本文目录
1.内置函数
进入 hive 客户端,通过命令
show functions
来查看系统内置的函数,默认内置了 289 个函数。通过命令
desc function 函数名
可以查看自带函数的描述,通过命令
desc function extended 函数名
可查看自带函数详细的用法(附带Example)。如下所示:
# 1.查看函数描述
hive (test)> desc function upper;
OK
tab_name
upper(str) - Returns str with all characters changed to uppercase
Time taken: 0.014 seconds, Fetched: 1 row(s)
# 2.查看函数详细用法
hive (test)> desc function extended upper;
OK
tab_name
upper(str) - Returns str with all characters changed to uppercase
Synonyms: ucase
Example:
> SELECT upper('Facebook') FROM src LIMIT 1;
'FACEBOOK'
Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFUpper
Function type:BUILTIN
Time taken: 0.066 seconds, Fetched: 7 row(s)
2.Hive函数分类
Hive 中的函数,分三种:
-
UDF
(一进一出,普通函数)
-
UDTF
(多进一出,聚合函数)
-
UDAF
(一进多出,炸裂函数)
一
和
多
指的是
输入数据的行数
。
UDF函数
:输入一行数据,返回一行数据。比如:upper(转大写)、substring(截取) 函数
UDTF函数
:输入多行数据,返回一行数据,就是我们常用的聚合函数。比如:sum(求和)、avg(求平均数)函数
UDAF函数
:输入一行数据,返回多行数据,又叫做炸裂函数。比如:explode(用于打散行,将一行的数据拆分成多行,它的参数必须为map或array)函数
(炸裂函数:比如一行有很多单词,逗号分割,最后将单词通过逗号拆开,一个单词放一行,即输入一行输出多行)
如下图所示
,通过命令:
desc function extended 函数名;
可以来查看函数是什么类型

3.常用函数介绍
由于博主有 MySQL 、Oracle 相关知识。此处部分函数的使用和 MySQL、Oracle 完全一致,就不在此过多描述
3.1 nvl
函数说明
:
给值为 NULL 的数据赋值,它的格式是
NVL( value,default_value)
。它的功能是如果 value 为 NULL,则 NVL 函数返回 default_value 的值,否则返回 value 的值,如果两个参数都为 NULL ,则返回 NULL。【Oracle 中也有 NVL 函数】。
示例:
select nvl(null,'默认值'); #返回默认值 select nvl("111","222"); #返回111 select nvl(100+100,"222"); #返回200
3.2 case when then else end
函数说明
:
多条件判断函数,类似 Java 中的 if else 语句
。condition是一个返回布尔类型的表达式,如果表达式返回true,则整个函数返回相应result的值,如果表达式皆为false,则返回 ElSE 后 result 的值,如果省略了 ELSE 子句,则返回 NULL。【MySQL、Oracle 中均有 case when then else end 函数】
格式:
CASE WHEN condition THEN result [WHEN...THEN...] ELSE result END
3.3 concat相关函数
Ⅰ.concat
函数说明
:
CONCAT(string A/col, string B/col…) 返回输入字符串连接后的结果,支持任意个输入字符串。【MySQL、Oracle中均有 concat 函数】
示例:
SELECT concat("Hello","----","World"); # 返回 Hello----World
Ⅱ.concat_ws
函数说明
:
CONCAT_WS(separator, str1, str2,…) :它是一个特殊形式的 CONCAT()。第一个参数为参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
示例:
select concat_ws("-","Hello","World","HaHaHa"); #返回Hello-World-HaHaHa
注意:
CONCAT_WS 中传入的参数,必须是
string字符串
或者
array<string>字符串数组
。
传入 array<string>字符串数组,concat_ws 可配合 collect_set、collect_list 使用
。
3.4 collect_相关函数
数据:
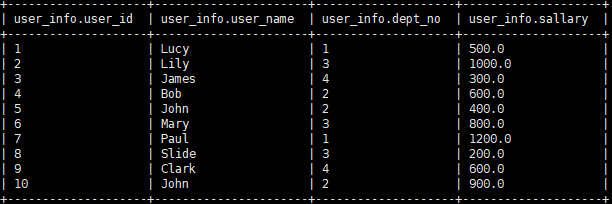
Ⅰ.collect_set
函数说明
:
collect_set
函数只接受基本数据类型,它的主要作用是将某字段的值进行
去重
汇总,产生 Array 类型字段。
示例:
# collect_set select dept_no,collect_set(user_name) from user_info group by dept_no;
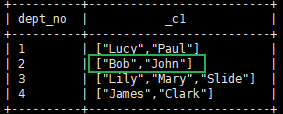
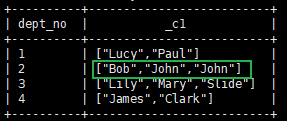
Ⅱ.collect_list
函数说明
:
collect_list 与 collect_set 不同的是它不会去重。
示例:
#collect_list select dept_no,collect_list(user_name) from user_info group by dept_no;
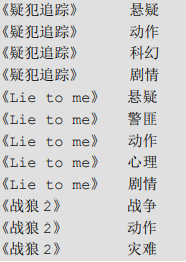
3.5 explode + lateral view
提示:
explode 是 UDTF函数,UDTF函数通常需要配合 lateral view 侧写表使用。
函数说明:
explode(col)
:将一行数据转换成列数据,可以用于array和map类型的数据。就是将 hive 一行中复杂的array或者map结构拆分成多行。
数据:
需求:
将电影分类中的数组数据展开。结果如下:
SQL:
# 表名.* 方式 select movie, category_name.* from movie_info lateral view explode(split(category,'/')) category_name; # 列名方式 select movie, category_name from movie_info lateral view explode(split(category,'/')) movie_info_tmp as category_name;
分析:
如果使用
select movie,explode(split(category,'/')) from movie_info;
则会报错:
UDTF’s are not supported outside the SELECT clause, nor nested in expressions
原因
:
当使用UDTF函数的时候,hive只允许对拆分字段进行访问。
正确命令:
select explode(split(category,'/')) from movie_info;
错误命令:
select movie,explode(split(category,'/')) from movie_info;
如果想访问除了拆分字段以外 的字段,怎么办呢?
用lateral view侧视图!
