目录
以全国各城市空气质量年度数据为例。分别应用系统聚类算法和K均值聚类法对数据进行分析
一、背景
系统聚类算法先将各个个体看作一类,根据个体间的相似程度(距离、相关系数)等合并出新类而后不断循环该过程直至达到事先确定的某些标准
其度量相似度的方法有
最小距离、最大距离、中间距离、重心距离、类平均、离差平均等(Q型聚类)
相似系数(P型聚类)
二、系统聚类算法代码实现
setwd("C:/Users/myq20170530/data")#路径设置
data<-read.csv('ex3.4.csv',header=1)#提取数据
d4.3<-data[,-c(1)] #由于数据的第一列是城市名字符串故删去
rownames(d4.3)=data[,1]#为方便下一步分类结果的可视化,把数据的序号改作城市名称
d<-dist(d4.3,method='euclidean',diag=T,upper=T,p=2) #利用欧式距离计算 p为明氏距离的参数
HC1<-hclust(d,method='single')#用最小距离法聚类(对应类与类之间的距离)
plot(HC1,hang=-1)#从底部对齐绘制聚类树状图
##dist() euclidean manhattan minkowski binary
##hclust() complete average median centroid ward
cutree(HC1,k=4)
[output]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 3 1 1 1 1 2 1
57 58 59 60
1 4 1 1
rect.hclust(HC1,k=3,border='red')#用红色矩形框框出聚类数为3的结果
#若已知数据为相关系数
d=dist(1-d4.3)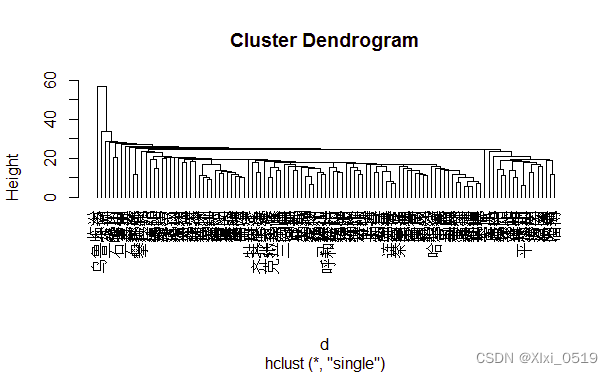
