01 窗口函数的应用场景
在讲什么是窗口函数之前,先来举几个在写SQL时,经常遇到的一些场景。
【场景1】现在数据库中有一张用户交易表order,其中有userid(用户ID)、amount(消费金额)、paytime(支付时间),请写出对应的SQL语句,查出每个用户第一单的消费金额。
【场景2】数据库中有一张销售业绩表,其中有销售员id,部门名称,销售金额。要取出每个部门销售金额Top10的员工,作为优秀员工。
其实本质上,场景1和场景2的内容是一样。
如果是查询每个用户最大金额、最小金额,对于熟悉SQL的同学,应该比较清晰,直接group by就行。但这里多了一个条件,按照金额的时间取第一单、或者按照销售取top10,即不再是全局排序、统计。你该咋办呢?
对,解决这种SQL取数的问题,就需要用到窗口函数。
02 基础概念
什么是窗口函数呢?
窗口函数,也叫OLAP(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理,一般和分析函数搭配使用以达到数据处理的目的。
其实可以将窗口函数理解成,将整体表按照某个字段拆分成多个小表,然后在小表中求排序、聚合、取值等相关操作的函数。
【关键词】over , partition by
窗口函数的语法结构如下:
window_function (expression) OVER ([ PARTITION BY part_list ][ ORDER BY order_list ]
-
PARTITION BY 表示将数据先按 part_list 进行分区
-
ORDER BY 表示将各个分区内的数据按 order_list 进行排序
传统的聚合、排序等函数都是基于全局整表的,窗口函数可以基于表中的每个细分部分。窗口函数在select子句的执行顺序中,仅在order by之前 。没事,没理解的话,下面会详细举几个例子。
03 应用示例
窗口函数主要有以下几类,其中排序函数应该是最常用到的。
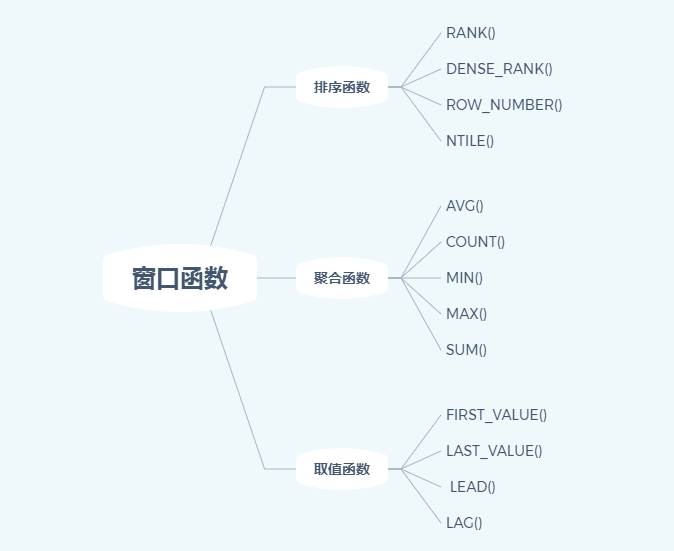
(1)排序函数
几个不同排序函数的一些差异,可以根据不同的业务场景选择合适的函数:
-
RANK(): 生成数据项在分组中的排名,排名相等会在名次中留下空位。比如会出现1、2、2、4、4、6、7
-
ROW_NUMBER(): 从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列。结果只会是1、2、3、4、5、6、7
-
DENSE_RANK(): 生成数据项在分组中的排名,排名相等会在名次中不会留下空位,比如会出现1、2、2、3、3、4、5这种
举例,给流量表按照用户的访问时间加上每个用户的访问次序:
SELECTuserid,createtime,pv,rank() over(partition BY userid order by pv DESC) AS rn1,dense_rank() over(partition BY userid order by pv DESC) AS rn2,row_number() over(partition BY userid order by pv DESC) AS rn3FROM tb_visit;
举例,取各二级类目下sku的订单金额总和前10的数据
select *,row_number() over(partition by cate2_name order by amount desc) rank_secdfrom tbnamewhere rank_secd<=10
(2)聚合函数
有以下示例:
SELECT *,sum(col2) over (partition by col1 order by col2) as current_sum,avg(col2) over (partition by col1 order by col2) as current_avg,count(col2) over (partition by col1 order by col2) as current_count,max(col2) over (partition by col1 order by col2) as current_max,min(col2) over (partition by col1 order bycol2) as current_minFROM tbname;
(3)取值函数
-
FIRST_VALUE():取分组内排序后,截止到当前行,第一个值
-
LAST_VALUE():取分组内排序后,截止到当前行,最后一个值
-
LAG():LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
-
LEAD():与LAG相反 LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
取值函数主要是用于错位进行计算,这里就不详细举例了。
over(order by salary rows between 5 preceding and 5 following):窗口范围为当前行前后各移动5行。
stddev (a.jjl) over (partition by business_new order by pt rows between 7 preceding and current row)
(a.jjl-avg(a.jjl) over (partition by business_new order by pt rows between 7 preceding and current row))
# 按照 year 分组,按照 month 排序,计算前3行和后1行的总和
sum(val) over(partition by year order by month rows between 3 preceding and 1 following)
• preceding:往前
• following:往后
• current row:当前行
• unbounded:起点
• unbounded preceding:表示从前面的起点
• unbounded following:表示到后面的终点
Hive Sql的窗口函数
1. count、sum、avg、max、min#
以 sum 为例
# 按照 year 来分组,统计每一年的总和 # 结果:每个月的值都是本年的总和 sum(val) over(partition by year)
# 按照 year 来分组,按照 month 来排序 # 结果:n 月的值是本年 1 – n 月的累计值 sum(val) over(partition by year order by month)
通过 explain select … 来查看语句解析,可以简单理解为,在每一次 order by 之后,会执行一次 sum 的 reduce 过程,也就导致结果计算的是 1 – n 月的累计值
2. rows between#
以 sum 为例