官方文档,参考:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
lateral view为侧视图,意义是为了配合UDTF函数来使用,把某一行数据拆分成多行数据
。
不加 lateral view 的UDTF只能提取单个字段拆分,并不能塞回原来数据表中。加上lateral view就可以将拆分的单个字段数据与原始表数据关联上。
explode 只炸裂一个列,直接炸裂即可。如果炸裂的同时,还需要原表相关的字段,就需要加 lateral view 侧写表了
注意:
在使用 lateral view 的时候需要指定视图别名和生成的新列别名【参考自:
https://blog.csdn.net/u011110301/article/details/104198588
】

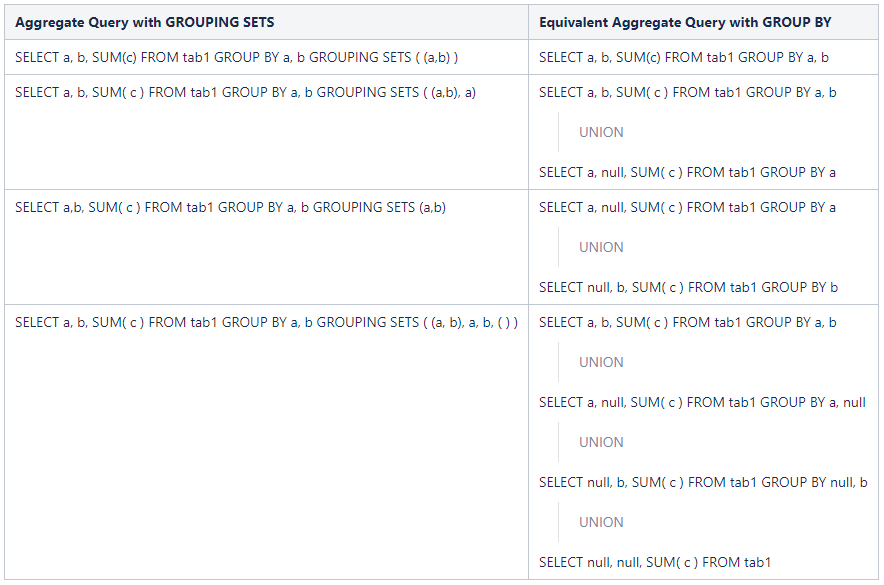
3.6 grouping sets 多维分析
使用 grouping sets 对数据进行多维度分析。如何使用 grouping sets 可参考官方文档:
Enhanced Aggregation, Cube, Grouping and Rollup
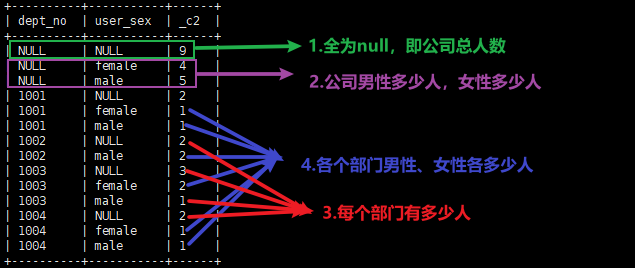
1.需求:
①查看公司的总人数
②查看公司男性多少人,女性多少人
③查看公司每个部门有多少人
④查看公司每个部门男性、女性有多少人
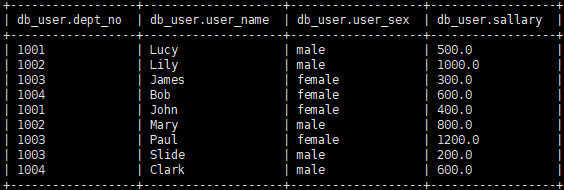
2.数据如下:
3.基础SQL语句查询
①查看公司的总人数
select count(*) from db_user;②查看公司男性多少人,女性多少人
select user_sex, count(*) from db_user group by user_sex;③查看公司每个部门有多少人
select dept_no, count(*) from db_user group by dept_no;④查看公司每个部门男性、女性有多少人
select dept_no, user_sex, count(*) from db_user group by dept_no, user_sex;
4.使用 GROUPING SETS 一个语句即可完成!!!!
select dept_no, user_sex, count(*) from db_user group by dept_no,user_sex grouping sets ((),user_sex,dept_no,(user_sex,dept_no));
查询结果:
5.聚合查询,使用grouping sets 和 group by 的对比图(摘自官方文档)
3.7 开窗函数
提示:
MySQL 在 8.X 版本也引入了开窗函数,与 Hive 中使用一样。随便找了个 blog 了解一下吧。
MySQL 8.x 开窗函数 blog
官方文档,参考:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
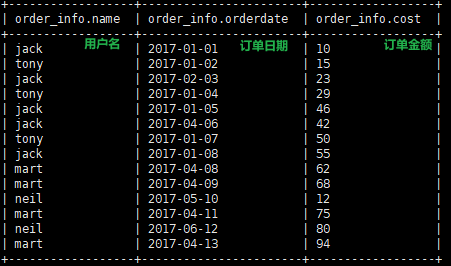
数据:
Ⅰ.over()大致介绍
说明:
group by 可以根据某个字段对数据集进行分组。over() 也类似,可以指定字段。但是它和 group by 还是不同的。
不同点在于
:
group by 按照某个字段分组,比如说部门id,那么只要 id 相同的就都在一个组中,聚合时会对组中所有数据进行聚合。
over() 则不同,它可以指定窗口大小随着行的改变而改变,比如说 over 根据某个字段分组(
此处说分组也不妥
),它可以在组内开窗,再次指定哪些行分为一组。
Ⅱ.over() 括号中会使用到的几个关键词(如何使用参考下文3.1)
关键词 含义 PARTITION BY 以某个字段分区 ORDER BY 用于排序,配合聚合函数可实现累加 CURRENT ROW 当前行 n PRECEDING 往前 n 行数据 n FOLLOWING 往后 n 行的数据 UNBOUNDED 起点
