
一、引言
在分布式环境下,如果舍弃SpringCloud,使用其他的分布式框架,那么注册心中,配置集中管理,集群管理,分布式锁,队列的管理想单独实现怎么办。
二、Zookeeper介绍及作用
Zookeeper本身是Hadoop生态圈的中的一个组件,Zookeeper强大的功能,在Java分布式架构中,也会频繁的使用到Zookeeper。
| Doug |
|---|
|
|

Zookeeper就是一个文件系统 + 监听通知机制
类似于nacos
作用
注册中心
配置中心
集群管理中心(hadoop master 选举机制,hbase 选举)
消息队列 (类似rabbitmq)
分布式锁
三、Zookeeper安装
1.创建docker-compose.yaml
[root@master java2109]#
mkdir docker-compose-zk1
[root@master java2109]#
cd docker-compose-zk1/
[root@master docker-compose-zk1]#
vim docker-compose.yaml
version: "3.1"
services:
zk:
image: daocloud.io/daocloud/zookeeper:latest
restart: always
container_name: zk
ports:
- 2181:2181

2.启动容器
[root@master docker-compose-zk1]#
docker-compose up

ctrl + c
停止容器,改为后台启动[root@master docker-compose-zk1]#
docker-compose up -d

3.进入容器内部
[root@yu-liu docker-compose-zk1]#
docker exec -it zk bash
4.进入Zookeeper命令行
root@aa2260a6a110:/opt/zookeeper#
cd bin/
root@aa2260a6a110:/opt/zookeeper/bin#
ls
README.txt zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.shroot@aa2260a6a110:/opt/zookeeper/bin#
./zkCli.sh
Connecting to localhost:2181


四、Zookeeper架构【
重点
】
重点
4.1 Zookeeper的架构图
每一个节点都称为znode
每一个znode中都可以存储数据
节点名称是不允许重复的
| Zookeeper的架构图 |
|---|
|
|
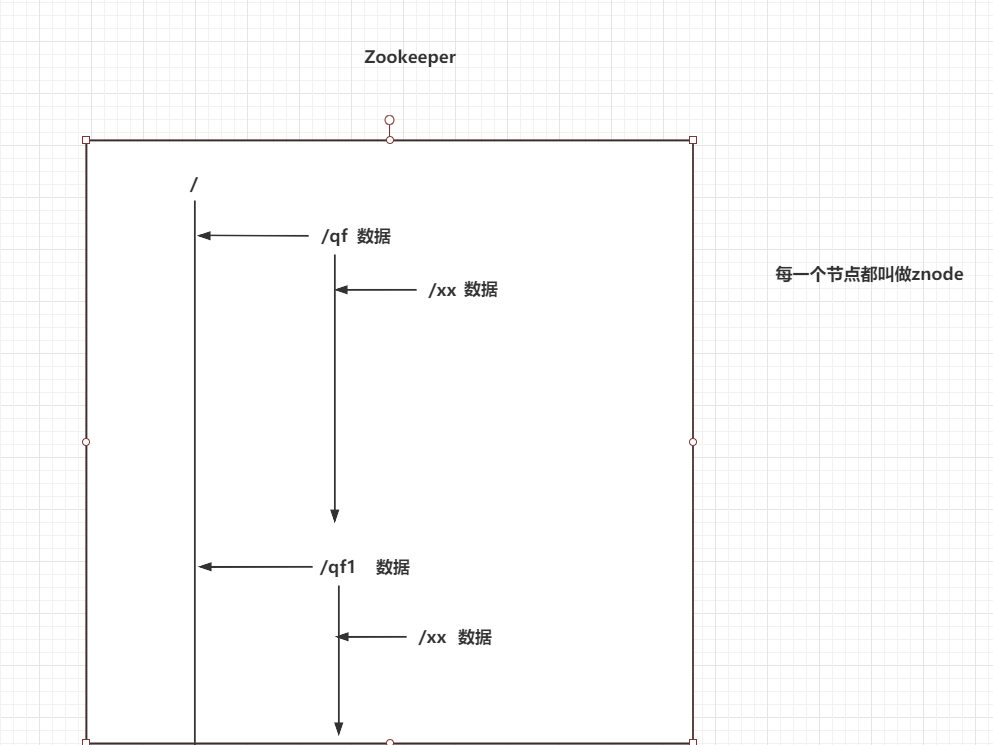

