目录
前言
Rasa NLU负责
意图提取
和
实体提取
。例如,输入“明天上海的天气如何?”,Rasa NLU要提取出改句子的意图是查询天气,以及对应的实体值和类型名:明天—日期、上海—城市。
Rasa NLU使用
有监督算法
来完成功能,因此需要开发者提供适当数量的语料,包括意图信息和实体信息。
Rasa NLU在软件架构上设计的很灵活,允许开发者使用各种算法来完成功能,这些算法的具体实现被称为
组件(component)。
为了让组件灵活配置和维持正确的前后组件的依赖关系,Rasa NLU引入了
有向无环图DAG
的组件配置系统。
一、训练数据
在示例项目文件列表中的 data/nlu.yml 正是Rasa NLU的数据文件,具体内容如下:
version: "3.0"
nlu:
# 意图字段
- intent: greet
examples: |
- hey!
- hello!
- hi!
- hello there!
- moin!
# 同义词字段
- synonym: 番茄
examples: |
- 番茄。
- 西红柿
- 洋柿子
- 火柿子
# 查找表字段
- lookup: 城市
examples: |
- 北京
- 上海
- ...
- 广州
- 深圳
# 正则表达式字段
- regex: help
examples: |
- \bhelp\b
Rasa NLU的训练数据为YAML格式。从结构上说,Rasa N:U的训练数据都在
键(key)为nlu
的列表内。列表中每个元素都是一个字典,依靠字典中的键来区分功能。具有特殊含义的键有
intent
、
synonym
、
regex
、
lookup
。
除intent外,其他3个都是可选的。
1.1 意图字段(intent)
具有intent键表明当前的对象是用来存储训练样例的。intent对应的值时意图名。需要注意的是
意图名中不能包含“/”字符
,因为Rasa已经将这个字符预留了。
1.2 同义词字段(synonym)
具有synonym键表明当前的对象是用来存储同义词信息的。例如西红柿是番茄的同义词。在启动EntitySynonymMapper组件(后续章节介绍)的情况下,
推理时,会将得到的实体值的同义词替换为标准词。
即将“西红柿”、“洋柿子”全部替换为“番茄”。
1.3 查找表字段(lookup)
具有lookup键表明当前的对象是用来存储查找表的。在实体识别和意图识别的时候,如果开发者能给这些组件一些额外的特征,那么将提高这些组件的准确度。

在上述实例中,会有查找表特征[0001111101111000]。在NER时,模型会重点考虑这些查找表的特征,因此,即使训练数据中未出现车站名,模型也能在查找表特征的帮助下,正确提取出车站名。
1.4 正则表达式字段(regex)
具有regex键表明当前的对象是用来存储正则表达式的。利用正则表达式匹配某种模式后,将这种模式是否出现作为特征传给NER组件或意图识别组件,以提高组件的性能。
其优点是精度高,因此在特别规则的NER识别过程中,如身份证号码识别、电话号码识别等场景下,可以利用正则表达式特征提高识别准确率。
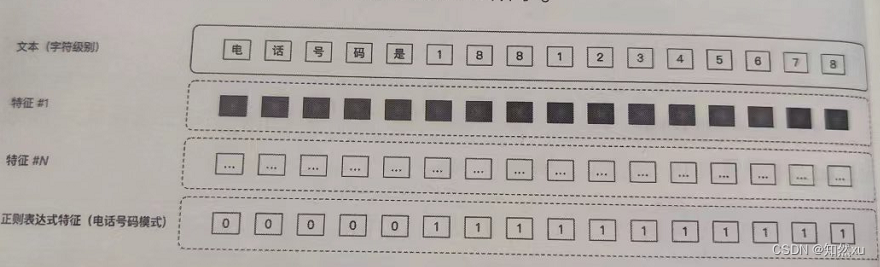
正则表达式同样也可以作为特征提供给NER模型做实体识别。
1.5 查找表和正则表达式的使用
在Rasa中,查找表和正则表达式主要通过2种方式使用:
- 作为NER组件的输入特征之一,可以与训练数据concat后,再输入神经网络中;
- 作为NER组件的输入,直接作为训练数据集;
二、组件
Rasa NLU是一个基于有向无环图的通用框架。
有向无环图是由组件(component)相互连接构成的。
一个NLU应用通常有实体识别、意图识别两个子任务。为了完成这些任务,一个典型的Rasa NLU配置通常包含如下各类组件。

