XML简要教程
XML 指可扩展标记语言(eXtensible Markup Language), 被设计用来传输和存储数据。是各种应用程序之间进行数据传输的最常用的工具。
XML提供了一套夸平台,跨网络,跨应用程序的语言的描述方式。使用XML可以方便的实现数据交换,系统配置,内容管理等。
XML 可被类似记事本这样的简单的文本编辑器来创建和编辑。不过,在您开始使用 XML 进行工作时,您很快会发现,使用一款专业的 XML编辑器来编辑 XML 文档会更好,它能:为开始标签自动添加结束标签,强制您编写合法的 XML 等等。XMLSpy就是一款比较好的 XML 编辑器。
XML文件怎么打开
1.用EXCEL打开。
2.用浏览器如IE就可以打开的,按照源文件样式显示。
3.有能力处理纯文本的软件都可以编辑XML文件。
一个例子test.xml
(提示:若window平台的记事本建立,要注意编码,后面将详细介绍):
<?xml version=”1.0″ encoding=”GB2312″?>
<softCompany>
<company>MicroSoft</company>
<company>google</company>
<company>Apple</company>
<company>百度</company>
</softCompany>
XML
允许用户定义自己的标签
。XML文件有且仅有一个根标签,其它标签都是这个根标签的子孙标签。XML文件中的标签,分为开始标签和结束标签,如<a>和</a>,成为一对。一对标签内的空格和换行都作为原始内容被处理。下面的(1)和(2)是不同的
(1)<b>呵呵</b>
(2)<b>呵
呵</b>
一个标签中也可以嵌套若干子标签。但所有标签必须合理的嵌套,绝对不允许交叉嵌套 ,例如:
错误的写法:<a>呵呵 <b>哈哈</a></b>
XML
标签可以包含字母、数字以及其它一些可见字符,但必须遵守下面的一些
规范
:
标签区分大小写,例如,<P>和<p>是两个不同的标记。
不能以数字或”_” (下划线)开头。
不能以xml(或XML、或Xml 等)开头。