节点的类型
永久节点:一直存在
临时节点:只要客户端断开连接,节点立即删除
有序节点:节点是有序号
分为四大类 :
永久的节点,永久有序,临时节点,临时有序节点
4.2 znode类型
四种Znode
持久节点:永久的保存在你的Zookeeper
持久有序节点:永久的保存在你的Zookeeper,他会给节点添加一个有序的序号。 /xx -> /xx0000001
临时节点:当存储的客户端和Zookeeper服务断开连接时,这个临时节点自动删除
临时有序节点:当存储的客户端和Zookeeper服务断开连接时,这个临时节点自动删除,他会给节点添加一个有序的序号。 /xx -> /xx0000001
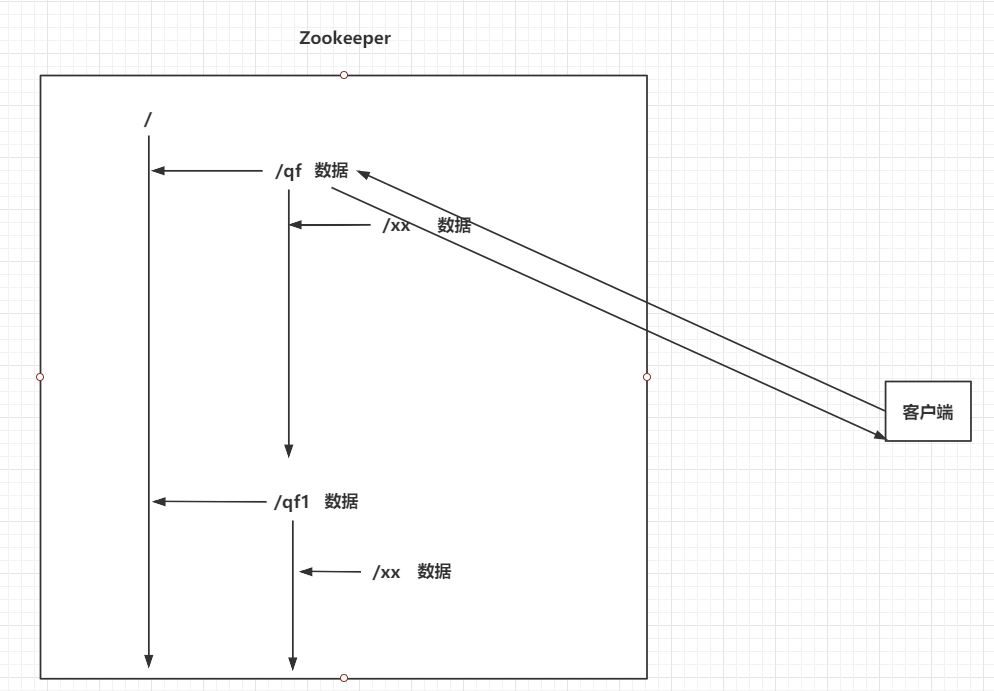
4.3 Zookeeper的监听通知机制
客户端可以去监听Zookeeper中的Znode节点。
Znode改变时,会通知监听当前Znode的客户端
| 监听通知机制 |
|---|
|
|
五、Zookeeper常用命令
Zookeeper针对增删改查的常用命令
# 查询当前节点下的全部子节点
ls 节点名称
# 例子 ls /
# 查询当前节点下的数据
get 节点名称
# 例子 get /zookeeper
# 创建节点 临时节点 当client 断开时则删除
create [-s] [-e] znode名称 znode数据
# -s:sequence,有序节点
# -e:ephemeral,临时节点
create -s -e /node1 b
# 修改节点值
set znode名称 新数据
set /node10000000001 c
# 删除节点
delete znode名称 # 没有子节点的znode
delete /node2/node1
rmr znode名称 # 删除当前节点和全部的子节点
rmr /node2

创建节点
# 创建永久节点 一定要加 /java
[zk: localhost:2181(CONNECTED) 2] create /java hellojava# 节点中在创建节点
[zk: localhost:2181(CONNECTED) 6] create /java/spring hellospring# 创建有序节点
[zk: localhost:2181(CONNECTED) 6] create -s /h5 html5



查看对应 路径下的节点列表
[zk: localhost:2181(CONNECTED) 3] ls /
获取节点中的内容
[zk: localhost:2181(CONNECTED) 9] get /java
hellojava

