linux内存分配
缺页中断
什么是缺页中断,简单来说是因为操作系统采用了虚拟内存技术,程序代码/数据对应的内容并不一定是完全读入到内存中,在使用到时候发生缺页中断将对应的内容读入到内存中。
当一个进程发生缺页中断的时候,进程会陷入内核态,执行以下操作:
- 检查要访问的虚拟地址是否合法
- 查找/分配一个物理页
- 填充物理页内容(读取磁盘,或者直接置0,或者啥也不干)
- 建立映射关系(虚拟地址到物理地址)
- 重新执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页中断就是majflt,否则就是minflt。
如何查看进程发生的缺页中断次数
用ps -o majflt,minflt -C program命令查看。
其中:majflt代表major fault,中文名叫大错误,minflt代表minor fault,中文名叫小错误。
这两个数值表示一个进程自启动以来所发生的缺页中断的次数。
test.cc
#include<stdio.h>
#include<malloc.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
while(1)
{
int* p = (int*)malloc(40);
sleep(10);
}
return 0;
}
test2.cc
#include<stdio.h>
#include<malloc.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
while(1)
{
int* p = (int*)malloc(40);
*p = 20;
sleep(10);
}
return 0;
}
当两个进程运行起来的时候我们观察缺页中断的次数。
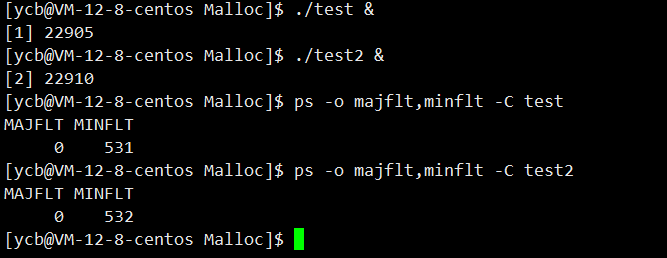
我们可以发现当对申请获得的内存进行写的时候缺页中断次数是多了一次的。这部分的原因在下文解释,此时分配的是虚拟内存,没有分配物理内存。
linux内存分配的原理
