http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/www.telesens.co
本文参考上文,做了部分翻译和自己的理解,欢迎交流讨论!
使用RCNN进行目标检测和分类
经典的RCNN系列(主要是RCNN,Fast-RCNN,Faster-RCNN,Mask-RCNN),是two-stage的经典目标检测模型。本文希望从细节上把这些模型了解清楚(Mask-RCNN的不在本文中介绍,因为Mask-RCNN主要用于分割任务,其在Faster-RCNN的基础上做了改进)
本文主要介绍Pytorch版本的Faster-RCNN,代码见
https://github.com/ruotianluo/pytorch-faster-rcnngithub.com
文章内容如下:
- 图像预处理
- 网络结构
-
实现细节:训练
- 锚框生成层
- 区域推荐层
- 推荐层
- 锚框目标层
- 计算分类层损失
- 推荐目标层
- 裁剪池化
- 分类层
- 实现细节:推理
-
附录
- Resnet-50网络架构
- 非极大抑制(NMS)
图像预处理
训练和推理过程的预处理方法不是一样的,需要注意这一点!
具体而言就是归一化的均值和方法分别是所有训练集和测试集数据的均值
和方差。
网络架构
一个RCNN神经网络主要解决如下两个问题:
- 从输入图像中获取感兴趣区域(Region of Interest – RoI)
- 识别RoI中目标类别,主要以计算概率的方法得到
RCNN包含三个子模块:
- Head。也称为backbone,即骨干网络。
- Region Proposal Network – RPN。RoI推荐网络,一是推荐可能存在目标的bbox,二是初步纠正anchor的坐标
- 分类网络。对于Faster-RCNN,有两个分支,一是分类,二是bbox回归,纠正锚框坐标。对于Mask-RCNN,有三个分支,在Faster-RCNN的基础上增加了与FPN类似的反卷积网络。
对于Head,一般是在ImageNe数据集上预训练好的CNN模型。由于预训练模型的浅层主要是基于边缘和颜色来作为特点,泛化能力较好。预训练模型的深层主要与特定任务相关,泛化能力较差。因此浅层的参数在训练的过程中保持相对稳定不变,可以设置较低的学习率,而深层的参数在训练的过程中需要针对数据集做较大修改,可以设置较高的学习率。
对于RPN,接收来自Head的输入图像特征,送入有CNN和MLP组成的RPN,生成推荐框RoI(来源于锚框,并初步实现了框坐标纠正)。然后根据推荐框对应到特征图上的位置,裁剪特征图(Crop Pooling,在Mask-RCNN中使用RoI Align代替了RoI pooling),得到输出结果,送入分类网络。
