由于Driver的内存管理较为简单,
内存管理主要对Executor的内存
管理进行探讨。
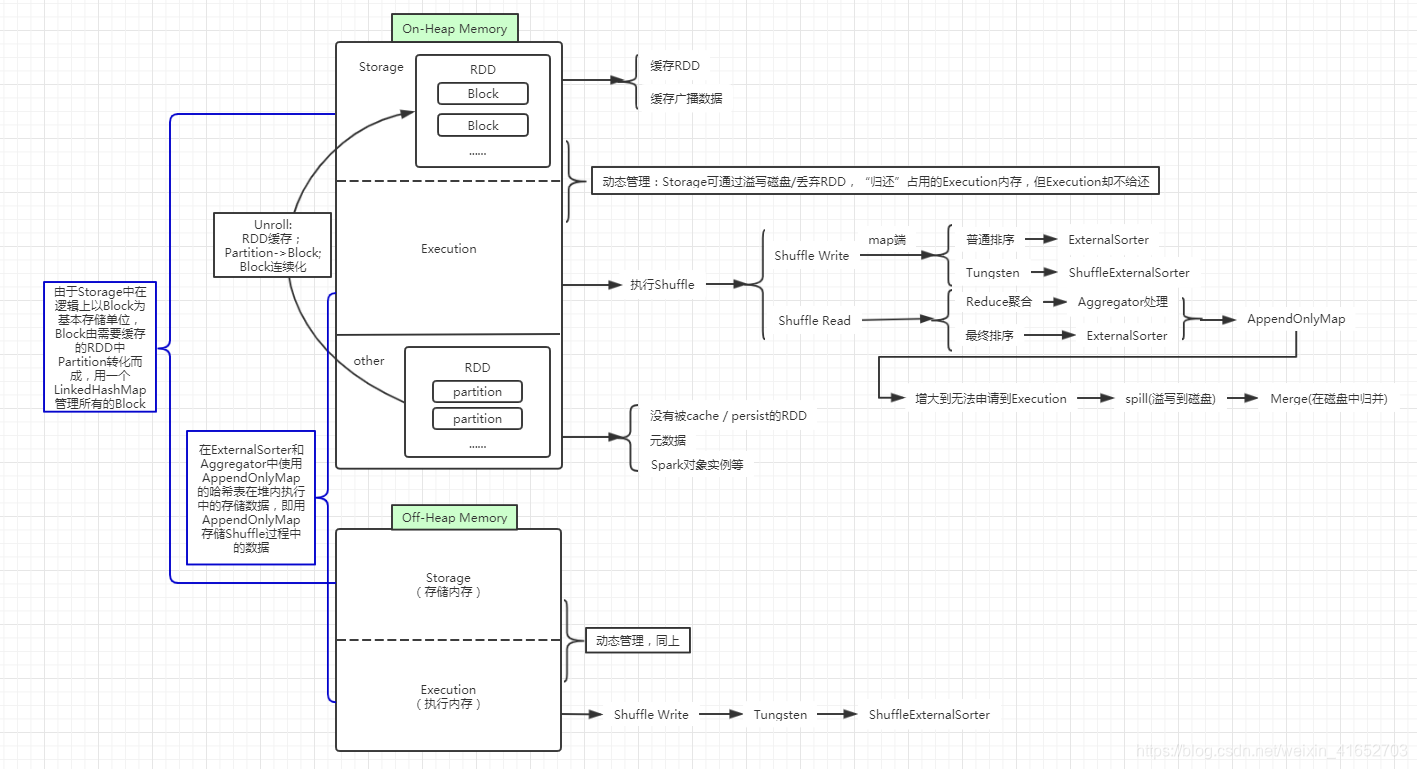
一、堆内(On-Heap Memory)和堆外(Off-Heap Memory)内存规划
Executor作为一个JVM进程,Executor的内存管理建立在JVM的内存管理之上。Spark对堆内内存进行JVM内存管理,引入了堆外内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用;其中,堆外内存直接向操作系统申请。
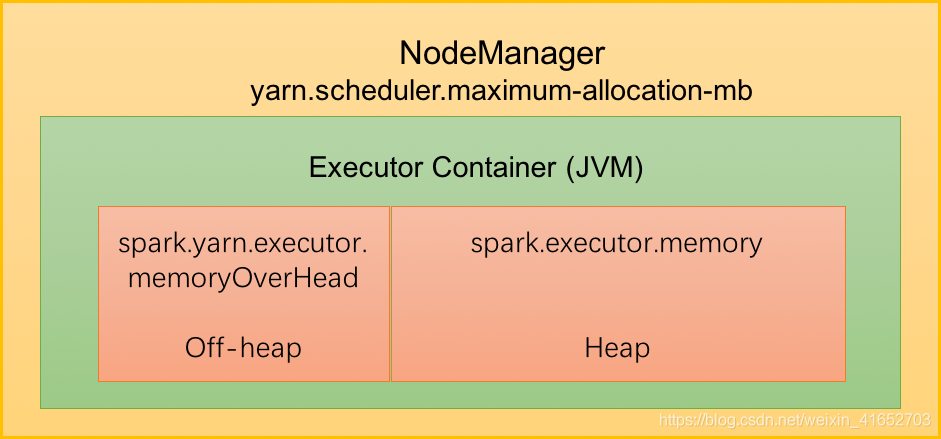
二、堆内内存(On-Heap Memory)
堆内内存概述:
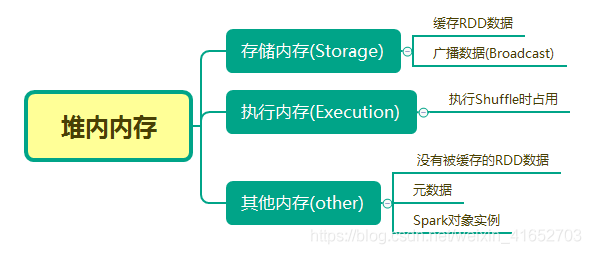
在Spark程序启动时,堆内内存的大小由spark-submit中的–executor-memory 或 spark.executor.memory参数配置。Spark对于堆内内存的管理是一种逻辑上的“规划式”管理,因为对象实例占用内存的申请和释放都由JVM完成,Spark只能在申请后和释放前记录这些内存。
