需求描述
统计视频网站的各种topN
1、统计视频观看数 Top10
2、统计视频类别热度 Top10
3、统计视频观看数 Top20 所属类别
4、统计每个类别中的视频热度 Top10
5、统计每个类别中视频流量 Top10
6、统计上传视频最多的用户 Top10 以及他们上传的的观看次数在 前 20 的视频
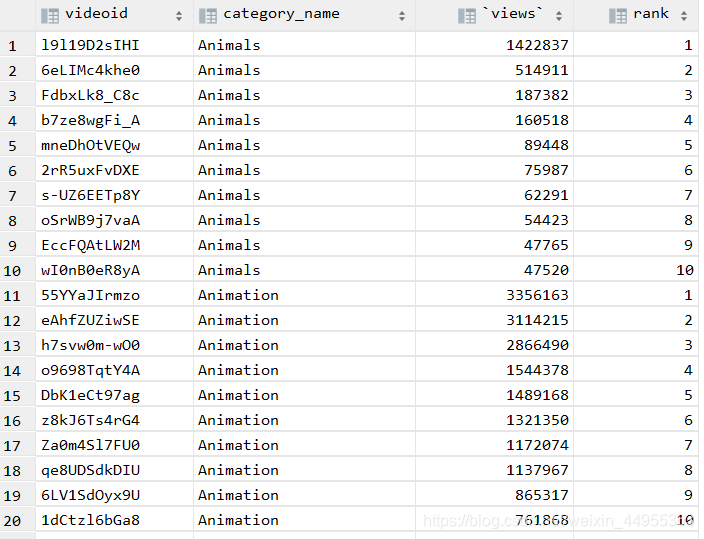
7、统计每个类别视频观看数 Top10
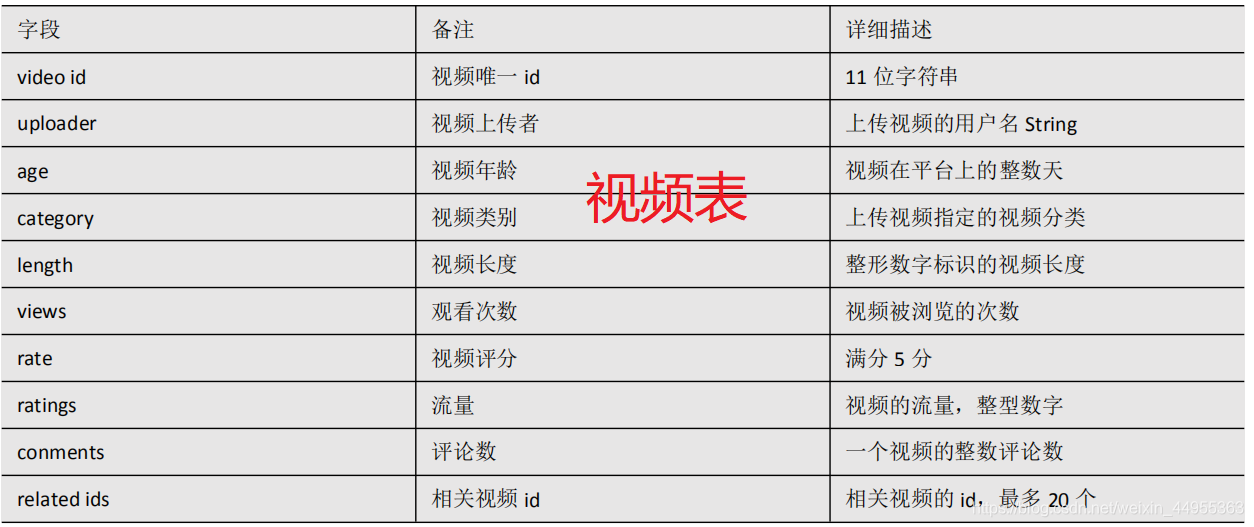

第一步:对数据预处理
第一步:对数据预处理
原始数据示例:
qR8WRLrO2aQ:mienge:406:
People & Blogs
:599:2788:5:1:0:4UUEKhr6vfA:zvDPXgPiiWI:TxP1eXHJQ2Q:k5Kb1K0zVxU:hLP_mJIMNFg:tzNRSSTGF4o:BrUGfqJANn8:OVIc-mNxqHc:gdxtKvNiYXc:bHZRZ-1A-qk:GUJdU6uHyzU:eyZOjktUb5M:Dv15_9gnM2A:lMQydgG1N2k:U0gZppW_-2Y:dUVU6xpMc6Y:ApA6VEYI8zQ:a3_boc9Z_Pc:N1z4tYob0hM:2UJkU2neoBs
预处理之后的数据示例
qR8WRLrO2aQ:mienge:406:
People ,Blogs
:599:2788:5:1:0:
4UUEKhr6vfA,zvDPXgPiiWI,TxP1eXHJQ2Q,k5Kb1K0zVxU,hLP_mJIMNFg,tzNRSSTGF4o,BrUGfqJANn8,OVIc-mNxqHc,gdxtKvNiYXc,bHZRZ-1A-qk,GUJdU6uHyzU,eyZOjktUb5M,Dv15_9gnM2A,lMQydgG1N2k,U0gZppW_-2Y,dUVU6xpMc6Y,ApA6VEYI8zQ,a3_boc9Z_Pc,N1z4tYob0hM,2UJkU2neoBs
1.1、使用了mapreduce来预处理
video和user数据
链接:https://pan.baidu.com/s/1wbI9vQdJHQ9UKRcAwjlSOg
提取码:xvwq
package Hive.guliVideo;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.testng.annotations.Test;
import java.io.IOException;
public class guli extends Mapper<LongWritable, Text, NullWritable,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String data = value.toString();
