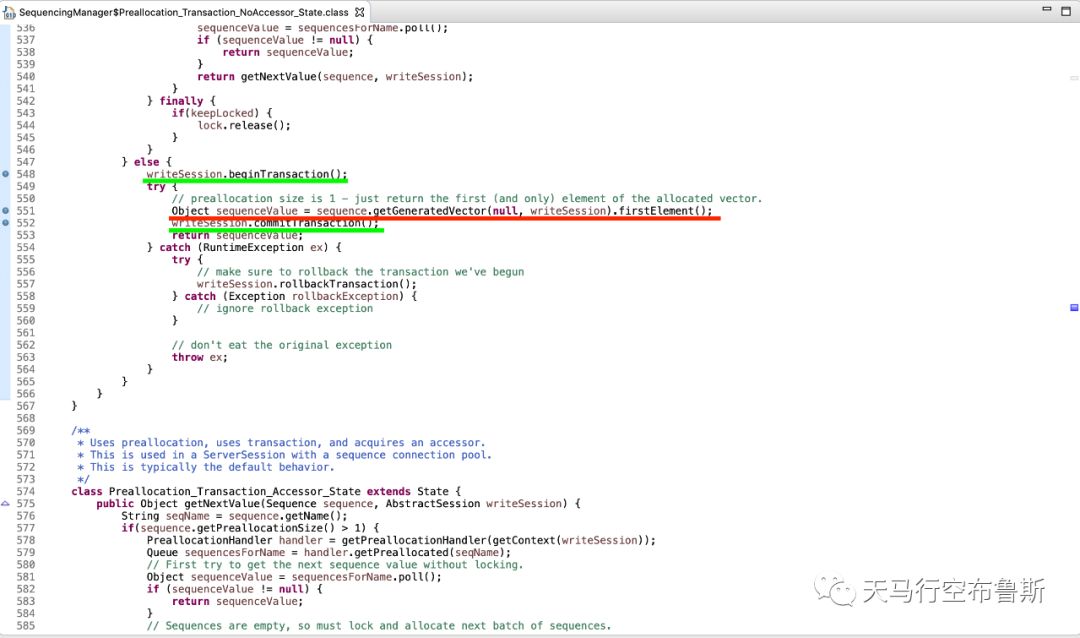
这里数据库排他锁工作的基本原理是:在一个事务中,当update一条记录时,会在当前记录上加一个排他锁(或者整个表上),只有事务结束(commit或者rollback)之后,才会释放这个锁;这时其他阻塞的事务就继续执行。参考如下代码:
Connection c = null;try {Class.forName(“org.postgresql.Driver”);c = DriverManager.getConnection(“jdbc:postgresql://localhost:5432/postgres”,”postgres”, “postgres”);} catch (Exception e) {e.printStackTrace();System.err.println(e.getClass().getName()+”: “+e.getMessage());System.exit(0);}c.setAutoCommit(false);String sql1 = “update sequence set seq_count = 35 where id_generation_category=’t1′”;PreparedStatement preparedStatement1 = c.prepareStatement(sql1);preparedStatement1.executeUpdate();String sql2 = “select * from sequence where id_generation_category=’t1′”;ResultSet rs = preparedStatement2.executeQuery();while(rs.next()) {int seq_count = rs.getInt(“seq_count”);System.out.println(“seq_count: ” + seq_count);}try{c.commit();}catch (SQLException e){c.rollback();} finally {preparedStatement1.close();preparedStatement2.close();c.close();}
Hibernate的实现类似,具体可以参考文章(https://dzone.com/articles/hibernate-identity-sequence),可以看到Hibernate采用的是select for update语句显示加排他锁的方式,和前面写的一篇文章(liquibase和flyway中分布式锁实现的区别?)flyway加锁的方式一样。
上面提到,实现自增序列也可以不用加锁,java语言层面提供的AtomicInteger类就是采用不加锁的方法,而是采用的CAS(Compare and Swap)。那么在分布式环境下,ID生成器是不是也可以采用CAS呢?这篇文章(浅谈CAS在分布式ID生成方案上的应用 | 架构师之路)就简单介绍了如何采用CAS实现分布式ID生成器。
延伸
References
https://vladmihalcea.com/why-you-should-never-use-the-table-identifier-generator-with-jpa-and-hibernate/
https://javarevisited.blogspot.com/2013/03/reentrantlock-example-in-java-synchronized-difference-vs-lock.html
欢迎关注公众号与作者交流