对于分类网络,对每个RoI进行分类和框坐标回归(二次框坐标修正)。
在原文
https://github.com/ruotianluo/pytorch-faster-rcnngithub.com
中提到了网络初始化的问题,这里我多写几种方法:
- Xavier初始化;
- He初始化;
-
BN层的
初始化为零(主要是针对带有skip-connection的模块,因为这样网络的前向和后向传播,在刚开始训练的时候均经过skip-connnection,一般认为这么做可以提高训练效率)。(参见论文bag of tricks …… from 李沐)
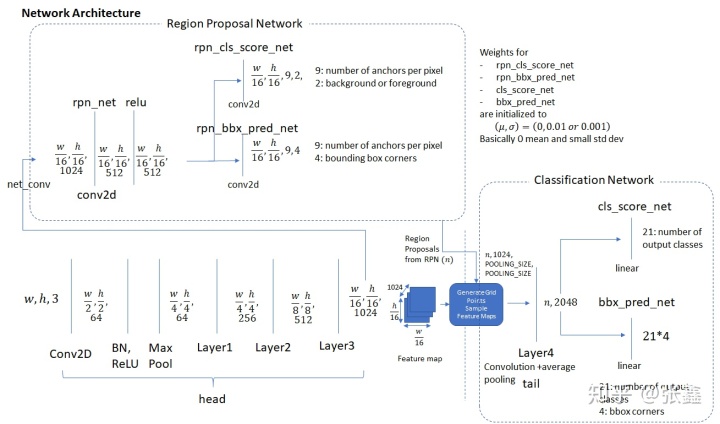
上图把Head,RPN和分类网络描述在一张图中。其中
和
表示经过预处理过后的输入图像的宽度和高度。
对于head,输入
分别表示输入图像的宽度、高度和通道数(3表示输入图像为RGB彩色图像),输入图像经过Conv2D降采样后变为
(64个宽度为
,高度为
的特征图),经过类似操作,head的输出为
(1024个宽度为
,高度为
的特征图),这个就是输入图像的特征图,有两个作用,一是输入到RPN中,另外一个根据RPN的推荐框来裁剪对应位置的特征图,作为分类网络的输入。
对于分类网络(Classification Network),接收裁剪好的特征图,进行Pooling,变为统一长宽的特征图(对于Faster-RCNN,为RoI Pooling,对于Mask-RCNN,为RoI Align),然后送到两个分支。一个分支为分类网络,另一个分支为边界框回归网络。
实现细节:训练
简要介绍完网络结构之后,我们详细介绍下head, RPN和分类网络的细节。
从网络架构可知,训练主要是要重新训练分类网络、RPN和微调head(可以考虑分开设置学习率)。
要训练,首先要得到标签。对于目标检测而言,标签就是一个输入图像中的目标框的位置坐标和目标框中的目标类别。对于VOC和COCO数据,一般以Json格式的文件存储,可以使用python的Json包来处理。对于COCO,还提供了pycocotools这样的库(真是方便呀,但是要学习一下这个库的使用方法)。数据集介绍下:
-
PASCAL VOC:VOC2007包含9963张图像(包括训练验证测试),带有24640个目标,目标种类为20类。种类为:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor

- COCO(Common object in Context): COCO数据集要大于VOC2007,包含操作200k的标签图像,类别又90类。