String[] split = data.split(":");
String str01="";
String str02="";
String str03="";
String str04="";
if (split.length>10) {
{
for (int i = 0; i < split.length; i++) {
if (i > 8) {
if (i != split.length - 1) {
str01 += split[i] + ",";
} else {
str01 += split[i];
}
} else {
str02 += split[i].trim() + ":";
str03 = str02.replace(" ", "").trim();
}
}
}
String s = str03 + str01;
if (s.contains("&")){
str04= s.replace("&",",");
}else {
str04=s;
}
context.write(NullWritable.get(), new Text( str04));
}
}
}
class reduce extends Reducer< NullWritable,Text, NullWritable,Text>{
@Override
protected void reduce(NullWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(NullWritable.get(),value);
}
}
}
class driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration cf = new Configuration();
Job job = Job.getInstance(cf, "name");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("E:\\Dashuju\\hadoop\\data\\video.txt"));
//设置map输出类型
job.setMapperClass(guli.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setReducerClass(reduce.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("E:\\Dashuju\\hadoop\\data\\aa"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
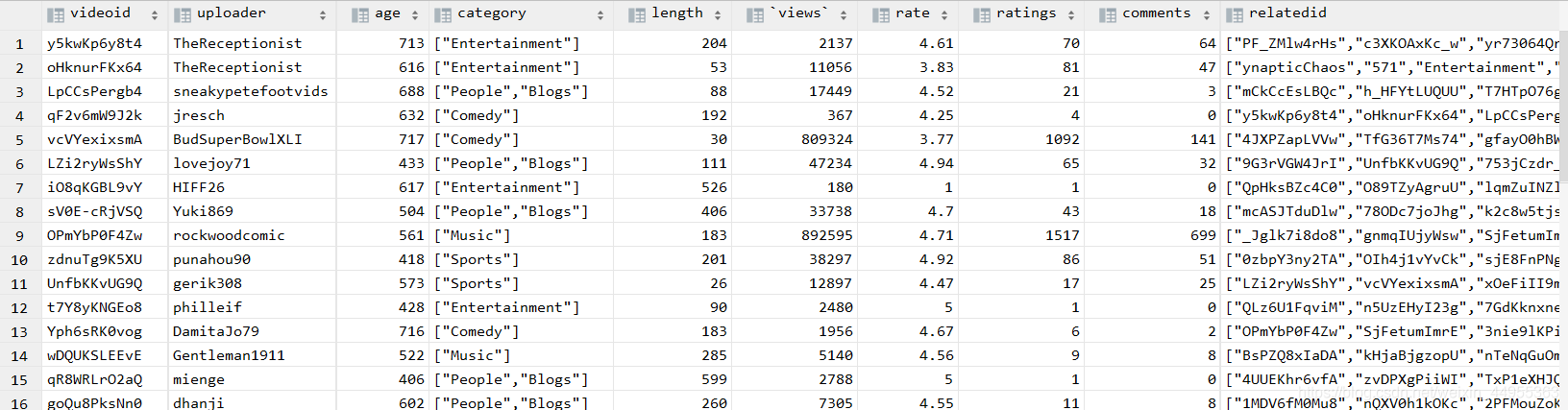
第二步:创建video_ori表,把video数据导入到video_ori
