声明:
本次文章内容以本人公司技术分享的PPT为基础。
若需要PPT内容,欢迎联系。
前言
在进行一致性哈希介绍前,先思考2个问题:
-
什么是Hash
-
一致性Hash和Hash的关系是什么
对于第一个问题Hash的定义
Hash也成散列,基本原理就是把任意长度的输入,通过hash算法变成固定长度的输出。
对于第二个问题,下面我们进行详细介绍。
引出问题
在了解一致性哈希算法之前,最好先了解一下缓存中的一个应用场景,了解了这个应用场景之后,再来理解一致性哈希算法,就容易多了,也更能体现出一致性哈希算法的优点,那么,我们先来描述一下这个经典的分布式缓存的应用场景。
场景描述

对于3万张图片的处理,第一种随机存储,可以满足我们的要求吗?可以。但是如果这样做,当我们需要访问某个缓存项时,则需要遍历3台缓存服务器,从3万个缓存项中找到我们需要访问的缓存,遍历的过程效率太低,时间太长,当我们找到需要访问的缓存项时,时长可能是不能被接受的,也就失去了缓存的意义。
那么就是第二种方式,进行Hash取模算法。

![]()
似乎,Hash取模算法可以满足我们的使用场景了,但是,上面还是会出现一些缺陷的,试想一下,如果3台缓存服务器已经不能满足我们的缓存需求,需要对服务器进行扩容,假设,我们增加了一台缓存服务器,那么缓存服务器数量由3台变为4台。此时,如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,被除数不变的情况下,余数肯定不同,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变,换句话说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据。数据库减少时,场景同理。

正式上述所述问题,由于大量缓存在同一时间失效,造成了缓存的雪崩,此时前端缓存已经无法起到承担部分压力的作用,后端服务器将会承受巨大的压力,整个系统很有可能被压垮,所以,我们应该想办法不让这种情况发生,但是由于上述HASH算法本身的缘故,使用取模法进行缓存时,这种情况是无法避免的,为了解决这些问题,一致性哈希算法诞生了。
我们来回顾一下Hash算法会出现的问题。
问题1:当缓存服务器数量发生变化时,会引起缓存的雪崩,可能会引起整体系统压力过大而崩溃(大量缓存同一时间失效)。
问题2:当缓存服务器数量发生变化时,几乎所有缓存的位置都会发生改变,怎样才能尽量减少受影响的缓存呢?
其实,上面两个问题是一个问题,那么,一致性哈希算法能够解决上述问题吗?
我们现在就来了解一下一致性哈希算法
一致性哈希算法的基本概念




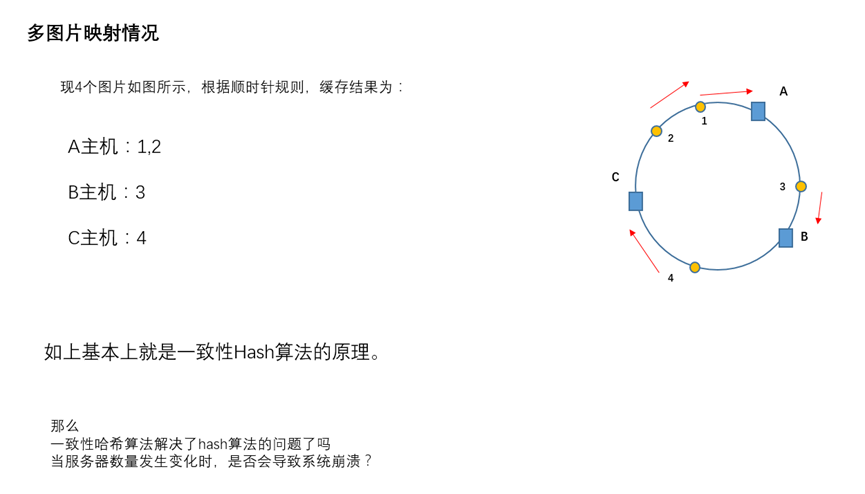
一致性哈希算法的优点
经过上述描述,大家应该已经明白了一致性哈希算法的原理了,但是话说回来,一致性哈希算法能够解决之前出现的问题吗,我们说过,如果简单的对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存的雪崩,从而很有可能导致系统崩溃,那么使用一致性哈希算法,能够避免这个问题吗?我们来模拟一遍,即可得到答案。

如上优点所述,这就是一致性哈希算法的优点,如果使用之前的hash算法,服务器数量发生改变时,所有服务器的所有缓存在同一时间失效了,而使用一致性哈希算法时,服务器的数量如果发生改变,并不是所有缓存都会失效,而是只有部分缓存会失效,前端的缓存仍然能分担整个系统的压力,而不至于所有压力都在同一时间集中到后端服务器上。
hash环的偏斜
上述内容,我们理想化的将3台服务器均匀映射到hash环上了,但是,我们想象的与实际情况往往不一样。很有可能大部分集中缓存到某一台服务器上,我们称这种现象为数据倾斜:

虚拟节点
所谓虚拟节点就是凭空的让服务器节点多起来,既然没有多余的真正的物理服务器节点,我们就只能将现有的物理节点通过虚拟的方法复制出来,这些由实际节点虚拟复制而来的节点被称为”虚拟节点”。加入虚拟节点以后的hash环如下。

以上为一致性哈希算法的原理。
以上为全部内容。
欢迎关注10W+的微信公众号:

技术难点欢迎咨询,如有需要加我微信:1106915848。
星光不问赶路人,时光不负有心人