UNBOUNDED PRECEDING 表示从前面的起点
UNBOUNDED FOLLOWING 表示到后面的终点LAG(col,n,default_val) 往前第 n 行数据
【col 字段,n 往前推n行,default_val 往前推的n行,如果该行为空,使用default_val字段】
LEAD(col,n,default_val) 往后第 n 行数据
【col 字段,n 往前推n行,default_val 往前推的n行,如果该行为空,使用default_val字段】
FIRST_VALUE 这最多需要两个参数。 第一个参数是您想要第一个值的列,第二个(可选)参数必须是默认值为 false 的布尔值。 如果设置为 true 则跳过空值 LAST_VALUE 这最多需要两个参数。 第一个参数是您想要最后一个值的列,第二个(可选)参数必须是默认为 false 的布尔值。 如果设置为 true 则跳过空值。 NTILE(n) 把有序窗口的行,分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回慈航所属的组的编号。
注意:n必须为 int 类型
提示:这几个关键字可以非常方便在开窗中对行数的控制。在下面的【需求 3.1 中会有使用到】,点击链接到 3.1 查看
→→To 3.1
。你也可以参见官方文档示例:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
通过案例来了解一下over()的含义
案例一
:
over()存在的意义
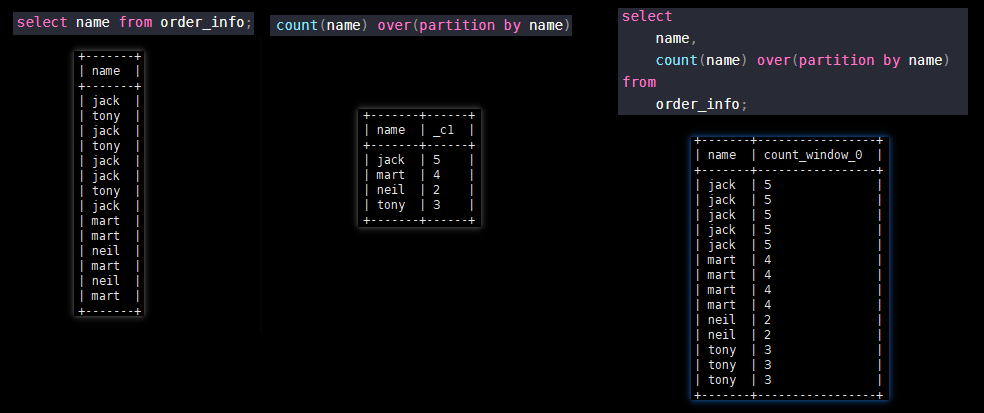
# 这个SQL是会直接报错的,因为使用count聚合函数,却没有 group by name; select name,count(name) from order_info;
# 加个 over() 在聚合函数后,在hive中就能够正常运行了。 select name,count(name) over() from order_info;
运行结果:
结果分析:
为什么是14呢?因为库中一共就有14条记录。
over() 在 group by 查询之后生效。我们执行
select name from order_info;
会有14条记录。over() 即开窗的意思,over() 括号中没有限制条件,即代表将
select name from order_info;
的14条记录作为窗口数据集,count(name) 就是对窗口里面的数据集进行 count 计算。select name 有14条数据,返回数据就为14条,count(name) 就是对 over() 窗口中的数据集计算,所以14条数据的 count(name) 都是14。
总结:
over() 开窗,窗口中的数据就是除聚合函数外查询到的数据。本例即:
select name from order_info;
会有14条记录,count(name)就是对窗口中的数据求 count,就是 14 咯。
案例二
:
over()分区使用
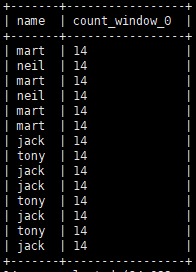
# over() 指定按照 name 分区 select name, count(name) over(partition by name) from order_info;
查询结果:
>

Ⅲ.通过几个需求来了解over()的使用:
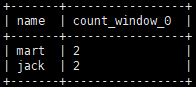
1.查询在2017年4月份购买过的顾客及总人数
select name, count(*) over () from order_info where date_format(orderdate,'yyyy-MM') = '2017-04' group by name;
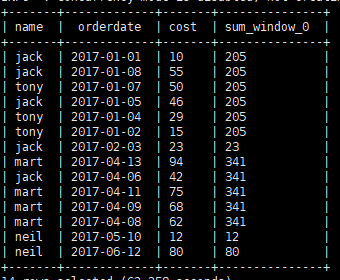
2.查询顾客的购买明细及月购买金额