三、K均值聚类算法代码实现
k聚类法每一步均要计算类间距计算量较大,k均值聚类法相较之下更加快捷。基本思想如下:先把n个对象粗略分为k类后按照某种最优原则修改不合理的分类直至准则函数收敛。
##仍以系统聚类算法的数据为例
KM<-kmeans(d4.3,4,nstart=20,algorithm="Hartigan-Wong")
#聚类数为4,初始随机集合的个数为20,算法:Hartigan-Wong Lloyd Forgy MacQueen
KM
sort(KM$cluster)
KM<-kmeans(d4.3,5,nstart=20;sort(KM$cluster))#当聚类个数为5
四、结果对比和分析
采用系统聚类算法时,利用abline(h)函数可知合并距离为2.2和2.5时113个数据分类结果如下图
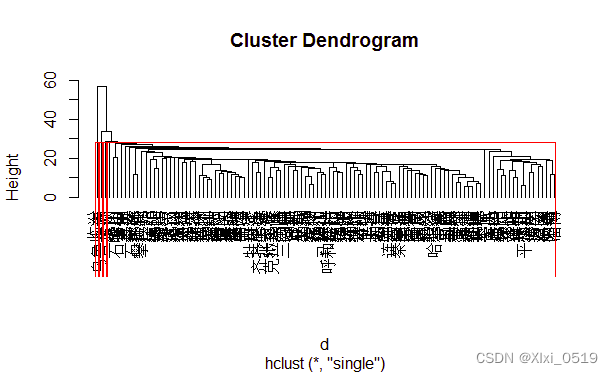
