1.sqoop介绍
sqoop是一个开源工具,数据搬运工,
企业中一般运用大数据存储和关系型存储两种存储方式,但是数据的交互是个问题,故有了sqoop(sql–hadoop或Hadoop–sql)
用户可以将数据从结构化存储器抽取到Hadoop中,用于进一步的处理,抽取的数据可以被mapreduce程序使用,也可以被其他类似与Hive、HBase的工具使用
sqoop是连接关系型数据库和hadoop的桥梁,主要有两个方面(导入和导出):
A.将关系型数据库的数据导入到Hadoop及其相关的系统中,如Hive和HBase
B.将数据从Hadoop系统里抽取并导出到关系型数据库。

2、sqoop安装
sqoop不属于分布式软件
下载安装包:
https://sqoop.apache.org/
sqoop属于相对稳定的开源软件,版本更新较少,本教程采用sqoop-1.4.6
软件上传目录:node1机器 /export/software
软件安装目录: node1机器 /export/server
上传成功
1)解压安装
(可选操作)文件名较长,重命名
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz sqoop-1.4.6.tar.gz
将其解压安装到 /export/server 实现源文件与安装目录分隔
tar -zxvf sqoop-1.4.6.tar.gz -C ../server
进入server文件夹查看解压是否完成

注解:狗头.jpg 这里解压后的文件名还是原文件名,所以各位小白希望该名称的可以解压后改,这里特地做了一次错误示范,解压前只能改压缩包名称,不能控制解压后文件名称,这里可以再重命名一次
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6

3、配置文件
进入sqoop-1.4.6,查看了解目录结构,其目录结构同其他大数据软件类似
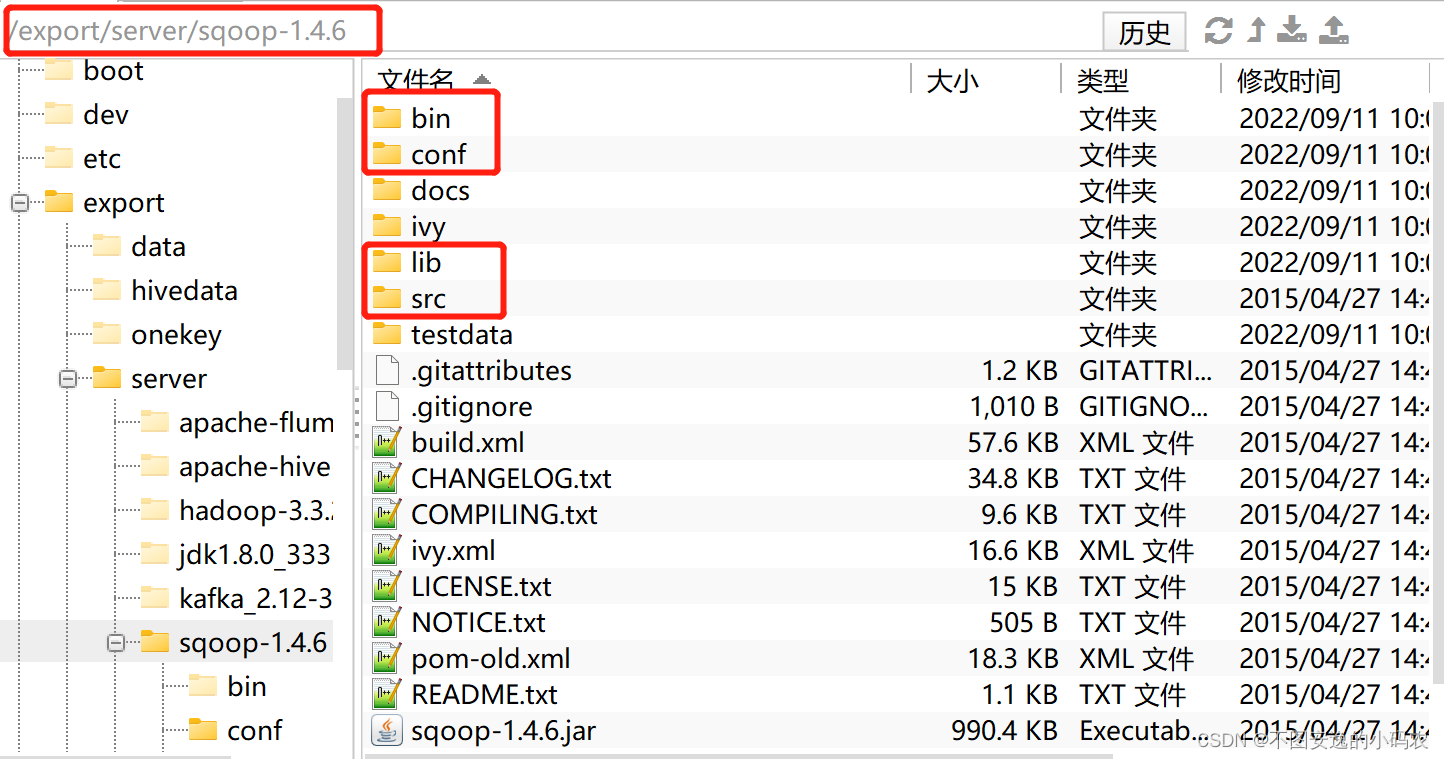
进入conf文件夹