不能包含空格。
名称中间不能包含冒号(:)
一个标签可以有多个属性,每个属性都有它自己的名称和取值,例如: <input name=“text”> ,属性值一定要用双引号(”)或单引号(’)引起来,定义属性必须遵循与标签相同的命名规范 。
在XML技术中,标签属性所代表的信息,也可以被改成用子元素的形式来描述,例如:
<input>
<name>text</name>
</input>
xml文件中的
注释
采用: <!–注释–> 格式。
注意:XML声明之前不能有注释;注释不能嵌套。
最简单的声明语法: <?xml version=”1.0″ ?>
当XML文件中有中文时,用encoding属性说明文档的字符编码,如:<?xmlversion=”1.0″ encoding=”GB2312″ ?> 或<?xml version=”1.0″ encoding=”UTF-8″ standlone=”yes”?>
顺序不能弄错,当XML文件中有中文时,必须使用encoding属性指明文档的字符编码,例如:encoding=”GB2312″或者encoding=”utf-8″,并且在保存文件时,也要以相应的文件编码来保存,否则在使用浏览器解析XML文件时,就会出现解析错误的情况。字符集属性encoding是可选的,默认值是UTF-8。standlone也是可选的,值只能是yes或no,若值是”yes” 表示没有呼叫外部文件,若值是”no” 则表示有呼叫外部文件。默认值是“yes”。(详见附录)
如果我们使用“记事本”或者“EditPlus”等文本编辑工具编写XML文件时,当我们在保存文件时,文件的编码默认是以“ANSI”来保存的,如下图)所示:
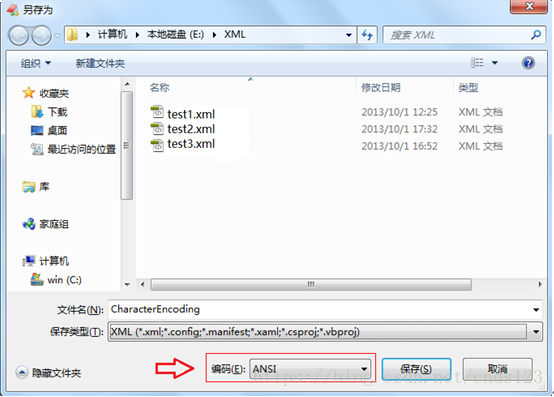
若编写XML文件时,使用encoding=”utf-8″来指明了文档的字符编码,但是在保存的时候却使用了“ANSI”编码来保存文件,打开时解析失败,请记住,使用“记事本”或者“EditPlus”等文本编辑工具编写XML文件时一定要以XML文件的encoding属性指明的编码来保存文件。
