Hadoop测试:
linux下Hadoop安装与环境配置(附详细步骤和安装包下载)
按照上一篇文章安装完Hadoop集群之后,启动hdfs文件系统及yarn资源管理器(也可通过start-dfs.sh和start-yarn.sh完成):
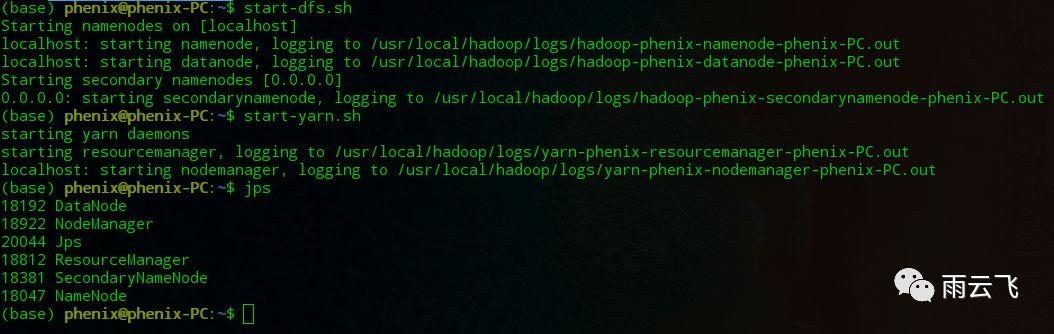
start-all.sh之后通过jps查看是否成功:
jps成功之后如下图:
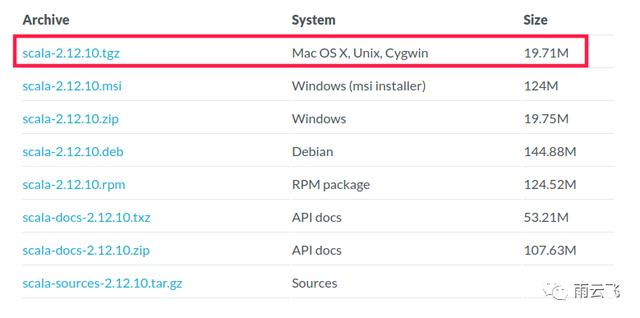
点击链接https://www.scala-lang.org/download/2.12.10.html,下载对应版本scala(本文选择scala 2.12.10):
下载好后解压到:/usr/local/
sudo tar zxvf ~/Downloads/scala-2.12.10.tgz -C /usr/local/删除安装包:
rm ~/Downloads/scala-2.12.10.tgz进入到减压目录并重命名:
cd /usr/local/sudo mv scala-2.12.10 scal配置环境变量:
sudo vim /etc/profile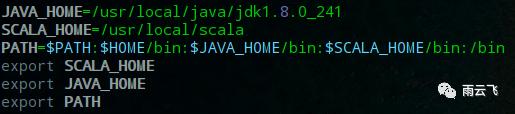
执行source命令并测试:
source /etc/profilescala -version
spark安装:
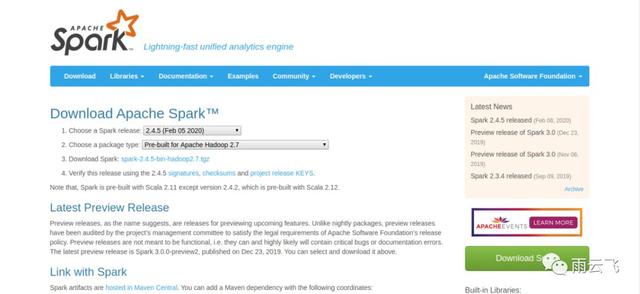
点击链接 http://spark.apache.org/downloads.html 进行下载(本文选择2.4.4版本):
下载好后解压至/usr/local/:
sudo tar zxvf ~/Downloads/spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local删除安装包:
rm spark-2.4.4-bin-hadoop2.7.tgz 进入到解压目录并重命名:
cd /usr/local/sudo mv spark-2.4.4-bin-hadoop2.7 spark
配置环境:
sudo vim /etc/profile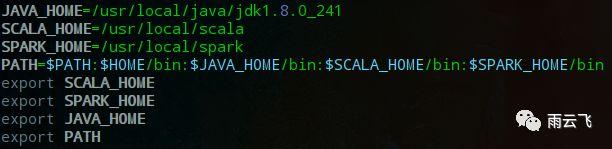
执行source更新命令:
source /etc/profile配置spark-env.sh:
进入到配置目录并打开spark-env.sh文件:
cd spark/confcp spark-env.sh.template spark-env.shvim spark-env.sh添加以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_241export HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SCALA_HOME=/usr/local/scalaexport SPARK_HOME=/usr/local/sparkexport SPARK_MASTER_IP=127.0.0.1export SPARK_MASTER_PORT=7077export SPARK_MASTER_WEBUI_PORT=8099export SPARK_WORKER_CORES=3export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=5Gexport SPARK_WORKER_WEBUI_PORT=8081export SPARK_EXECUTOR_CORES=1export SPARK_EXECUTOR_MEMORY=1Gexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native配置slaves:
cp slaves.template slavesvim slaves注:我们会发现slaves文件里为localhost即本机地址,当前为伪分布式,因此不用修改
启动sbin目录下的start-master.sh以及start-slaves.sh(前提是hadoop已启动):
cd /usr/local/spark/./sbin/start-master.sh./sbin/start-slaves.sh通过jps命令会发现多出worker一项
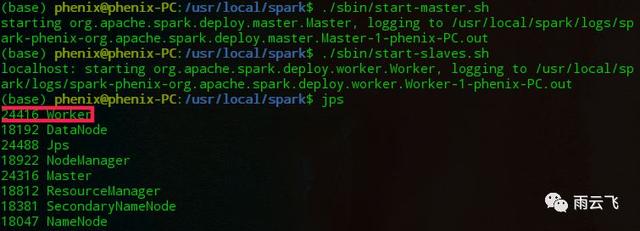
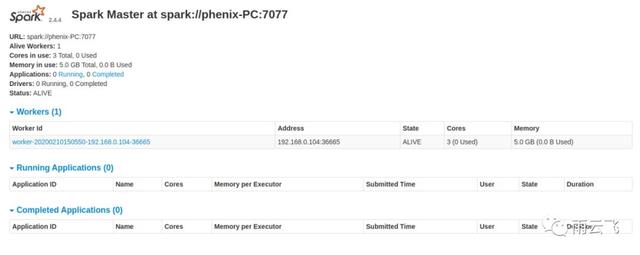
通过spark的web界面 http://127.0.0.1:8099/ 可以查看spark集群当前概况:
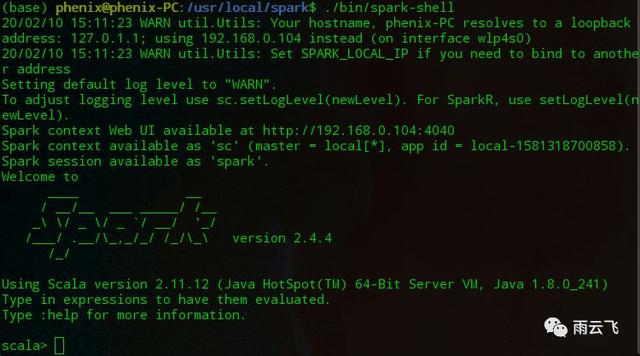
启动bin目录下的spark-shell:
./bin/spark-shell即会出现spark scala的命令行执行环境:
同时我们还可通过spark-shell的web管理界面进行任务可视化监控:
同时,也为了方便可以修改Bash环境变量配置:
vim /etc/bash.bashrc添加相应环境变量:
export SPARK_HOME=/usr/local/sparkexport PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH执行source更新命令:
source /etc/bash.bashrc至此linux环境下Hadoop与Spark安装结束,下回将对这些框架的使用做进一步的介绍。