第二步:创建video_ori表,把video数据导入到video_ori
创建video_ori视频表:
create table video_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by ":"
collection items terminated by ","
stored as textfile;
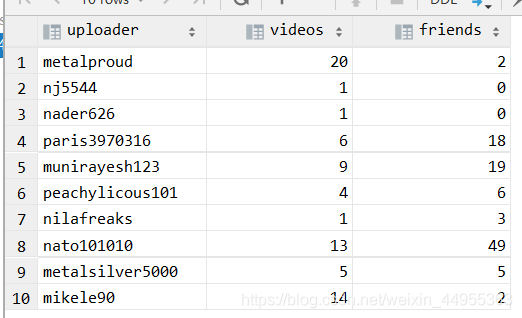
创建video_user_ori用户表:
create table video_user_ori(
uploader string,
videos int,
friends int)
row format delimited
fields terminated by ","
stored as textfile;
2.1、上传linux,往表中加载数据
load data local inpath '/opt/video.txt' into table video_ori;
load data local inpath '/opt/user.txt' into table video_user_ori;
video_ori数据
video_user_ori数据
第三步:实现和分析需求:
第三步:实现和分析需求:
1、统计视频观看数 Top10
思路:使用 order by 对 views 字段做一个全局排序(降序), 只显示前 10 条
select * from video_ori a1 order by a1.`views` desc limit 10 ;
2、统计视频类别热度 Top10
思路:
1) 即统计每个类别有多少个视频,显示出包含视频最多的前 10 个类别。
2) 我们需要按照类别 group by 聚合,然后 count 组内的 videoId 个数即可
3) 因为当前表结构为:一个视频对应一个或多个类别。所以如果要 group by 类 别,需要先 将类别进行列转行(展开),然后再进行 count 即可。
4) 最后按照热度排序,显示前 10 条。
hql实现第一步:先把category类别列转行
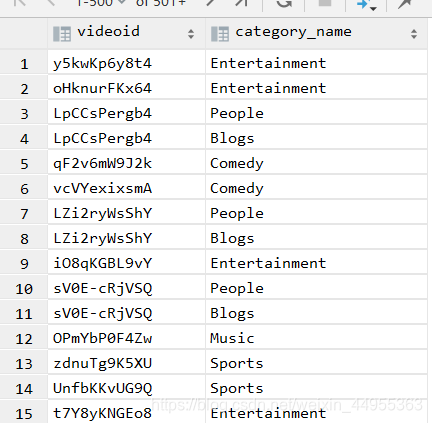
select videoId, category_name from video_ori
lateral view explode(category) t_catetory as category_name
hql实现第二步:把前一步结果当成一张子表 进行查询 ,对类别进行分组,把相同类别的放一起,求count(video_id)
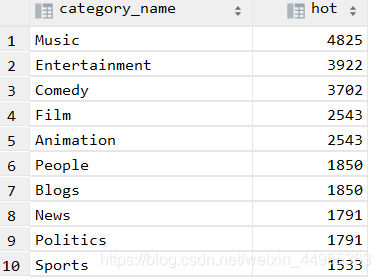
select category_name,count(t1.category_name) hot from