使用一些比较智能的IDE编写XML文件时,IDE在保存XML文件时,会自动以encoding属性指明的编码来保存文件。
处理指令
,简称PI(processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。例如,在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用css文件显示xml文档内容,标签名为中文时,css不起作用。
<?xml-stylesheet type=”text/css” href=”css文件名.css”?>
例如,
test2.xml
:
<?xml version=”1.0″ encoding=”utf-8″?>
<!–在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用country.css文件显示xml文档内容–>
<?xml-stylesheet type=”text/css” href=”country.css”?>
<Country>
<c1>中国</c1>
<c2>美国</c2>
<c3>俄罗斯</c3>
<c4>巴基斯坦</c4>
</Country>
country.css
样式文件代码如下:
c1{
font-size:200px;
color:red;
}
c2{
font-size:150px;
color:green;
}
c3{
font-size:100px;
color:#ccc;
}
c4{
font-size:130px;
color:blue;
}
用浏览器打开test2.xml,显示:
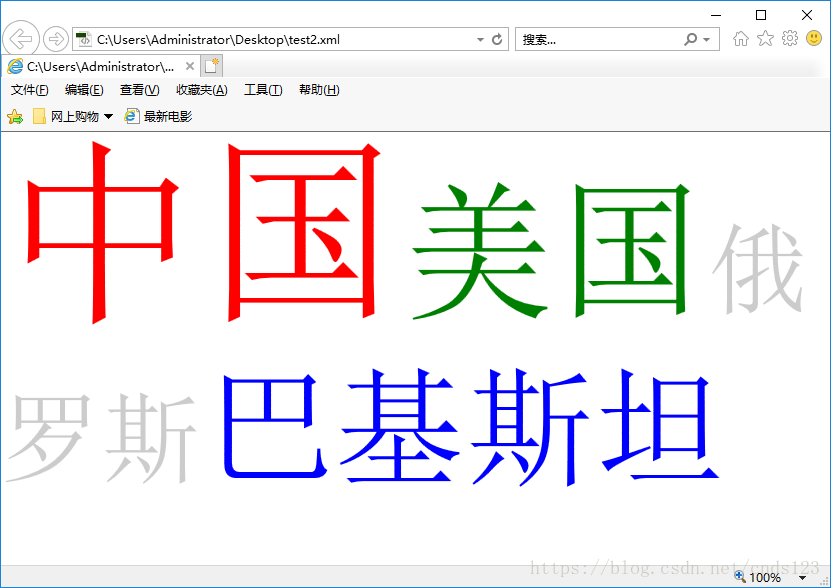
在编写XML文件时,有些内容可能不想让解析引擎解析执行,而是当作原始内容处理,遇到此种情况,可以把这些内容放在CDATA区里,对于CDATA区域内的内容,XML解析程序不会处理,而是直接原封不动的输出。
语法:<![CDATA[ 内容 ]]>