对于Spark的序列化对象,由于是字节流的形式,其占用的内存大小可以直接计算,而对于非序列化对象,其占用的内存是通过周期性的采样估算而得,即并不是新增数据项都会计算一次占用内存的大小,这种方法降低了时间开销,但是有可能误差较大,导致某一时刻的实际内存远远超出预期。所以Spark并不能准确记录实际可用的堆内内存,从而也无法避免内存溢出—OOM。
1.内存空间的动态分配
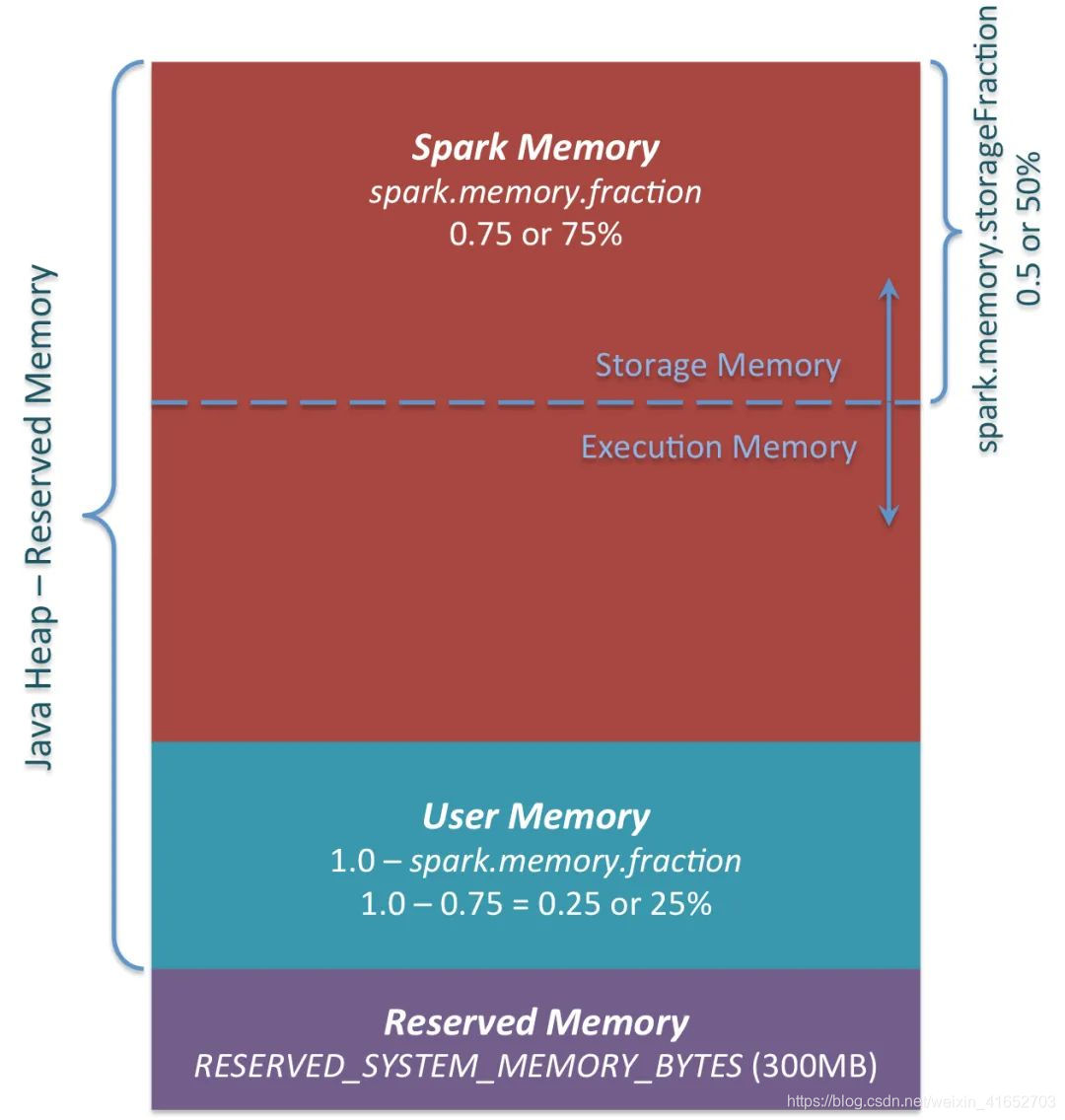
在Spark1.6之前使用静态内存管理,即存储内存、执行内存和其他内存的大小在Spark应用程序运行期间是固定的。缺点很多,因此在Spark1.6以后,堆内内存和堆外内存的管理采用动态分配的形式,即:存储内存(Storage)和执行内存(Execution)共享同一块存储空间,双方可以动态的占用对方的空闲区域。
动态占用机制的规则如下:
1.首先设定基本的Storage和Execution的区域(spark.storage.storageFraction参数),该设定确定了双方各自拥有的空间范围;
2.双方的空间都不足时,则都存储到磁盘上面;
3.若己方空间不足,而对方空间空余时,可借用对方的空间(存储空间不足指不足以放下一个完整的Block)。