从操作系统的角度来看,进程分配内存的原理有两种方式,分别由两个系统调用完成。
-
brk是将数据段(.data)的最高地址指针_edata往高地址推
-
mmap是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存
这两种方式分配的都是虚拟内存,没有分配物理内存
。
在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系
如下图:当我们调用
brk()
的时候,会在虚拟地址空间中将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系)
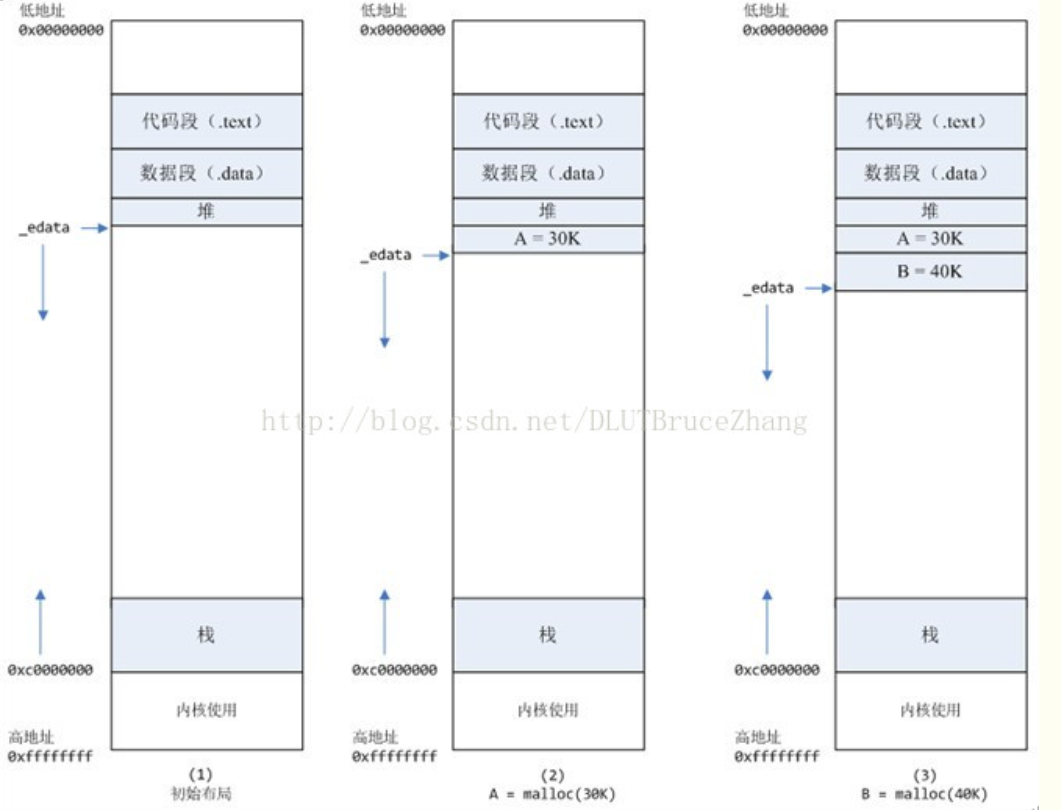
其中,
mmap内存映射文件是在堆和栈的中间
(例如libc-2.2.93.so,其它数据文件等),为了简单起见,省略了内存映射文件。
如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的
(缺页中断中的demo演示)
使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0)
如下图:
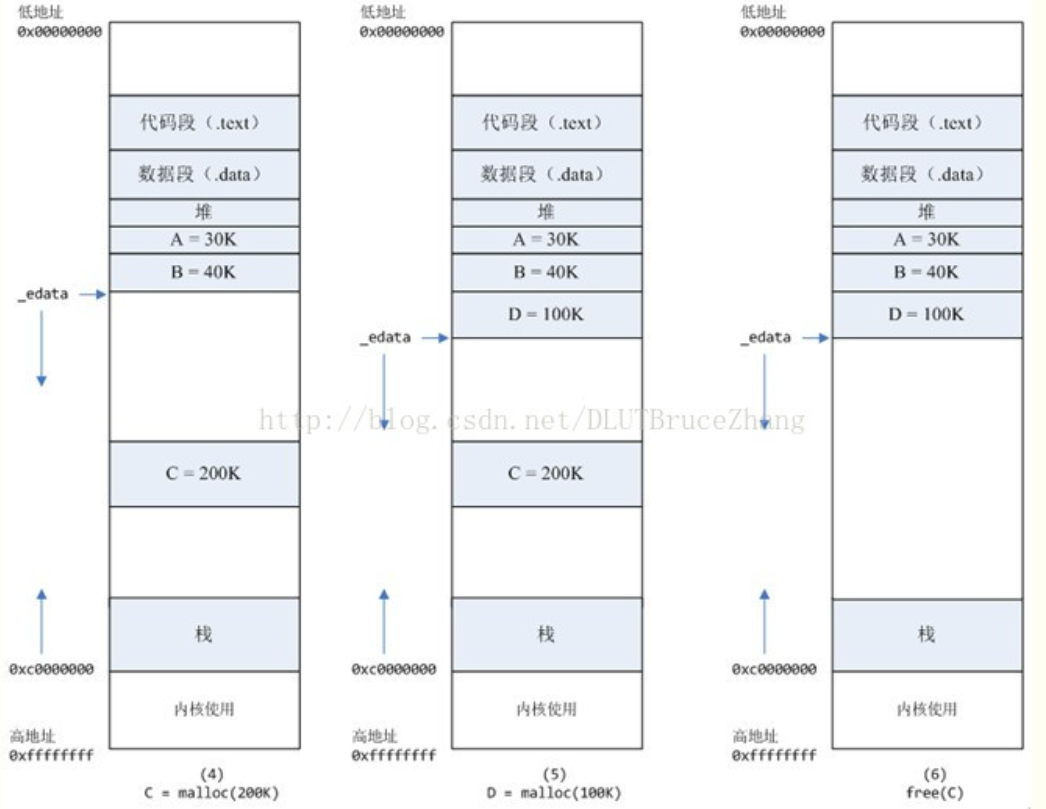
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
进程调用free©以后,C对应的虚拟内存和物理内存一起释放。
进程调用free(B)以后,如图7所示:
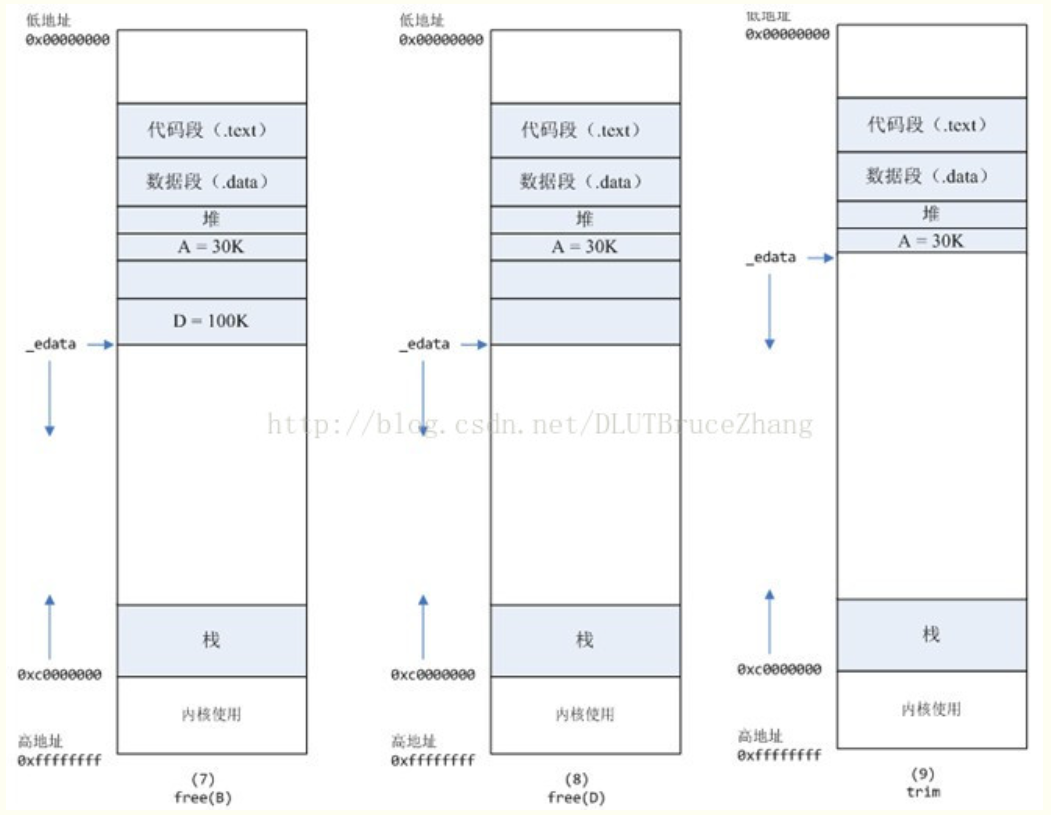
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了。
进程调用free(D)以后,如图8所示:
B和D连接起来,变成一块140K的空闲内存。
malloc()背后的实现原理
malloc()和free()的功能
而在标准C库中,提供了malloc/free函数分配释放内存,这两个函数底层是由brk,mmap,munmap这些系统调用实现的。
那么一种简单的想法是 malloc() 在堆上分配内存的内存管理直接交给系统内核去做。然而每次程序申请或者释放堆空间都要进行系统调用。我们知道系统调用的性能开销是比较大的,当程序对堆的操作比较频繁时,这样做的结果会严重影响程序的性能。
因此我们不会直接通过
brk
或
sbrk
来分配堆内存,而是先通过
sbrk
扩展堆,将这部分空闲内存空间作为
缓冲池
,然后通过
malloc
/
free
管理缓冲池中的内存。这是一种
池化思想
,能够避免频繁的系统调用,提高程序性能。
因此,malloc() 相当于向操作系统“批发”了一块较大的内存空间,然后“零售”给程序用。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。当然 malloc() 在向程序零售堆空间时,必须管理它批发来的堆空间,不能把同一块地址出售两次,导致地址的冲突。于是malloc() 需要一个算法来管理堆空间,这个算法就是堆的分配算法。
malloc()和free()的分配算法
malloc
使用链表管理内存块。
malloc
有多种实现方式,在不同场景下可能会使用不同的匹配算法。比如在很多操作系统书上都写了如最佳适应法,最差适应法,首次适应法,下一个适应法等。而具体的实现过程中都基本离不开链表,比如显式空闲链表 + 整块分配,显式空闲链表 + 按需分配,分离的空闲链表(其中包括简单分离存储,分离适配,伙伴系统,tcmalloc)等等。
其中个人的项目中实现了mini版本的tcmalloc,可以看
项目文档
。
这里学习一下显式空闲链表 + 按需分配的流程。

带阴影的方框是已被分配的内存,白色方框是空闲内存或已被释放的内存。程序需要内存时,malloc() 首先遍历空闲区域,看是否有大小合适的内存块,如果有,就分配,如果没有,就向操作系统申请(发生系统调用)。
为了保证分配给程序的内存的连续性,malloc() 只会在一个空闲区域中分配,而不能将多个空闲区域联合起来。