在原文https://github.com/ruotianluo/pytorch-faster-rcnn中提到使用VOC2007做训练,如果计算资源有限的情况下,是一个选择。
下面重点来了,先看看两个麻烦一点的概念。
- Bounding Box Regression Coefficients
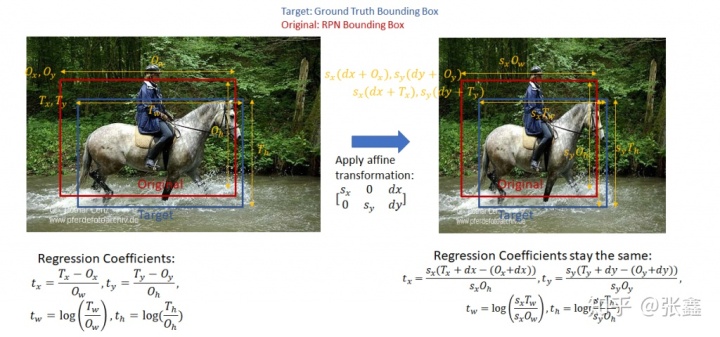
这里的图片看的不是很清楚。我们直接描述,令
分别表示ground truth的左上角坐标和原始的左上角坐标,令
分别ground truth的宽度高度和原始的宽度高度。那么回归系数为:
,
,
,
这里使用回归系数,而不是直接回归坐标,是为了防止回归误差太大,导致回归框超出图像框的范围。另外回归系数不会受到仿射变换的影响。在原文中提到了使用回归系数在计算分类损失的时候具有优点,但是我在这里理解的不是很透彻,在讲述分类损失的时候可以感受到使用回归系数的优势。
- Intersection over Union (IOU) Overlap
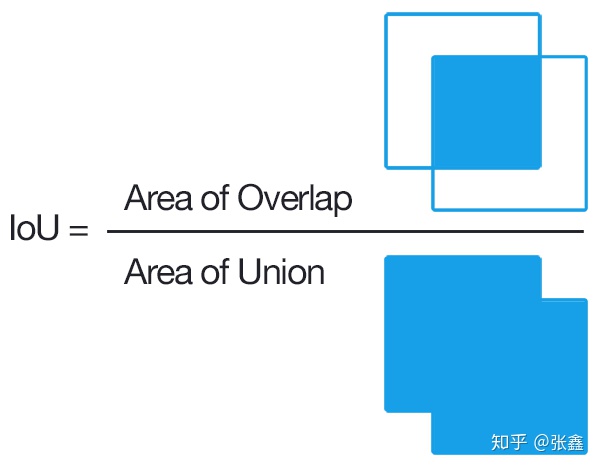
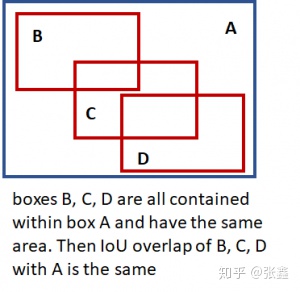
用交并比(IoU)来表示两个框的重叠程度,主要用在候选框的挑选上。
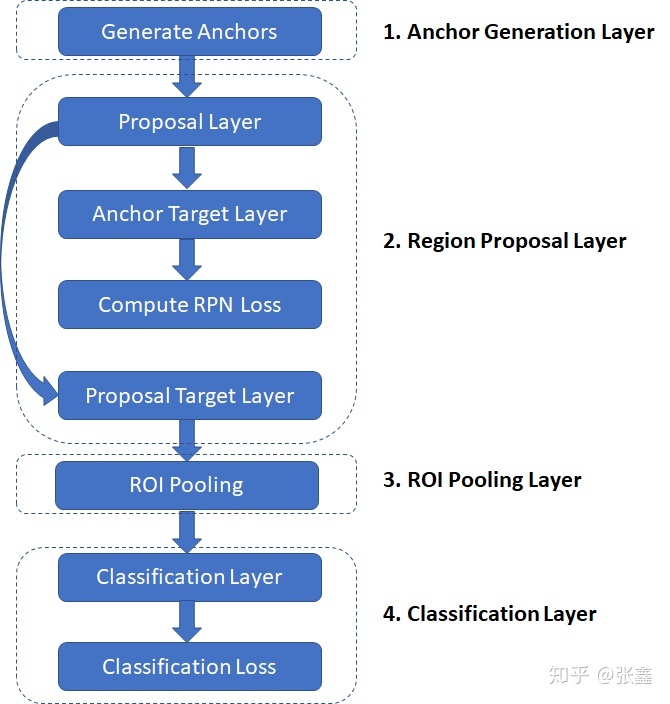
上图是训练过程中需要执行的步骤。
-
Anchor Generation Layer,锚框生成层:这个层会根据预先设定的基尺寸、尺寸比例、尺寸缩放来生成锚框。因此这个框是固定大小的,在实际使用中一般尺寸比例为基尺寸为
,长宽比例为
,尺寸缩放比例为[8, 16, 32]。 - Proposal Layer, 候选层:根据bbox系数修正锚框的坐标。根据锚框中的目标类型概率,和NMS算法来减少锚框数量(去掉IoU低于给定阈值的锚框)。
- Anchor Target Layer, 锚框目标层:生成用于训练RPN的锚框以及对应的前景/背景标签和框系数。该层的作用仅仅用来训练RPN,并不会输出到分类网络中。
- RPN Loss,RPN损失:该损失用来训练RPN网络,包括候选框的前景背景分类损失和框坐标回归损失。
- Proposal Target Layer,候选目标层:该层是为了降低候选层输出的候选框的数量,并且生成供分类网络训练用的标签(包括框类别和坐标)。
- ROI Pooling Layer, ROI池化层:实现一个空间变换网络,该网络对候选框进行池化,使得不同大小的候选框可以得到相同尺寸的输出。然后送到分类器分支和框回归分支。