( select videoId, category_name from video_ori lateral view explode(category) t_catetory as category_name ) t1
group by t1.category_name order by hot desc limit 10 ;
3、统计出视频观看数最高的 20 个视频的所属类别以及类别包含 Top20 视频的个数
思路:
- 先找到观看数最高的 20 个视频所属条目的所有信息,降序排列
- 把这 20 条信息中的 category 分裂出来(列转行)
-
最后查询视频分类名称和该分类下有多少个 Top20 的视频
第一步:
select * from video_ori order by `views` desc limit 20 ;
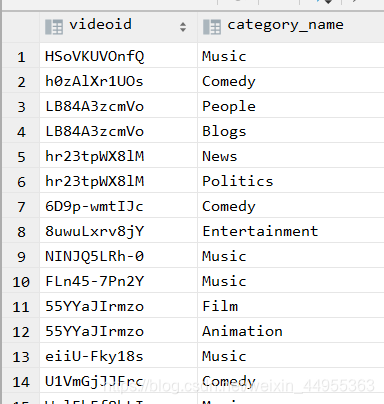
第二步:
select videoid , category_name from
(select * from video_ori
order by `views` desc limit 20 ) t1
lateral view explode(t1.category) t_catetory as category_name;
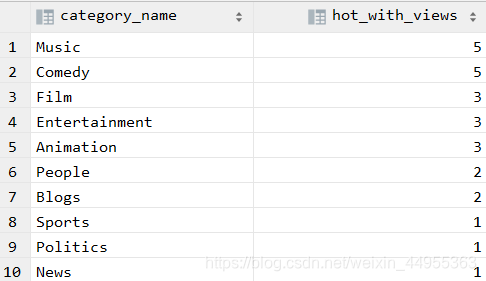
第三步:
select category_name,count(t2.videoid) hot_with_views
from (select videoid , category_name
from (select *
from video_ori
order by `views` desc
limit 20 ) t1
lateral view explode(t1.category) t_catetory as category_name)t2
group by t2.category_name
order by hot_with_views desc ;
4、统计每个类别中的视频热度 Top10: 以 Music 为例
思路:
- 要想统计 Music 类别中的视频热度 Top10,因为当前表结构为:一个视频对应一个或多个类别,把category类别列转行
- 统计对应类别(Music)中的视频热度。limit 10 ;
hql实现第一步:先把category类别列转行
select videoId, uploader, age,
categoryId,length ,`views`, rate, ratings,
comments, relatedId from video_ori
lateral view explode(category) catetory as categoryId;

hql实现第二步: 把第一步当成子表,因为我们要查询的music,只要music类别的前十的热度,所以我们对views进行降序排序,取前十