修改节点中的内容
[zk: localhost:2181(CONNECTED) 10] set /java hello-world
删除节点
#delete 不可以删除节点 非空的节点
[zk: localhost:2181(CONNECTED) 13] delete /java
Node not empty: /java#强制删除节点 无论是否有子节点
[zk: localhost:2181(CONNECTED) 2] rmr /java
退出命令行
[zk: localhost:2181(CONNECTED) 15] quit
六、Zookeeper集群【
重点
】
重点
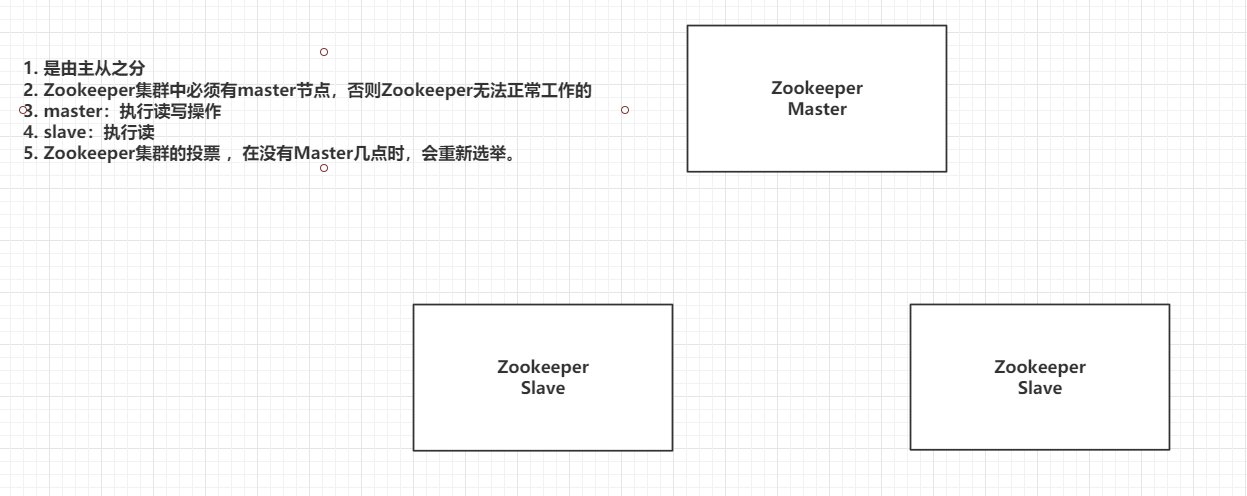
6.1 Zookeeper集群架构图
zk是文件系统,读写性能比较弱。单机有单点故障问题
| 集群架构图 |
|---|
|
|

搭建zk 集权要求:
1.zk 集群必须3台以上
2.zk 集群数量 尽量是奇数,偶数则会浪费一台
6.2 Zookeeper集群中节点的角色
Leader:Master主节点
Follower (默认的从节点):从节点,参与选举全新的Leader
Observer:从节点,不参与投票
Looking:正在找Leader节点

6.3 Zookeeper选举机制
(1)Zookeeper集群中只有超过半数以上的服务器启动,集群才能正常工作;
(2)在集群正常工作之前,myid小的服务器给myid大的服务器投票,直到集群正常工作,选出Leader;
(3)选出Leader之后,之前的服务器状态由Looking改变为Following,以后的服务器都是Follower。
参考:
Zookeeper的选举机制原理(图文深度讲解)_攻城狮Kevin-CSDN博客_zk选举机制
6.4 搭建Zookeeper集群
前提:
先将原来的zk 容器删除
[root@master java2109]# mkdir docker-compose-zk2
[root@master java2109]# cd docker-compose-zk2/
[root@master docker-compose-zk2]# ls
[root@master docker-compose-zk2]# vim docker-compose.yaml
yml文件
version: "3.1"
services:
zk1:
image: zookeeper
restart: always
container_name: zk1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk2:
image: zookeeper
restart: always
container_name: zk2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk3:
image: zookeeper
restart: always
container_name: zk3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181端口说明
1、2181:对cline端提供服务 2、3888:选举leader使用 3、2888:集群内机器通讯使用(Leader监听此端口)

2.启动
docker-compose up -d
3.新起一个窗口查看zk 的转态
[root@master ~]# docker exec -it zk1 bash
root@36dc810aaa3b:/apache-zookeeper-3.7.0-bin# ./bin/zkServer.sh status



两个疑惑?
1 zk1 是从节点,为什么可以创建节点?
2.为甚zk2 是 leader ?
6.5 zk数据写的流程
zk1 是从节点,为什么可以创建节点?

6.6 zk 集群的选举机制
选举机制:谁得到的票数多,谁就是老大
什么时候会发生选举?
集群开始创建的时候,会发生选举
当master 节点挂了也会发生选举
当从节点的数量少于一半时,master 节点会自杀
有 5个 节点 ,主节点可以收到5张票, 加入有3个slaver 挂了,就剩一个主节点,一个从节点,测试选举没有超过一半,则master 自杀
当新的节点加入集群,也会发生选举(投票),此时主节点不会变化