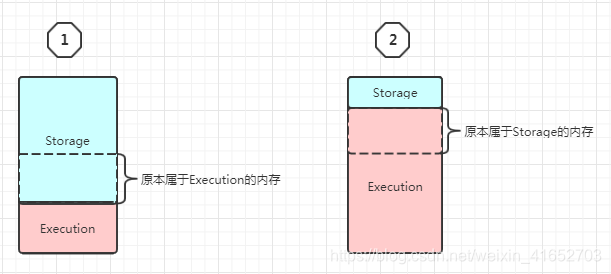
在上图1中的情况中,Storage占用了Execution的空余内存后,Execution要开始用了,想把虚线标示的内存要回来,于是Storage便开始在自己缓存的RDD中,找到 StorageLevel.MEMORY_AND_DISK / .MEMORY_AND_DISK_2 / .MEMORY_AND_DISK_SER / .MEMORY_AND_DISK_SER_2 的数据,溢写到磁盘上。如果写到磁盘上以后,还是达不到虚线的标准,在这一部分存储的数据,会直接被删除。鉴于此种状况,cache / persist一般都与checkpoint结合使用。Spark-core的checkpoint将一个RDD存储到分布式文件系统中;Spark-streaming的checkpoint:1.保存整个运行环境;2.保存未处理的RDD,便于恢复故障;
在上图2中的情况中,Execution占用了Storage的空余内存,但是Storage要开始用了,想把虚线标示的内存要回来,这时候!Execution对Storage理直气壮地说:我的Shuffle调度时对内存的应用太复杂了,给你腾不出来地方,这些内存就不还给你了!Storage当然义愤填膺的说:好!