select videoId, categoryId ,`views` from
(select videoId, uploader, age, categoryId,length ,`views`, rate, ratings, comments, relatedId from video_ori lateral view explode(category) catetory as categoryId) t1
where t1.categoryId = "Music"
order by `views` desc limit 10;
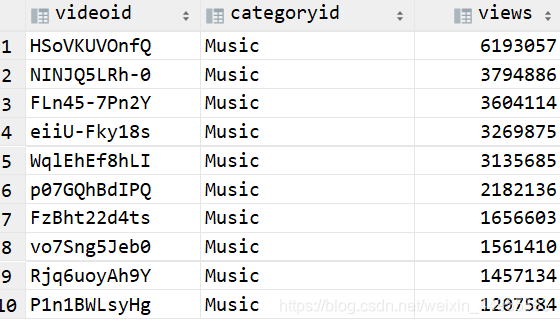
附加:统计每个类别中的视频热度(求所有的类别前十的热度)
hql实现第一步:先把category类别列转行
select videoId, uploader, age,
categoryId,length ,`views`,
rate, ratings, comments, relatedId
from video_ori lateral view explode(category) catetory as categoryId

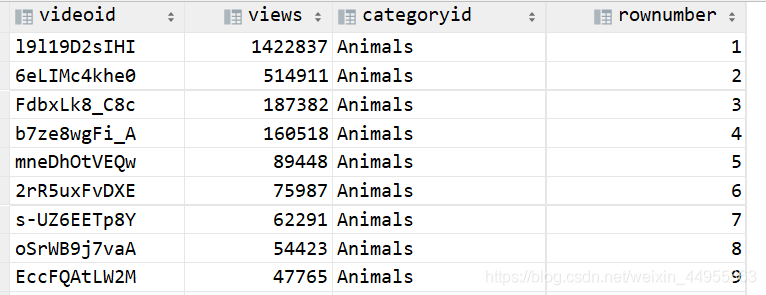
hql实现第二步:使用开窗函数
select videoid , `views`,t1.categoryId,
row_number() over(partition by t1.categoryId order by `views` desc) rownumber
from (select videoId, uploader, age
, categoryId,length ,`views`, rate,
ratings, comments, relatedId
from video_ori
lateral view explode(category) catetory as categoryId) t1 ;
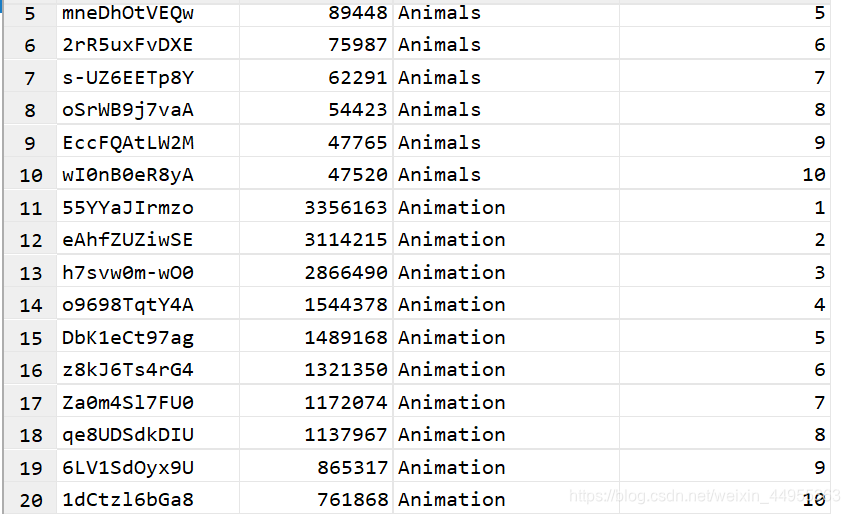
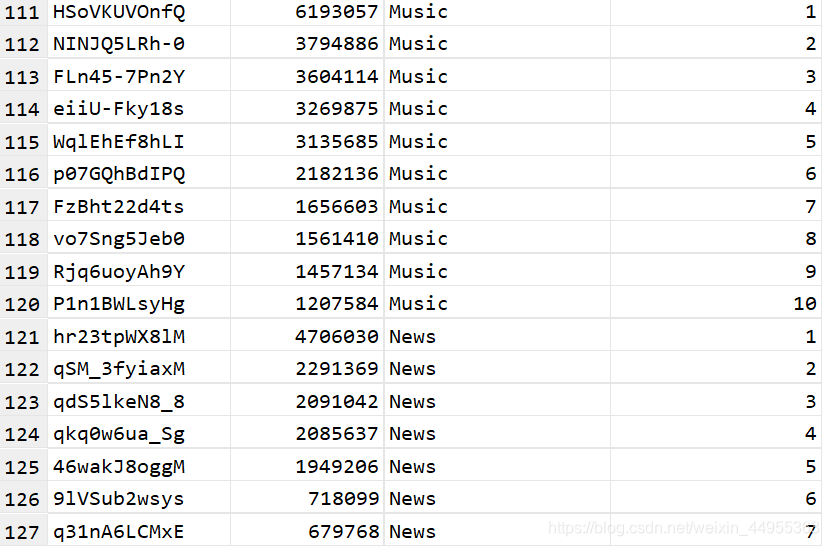
hql实现 第三步 :取 rownumber 小于等于10
select t2.videoid,t2.`views`,t2.categoryId,t2.rownumber
from (select videoid , `views`,t1.categoryId,
row_number() over(partition by t1.categoryId
order by `views` desc) rownumber
from (select videoId, uploader,
age, categoryId,length ,