- 分类损失:与RPN损失类似,用来训练分类网络。在梯度反向传播过程中,误差也会流过RPN网络,进而会调整RPN网络的参数。分类网络包括:目标分类损失和框回归损失。
Anchor Generation Layer
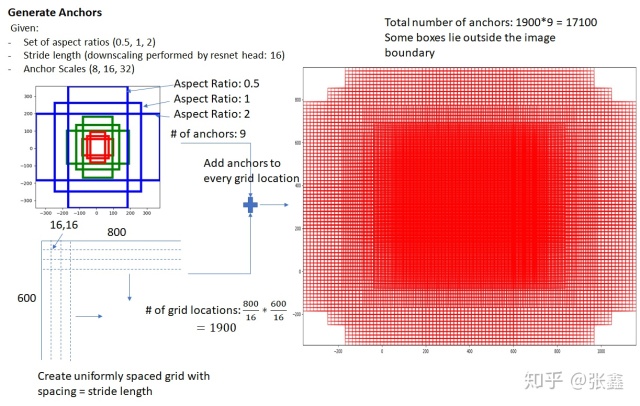
锚框就是根据基尺寸、锚框长宽比例、锚框尺寸缩放比例来生成候选框,如上图所示,会生成9个候选框。由此可知,这些候选框对所有的图片都是一样的。这些锚框几乎包含了图片中的所有目标,但是大多数锚框都是空的。RPN网络的目标就是寻找有可能存在目标的锚框,并对锚框的坐标进行修正。
Region Proposal Layer
目标检测方法中需要的区域推荐系统,稀疏方法有selective search,密集方法有deformable part models。对于Faster RCNN和Mask RCNN而言,RPL根据锚框生成方法得到大量的密集锚框,并根据锚框包含目标的概率进行打分,以及进行锚框坐标的校正。主要做两件事情:
- 从一系列锚框中,识别出包含前景框的锚框和背景框的锚框
- 修正锚框的中心位置、长度和宽度。这里是通过锚框坐标修正因子来实现的。
区域推荐层包含三个层:
- proposal layer 候选层
- anchor target layer 框目标层
- proposal target layer 候选目标层
RPN
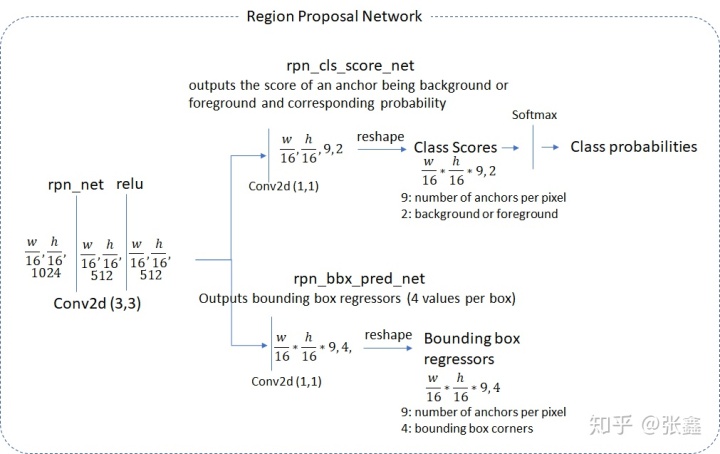
head部分将图片卷积处理后,分别经过1×1卷积到两个支路。一条支路为前景背景分类层,另一条支路为框回归层。由图可知,特征图的尺寸为
,特征图的每个点会生成9个候选框,因此候选框个数为
。于是前景背景二分类网络的输出为
,框回归网络的输出为
。
Proposal Layer
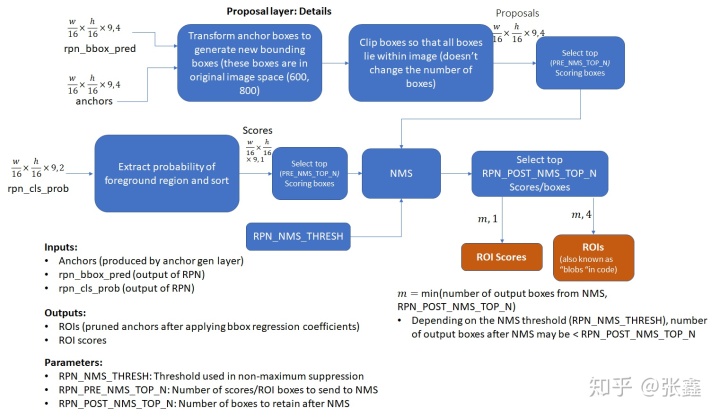
候选层的输入为所有的
个锚框。通过应用基于前景分类得分的非极大值抑制从锚框中减少部分候选框。另外也通过框回归的坐标系数来校正候选框的坐标。
Anchor Target Layer
锚框目标层的目标是选出合适的锚框作为RPN网络的训练数据(这个也是让我挺疑惑的地方,在推理网络中生成训练数据)。RPN网络的目的:
- 识别一个区域是前景还是背景
- 对前景框回归一个合理的坐标校正参数
下面作者认为讨论下RPN损失,有助于理解RPN网络。
计算RPN损失
RPN的目标是生成好的候选框(包含前景分类和坐标回归)。具体点,就是需要在锚框集合中,寻找到含目标可能性高的锚框,以及回归出这些锚框对应的坐标变换系数(包含位置、宽度和高度)。RPN损失的设计也是基于以上目的,那我们看下是不是这样的?
