kafka MQ软件
数据库:mysql oracle redis mongo ES
MQ: activeMQ RabbitMQ RockectMQ zeroMQ Kafka
kafka介绍
Kafka 是一个分布式流媒体平台 这里的流指的是源源不断的数据
kafka官网:http://kafka.apache.org/
(1)流媒体平台有三个关键功能:
-
发布和订阅记录流
,类似于消息队列或企业消息传递系统。 -
以
容错的持久方式存储记录流
。 kafka中的数据即使消费后也不会消失 - 记录发生时处理流。
(2)Kafka通常用于两大类应用:
-
构建可在
系统或应用程序之间
可靠获取数据的实时流数据管道 - 构建转换或响应数据流的实时流应用程序
1、kafka可以提供和RabbitMq一样的功能
2、Kafka可以处理源源不断产生的数据
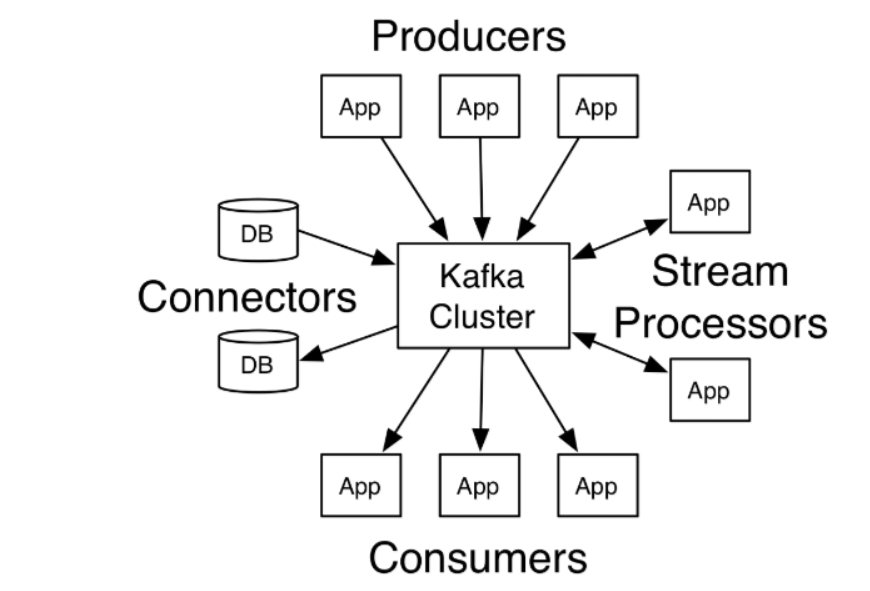
(3)kafka名词解释
- topic:Kafka将消息分门别类,每一类的消息称之为一个主题(Topic 就是Rabbitmq中的queue)
- producer:发布消息的对象称之为主题生产者(Kafka topic producer)
- consumer:订阅消息并处理发布的消息的对象称之为主题消费者(consumers)
- broker:已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
kafka安装
使用docker-compose ,配置
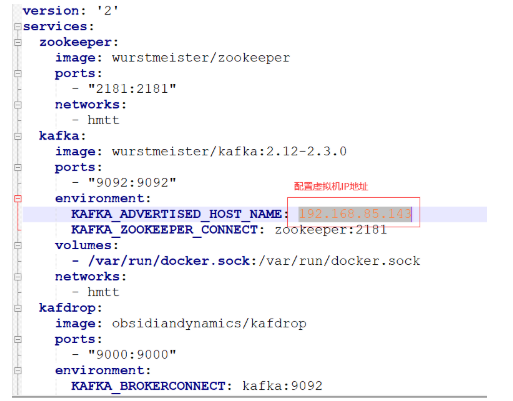
注: 这里修改下kafdrop的端口: 9080:9000, 这里如果用9000会跟minio冲突
启动前先删除之前的kafka容器
# 找到已经存在的容器
docker ps -a
cd /opt/hmtt/kafka
# 删除kafka和zookeeper对应的id
./remove.sh #和其他容器不一样 这里执行的是remove.sh
./start.sh
kafka入门案例
创建工程kafka-demo
创建kafka-demo工程(也可以直接引入资料中的demo),引入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
消息生产者
官方文档:http://kafka.apache.org/21/documentation.html#producerapi
创建类:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CGGxkwMl-1652234020403)(assets/image-20210901094051762.png)]](https://img-blog.csdnimg.cn/2486d40cb4e7496496d0bcde62a483a3.png)
package com.heima.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Map;
import java.util.Properties;
public class ProducerTest {
public static void main(String[] args) {
// 设置属性
Properties props = new Properties();
// 指定连接的kafka服务器的地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.85.143:9092");
// 构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props, new StringSerializer(), new StringSerializer());
// 定义kafka主题
String topic = "shunyi_topic";
// 调用生产者发送消息
String message = "hello kafka!";
// 构建消息
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, message);
// 同时发送key和value
record = new ProducerRecord<String, String>(topic, "10010", message);
// 发送消息
producer.send(record);
// 释放连接
producer.close();
}
}
消息消费者
http://kafka.apache.org/21/documentation.html#consumerapi
创建消费者类:
package com.heima.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class ConsumerTest {
public static void main(String[] args) {
// 设置属性
Properties props = new Properties();
// 指定连接的kafka服务器的地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.85.143:9092");
// 指定消费者的分组编号
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group_1");
// 构建kafka消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props, new StringDeserializer(), new StringDeserializer());
// 定义kafka主题
String topic = "sy_160_1";
// 指定消费者订阅主题
List<String> topics = new ArrayList<String>();
topics.add(topic);
consumer.subscribe(topics);
// 调用消费者拉取消息
while (true) {
// Duration.ofSeconds(1) 每隔1秒拉取一次消息
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
// 遍历集合
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
String key = consumerRecord.key();
String value = consumerRecord.value();
System.out.println("接收到消息: key = " + key + ", value = " + value);
}
}
}
}
kafka详解
相关概念
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0YPHHQT9-1652234020408)(assets\1598766498854.png)]](https://img-blog.csdnimg.cn/54d87609bbcc44b5a3e86f440d0c8593.png)
在kafka概述里介绍了概念包括:topic、producer、consumer、broker,这些是最基本的一些概念,想要更深入理解kafka还要知道它的一些其他概念定义:
-
消息Message
Kafka 中的数据单元被称为消息message,也被称为记录,可以把它看作数据库表中某一行的记录。
-
topic
Kafka将消息分门别类,每一类的消息称之为一个主题(Topic),消息存放在Topic中,可以简单理解Topic为文件夹,消息为文件夹中的文件,与传统的消息系统不同的是,消息被消费后不会删除,但是可以设置过期时间 分区==分片
-
偏移量 Offset
偏移量(Offset)是一种元数据,它是一个不断递增的整数值,消费者消费时可以灵活指定偏移量,可以从头开始或者从上一次最后的偏移量开始消费
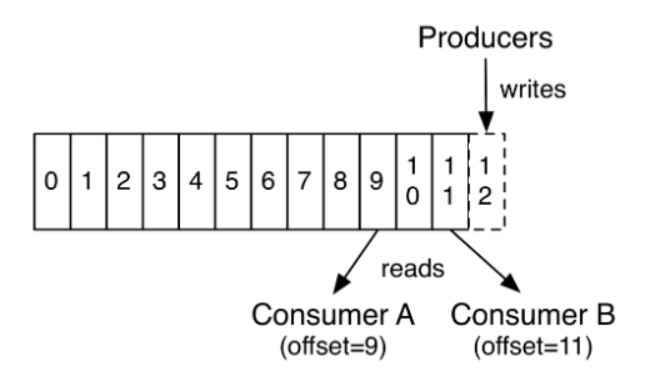
-
broker
一个独立的 Kafka 服务器就被称为 broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
-
Broker 集群
broker 是集群 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
-
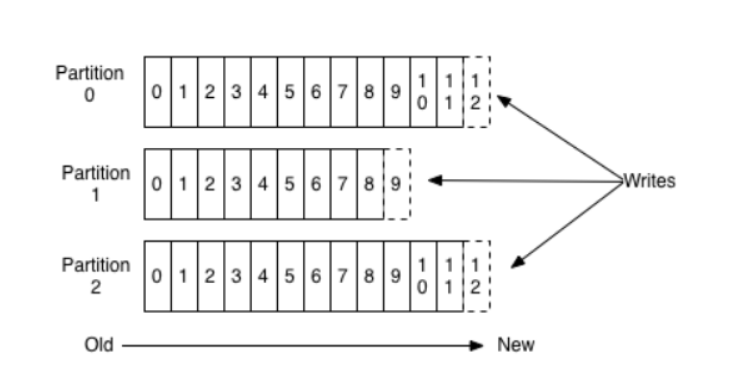
分区Partition
主题可以被分为若干个分区(partition),同一个主题中的分区可以在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性。topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个文件进行存储。partition中的数据是有序的,partition之间的数据是没有顺序的。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
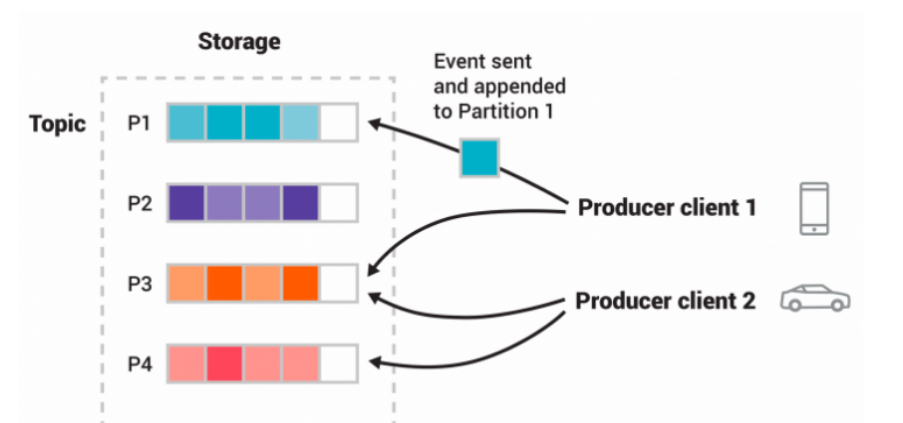
-
副本Replica