`views`, rate, ratings, comments, relatedId from video_ori
lateral view explode(category) catetory as categoryId) t1 )t2
where rownumber<=10 ;
5、统计每个类别中视频流量 Top10(以music为例)
hql实现第一步:先把category类别列转行
select videoId,ratings, category_name
from video_ori
lateral view explode(category) t_catetory as category_name;
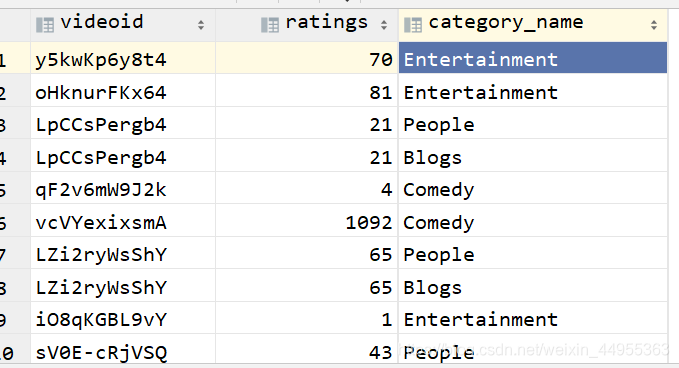
hql实现第二步: 把第一步当成子表,因为我们要查询的music,只要music类别的前十的视频流量,所以我们对views进行降序排序,取前十
select t1.ratings,t1.category_name from
(select videoId,ratings, category_name
from video_ori
lateral view explode(category) t_catetory as category_name) t1
where t1.category_name='Music' order by t1.ratings
desc limit 10 ;
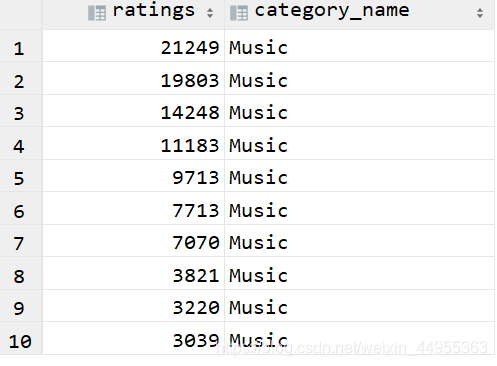
附加 :统计每个类别中视频流量 Top10
跟第五题思路一样 ,使用开窗函数
6、统计上传视频最多的用户 Top10 以及他们上传的的观看次数在 前 20 的视频
select video.* from video_ori video
inner join
(select * from video_user_ori order by videos desc limit 10 ) users
on video.uploader=users.uploader
order by `views` desc limit 20;
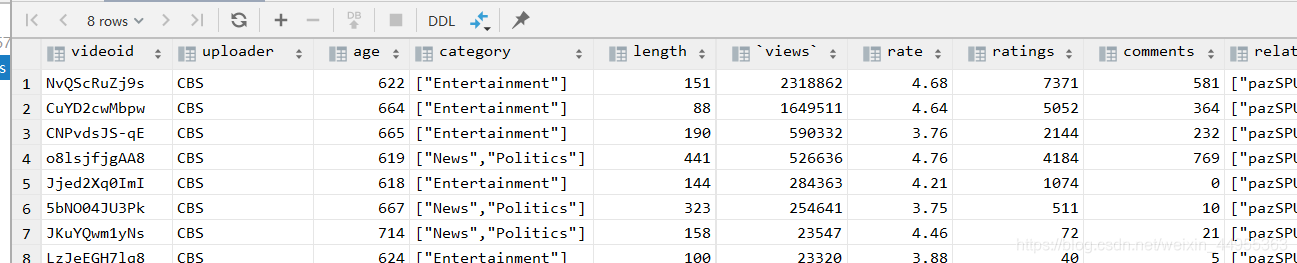
7 、统计每个类别视频观看数 Top10
select t1.*
from ( select videoid, t2.category_name,`views`, row_number() over(partition by t2.category_name
order by `views` desc) rank from
(select * from
video_ori lateral view explode(category) t_catetory as category_name) t2) t1
where rank <= 10;