对RDD操作,可以通过spark提供的算子完成
在spark提供的对RDD操作的算子中,分成了两类:
- **转换算子(transfermation): ** 从-一个RDD,经过算子处理转换成另外一个RDD。
-
行动算子(
Action
):
从一个RDD,经过算子处理,会生成一个scala对象。
转换算子是懒加载模式,只有遇到了行动算子,转换算子才会真正执行
RDD转换(Transformations)算子
转换算子(transfermation) 分成了两部分:
1.对值(value)进行操作的算子
2.对key-value结构数据操作的算子
1. 值类型的算子: Value类型
map:
对rdd中的元素进行映射处理,生成新的RDD
flatMap:
对rdd中的元素进行扁平化映射处理,生成新的RDD
fliter:
过滤
mapPartitions:
以分区为单位进行映射处理,每一 个分区执行一-次匿名函数
map和mapPartition的区别
map():每次处理一条数据。
mapPartition():每次处理一个分区的数据
mapPartitionsWithIndex:
和上面的算子一样,以分区为单位。不一样的
是,这个算子还可以获取到分区编号
glom:
把分区内的数据封装形成数组
group by
:分组,将相同的key对应的值放入一个迭代器。
distinct
:去重,对源RDD进行去重后返回一个新的RDD
repartition
:根据分区数,重新通过网络随机洗牌(shuffle)所有数据。
coalesce
:默认是不进行shuffle的,所以要是以哦那个coalesce算子增加分区,就应该把shuffle参数设置为true
sortBy
:使用func先对数据进行处理,按照处理后的数据比较结果排序,默认为正序。
union
:和集,两个RDD元素合并在一起,返回一个新的RDD
subtract
:差集,从第一个RDD减去第二个RDD的交集部分
intersection
:交集,对源RDD和参数RDD求交集后返回一个新的RDD
2. Key-Value pair类型
就是根据key对value进行数据处理
groupByKey
:groupByKey也是对每个key进行操作,但只生成一个sequence。
reduceByKey
:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
reduceByKey和groupByKey的区别
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v].
groupByKey:按照key进行分组,直接进行shuffle。
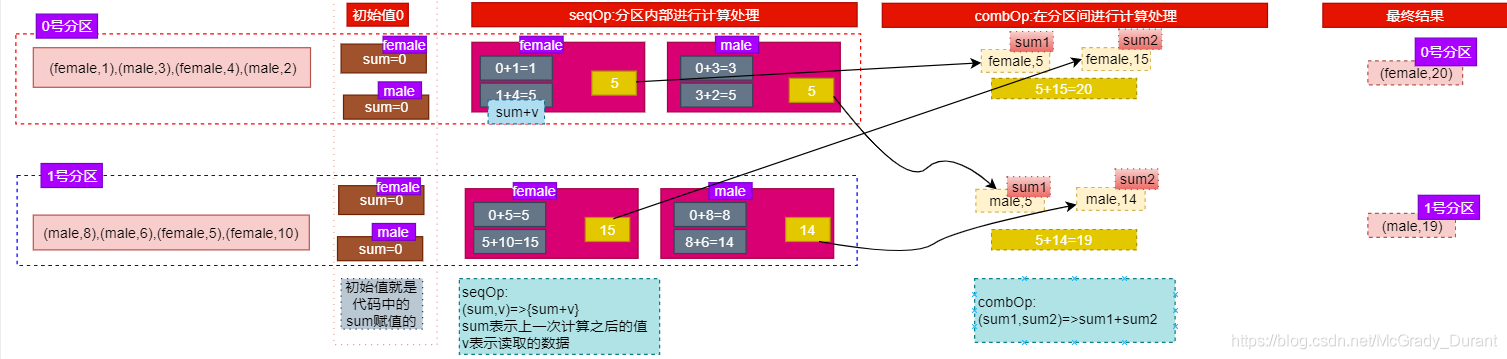
aggregateByKey
:聚合算子,根据key进行聚合
1.aggregateByKey算子,就是根据key对value进行操作
key相同的value进行聚合处理
2可以返回一个和value类型不一 样的数据。输入数据和输出
数据类型可以不一样
3.需要一 个初识值
4.这个算子需要两个函数完成对应的功能。一个函数在分区内
部进行聚合,另外个函数在分区间进行聚合
seqOp:就是在分区内部进行聚合;
combOp:就是在分区之 间进行聚合
rdd aggregateByKey(zeroValue)(seqOp.combOp)
sortByKey
:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
mapValues
:针对于(K,V)形式的类型只对V进行操作
join
:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
RDD的行动(Action)算子
只有调用行动算子才会触发之前的转换算子的调用,rdd调用转换算子返回的还是rdd对象,如果调用行动算子返回的是scala对象,只有rdd才可以调用spark中的转换或者行动算子
reduce
:通过func函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据
collect
:在驱动程序中,以数组的形式返回数据集的所有元素
count
:返回RDD中元素的个数
first
:返回RDD中的第一个元素
take
:返回一个由RDD的前n个元素组成的数组
takeOrdered(n)
:返回该RDD排序后的前n个元素组成的数组
aggregate
:
参数:(zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)
作用:aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。
fold(num)(func)
:折叠操作,aggregate的简化操作,seqop和combop一样,将所有元素相加得到结果.
saveAsTextFile(path)
:对应读取文件的方法,Spark将会调用toString方法,将它装换为文件中的文本。
saveAsSequenceFile(path)
:将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
saveAsObjectFile(path)
:用于将RDD中的元素序列化成对象,存储到文件中。
countByKey()
:针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
foreach(func)
:对每个元素进行打印