select name, orderdate, cost, sum(cost) over(partition by month(orderdate)) from order_info;
3.查询顾客的购买明细,将每个顾客的cost按照日期进行累加
备注:
累加功能,在 over() 中加个
order by
即可
。select name, orderdate, cost, sum(cost) over(partition by name order by orderdate) from order_info;
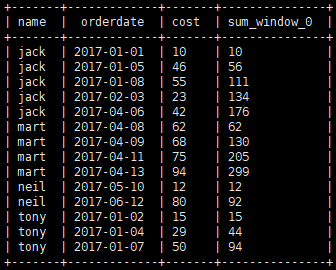
3.1 over 中的几个关键字使用介绍
①
sum(cost) over(partition by name order by orderdate)
按name分组,组内数据累加
②
sum(cost) over(partition by name order by orderdate
rows between
UNBOUNDED PRECEDING
and
CURRENT ROW
)
按name分组,由
起点
到
当前行
的聚合,与①一样,①默认也是起点到当前行的聚合
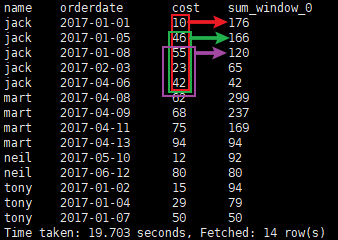
③
sum(cost) over(partition by name order by orderdate
rows between
1 PRECEDING
and
CURRENT ROW
)
按name分组,
当前行
与
前面1行
做聚合
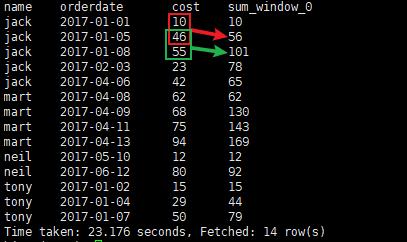
④
sum(cost) over(partition by name order by orderdate
rows between
1 PRECEDING
and
1 FOLLOWING
)
按name分组,
当前行
与
前面1行
与
后面一行
做聚合
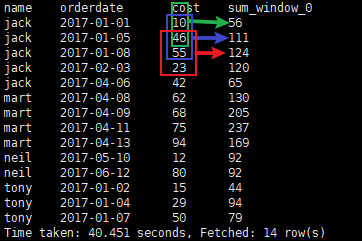
⑤
sum(cost) over(partition by name order by orderdate
rows between
CURRENT ROW
and
1 FOLLOWING
)
按name分组,
当前行
与
后面1行
做聚合
⑤
sum(cost) over(partition by name order by orderdate
rows between
CURRENT ROW
and
UNBOUNDED FOLLOWING
)
按name分组,
当前行
与
后面所有行
做聚合
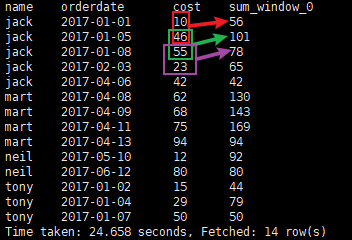
4.LAG查询每个顾客上次的购买时间
提示:
lag(col,n,default_val): 【col 字段,n 往前推n行,default_val 往前推的n行,如果改行为空,使用default_val字段】
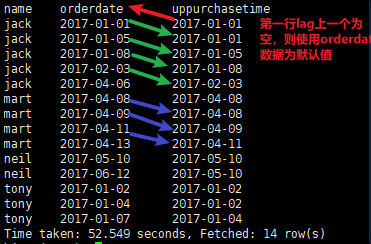
① Lag 将前n条数据整体往下瞬移的意思。可以做页面访问轨迹。比如:从【A页面 > B页面 > C页面】访问
select name, orderdate, (lag(orderdate,1,orderdate) over(partition by name order by orderdate)) upPurchaseTime from order_info;
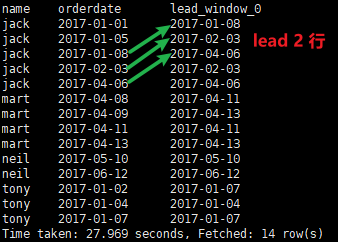
② Lead 与 Lag 正好反方向。功能一致
# lead 1行,为 null 使用本行的 orderdate select name, orderdate, lead(orderdate,1,orderdate) over(partition by name order by orderdate) from order_info;
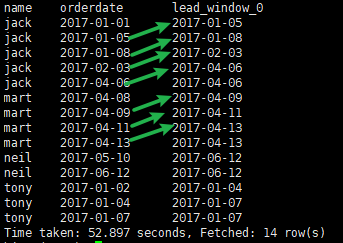