Kafka 中分区的备份叫做 副本(Replica),分区分布在不同的服务器上,分区可以配置一定数量的副本进行容错,每个分区都有一台服务器充当领导者(Leader )及其他的副本称为追随者(Follower);所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader断开、卡住或者同步太慢,leader会把这个follower从ISR列表(保持同步的副本列表)中删除,重新创建一个Follower。
-
Zookeeper
kafka对于zookeeper是强依赖的,是以zookeeper作为基础的,即使不做集群,也需要zk的支持。Kafka通过Zookeeper管理集群配置,选举leader。
-
消费者群组Consumer Group
生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。Kafka会将分区”尽量公平”的分给不同的消费者
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jAyDHCUR-1652234020424)(assets/image-20201018101224469.png)]](https://img-blog.csdnimg.cn/194409bf1436489d8f3f25306fac7245.png)
- 生产者发送消息,同一个组中的多个消费者只能有一个消费者接收消息
- 生产者发送消息,如果有多个组,每个组中只能有一个消费者接收消息,如果想要实现广播的效果,可以让每个消费者单独有一个组即可,这样每个消费者都可以接收到消息
-
客户端再均衡
当消费者发生变化(加入新的消费者或原有消费者宕机)或topic发生变化时会出现再均衡现象(分区的所有权从一个消费者转到另一个消费者)。
生产者详解
(1)发送消息的工作原理
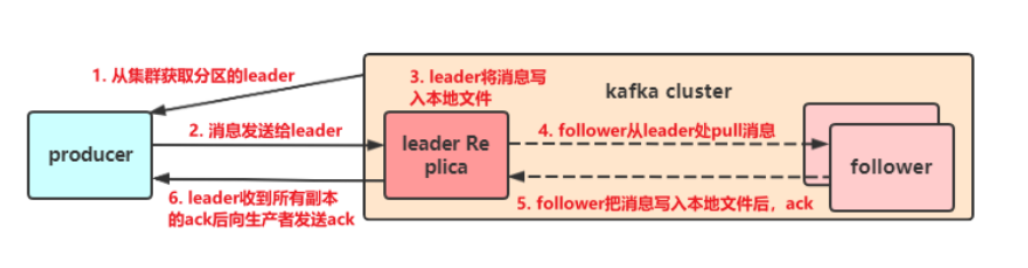
(2)发送类型
-
发送并忘记(fire-and-forget)
把消息发送给服务器,并不关心它是否正常到达,大多数情况下,消息会正常到达,因为kafka是高可用的,而且生产者会自动尝试重发,使用这种方式有时候会丢失一些信息
-
同步发送
使用send()方法发送,它会返回一个Future对象,调用get()方法进行等待,就可以知道消息是否发送成功
//发送消息 try { RecordMetadata recordMetadata = producer.send(record).get(); System.out.println(recordMetadata.offset());//获取偏移量 }catch (Exception e){ e.printStackTrace(); }如果服务器返回错误,get()方法会抛出异常,如果没有发生错误,我们就会得到一个RecordMetadata对象,可以用它来获取消息的偏移量
-
异步发送
调用send()方法,并指定一个回调函数,服务器在返回响应时调用函数。如下代码
//发送消息 try { producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if(e!=null){ e.printStackTrace(); } System.out.println(recordMetadata.offset()); } }); }catch (Exception e){ e.printStackTrace(); }如果kafka返回一个错误,onCompletion()方法会抛出一个非空(non null)异常,可以根据实际情况处理,比如记录错误日志,或者把消息写入“错误消息”文件中,方便后期进行分析。
(3)参数详解
到目前为止,我们只介绍了生产者的几个必要参数(bootstrap.servers、序列化器等)
生产者还有很多可配置的参数,可以在
ProducerConfig
中查看,在kafka官方文档中都有说明,http://kafka.apache.org/21/documentation.html#producerconfigs,大部分都有合理的默认值,所以没有必要去修改它们,不过有几个参数在内存使用,性能和可靠性方法对生产者有影响
-
acks
指的是producer的消息发送确认机制,
properties.put(ProducerConfig.ACKS_CONFIG,"all");
-
acks=0
生产者在成功写入消息之前不会等待任何来自服务器的响应,也就是说,如果当中出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。不过,因为生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量。
-
acks=1
只要集群首领节点收到消息,生产者就会收到一个来自服务器的成功响应,如果消息无法到达首领节点,生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。