RPN损失是分类损失和回归损失之和。分类损失使用交叉熵损失,框回归使用真实回归系数和预测系数之间的距离(RMSE)计算得到。真实回归系数使用与锚框最近的标签框计算得到,预测系数通过网络预测得到。
Classification Loss
cross_entropy(predicted_class, actual_class)
Bounding Box Regression Loss
回归框损失只计算了前景的回归框损失。作者认为背景框的回归损失没有意义,因为背景回归框没有对应的标签框。
其中
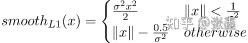
上式中的
需要人工设定,也可以成为超参数,一般设置为3。(PS: 这里作者介绍了在Python实现中,前景锚框bbox_inside_weights,也就是掩膜阵列一般作为向量运算,一般不要用for-if循环,因为循环不方便并行计算)
所以,计算RPN损失需要两个要素:
- 锚框的前景背景类别标签和打分(和softmax概率有关)
- 对于前景锚框的目标回归系数
下面介绍上面两个要素如何获取。
- 选择有目标的锚框
- 计算锚框和标签框的交并比(IOU)值,然后选择好的前景框
按照IOU比选择前景框,有下面两种情况:
- type A:对于每个标签框(ground truth bbox),所有的前景框是与标签框IOU最大的锚框
- type B:前景框与标签框的IOU会超过一个阈值
如下图所示。

在上图中,只有与标签框的重叠区域超过一定阈值(IOU超过一定阈值)的锚框才被选择下来(还有很多重复锚框,这个时候选择NMS算法,选择一个锚框作为结果)。这里的阈值非常重要,选择合理的阈值有助于提高RPN的效果。类似的,重叠区域小于一定阈值(IOU超过一定阈值)的锚框作为负样本。需要注意的是,不是所有非正样本(重叠区域大于一个指定阈值)是负样本,就是还有中间派,即不是正样本,又不是负样本。这类样本被称为“don’t care”(不关心的样本,哈哈!!!)。这些样本不会用来计算RPN损失。
因此有两个额外的阈值,与前景背景框的数量有关。前景背景框的总数量我们需要定义,以及前景框的占比也需要事先定义。如果通过测试的前景框数量操作一定阈值,则会随机将这些通过测试的前景框标记为“don’t care”,对于背景框也是同样的操作。
然后,计算前景框与其最重叠(IOU值最大)的真实框的框回归系数。这个相对简单,只需要按照公式计算即可。
最后我们总结下anchor target layer。为记忆方便,我们列出该层的参数和输入输出配置:
参数:
- TRAIN.RPN_POSITIVE_OVERLAP:默认为0.7。用于选择正样本的阈值。如果锚框和ground truth框的IOU大于该值,则为正样本。
- TRAIN.RPN_NEGATIVE_OVERLAP: 默认为0.3。用于选择负样本的阈值。如果一个锚框和ground truth框的IOU小于该值,则为负样本。锚框的IOU大于TRAIN.RPN_NEGATIVE_OVERLAP、小于TRAIN.RPN_POSITIVE_OVERLAP被标记为“don’t care”。
- TRAIN.RPN_BATCHSIZE:默认为256。前景锚框和背景锚框的综述。
- TRAIN.RPN_FG_FRACTION:默认为0.5。前景框在batch_size中的占比(默认值设定的很平衡)。如果前景框的数量大于TRAIN.RPN_BATCHSIZE*TRAIN.RPN_FG_FRACTION,将会随机选择超过的部分为“don’t care”。
输入:
- RPN网络输出(前景背景预测结果,框回归系数)
- 锚框(通过anchor generation layer)
- ground truth框
输出:
- 经过第一次纠正的目标框和对应的类别标签
- 目标回归系数
其它层,比如proposal target layer,ROI pooling和分类层被用来生成计算分类损失的数据。下面我们将与anchor target layer类似,看看如何计算分类层损失,以及计算该损失需要哪些数据。