② lead 往后2行
# lead 2行,为 null 使用本行的 orderdate select name, orderdate, lead(orderdate,2,orderdate) over(partition by name order by orderdate) from order_info;
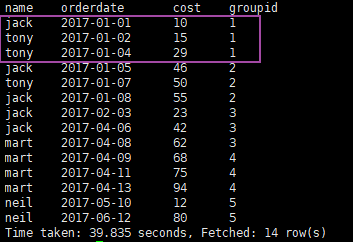
5.查询前 20% 时间的订单信息
按时间排序,20%即分成5个组,取第一个组的数据,使用到 ntile(n) 配合 over()完成
select
tb.name,
tb.orderdate,
tb.cose
from (
select
name,
orderdate,
cost,
ntile(5) over(order by orderdate) groupId
from
order_info;
) tb
where
tb.groupId = 1
3.8 rank、dense_rank
提示:
需要配合开窗函数 over() 使用。
MySQL 在 8.x版本也引入了开窗函数,就很容易实现类似 rank、dense_rank 的功能。
函数说明:
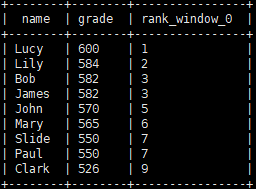
rank
函数用于排序,排序相同时会重复,总数不会变。
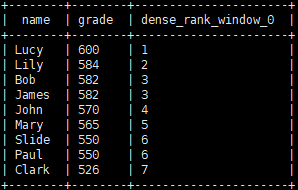
dense_rank
函数用于排序,排序相同时总数会减少。
举例:
类似成绩排名。第一个人500分,第二个人500分。并列第一。第三个人499。说的就是他是第二名?还是第三名的问题。
rank 总数不会变,排序后是 1、1、3
;
dense_rank 总数则会减少,排序后是1、1、2
数据:
示例:
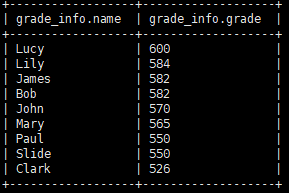
# rank 排序后总数不会变,排序后是 1、1、3 select name, grade, rank() over(order by grade desc) from grade_info;
# dense_rank 总数则会减少,排序后是1、1、2 select name, grade, dense_rank() over(order by grade desc) from grade_info;
3.9 row_number
提示:
需要配合开窗函数 over() 使用
MySQL 在 8.x版本也引入了开窗函数,就很容易实现类似 row_number 的功能。如果没有开窗函数,就比较复杂了,可参考:
MySQL语句练习50题
函数说明:
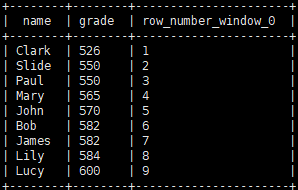
row_number
函数,是给每一行添加一个编号,编号从1 开始,与 Oracle 中的 ROWNUM 差不多。
数据:
使用 3.7 数据
示例:
select name, grade, row_number() over() from grade_info;
提示:
其他没介绍的内置函数,自行研究吧。通过命令
show functions
来查看系统内置的函数,默认内置了 289 个函数。
4.自定义函数
总有 Hive 内置函数解决不了的问题,就需要我们来自定义 Hive 函数了。常用来自定义的是 UDF、UDTF 函数。聚合函数 UDAF 基本已经都内置了。此处就重点介绍
自定义UDF函数
和
自定义UDTF函数
Hive 自定义函数,本文不做介绍,如需了解。跳转查看:
https://blog.csdn.net/lzb348110175/article/details/117653668
下一篇:
Hive自定义函数
博主写作不易,加个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
我不能保证所写的内容都正确,但是可以保证不复制、不粘贴。保证每一句话、每一行代码都是亲手敲过的,错误也请指出,望轻喷 Thanks♪(・ω・)ノ