-
acks=all
只有当所有参与赋值的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应,这种模式是最安全的,它可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群仍然可以运行。不过他的延迟比acks=1时更高。
-
-
retries
生产者从服务器收到的错误有可能是临时性错误,在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试返回错误,默认情况下,生产者会在每次重试之间等待100ms
消费者详解
(1)消费者工作原理
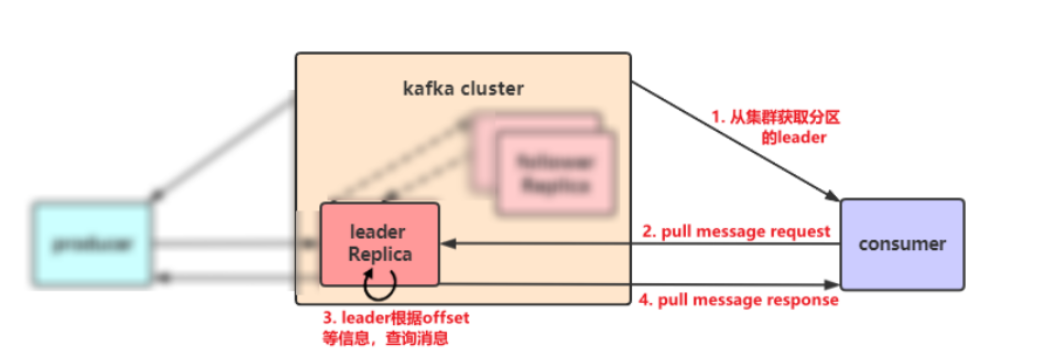
(2)参数详解
http://kafka.apache.org/21/documentation.html#consumerconfigs
-
enable.auto.commit
该属性指定了消费者是否自动提交偏移量,默认值是true。为了尽量避免出现重复数据和数据丢失,可以把它设置为false,由自己控制何时提交偏移量。如果把它设置为true,还可以通过配置
auto.commit.interval.ms
属性来控制提交的频率。 -
auto.offset.reset
如果没有初始偏移量或者当前的偏移量在服务器上不存在时如何处理
-
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
-
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
-
none
topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
-
anything else
向consumer抛出异常
-
(3)提交和偏移量
每次调用poll()方法,它会返回由生产者写入kafka但还没有被消费者读取过来的记录,我们由此可以追踪到哪些记录是被群组里的哪个消费者读取的,kafka不会像其他JMS队列那样需要得到消费者的确认,这是kafka的一个独特之处,相反,消费者可以使用kafka来追踪消息在分区的位置(偏移量)
消费者会往一个叫做
_consumer_offset
的特殊主题发送消息,消息里包含了每个分区的偏移量。如果消费者一直处于运行状态,那么偏移量就没有什么用处。不过,如果消费者发生崩溃或有新的消费者加入群组,就会触发再均衡,完成再均衡之后,每个消费者可能分配到新的分区,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的地方继续处理。
如果提交偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
如下图:
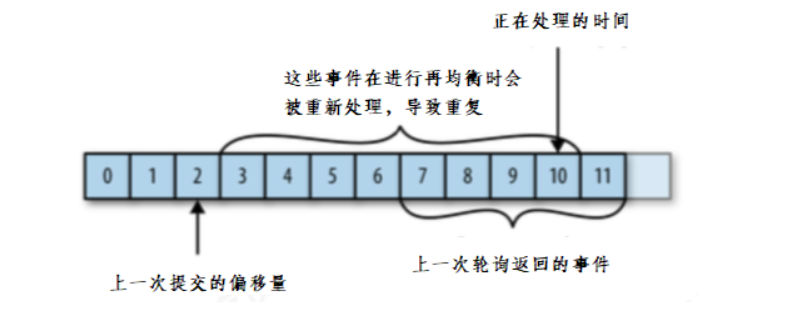
如果提交的偏移量大于客户端的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
如下图:
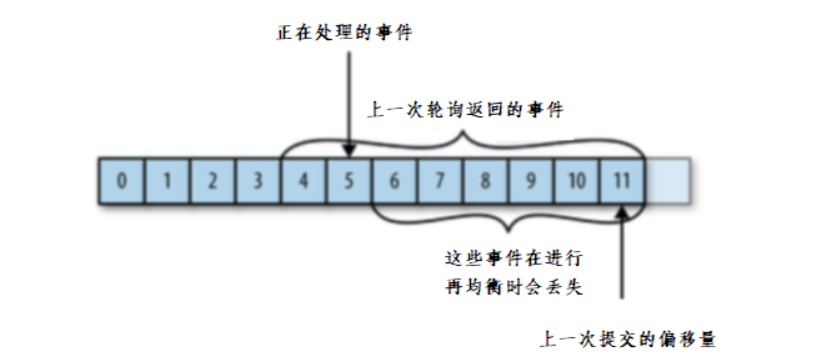
(4)自动提交偏移量
当
enable.auto.commit
被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去。提交时间间隔有
auto.commot.interval.ms
控制,默认值是5秒。
需要注意到,这种方式可能会导致消息重复消费。假如,某个消费者poll消息后,应用正在处理消息,在3秒后Kafka进行了重平衡,那么由于没有更新位移导致重平衡后这部分消息重复消费。
(5)提交当前偏移量(同步提交)
把
enable.auto.commit
设置为false,让应用程序决定何时提交偏移量。
properties.put("enable.auto.commit", "false");
使用commitSync()提交偏移量,commitSync()将会提交poll返回的最新的偏移量,所以在处理完所有记录后要确保调用了commitSync()方法。否则还是会有消息丢失的风险。
只要没有发生不可恢复的错误,commitSync()方法会一直尝试直至提交成功,如果提交失败也可以记录到错误日志里。
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
System.out.println(record.key());
}
try {
consumer.commitSync();//同步提交当前最新的偏移量
}catch (CommitFailedException e){
System.out.println("记录提交失败的异常:"+e);
}
}