# 按照 year 分组,按照 month 排序,计算前3行和后1行的总和 sum(val) over(partition by year order by month rows between 3 preceding and 1 following)
• preceding:往前
• following:往后
• current row:当前行
• unbounded:起点
○ unbounded preceding:表示从前面的起点
○ unbounded following:表示到后面的终点
# 以下两种方式是等效的 sum(val) over(partition by year) sum(val) over(partition by year rows between unbounded preceding and unbounded following)
# 以下两种方式是等效的 sum(val) over(partition by year order by month) sum(val) over(partition by year order by month rows between unbounded preceding and current row)
# 以下两种方式不等效 sum(val) over(partition by year rows between unbounded preceding and current row) sum(val) over(partition by year order by month rows between unbounded preceding and current row) # current row 应该是和 order by 同时出现,要不然会导致数据错位
3. ntile#
切片:用于将分组数据按照顺序切分成n片,返回当前切片值;不支持 rows between;如果切片不均匀,默认增加第一个切片的分布(比如有6条数据,分4组,数量依次为2 2 1 1)
# 统计一个月内,val 最多的前 1/n ntile(n) over(partition by month order by val desc) as rn rn = 1 就是最终想要的结果,前提是数据可以被均匀分片
4. row_number、rank、dense_rank#
• row_number:行号
• rank:排名——结果中可能有空位 eg:1 2 2 4
• dense_rank:排名——结果中无空位 eg:1 2 2 3
5. cume_dist#
计算公式:(小于等于当前值的行数 / 分组内的总行数)
# 统计小于等于当前薪水的人占部门内总人数的比例 cume_dist() over(partition by dept order by salary)
6. percent_rank#
计算公式:(分组内当前行的rank值 – 1 / 分组内总行数 – 1)
7. lag(col, n, DEFAULT)#
统计窗口内往上第 n 行值
三个参数分别是:列名;往上第 n 行(可选,默认是1);当往上第 n 行为 NULL 的时候,取默认值,如不指定,则为 NULL
8. lead(col, n, DEFAULT)#
统计窗口内往下第 n 行值
三个参数分别是:列名;往下第 n 行(可选,默认是1);当往下第 n 行为 NULL 的时候,取默认值,如不指定,则为 NULL
9. first_value(col)#
取分组内排序后,取第一个的 col
first_value(col) over(partition by … order by …)
10. last_value(col)#
取分组内排序后,截止到当前行,最后一个的 col => 相当于分组排序后,取当前这一行的 col
last_value(col) over(partition by … order by …)
如果不指定 order by,则默认按照记录在文件中的偏移量进行排序,会出现错误的结果
如果要取分组内排序后最后一个 col,可以换成下面的形式
first_value(col) over(partition by … order by … desc)
11. grouping sets#
在一个 group by 查询中,根据不同的维度组合进行聚合,等价于将不同维度的 group by 结果集进行 union all
select year, month, count(1)a, grouping__id from … group by year, month grouping sets(year, month, (year, month)) order by grouping__id
等价于
select year, ‘null’ as month, count(1)a, 1 as grouping__id from … group by year, month union all select ‘null’ as year, month, count(1)a, 2 as grouping__id from … group by month union all select year, month, count(1)a, 3 as grouping__id from … group by year, month
grouping sets (col1, col2 …) 使用前必须要先写 group by (col1, col2 …), grouping sets 表示在 group by 括号内出现的字段组合的情况,所以 grouping sets 出现的字段肯定是在 group by 中出现过的
grouping__id 表示结果属于哪一个分组集合,只能和 grouping sets 组合着用,单独使用报错。有两个下划线!!!
12. cube#
根据 group by 的维度的所有组合进行聚合。
select year, month, count(1)a, grouping__id from … group by year, month with cube order by grouping__id
等价于以下四种情况 union all 1. 相当于直接 count(1)a 2. 按照 year 来分组 3. 按照 month 来分组 4. 按照 year&month 来分组
13. rollup#
是 cube 的子集,以最左侧的维度为主,从该维度进行层级聚合。
select year, month, count(1)a, grouping__id from … group by year, month with rollup order by grouping__id
等价于先进行 with cube操作,即以下四种情况 union all 1. 相当于直接 count(1)a 2. 按照 year 来分组 3. 按照 month 来分组 4. 按照 year&month 来分组
然后 year 是最左侧的维度,则按照 year 来进行层级聚合,过滤掉 year 为 NULL 的记录(但是第1中情况对所有数据进行count(1)的这一条数据会依旧保存)