6.7 启动时期的 Leader 选举
选举规则:
谁的的得到的票数超过一半,谁就是master
谁的myid大,小的myid 票投给大的

集群刚启动选举过程
假设服务器依次启动,我们来分析一下选举过程:
(1)服务器1启动
发起一次选举,服务器1投自己一票,此时服务器1票数一票,不够半数以上(3票),选举无法完成。
投票结果:服务器1为1票。
服务器1状态保持为
LOOKING
。
(2)服务器2启动
发起一次选举,服务器1和2分别投自己一票,此时服务器1发现服务器2的id比自己大,更改选票投给服务器2。
投票结果:服务器1为0票,服务器2为2票。 不满足半数原则
服务器1,2状态保持
LOOKING
(3)服务器3启动
发起一次选举,服务器1、2、3先投自己一票,然后因为服务器3的id最大,两者更改选票投给为服务器3;
投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数(3票),
服务器3当选
Leader
。
服务器1,2更改状态为
FOLLOWING
,服务器3更改状态为
LEADING
。
(4)服务器4启动
发起一次选举,此时服务器1,2,3已经不是LOOKING 状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3。
服务器4并更改状态为
FOLLOWING
。
(5)服务器5启动
与服务器4一样投票给3,此时服务器3一共5票,服务器5为0票。
服务器5并更改状态为
FOLLOWING
。
最终的结果
:
服务器3是
Leader
,状态为
LEADING
;其余服务器是
Follower
,状态为
FOLLOWING
。
6.8 运行时期的集群选举机制
原则:
谁得到的票数多,谁是leader
谁的数据最新鲜(数据版本最新)谁是leader


(1)Server id(或sid):服务器ID
比如有三台服务器,编号分别是1,2,3。编号越大在选择算法中的权重越大,比如初始化启动时就是根据服务器ID进行比较。
(2)Zxid:事务ID
服务器中存放的数据的事务ID,值越大说明数据越新,在选举算法中数据越新权重越大。
(3)Epoch:逻辑时钟
也叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的,每投完一次票这个数据就会增加。
(4)Server状态:选举状态
LOOKING
,竞选状态。
FOLLOWING
,随从状态,同步leader状态,参与投票。
OBSERVING
,观察状态,同步leader状态,不参与投票。
LEADING
,领导者状态。
七、Java操作Zookeeper
7.1 Java连接Zookeeper
zk 有自己的客户端连接,但是使用起来比较麻烦不容易配置,所以我们一般都使用其他第三方的封装curator
创建Maven工程
导入依赖
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>编写连接Zookeeper集群的工具类
package com.qf.utils;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class CuratorFrameworkUtils {
/**
* CuratorFramework 就是封装的zk 客户端
*
* @return
*/
public static CuratorFramework getCuratorFramework(){
// 当客户端 和 服务端 连接异常时,会发起重试 每隔2s 重试1次,总共试 3次
RetryPolicy retryPolicy = new ExponentialBackoffRetry(2000,3);
CuratorFramework curatorFramework = CuratorFrameworkFactory.builder()
.retryPolicy(retryPolicy).connectString("192.168.134.139:2181;192.168.134.139:2182;192.168.134.139:2183").build();
curatorFramework.start();
return curatorFramework;
}
}
测试类
package com.qf;
import com.qf.utils.CuratorFrameworkUtils;
import org.apache.curator.framework.CuratorFramework;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.data.Stat;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
public class CuratorTest {
private CuratorFramework curatorFramework;
@Before
public void init(){
curatorFramework = CuratorFrameworkUtils.getCuratorFramework();
}
@Test
public void listTest() throws Exception {
// 查询某一路径下 所有结点
List<String> pathList = curatorFramework.getChildren().forPath("/");
for (String node : pathList) {
System.out.println("node = " + node);
}
}
/**
* 获取节点中的数
*/
@Test
public void getData() throws Exception {
byte[] bytes = curatorFramework.getData().forPath("/java");
System.out.println("data:"+new String(bytes,"utf-8"));
}
@Test
public void setData() throws Exception {
// 修改节点内容 返回节点状态
Stat stat = curatorFramework.setData().forPath("/java", "hello 2109".getBytes());
System.out.println(stat);
}
/**
* 创建节点 转态
*/
@Test
public void createData() throws Exception {
// PERSISTENT(0, false, false, false, false), 永久节点
// PERSISTENT_SEQUENTIAL(2, false, true, false, false), 永久有序
// EPHEMERAL(1, true, false, false, false), 临时节点
// EPHEMERAL_SEQUENTIAL(3, true, true, false, false), 临时有序
String path = curatorFramework.create()
.withMode(CreateMode.PERSISTENT)
.forPath("/java2109", "bye bye".getBytes());
System.out.println("path = " + path);
}
/**
* 删除节点
* @throws Exception
*/
@Test
public void deleteTest() throws Exception {
Void aVoid = curatorFramework.delete().forPath("/java2109");
}
@After
public void destroy(){
curatorFramework.close();
}
}