2.淘汰与落盘
由于同一个Executor的所有计算任务共享有限的存储内存空间,当有新的Block需要缓存但是剩余的内存空间不足且无法动态占用时,就要对LinkHashMap中的旧Block进行淘汰(Eviction),而被淘汰的Block如果存储级别中包含存储到磁盘的要求,则要对其进行落盘(Drop),否则直接删除该Block。遍历LinkedHashMap中Block,按照LRU进行淘汰,被淘汰的旧Block与新Block的MemoryMode相同,即同属堆外或堆内内存;新旧Block不能同属一个 RDD,避免循环淘汰。
在RDD的缓存时,将原先存在Others中的含有多个Partition,且每个Partition中的record不连续的RDD,转存至Storage中,并且每个RDD中含有多个Block,且每个Block中的record连续,这个过程称为Unroll。
Storage模块在逻辑上以Block为基本存储单位,RDD的每个Partition经过处理后唯一对应一个Block(BlockId格式为rdd_RDD-ID_PARTITION-ID)。Driver端的Master负责整个Spark应用程序的Block的元数据信息管理和维护,而Executor端的Slave负责将Block的更新状态上报到Master,同时接收Master的命令,例如新增或者删除一个RDD。
3.执行内存(Execution)
Execution主要用来存储任务在执行Shuffle时占用的内存,Shuffle是按照一定规则对RDD数据重新分区的过程,由Shuffle Write和Shuffle Read两个阶段组成。
3-1 Shuffle Write
(1) 若在map端选用普通的排序方式,会采用ExternalSorter进行外排,在内存中存储数据时主要占用堆内执行空间;
(2)若在map端选择Tungsten方式,则采用ShuffleExternalSorter直接对序列化形式存储的数据排序,在内存中执行存储数据时可以使用堆内或堆外执行空间,取决了用户是否开启了堆外内存及堆外内存是否足够。
3-2 Shuffle Read
(1)在对reduce端数据进行聚合时,要将数据交给Aggregator处理,在内存中存储数据时占用堆内执行空间;
(2) 若对最终结果进行排序,则再次将数据交给ExternalSorter处理,此时占用堆内执行空间;
在ExternalSorter和Aggregator中,Spark会使用一种叫AppendOnlyMap的哈希表在堆内执行内存中存储数据,但是在Shuffle过程中并不是所有的数据都能保存到哈希表中,这个哈希表占用的内存会周期性的进行估算,当达到一定程度,无法再从MemoryManager中申请到执行内存时,Spark就会全部存储到磁盘文件中,这个过程被称为溢存(Spill),溢存到磁盘的文件最后会被归并(Merge)。
4.其他内存(other)
这里用于存储没有被缓存的RDD、元数据及Spark对象实例。其中,RDD以Partition为基本存储单位。
总结
Spark的存储内存和执行内存有着截然不同的管理方式:对于Storage来说,Spark用一个LinkedHashMap来集中管理所有的Block,Block由需要缓存的RDD的Partition转化而成,而对于Execution来说,Spark用AppendOnlyMap来存储Shuffle过程中的数据,在Tungsten排序中甚至抽象成为页式管理,开辟了全新的JVM内存管理机制。
三、堆外内存(Off-Heap Memory)
Spark引入堆外内存(Off-Heap),使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据;
堆外内存意味着把内存对象分配到Java虚拟以外的内存,这些内存直接受操作系统(而不是虚拟机)管理。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。Spark可以直接操作系统堆外内存,减少了不必要的系统开销,以及频繁的GC扫描和回收,提高了处理性能。堆外内存可以被精确地申请和释放(JVM对于内存的清理是无法精确指定时间点的,因此无法实现精确的释放),而且序列化的数据占用的空间可以被精确地计算,所以相比堆内内存来说降低了难度,也降低了误差;
在默认情况下堆外内存并不启用,可以通过配置spark.memory.offheap.enabled参数启用,并由spark.memory.offheap.size设定堆外空间的大小。除了没有Other空间外,堆内内存与堆外内存的划分方式相同,所有运行中的并发任务共享存储内存和执行内存。
四、spark常用参数说明
1.num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
2.executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G
8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3
1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
3.executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
4.driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
5.spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
6.spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
7.spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
8.total-executor-cores
参数说明:Total cores for all executors.
9.资源参数参考示例
以下是一份spark-submit命令的示例:
./bin/spark-submit \
--master spark://192.168.1.1:7077 \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--total-executor-cores 400 \ ##standalone default all cores
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \