https://blog.csdn.net/u012957549/article/details/119333925
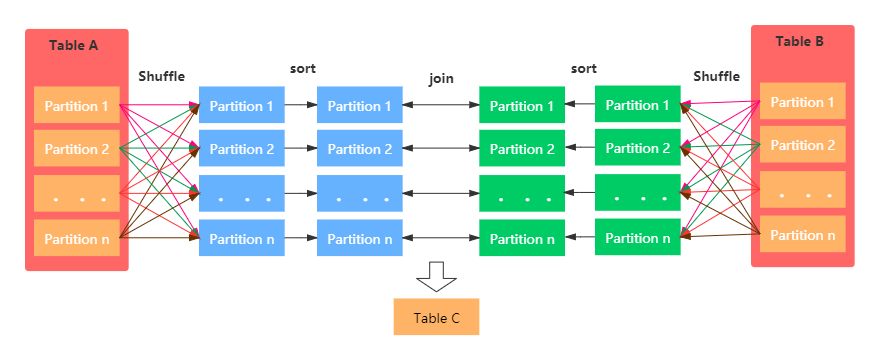
Sort merge join (Spark默认Join方式)
正是因为 NLJ 极低的执行效率,所以在它推出之后没多久之后,就有人用排序、归并的算法代替 NLJ 实现了数据关联,这种算法就是 SMJ。SMJ 的思路是先排序、再归并。具体来说,就是参与 Join 的两张表先分别按照 Join Key 做升序排序。然后,SMJ 会使用两个独立的游标对排好序的两张表完成归并关联。
Hash Join
HJ 的计算分为两个阶段,分别是 Build 阶段和 Probe 阶段。在 Build 阶段,基于内表,算法使用既定的哈希函数构建哈希表,如上图的步骤 1 所示。哈希表中的 Key 是 Join Key应用(Apply)哈希函数之后的哈希值,表中的 Value 同时包含了原始的 Join Key 和Payload。在 Probe 阶段,算法遍历每一条数据记录,先是使用同样的哈希函数,以动态的方式(On The Fly)计算 Join Key 的哈希值。然后,用计算得到的哈希值去查询刚刚在 Build阶段创建好的哈希表。如果查询失败,说明该条记录与维度表中的数据不存在关联关系;如果查询成功,则继续对比两边的 Join Key。如果 Join Key 一致,就把两边的记录进行拼接并输出,从而完成数据关联。
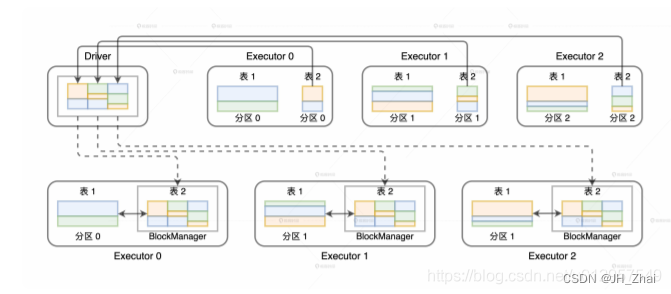
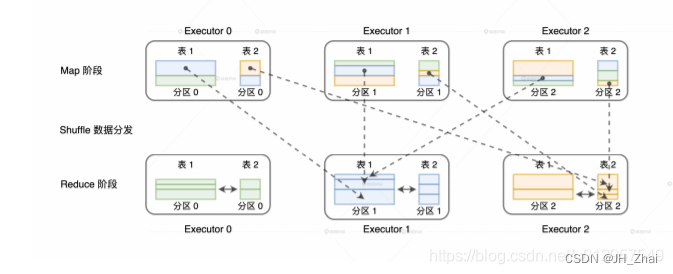
相比单机环境,分布式环境中的数据关联在计算环节依然遵循着 NLJ、SMJ 和 HJ 这 3 种实现方式,只不过是增加了网络分发这一变数。在 Spark的分布式计算环境中,数据在网络中的分发主要有两种方式,分别是 Shuffle 和广播。那么,不同的网络分发方式,对于数据关联的计算又都有哪些影响呢?如果采用 Shuffle 的分发方式来完成数据关联,那么外表和内表都需要按照 Join Key 在集群中做全量的数据分发。因为只有这样,两个数据表中 Join Key 相同的数据记录才能分配到同一个 Executor 进程,从而完成关联计算,如下图所示。
BroadCast
如果采用广播机制的话,情况会大有不同。在这种情况下,Spark 只需要把内表(基表)封装到广播变量,然后在全网进行分发。由于广播变量中包含了内表的全量数据,因此体量较大的外表只要“待在原地、保持不动”,就能轻松地完成关联计算,如下图所示。