
引言
pandas中的
read_html()
函数是将HTML的表格转换为DataFrame的一种快速方便的方法,这个函数对于快速合并来自不同网页上的表格非常有用。 在合并时,不需要用爬虫获取站点的HTML。但是,在分析数据之前,数据的清理和格式化可能会遇到一些问题。在本文中,我将讨论如何使用pandas的
read_html()
来读取和清理来自维基百科的多个HTML表格,以便对它们做进一步的数值分析。
基本方法
在第一个例子中,我们将尝试解析一个表格。这个表格来自维基百科页面中明尼苏达州的政治部分(
https://en.wikipedia.org/wiki/Minnesota)
。
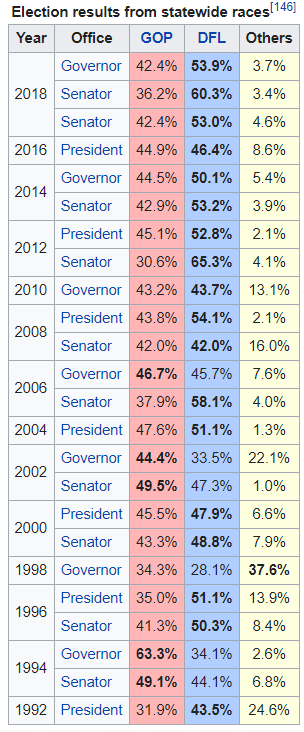
read_html
的基本用法非常简单,在许多维基百科页面上都能运行良好,因为表格并不复杂。首先,要导入一些库 ,在后面的数据清理中都会用到:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from unicodedata import normalize
table_MN = pd.read_html('https://en.wikipedia.org/wiki/Minnesota')
特别注意,上面代码中得到的
table_MN
是页面上所有表格的列表:
print(f'Total tables: {len(table_MN)}')
Total tables: 38
很难在38张表格中找到你需要的那张,要想容易地找出来,可以设置
match
参数,如下面的代码所示,用
mathch
参数指明要选择标题为“Election results from statewide races”的那张表格。
table_MN = pd.read_html('https://en.wikipedia.org/wiki/Minnesota', match='Election results from statewide races')
len(table_MN)
# 输出
1df = table_MN[0]
df.head()输出:
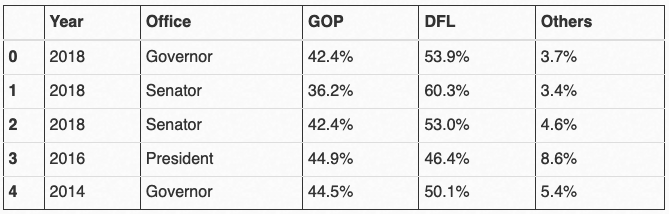
显然,用Pandas能够很容易地读取到了表格,此外,从上面的输出结果可以看出,跨多行的
Year
列也得到了很好地处理,这要比自己写爬虫工具专门收集数据简单多了。
总的来说,这样的操作看起来还不错,然而,如果用
df.info()
来查看数据类型:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 24 entries, 0 to 23
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year 24 non-null int64
1 Office 24 non-null object
2 GOP 24 non-null object
3 DFL 24 non-null object
4 Others 24 non-null object
dtypes: int64(1), object(4)
memory usage: 1.1+ KB
如果想对这些数据进行分析,需要将
GOP
、
DFL
和其他类型为
object
的列转换为数值。
如果这么操作:
df['GOP'].astype('float')
系统就会报错:
ValueError: could not convert string to float: '42.4%'
最有可能的罪魁祸首是
%
,下面用pandas的
replace()
函数删除它。
df['GOP'].replace({'%':''}, regex=True).astype('float')