1、
语言模型组件
:加载模型文件,为后续组件提供框架支持,如初始化spaCy和BERT;2、
分词组件
:将文本分割成词,为后续的高级NLP任务提供基础数据;3、
特征提取组件
:提取词语序列的文本特征,可以同时使用多个特征提取组件;4、
NER组件
:根据前面提供的特征对文本进行命名实体识别;5、
意图分类组件
:按照语义对文本进行意图的分类,也成意图识别组件;6、
结构化输出组件
:将预测结果整理成结构化数据并输出。
这一部分不是以组件的形式提供的,而是流水线内建的功能,开发者不可见。
2.1 语言模型组件
语言模型组件加载
预训练的词向量模型
。目前有2个语言模型组件,如下表:
|
组件 |
备注 |
| spaCyNLP | 该组件所需的模型需要提前下载到本地,否则会出错 |
| MitieNLP | 需要预先训练好的模型 |
2.2 分词组件
Rasa分词组件中支持中文语言的分词器如下表:
|
组件 |
依赖 |
备注 |
| JiebaTokenizer | Jieba | |
| MitieTokenizer | Mitie | 经过改造可以支持中文分词 |
| spaCyTokenizer | spaCy |
2.3 特征提取组件
无论是实体识别还是意图分类,都需要上游的组件提供特征。Rasa的特征提取组件如下:
|
组件 |
依赖组件 |
备注 |
| MitieFeaturizer | MitieNLP | |
| spaCyFeaturizer | spaCyNLP | |
| ConveRFeaturizer | 分词组件 | 基于Poly AI的conveRT模型 |
| LanguageModelFeaturizer | 分词组件 | 基于HuggingFace的transformers库 |
| RegexFeaturizer | 分词组件 | 读取训练数据中的正则表达式配置 |
| CountVectorsFeaturizer | 分词组件 | 词袋模型 |
| LexicalSynacticFeaturizer | 分词组件 | 提供词法和语法特征,如是否句首、句尾、纯数字等 |
2.4 NER组件
Rasa支持多种NER组件,多数不可同时使用,少数组件可以有条件的同时使用。
|
组件 |
备注 |
| CRFEntityExtractor | |
| spcaCyEntityExtractor | 只能使用spaCy内置的实体提取模型,不能再训练。内置实体种类为人名、地名、组织结构名等 |
| DucklingEntityExtractor | 只能使用预定义的实体,不能再训练。内置的实体种类为邮箱、距离、时间等 |
| MitieEntityExtractor | |
| EntitySynonymMapper | 用于同义词改写,将提取到的实体标准化 |
| DIETClassifier | |
| RegexEntityExtractor | 读取训练数据中的查找表及正则表达式,用于提取实体 |
2.5 意图分类组件
意图分类组件如下表所示:
| 组件 | 依赖 | 备注 |
| MitieIntentClassifier | Mitie | |
| SklearnIntentClassifier | Scikit-learn | |
| KeywordIntentClassifier | ||
| DIETIntentClassifier | Tensorflow | |
| FallIntentClassifier | 如果其他组件预测的intent得分过低,则该组件将intent更改为NLU fallback |
2.6 实体和意图联合提取组件
Rasa提供DIETClassifier(基于Rasa自行研发的DIET技术)用户实体和意图的联合建模。
2.7 回复选择器
对于FQA等简单的QA问题,只需要使用NLU部分就可以轻松完成,因此Rasa提供了回复选择器(ResponseSelector)组件。
三、流水线
Rasa NLU基于有向无环图进行组件配置,此有向无环图在Rasa中称为流水线(pipeline)。
流水线定义了各个组件和组件之间的依赖关系,允许开发者对各个组件进行配置。
Rasa NLU的配置文件使用的是YAML格式。下面是适合
中文开发者
的,推荐流水线配置:
recipe: default.v1
language: "zh"
pipeline:
-name: JiebaTokenizer # 分词组件,jiba分词可能会和实体边界产生冲突,后续介绍其他分词组件
-name: LanguageModelFeaturizer
model_name: "bert"
model_weights: "bert-base-chinese"
-name: "DIETClassifier"大体上Rasa NLU的配置文件可以分为3个主要的键:recipe、language、pipeline。
recipe:
表示当前配置文件所用的格式,当前Rasa只支持一种格式,那就是default.v1
language:
用于指定Rasa NLU将要处理的语言
pipeline:
配置文件的核心,由列表构成,每个元素都是一个字典(表现在YAML中类似于name: xxx),这些字典直接对应流水线组件
四、输出格式
NLU的输出内容主要包括text、intent、entities 3个部分。分别表示请求文本、意图识别、实体识别。实例如下:
{
"text": "show me chinese restaurants", # 用户输入的文本
"intent": "restaurant_search", # 意图字段
"entities": [ # 实体字段
{
"start": 8, # 开始位置
"end": 15, # 结束位置
"value": "chinese", # 实体值
"entity": "cuisine", # 实体类型
"extractor": "CRFEntityExtractor",# 提取器信息
"confidence": 0.854, # 置信度
"processors": [],
}
]
}
五、如何使用Rasa NLU
Rasa是一种高度内聚的框架,可以使用Rasa自带的命令行工具进行模型训练和推理任务。
(1)训练模型
rasa train nlu
这条命令将会从 data/ 目录下查找训练数据,使用config.yml作为流水线配置并将训练后的模型保存在 models/ 目录中,模型的名字以nlu-为前缀
(2)命令行测试
rasa shell nlu
如果想自行制定模型,则可以使用如下命令:
rasa shell -m models/nlu-<timestamp>.tar.gz
下面是rasa shell的使用界面:
hello # 用户自己的输入
# 返回结果
{
"text": "hello", # 原始文本
"entities": [], # 实体字段
"intent": { # 意图字段
"name": "greet",# 意图类型
"confidence": 0.996844410963013 # 置信度
},
"intent_ranking": [ # 各意图置信度
{
"name": "greet",
"confidence": 0.9968444108963013
},
{
"name": "mood_greet",
"confidence": 5.1380e-05
},
]
}(3)启动服务
Rasa NLU提供了 RESTful HTTP API的服务形式,使用如下命令开启。
rasa run — enable-api
我们可以通过向 /model/parse 路径发送请求的方式使用预测服务,如使用curl作为客户端。
curl localhos:5005/model/parse -d ‘{“text”:”hello”}’
在实际调试中,开发者可以考虑使用postman等工具发送请求,如下所示:

六、实战:医疗机器人的NLU模块
在学习完Rasa NLU模块后,检验学习效果最好的办法就是实战。本项目将构建一个简单的医疗领域机器人的NLU模块。它支持以下实体和意图识别:
- 对药品查询或医院、科室查询的意图识别
- 对疾病和病症的实体识别
- 简单地打招呼
具体代码可参考:
Git