(6)异步提交
手动提交有一个缺点,那就是当发起提交调用时应用会阻塞。当然我们可以减少手动提交的频率,但这个会增加消息重复的概率(和自动提交一样)。另外一个解决办法是,使用异步提交的API。
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
System.out.println(record.key());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
if(e!=null){
System.out.println("记录错误的提交偏移量:"+ map+",异常信息"+e);
}
}
});
}
(7) 消费组和偏移量
修改消费组,并且将
auto.offset.reset
设置为
earliest
// 设置消费的方式 从最早记录开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 指定消费者分组
String groupId = "group-5";
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
可以看到消息被重新消费,并且重新计算这个组的偏移量
spring集成kafka收发消息
环境搭建
(1)搭建工程kafka-spring-boot-demo 添加pom依赖,最终的依赖信息
<!-- 继承Spring boot工程 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.8.RELEASE</version>
</parent>
<properties>
<fastjson.version>1.2.58</fastjson.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>
(2)在resources下创建文件application.yml
server:
port: 8080
spring:
application:
name: kafka-demo
kafka:
bootstrap-servers: 192.168.85.143:9092
consumer:
group-id: kafka-demo-kafka-group
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
(3)引导类
package com.heima.kafka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class KafkaApp {
public static void main(String[] args) {
SpringApplication.run(KafkaApp.class, args);
}
}
消息生产者
junit测试,新建消息发送方
package com.heima.kafka.test;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class KafkaSendTest {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate; //如果这里有红色波浪线,那是假错误
@Test
public void sendMsg(){
String topic = "spring_test";
kafkaTemplate.send(topic,"hello spring boot kafka!");
System.out.println("发送成功.");
while (true){ //保存加载ioc容器
}
}
}
消息消费者
新建监听类:
package com.heima.kafka.listener;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class MyKafkaListener {
// 以下两种方法都行
// 指定监听的主题
// @KafkaListener(topics = "spring_test")
// public void receiveMsg(String message){
// System.out.println("接收到的消息:"+message);
// }
@KafkaListener(topics = "spring_test")
public void handleMessage(ConsumerRecord<String, String> record) {
System.out.println("接收到消息,偏移量为: " + record.offset() + " 消息为: " + record.value());
}
}
项目结构: