英文词频统计
以下代码为英文的词频统计,其中article为我们要统计词频的文章。
article='''Last sunday, it was a fine day. My friend and I went to Mount Daifu.
In the morning, we rode bikes to the foot of the mountain. After a short rest, we climbed the mountain. on its peak, we shared the beautiful scenery in our eyes. There were lots of light foggy clouds around us. What's more, varieties of birds flying around us were pretty. What a harmony situation! At noon, we had lunch in a restaurant. With a happy emotion, we finished our climbing. Although tired, we still felt happy and relaxed. we hope our country will become more and more beautiful.
'''
#替换标点符号,将文章中所有的标点符号全部去掉
article=article.replace(',','').replace('.','').replace(';','').replace(':','').replace('?','')
#大写字母转换为小写字母
exchange=article.lower()
#生成单词列表,split函数会将文章按照空格切割开来,生成一个列表
list=exchange.split()
print(list)
#生成词频统计,这里我们用字典类型统计词频
dict={}
for my_key in list:
count=list.count(my_key)
dict[my_key]=count
print(dict)
#排序
dict_sorted=sorted(dict.items(),key=lambda x:x[1],reverse=True)
print(dict_sorted)
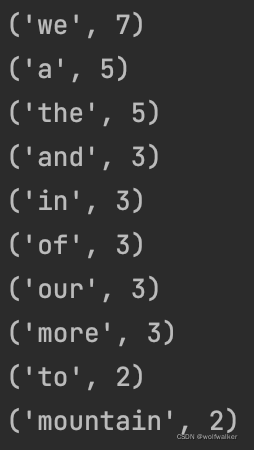
#输出词频最大的前十位
for i in range (10):
print(dict_sorted[i])
中文词频统计
对中文进行词频统计,我们需要安装jieba的包。其统计方法和原理大致和英文相同
import jieba
article='''气候原因也为此次搜救增加了难度,第四次发布会上,广西消防救援总队总队长郑西表示,连日来藤县地区连续降雨,给现场救援增加了不少难度。一是降雨造成了事故核心区域的积水;截至发稿时,MU5735的搜寻援救行动已经持续了超过72小时。3月24日,广西消防救援总队作战训练处副处长黄尚武在接受央视采访时表示,目前救援队伍的任务以搜救生命为主,使用了热成像仪、生命探测仪进行表层搜索,但是由于天气原因,搜寻仪器的信号相对较弱,因此采用人工搜索和空中无人机搜索配合'''
article=article.replace(',','').replace('。','').replace(';','').replace(':','').replace('?','')
#调用jieba包中的lcut方法将整个文本切割成不同的词组
list=jieba.lcut(article)
print(list)
dict={}
#统计词频,将每个单词出现的次数统计到dict字典中
for my_key in list:
count=list.count(my_key)
dict[my_key]=count
print(dict)
#排序,此处的x[1]表示取出来的是键值对后面的值,reverse=TRUE表示降序排序
dict_sorted=sorted(dict.items(),key=lambda x:x[1],reverse=True)
print(dict_sorted)
#输出词频最大的前十位
for i in range (10):
print(dict_sorted[i])
版权声明:本文为weixin_62684026原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。