例如,test3.xml :
<?xml version=”1.0″ encoding=”utf-8″?>
<soft>
<![CDATA[
<a className=”gacl.xdp”>
<a1>gacl</a1>
<a2>xdp</a2>
</a>
]]>
<b>
<b1>中国</b1>
<b2>美国</b2>
</b>
</soft>
用EXCEL打开XML文件:
法一、新建一个空白的excel文件,将该xml文件,拖动到excel文件中,参见下图
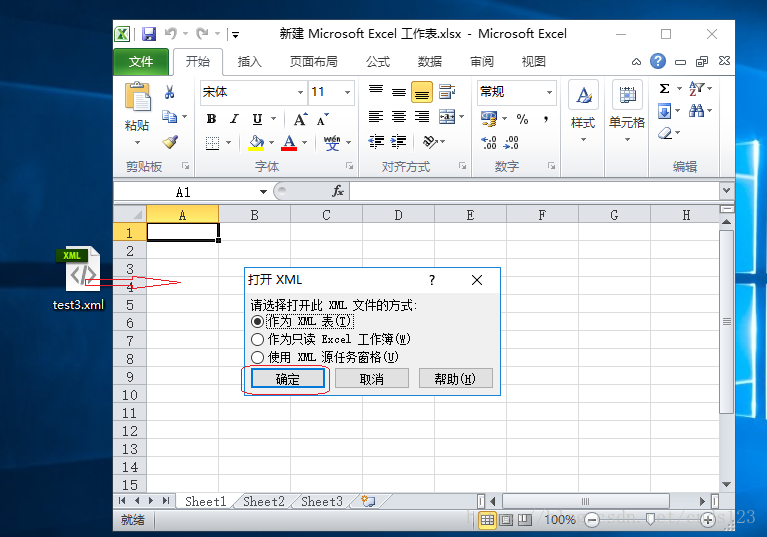
单击“确定”按钮,显示如下图
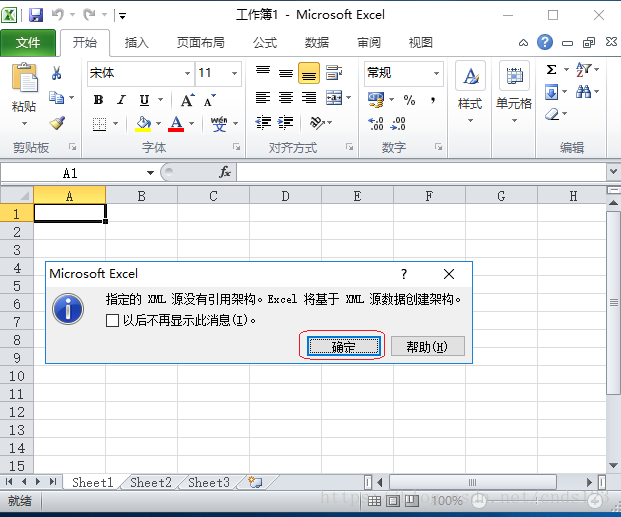
再次单击“定”按钮,完成,显示如下图
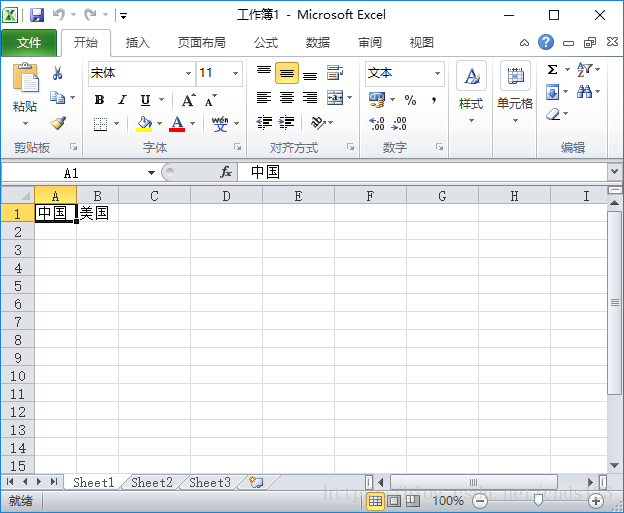
法二、打开Excel,再按下图步骤进行单击
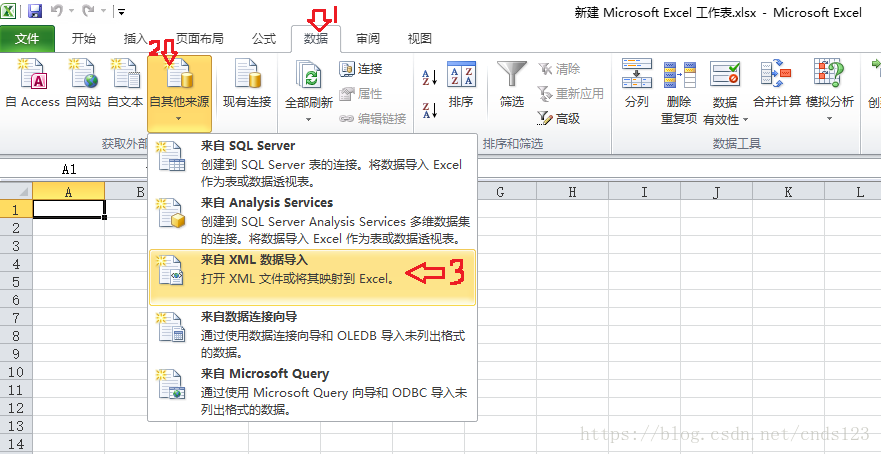
出现如下图对话框
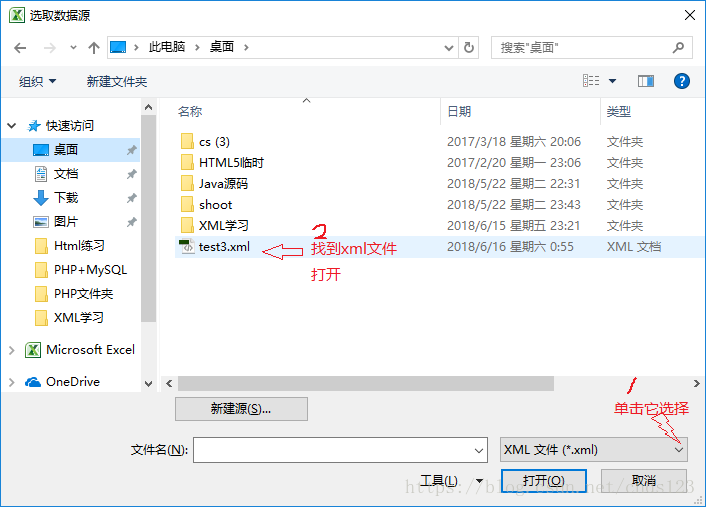
图步骤进行单击,
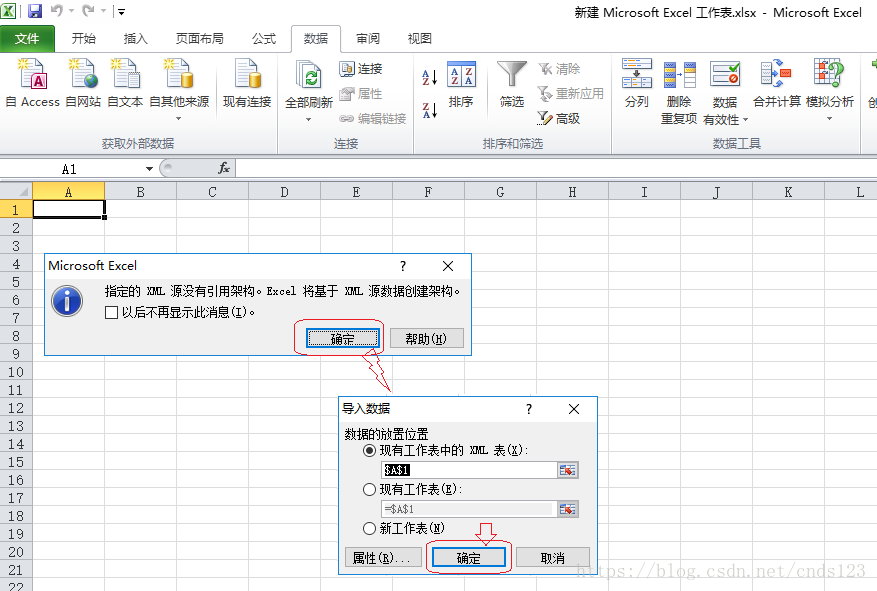
显示结果
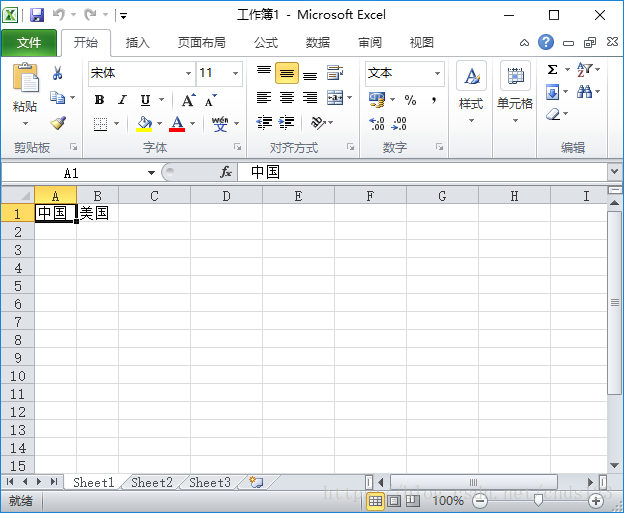
转义字符表:
对于一些特殊字符,若想显示其原始样式,也可以使用转义的形式予以处理。
例如:
<?xml version=”1.0″ encoding=”utf-8″?>
<soft>
<b>
<b1>特殊符号</b1>
<b2>验证</b2>
</b>
</soft>
用浏览器打开结果如下图
standalone
在
XML
里的作用
standalone 用来表示该文件是否呼叫其它外部的文件。若值是”yes” 表示没有呼叫外部文件,若值是”no” 则表示有呼叫外部文件。默认值是“yes”。
这里所指的外部文件其实就是查检XML是不是有效的约束文件,或是DTD或是Schema,那这两者又有什么区别呢?
