1、为什么要使用RocketMQ
RocketMQ是一款分布式、队列模型的消息中间件,支持严格的消息顺序,优点:
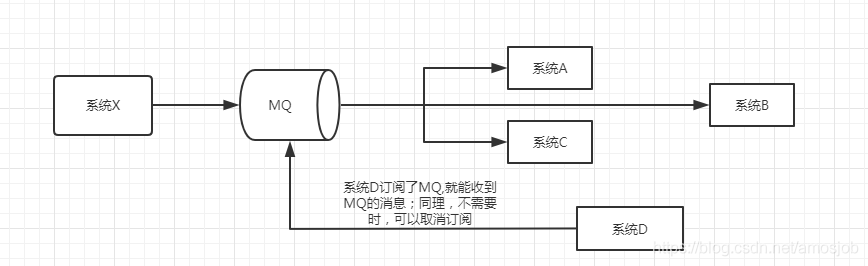
应用解耦:如果系统A、系统B、系统C,都直接依赖于系统X,那么系统之间的耦合度就非常高;如果在系统X之前加上RocketMQ,就实现了系统之间的解耦。
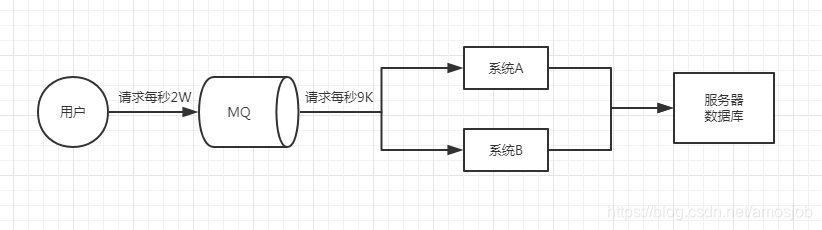
流量削峰:如果用户的每次访问都是直接连接到应用上的话,服务器的承受的访问压力就会非常大,达到服务器的承受上限时就可能会崩溃,同时对服务器的性能也是很大的浪费, 而如果把请求先到MQ,然后应用再到MQ中去拿的话,就能大大缓解服务器的压力,就算访问量再大,只要不大得过MQ的保存上限,应用就能很好的处理用户的请求。
消息分发:如如果好几个模块都需要消费X模块的消息,突然加了一个模块D要加的话,X模块就需要改代码,对接到新加的模块,如果使用MQ的话,则D模块只需要对接MQ即可,至于新加的模块只需要去MQ取即可,不需要再和X模块直接对接了
使用RocketMQ的缺点:
- 系统可用性降低,MQ宕机影响的业务会很多,所有mq需要高可用
- 系统复杂性提高,通过mq调用,怎么保证数据顺序,不重复消费,怎么保证不丢失数据
- 一致性消息,如果应用解耦的情况,流程中的一个部分失败了,如何保证数据一致性
- 消息重复问题,它不能保证不重复,只能保证正常情况下不重复
- 不支持分布式事务
- 消息过滤功能扩展比较单一

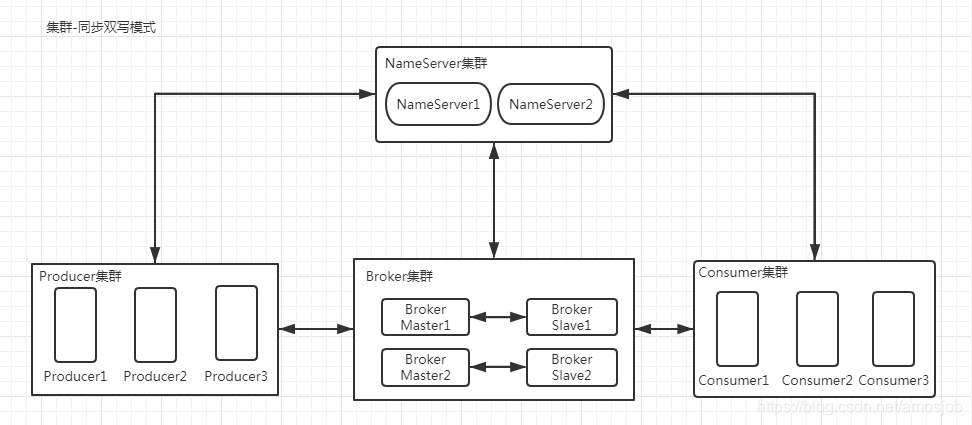
2、RocketMQ集群部署结构
概述:Producer集群作为消息生产者,要发消息给Consumer集群,首先Producer集群和Consumer集群是要把自己的信息注册到NameServer集群的,与此同时,Broker也会把自己的消息注册到NameServer,这样,Producer到消息发送到Broker节点上之后,Broker会到NameServer集群查找到Consumer的目标位置,这样,就能把消息正确的发送给Consumer集群。
详解:
- Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
- Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master,Master与Slave的对应关系通过指定相同的Broker Name,不同的Broker Id来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与Name Server集群中的所有节点建立长连接,定时(每隔30s)注册Topic信息到所有Name Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟没有收到心跳,则Name Server断开与Broker的连接。
- Producer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。Producer每隔30s(由ClientConfig的pollNameServerInterval)从Name server获取所有topic队列的最新情况,这意味着如果Broker不可用,Producer最多30s能够感知,在此期间内发往Broker的所有消息都会失败。Producer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳,Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到心跳数据,则关闭与Producer的连接。
- Consumer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。Consumer每隔30s从Name server获取topic的最新队列情况,这意味着Broker不可用时,Consumer最多最需要30s才能感知。Consumer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳,Broker每隔10s扫描所有存活的连接,若某个连接2分钟内没有发送心跳数据,则关闭连接;并向该Consumer Group的所有Consumer发出通知,Group内的Consumer重新分配队列,然后继续消费。当Consumer得到master宕机通知后,转向slave消费,slave不能保证master的消息100%都同步过来了,因此会有少量的消息丢失。但是一旦master恢复,未同步过去的消息会被最终消费掉。

3. RocketMQ集群模式
1、单Master模式
这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用。不建议线上环境使用,可以用于本地测试。2、多Master模式
一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优缺点如下:优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢),性能最高;
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。3、多Master多Slave模式(同步)
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,即只有主备都写成功,才向应用返回成功,这种模式的优缺点如下:优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
缺点:性能比异步复制模式略低(大约低10%左右),发送单个消息的RT会略高,且目前版本在主节点宕机后,备机不能自动切换为主机。示例:
4、多Master多Slave模式(异步)
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟(毫秒级),这种模式的优缺点如下:优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
缺点:Master宕机,磁盘损坏情况下会丢失少量消息。