今天在训练模型的时候突然报了显存不够的问题,然后分析了一下,找到了解决的办法,这里记录一下,方便以后查阅。
注
:以下的解决方案是在
模型测试
而不是模型训练时出现这个报错的!
RuntimeError: CUDA out of memory
完整的报错信息:
Traceback (most recent call last):
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 420, in <module>
main()
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 414, in main
train_with_cross_validate(training_epochs, kfolds, train_indices, eval_indices, X_train, Y_train, model, losser, optimizer)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/main.py", line 77, in train_with_cross_validate
val_probs = model(inputs)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 235, in forward
x = self.camlp_mixer(x) # (batch_size, F, C, L)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/container.py", line 139, in forward
input = module(input)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 202, in forward
x = self.time_mixing_unit(x)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 186, in forward
x = self.mixing_unit(x)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/LiangXiaohan/MI_Same_limb/Joint_Motion_Decoding/SelfAten_Mixer/model/S_CAMLP_Net.py", line 147, in forward
x = self.activate(x)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/modules/activation.py", line 772, in forward
return F.leaky_relu(input, self.negative_slope, self.inplace)
File "/home/pytorch/anaconda3/envs/pytorch_env/lib/python3.7/site-packages/torch/nn/functional.py", line 1633, in leaky_relu
result = torch._C._nn.leaky_relu(input, negative_slope)
RuntimeError: CUDA out of memory. Tried to allocate 2.49 GiB (GPU 0; 23.70 GiB total capacity; 21.49 GiB already allocated; 550.81 MiB free; 21.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
因为自己写的程序训练完成一轮会有输出,所以这些信息是在模型预测过程中发生的
。
关键的报错信息:
RuntimeError: CUDA out of memory. Tried to allocate 2.49 GiB (GPU 0; 23.70 GiB total capacity; 21.49 GiB already allocated; 550.81 MiB free; 21.53 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
大体意思就是
显存不够
了。
通过下面的代码查看程序运行过程中显卡的状态:
nvidia-smi -l 1
模型加载完成后,此时的显卡状态:

模型训练过程中显卡的状态:

模型训练完成,开始模型预测阶段,并且是数据输入模型之后,紧接着出现如下的显卡状态,并且这个状态持续时间很短,在显示过程中,只有一次输出结果是这样的:

紧接着程序报错,显卡内存被释放,显卡的任务栏中,运行的程序也没有了:

然后,就感觉很奇怪,觉得是梯度的问题,因为在训练的时候很正常,然后模型预测就出现问题了,然后模型训练需要梯度信息,模型预测不需要梯度信息,就尝试着解决梯度的问题:
就是在模型训练代码的前面加入下面这句话:
with torch.no_grad():
更改后的代码如下所示:
with torch.no_grad():
# validation
model.eval()
inputs = x_eval.to(device)
val_probs = model(inputs)
val_acc = (val_probs.argmax(dim=1) == y_eval.to(device)).float().mean()
# print(f"Eval : Epoch : {iter} - kfold : {kfold+1} - acc: {val_acc:.4f}\n")
epoch_val_acc += val_acc
更改之后模型预测阶段显卡的状态如下所示:
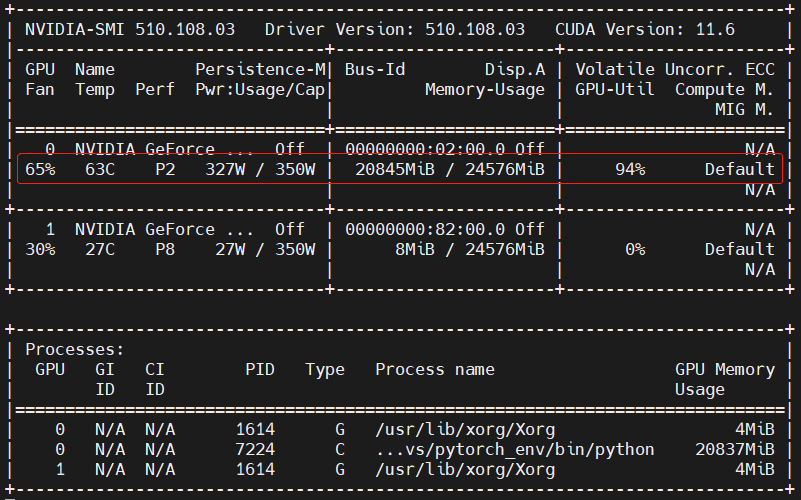
然后开始新一轮的训练过程,显卡的显存占用情况也没有再发生变化。
这样就不再报错了!!!