最近在做一些图神经网络相关的课题,做了些调研,简单记录一下想法和收获。
图神经网络简介
图(Graph)这种数据结构在很多场景下都有大量应用和表现。各节点通过边建立关系,图神经网络是借助神经网络的知识,将图中的每个节点embedding为向量,每个节点向量化后,就可以做很多下游任务了,比如节点的分类、节点间链路预测、节点相关性预测等等。
应用场景
有了节点的embedding表示,其实就可以有很多很多的应用场景。比如:
-
商品推荐
:有user和item,可以用item作为节点(节点包含自身原始的属性特征),用户的点击行为,可以刻画item之间的连接关系。这样就建立了Graph。然后用两个item的内积衡量相似性,损失函数优化相似性,就可以得到各item的embedding。推断时,来了新item,通过额外信息可建立与其他item的关系,从而得到embedding,然后计算与某些其他item的相似程度,进行推荐。 -
用户分类
:有user和各类与user有关的信息,通过这些信息建立user之间的连接关系,完成构图。损失函数选择交叉熵,从而可对embedding再经过mlp、softmax进行类别的预测概率,从而完成训练。 -
交通流量预测
:路口的流量看作节点,可与其他节点建立连接关系。 -
其他经典数据集
:如论文引用数据集、分子结构等等。 -
异质图
:上面建立的大都是同质图,即节点的类型都相同。也可构建异质图,图中不同节点有不同的类型。
典型模型
图神经网络典型的方法如GCN,HAT,GraphSAGE, PinSAGE等。通过图的连接关系以及节点本身的属性信息,得到节点的embedding。
GCN适用于同质图的节点embedding,因为它在卷积过程中没有考虑节点的不同类型。HAT全称是基于注意力机制的异质图神经网络 Heterogeneous Graph Attention Network,可以广泛地应用于异质图分析。GraphSAGE是一个工业级的图节点embedding模型,容易在超大规模的图中进行训练和推断。PinSAGE是Pinterest公司在其推荐系统中成功应用的一个案例。
GCN
最原始的GCN应该是借助拉普拉斯矩阵进行图的embedding,这个讨论讲的很详细了:
如何理解GCN
。总之就是将图中的节点经过层层变换得到embedding,但这个最大的问题就是,它每次都需要将所有的节点都参与计算,这对工业界海量的节点根本不现实。另外,在新节点参与图后,需要重新对全图进行计算,才能得到新节点的embedding(也就是transductive的)。因此后面的很多图神经网络都对此进行了很多改进,inductive的方法才更适合海量节点的场景。
PinSAGE
PinSAGE论文解读
PinSAGE是GraphSAGE的一个工业级实现和应用。原文处理的是个二部图,一类节点是item,另一类节点可以理解成相关item的集合(简单点,可以理解成user的特征吧)。因为是二部图,所以这两类节点内部没有边连接。理解PinSAGE可以从下面几个角度来看:
-
邻居节点卷积
:如下图,A节点的embedding是通过 A本身的属性特征编码+邻居特征聚合 得到的。假设每个节点的embedding维度为10,由于A节点本身有BCD三个邻居,因此BCD三个embedding经过MLP、relu可以再得到三个10维向量,然后池化或聚合成一个10维向量。再把这个聚合的邻居节点的10维向量与A的原本的embedding concat起来,再经过MLP,可以得到一个新的10维向量,这个新的向量就是A新的embedding。
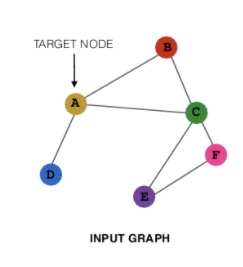
左图为输入图结构,右图为卷积过程

-
邻居的采样方法
:如果采用当前节点的所有邻居节点,可能节点非常多,对内存的使用无法预见,因此采样指定数量的邻居。采用随机游走,取前T个邻居。 -
卷积层的堆叠
:下图比上图多的部分是最右边的二阶邻居,这样可以进行二层邻居的卷积,从而使A的embedding中包含了二阶邻居特征。

-
训练方法
:item的embedding内积可看作两个item的相似性,损失函数就是使相似的item的embedding内积尽可能大,不相似的item的embedding内积尽可能小。
GraphSAGE
GraphSAGE全称为Graph SAmple and aggreGatE。从名称中可以看到,其实最重要的两点就是图的sample和aggregate。“sample”是指对邻居节点采样,因为大规模图谱中,某一节点的邻居节点数量通常有多有少,在训练时难以控制内存的使用量,甚至过多时会超出内存容量,因此对邻居节点进行固定数量的采样,仅借助固定个数的邻居节点和自身属性进行embedding。“aggregate”是指对邻居节点的embedding进行聚合,如池化、LSTM等方式将采样的邻居节点聚合成一个向量,此向量就作为邻居节点所传递的所有信息。
GraphSAGE是PinSAGE的原型。PinSAGE基本按照GraphSAGE的原理来实现,只是在实现过程中进行了一些改进。
- PinSAGE在邻居节点embedding前加了一层全连接层
- PinSAGE在聚合邻居节点时采取了重要性采样的方式,每个邻居节点的权重不一样。而GraphSAGE没有进行重要性采样。
-
graphsage源码
GAT
GAT(GRAPH ATTENTION NETWORKS)通过名字可以看到,是将attention引入到图神经网络领域。
对于当前节点,计算该节点与其邻居节点的相似度,大致想法和,这样计算出来,邻居节点的权重就不一样了,通过权重乘以每个邻居的特征(邻居特征后会先经过一个MLP网络),从而将邻居节点的信息聚合起来。
优点:对于不同的邻居具有不同的权重
缺点:只有一阶邻居的信息,没有表征更高阶的信息。
图神经网络与知识图谱
图神经网络跟知识图谱都是以图的形式进行表示,都是为了得到节点的分布式表示。但是他们的原理方法上有点不一样:
-
图神经网络受到word2vec中由中心词预测上下文的启发,图神经网络的表示学习通常有两个基本目标。一是在低维空间中学习到的表征可以重构出原有网络结构。第二个目标是学习到的表征可以有效地支持网络推断。在应用上主要侧重度量图结构信息,为具体任务提供输入信息,比如节点分类、链路预测,这里以DeepWalk为代表。四种典型的图神经网络的结构:GraphSAGE, GCN, GAT, PPNP。
-
而知识图谱是受到word2vec能自动发现implicit relation的启发(king-man=quene-women),重点在学习图数据时强调的是节点跟关系的表示,这里以trans系列(TransE,TransR,TransH)为代表。知识图谱在应用更关注于关系建模。但是两种方法也可以互相借鉴的。
异质图和同质图
异质图是指图中的节点类型有多个,如user和item等都作为节点,不同类型节点的特征分布都不同。图质图是指图中只有一种节点类型。异质图和同质图的区别主要就是邻居类型不同,如果使用同样的参数,可能会造成embedding有所偏差。
查阅了一些应用案例,感觉可以把异质图变成同质图来处理。处理异质图的一个简单方法是将每个节点的类型转换为一个与原始特征连接的热特征向量。这样就可以在节点的embedding或原始特征中有类型差异的表征了。像是PinSAGE网络,尽管用pins和boards两种节点类型组成了graph,但是它是一个二部图,pins之间没有
部分参考链接:
https://zhuanlan.zhihu.com/p/144083271
https://blog.csdn.net/eagleuniversityeye/article/details/108772280
https://blog.csdn.net/byn12345/article/details/105787601