红色框圈出聚类数为3的分类结果,若合并距离取25则大致可分为三类
利用k均值聚类算法时结果如下图
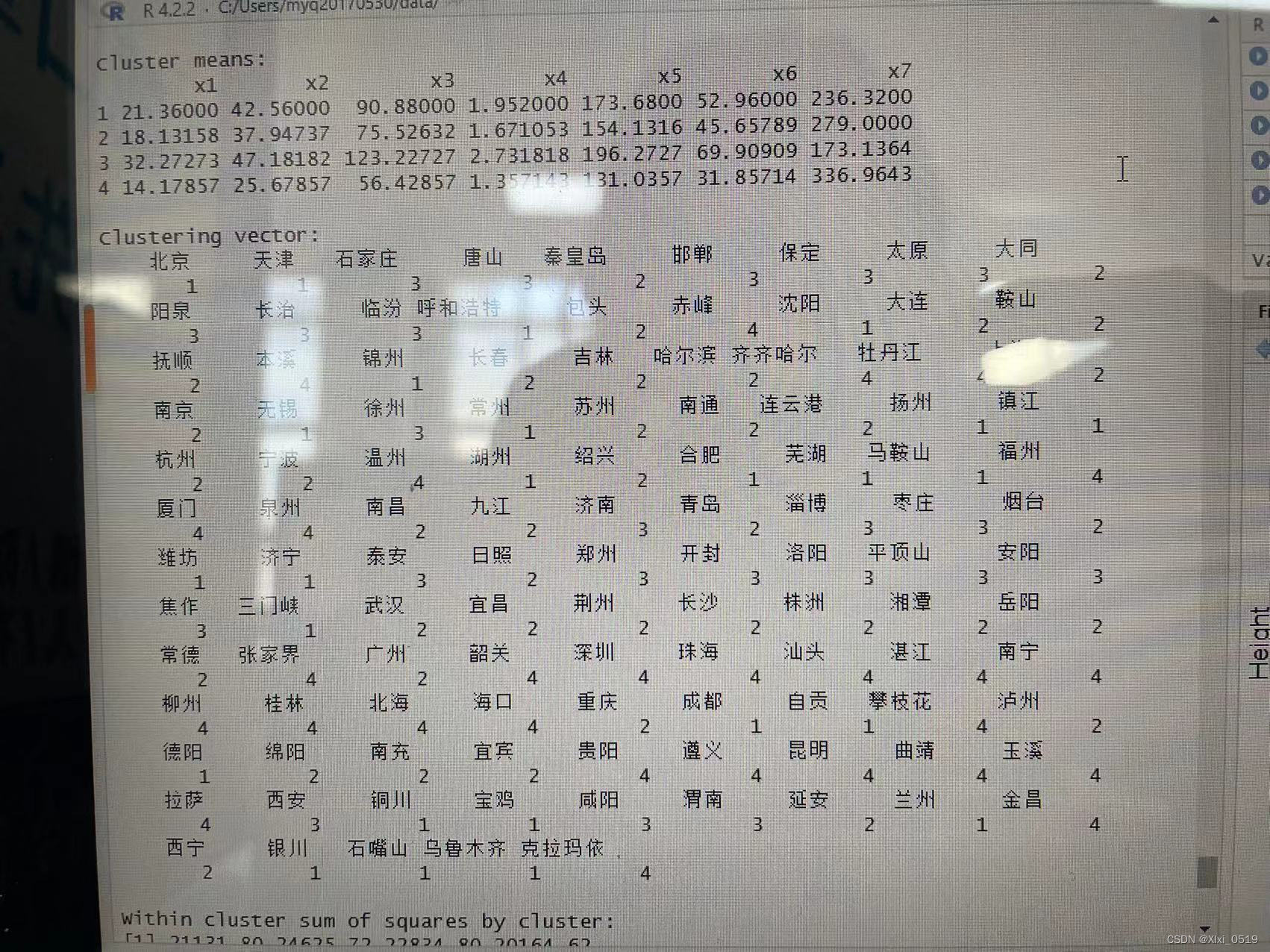
当k=4时各类的样本个数分别为25,38,22,28;means是各类的均值;Clustering Vector表示各地区原顺序聚类后的分类情况和类间平方和在总平方和中的占比,这里为85.1%(该数据越大越好)
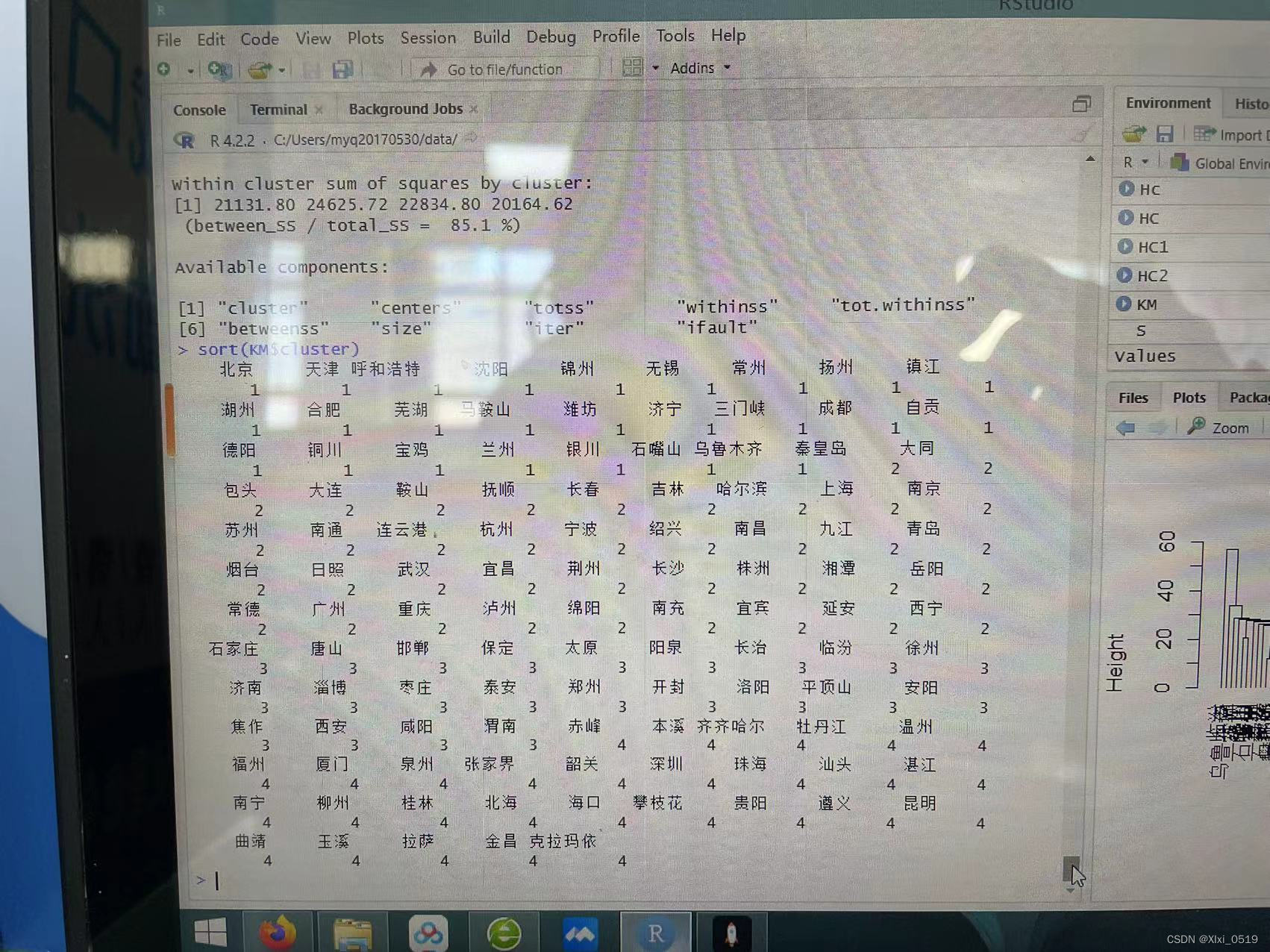
对分类结果进行排序并且查看分类情况有
第一类:北京、天津、呼和浩特
第二类:大同、南京、青岛、西宁
第三类:枣庄、唐山、石家庄
第四类:南宁、柳州、桂林、北海
若k=3则
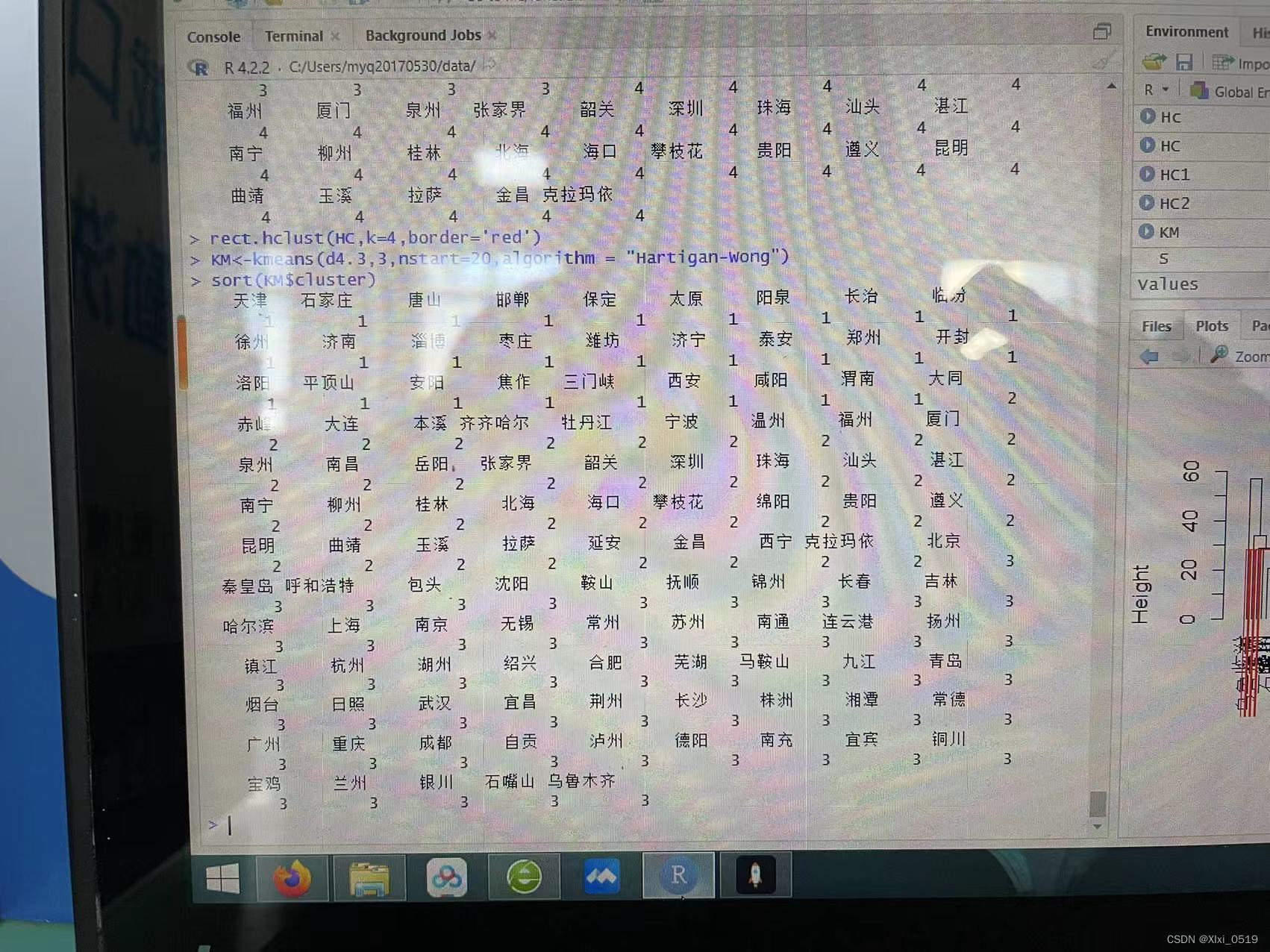
第一类:天津、石家庄、唐山
第二类:汕头、湛江、南宁
第三类:武汉、荆州、南昌
且此时和合并距离为30的聚类结果一致