主要配置sqoop-env.sh文件,其他几款大数据软件,如Kafka都是先给示例文件,可以直接改名或复制
以下二选一
#原文件不变,新复制一份操作,我的习惯
cp sqoop-env-template.sh sqoop-env.sh
#原文件改名,直接操作
mv sqoop-env-template.sh sqoop-env.sh

vim sqoop-env.sh

这里只配置了Hadoop和hive,路径根据自身安装进行填写
另外,sqoop是关系型数据库与Hadoop的数据交互,故需要配置关系型数据库,这里选择MySQL作为示例
之前安装Hive时,曾经替换过其MySQL连接包,到Hive下查看
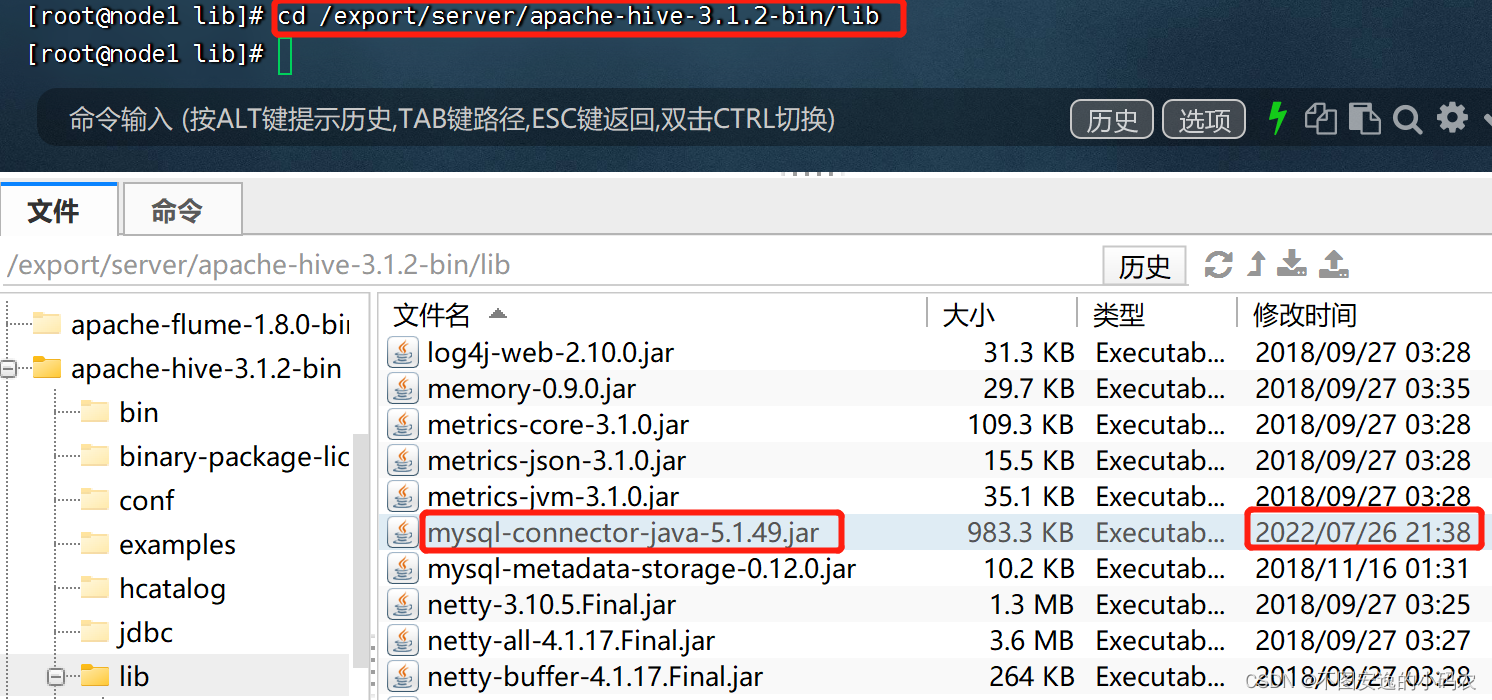
复制一个到sqoop\lib下
cp mysql-connector-java-5.1.49.jar /export/server/sqoop-1.4.6/lib/
4、验证启动
提一点,本次安装没有配置环境变量,运行启动都要到sqoop文件夹下
bin/sqoop list-databases \
--connect jdbc:mysql://localhost:3306/ \
--username root --password hadoop本命令会列出所有node1上的MySQL数据库
换行要记得加 \
数据库用户名、密码都是各位自己设计的
如果使用了分布式Hadoop集群,则连接字符串中不能使用localhost,否则与数据库不在同一台机器上运行的map任务都将无法连接到数据库,建议写主机名或ip,即如下
bin/sqoop list-databases \
--connect jdbc:mysql://node1:3306/ \
--username root --password hadoop

至此,安装并测试完成