可以发现,光是内存是没法组织和管理的。要想进行组织和管理必须要先描述再组织,描述定义内存块,并且在内存块的首部创建对象从而进行组织管理。(先描述,再组织)
内存块(包括已分配和空闲的)的结构类似于链表,它们之间通过指针连接在一起。在实际应用中,一个内存块的结构如下图所示:
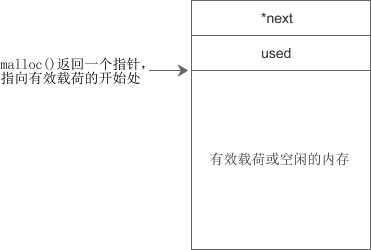

现在假设需要为程序分配100个字节的内存,当搜索到图中第一个空闲区域(大小为200个字节)时,发现满足条件,那么就在这里分配。这时候 malloc() 会把第一个空闲区域拆分成两部分,一部分交给程序使用,剩下的部分任然空闲,如下图所示:

以原来的图为例,当程序释放掉第三个内存块时,就会形成新的空闲区域,free() 会将第二、三、四个连续的空闲区域合并为一。

另外,由于单向链表只能向一个方向搜索,在合并或拆分内存块时不方便,所以大部分 malloc() 实现都会在内存块中增加一个 pre 指针指向上一个内存块,构成双向链表,如下图所示:
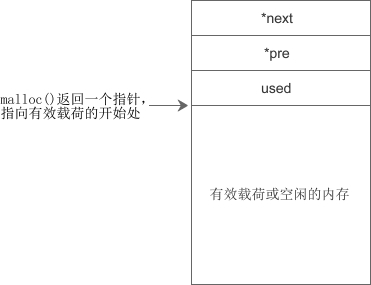
但是我们可以看到,操作系统课本上讲的这些方法其实效率都不高。
- 一旦链表中的 pre 或 next 指针被破坏,整个堆就无法工作,而这些数据恰恰很容易被越界读写所接触到。
- 小的空闲区域往往不容易再次分配,形成很多内存碎片。
- 经常分配和释放内存会造成链表过长,增加遍历的时间。
主要存在的是两个问题,一个是效率问题,另一个是内存碎片问题。
因此实际上具体实现并不采用这样的原生方法,通常采用内存池来解决。malloc其实就是一个通用的内存池,什么场景下都可以用,但是什么场景下都可以用就意味着什么场景下都不会有很高的性能。其中google家实现了tcmalloc用于实现高并发场景下的内存池。C++中的STL中的容器申请内存实际上也是从内存池申请的。而其中这几者的内存池结构和框架都是类似的,学习了其中一个之后基本可以触类旁通。个人的项目中学习实现了mini版本的tcmalloc,可以看
项目文档
。
参考资料