尽管XML1.0提供了一种机制,即文档类型定义(DTD,Document Type Definition)来规范XML的格式规则。但是它天生存在一些缺点,比如,它采用了非XML的语法规则、不支持更多的数据类型、扩展性差等,为了克服这些缺点,XSD(XML Schema Definition)出现了。W3C推荐在XML中使用XSD来代替DTD。
XSD(XML Schema Definition,XML模式定义)跟DTD一样,也用于定义 XML 文档的约束。但它与DTD明显不同的是,XSD遵循XML语法规则,更好地支持数据类型以及命名空间。W3C称:XML Schema is an XML based alternative to DTD。模式在单独的文件中定义,通常扩展名为 .xsd。每个模式定义都有一个根元素 schema,该元素属于名称空间。schema 元素可以包含可选的属性。
比如:
<xs:schema xmlns:xs=http://www.w3.org/2001/XMLSchema
elementFormDefault=”qualified” attributeFormDefault=”unqualified”>
这表示模式中使用的元素来自名称空间。
XML 文件使用 schema 名称空间中的schemaLocation 属性链接到对应的模式。使用schemaLocation 属性必须定义 schema 名称空间。所有这些定义都出现在 XML 文档的根元素中。
语法如下:
<root_element schema_namespace_definition schema_location_definition>
下面是一个例子:
<Books xmlns:xs=” Books.xsd”>
先来看看一个XML文件示例(message.xml),分别用DTD和XSD 描述这个文件,看看它们之间的区别:
1、使用DTD:
<?xml version=”1.0″ standalone=”yes”?>
<!DOCTYPE message[
<!ELEMENT message (to,from,body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT body (#PCDATA)>
]>
<message>
<to>rose</to>
<from>alex</from>
<body>Hi,My Girl!</body>
</message>
2、使用XSD(XML Schema Definition):
message.xml:
<?xml version=”1.0″ standalone=”no”? >
<message xmlns=http://www.example.com
xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance
xsi:schemaLocation=” message.xsd”>
<to>Rose</to>
<from>Alex</from>
<body>Hi,My Girl!</body>
</message>
message.xsd:
<?xml version=”1.0″?>
<xs:schema xmlns:xs=http://www.w3.org/2001/XMLSchema
targetNamespace=http://www.example.com
xmlns=”” elementFormDefault=”qualified”>
<xs:element name=”message”>
<xs:complexType>
<xs:sequence>
<xs:element name=”to”type=”xs:string”/>
<xs:element name=”from”type=”xs:string”/>
<xs:element name=”body”type=”xs:string”/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sch
有了上述基础,想进一步学习,就比较容易啦。
XML基础小结
XML(Extensible Markup Language:可扩展标记型语言)xml 主要用途:用来存储数据,体现在作配置文件,或者充当小型数据库,在网络中传输数据。
特别提示:XML被设计为“什么都不做”,XML数据或XML文档只用于组织、存储数据,除此之外的数据生成、读取、传送、存取等等操作都与XML本身无关!
