1.HDFS HA 架构
1.1首先我们需要准备最起码三台机器做HDFS的高可用
ruozedata001: ZK(zookeeper) NN(namenode) zkfc(zookeeperFailoverControl) jn(JournalNode) DN(datanode)
ruozedata002: ZK(zookeeper) NN(namenode) zkfc(zookeeperFailoverControl) jn(JournalNode) DN(datanode)
ruozedata003: ZK(zookeeper) jn(JournalNode) DN(datanode)
jn: 数量需要大于等于3台 2n+1 存储active nn的日志信息。
zk: 2n+1 投票选举哪一个nn是active状态 当集群数量小于等于20台时,建议zk使用5台机器 ,当集群数量在20到100台之间,建议zk使用7/9/11台机器,当集群数量大于100台,建议zk使用11台机器。并不是zk越多越好,数量太多,会导致选举active状态的nn时间过长。最好单独部署zk在服务器上。
1.2HDFS HA架构图
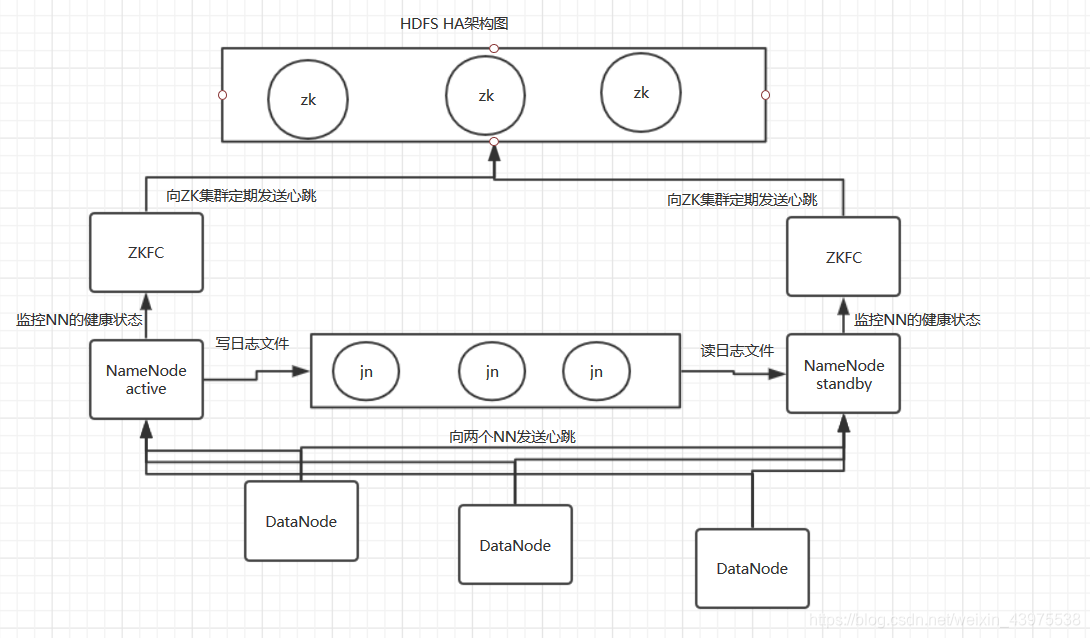
HA使用active NN, standby NN两个节点解决单点问题。两个NN节点通过JN集群,共享数据状态,通过ZKFC选举active,监控状态,自动备援。DN会同时向两个NN节点发送心跳。
active nn:
接收client的rpc请求并处理,同时自己editlog写一份,也向JN的共享存储上的editlog写一份。也同时接收DN的block report,block location updates 和 heartbeat
standby nn:
同样会接受到从JN的editlog上读取并执行这些log操作,使自己的NN的元数据和activenn的元数是同步的,使用说standby是active nn的一个热备。一旦切换为active状态,就能够立即马上对外提供NN角色的服务。也同时接收DN的block report,block location updates 和 heartbeat
jn:
用于active nn,standby nn的同步数据,本身由一组的JN节点组成的集群,奇数,最少3台(CDH),是支持Paxos协议。保证高可用。
ZKFC:
监控NN的健康状态;向ZK集群定期发送心跳 ,让自己被选举,当自己被ZK选举为主时,zkfc进程通过rpc调用让nn转换为active状态
2.YARN HA 架构
2.1需要准备最起码三台机器做YARN的高可用
ruozedata001: ZK(zookeeper) NN(namenode) zkfc(zookeeperFailoverControl) jn(JournalNode) DN(datanode) RM(ResourceManager) NM(NodeManager)
ruozedata002: ZK(zookeeper) NN(namenode) zkfc(zookeeperFailoverControl) jn(JournalNode) DN(datanode) RM(ResourceManager) NM(NodeManager)
ruozedata003: ZK(zookeeper) jn(JournalNode) DN(datanode) NM(NodeManager)
2.2YARN HA架构图

RM:
a.启动时会通过向ZK的/hadoop-ha目录写一个lock文件,写成功则为active,否则standby。standby RM会一直监控lock文件的是否存在,如果不存在就会尝试去创建,争取为active rm。
b.会接收客户端的任务请求,接收和监控nm的资源的汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)
NM:
节点上的资源的管理,启动container 容器 运行task的计算,上报资源,container情况汇报给RM和任务的处理情况汇报给 ApplicationMaster(AM)
ApplicationMaster(AM): nm机器上的container
单个application(job)的task的管理和调度,并向rm进行资源的申请,向nm发出 launch container指令,接收NM的task的处理状态信息。
RMstatestore:
a.RM的作业信息存储在ZK的/rmstore下,active RM向这个目录写app信息
b.当active rm挂了,另外一个standby rm成功转换为active rm后,会从/rmstore目录读取相应的作业信息,重新构建作业的内存信息。然后启动内部服务,开始接收NM的心跳,构建集群资源的信息,并接收客户端的提交作业的请求等。
ZKFC:
自动故障转移 只作为RM进程的一个线程 而非独立的守护进程来启动
3.HDFS HA 跟YARN HA 区别
1.HDFS HA中的ZKFS属于进程级别,YARN HA中的ZKFS属于线程级别
2.HDFS HA 中有独立数据中间件集群来进行维护,YARN HA在zk里面维护
4.总结
4.1为什么DN NM部署在同一个机器上?
保持数据本地化
4.2大数据生态圈大部分组件都是主从架构,但HBase例外,进程名:master regionserver HBase读写流程并不会经过master
4.3客户端访问NN,并不是直接访问,而是通过nameservice进行访问,nameservice并不是一个进程,而是通过配置core-site.xml和hdfs-site.xml。
4.4什么是双写
双写分为数据同步双写和结果双写
数据同步双写:分为A线跟B线 从其他地方同步数据到大数据中
结果双写:通过spark将结果保存到HBase跟es上,HBase存储所有的数据,es根据你的业务周期时间,来存储多久的数据
4.5 hdfs dfs -ls理解
hdfs dfs -ls 展示当前用户的目录下的文件
hdfs dfs -ls / 展示/目录下的文件
hdfs dfs -ls hdfs://ip:9000/ 展示的也是/目录下的文件