本文将手把手地教大家从零开始用Java写一个简单地爬虫!
目标
爬取全景网图片,并下载到本地
收获
通过本文,你将复习到:
IDEA创建工程IDEA导入jar包爬虫的基本原理Jsoup的基本使用File的基本使用FileOutputStream的基本使用ArrayList的基本使用foreach的基本使用说明
爬虫所用的HTM解析器为Jsoup。Jsoup可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
Jsoup相关API整理见文末附录一。
开始
一、前端分析
1、使用Chrome或其他浏览器,打开全景网,按F12进入调试模式,分析网页结构。(这里选的是“创意”=>“优山美地”)
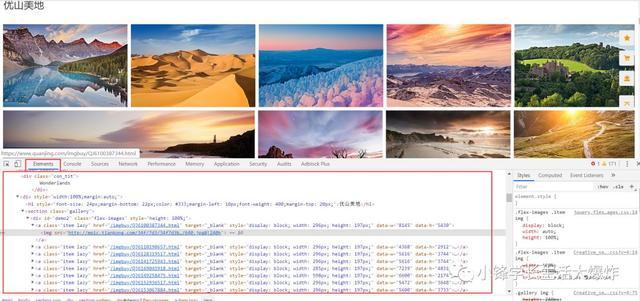
2、找规律,看图片对应的结构是什么。可以发现,每个图片的结构都如下图红框所示。
版权声明:本文为weixin_39937635原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。