xml文档的后缀名为 .xml。xml代码区分大小写。
XML 文档形成一种树结构
XML 文档必须包含
根元素
。该元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有元素均可拥有子元素。

上图表示下面的 XML 中的一本书:
<bookstore>
<book category=”CHILDREN”>
<title lang=”en”>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category=””>
……
</book>
</bookstore>
xml语法
(1) 文档声明
创建一个xm文件后,第一步就是 必须要有 一个文档声明(写了文档声明之后,表写xml文件的内容)
<?xml version=”1.0″ encoding=”utf-8″ standalone=”no”?>
说明:
-
version
: xml版本,必须写 -
encoding
:xml编码 常见编码: GBK、UTF-8、ISO8859-1(不包含中文)- 保存时编码和设置打开时候的编码需要一致,否则会出现乱码
-
standalone
:standalone表示该xml是不是独立的yes/no,缺省是no。如果是yes,则表示这个XML文档时独立的,不能引用外部的DTD规范文件;如果是no,则该XML文档不是独立的,表示可以引用外部的DTD规范文档。
(2) 标签的定义
标签(标记,也称为元素)是根据实际需要定义的。
注意事项
:
- 有始有终:<person></peoson>
- 合理嵌套:<aa><bb></bb></aa>
- 空格和换行均当做内容来解析,所以可能我们需要注意一些缩进的问题
- 不能交叉嵌套
名称规则
:
- xml 代码区分大小写
- 名称不能以数字或者标点符号开始
- 不能以 xml、XML、Xml等开头
- 不能包含空格和冒号
(3) 属性的定义
- 一个标签上可有多个属性 <person id1=”aaa” id2=”bbb”></person>
- 属性名称和值之间使用 = 连接,属性值用引号包起来(单引号和双引号都可以)
属性的命名规范也是和XML元素一样的。
(4) 注释
<?xml version=”1.0″ encoding=”UTF-8″?>
<!– xml注释 –>
注释不能嵌套,并且不能放到第一行,第一行必须方式文档声明
(5) 特殊字符
如果想在xml中输入特殊字符,需要对字符进行转义,因为 < 等会被当做标签
|
|
|
|
|
& |
& |
和 |
|
< |
< |
小于号 |
|
> |
> |
大于号 |
|
” |
” |
双引号 |
|
‘ |
‘ |
单引号 |
若多个字符都需要转义,则可以将这些内容存放到
CDATA里面
<![CDATA[ 内容 ]]>
对于CDATA内的内容,XML解析程序不会处理,而是当作原始内容处理。
(七) PI指令
(processing instruction处理指令)
可以在xml中使用xml-stylesheet指令应用css文件设置样式
<?xml-stylesheet type=”text/css” href=”css的路径”?>
XML解析方式
XML解析方式分为两种:
☆dom(Document Object Model)文档对象模型,是W3C组织推荐解析XML的一种方式。
☆sax(Simple API For XML),它是XML社区的标准,几乎所有XML解析器都支持它!
dom解析和sax解析区别:
dom方式解析:根据xml的层级结构在内存中分配一个树形结构,把xml的标签,属性和文本都封装成对象。
* 优点:元素与元素之间保留结构关系,很方便实现增删改操作
* 缺点:如果文件过大,可能造成内存溢出
sax方式解析:采用事件驱动,边读边解析,从上到下,一行一行的解析,解析到某一个对象,返回对象名称,当SAX解析结束,不会保存任何XML文档的数据。
* 优点:处理速度快,可以处理大文件,不会造成内存溢出,方便实现查询操作
* 缺点:不能实现增删改操作
XML文档也是数据的一种,对数据的操作也不外乎是“增删改查”。也被大家称之为“CRUD”:
C:Create
R:Retrieve
U:Update
D:Delete
可以使用记事本编辑XML文件,为了工作效率,建议您使用一款智能的 XML 编辑器,如XMLSpy。
Python 对XML的解析
python有三种方法解析XML:SAX,DOM和ElementTree。
☆DOM(Document Object Model)
DOM的解析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后利用DOM提供的不同函数来读取该文档的内容和结构,也可以把修改过的内容写入XML文件。由于DOM是将XML读取到内存,然后解析成一个树,如果要处理的XML文本比较大的话,就会很耗内存,所以DOM一般偏向于处理一些小的XML,(如配置文件)比较快。
☆SAX(simple API for XML)
Python标准库中包含SAX解析器,SAX是用的是事件驱动模型,通过在解析XML过程
中触发一个个的事件并调用用户定义的回调函数来处理XML文件。使用import xml.sax引入。
解析的基本过程:
读到一个XML开始标签,就会开始一个事件,然后事件就会调用一系列的函数去处理
一些事情,当读到一个结束标签时,就会触发另一个事件。所以,我们写XML文档入
如果有格式错误的话,解析就会出错。
这是一种流式处理,一边读一边解析,占用内存少。适用场景如下:
1、对大型文件进行处理;
2、只需要文件的部分内容,或者只需从文件中得到特定信息。
3、想建立自己的对象模型的时候。
☆ElementTree(元素树)
ElementTree就像一个轻量级的DOM,具有方便友好的API。代码可用性好,速度快,消耗内存少。使用import xml.etree.ElementTree引入。
附
、深入解读Python解析XML的几种方式
https://www.jb51.net/article/79494.htm