写在前面
语雀原文阅读效果更佳:
5、Job与CronJob · 语雀
《5、Job与CronJob》
Job 与 CronJob

接下来给大家介绍另外一类资源对象:
Job
,我们在日常的工作中经常都会遇到一些需要进行
批量数据处理和分析
的需求,当然也会有按时间来进行调度的工作。在我们的 Kubernetes 集群中为我们提供了
Job
和
CronJob
两种资源对象来应对我们的这种需求。
Job
负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。而
CronJob
则就是在
Job
上加上了时间调度。
Job和CronJob的应用场景:
Job:机器学习 CronJob:etcd/mysql backup
问题:Job可以运行在多个节点吗?
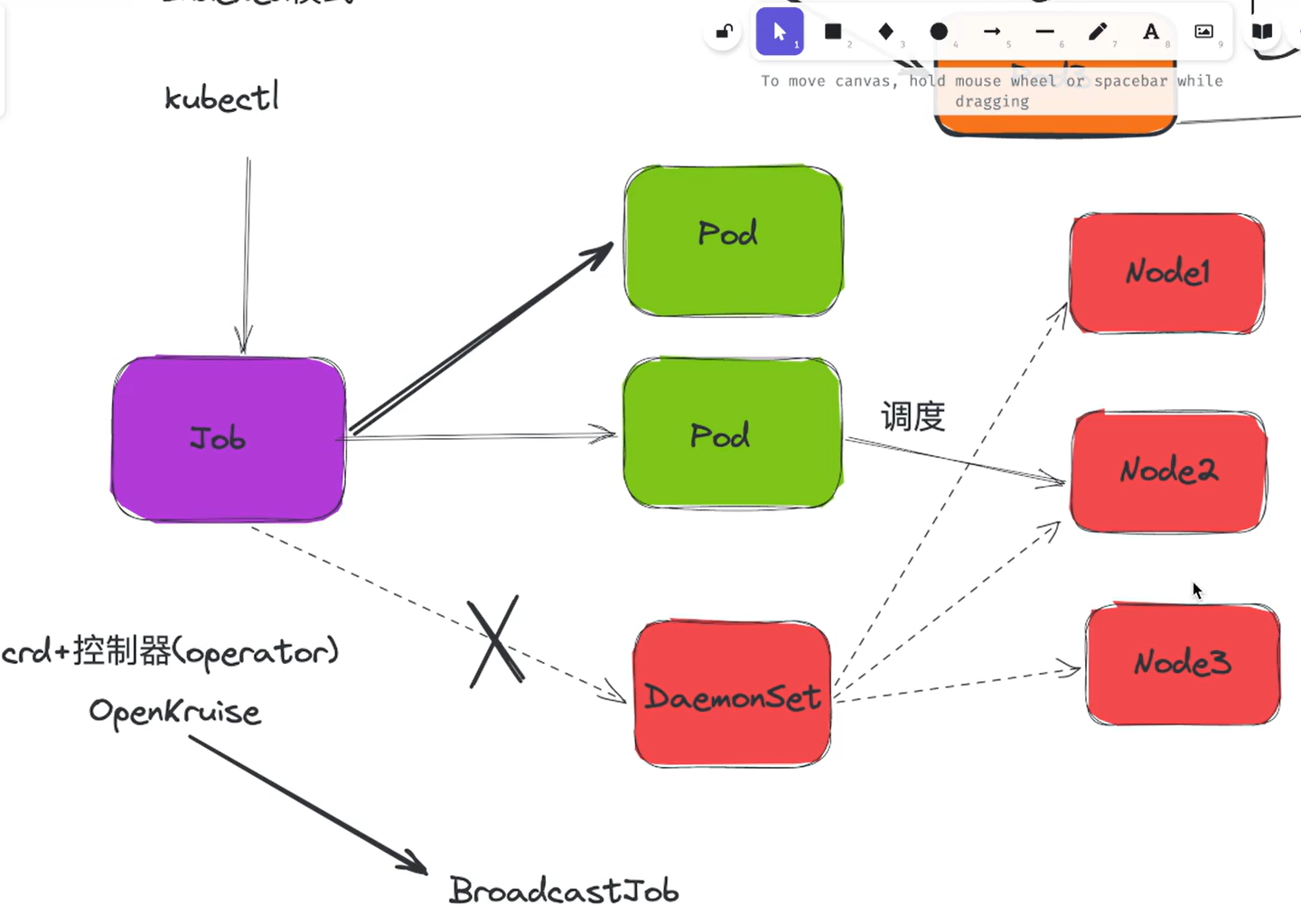
1、Job
💘 实战:Job测试-2022.12.22(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
我们用 Job 这个资源对象来创建一个如下所示的任务,该任务负责计算 π 到小数点后 2000 位,并将结果打印出来,此计算大约需要 10 秒钟完成。对应的资源清单如下所示
# job-pi.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
我们可以看到 Job 中也是一个 Pod 模板,和之前的 Deployment、StatefulSet 之类的是一致的,只是
Pod 中的容器要求是一个任务
,而不是一个常驻前台的进程了,因为需要退出。另外值得注意的是 Job 的 RestartPolicy 仅支
持
Never 和 OnFailure
两种,不支持 Always,我们知道 Job 就相当于来执行一个批处理任务,执行完就结束了,如果支持 Always 的话是不是就陷入了死循环了?
- 直接创建这个 Job 对象
[root@master1 ~]#kubectl apply -f job-pi.yaml job.batch/pi created [root@master1 ~]#kubectl get job NAME COMPLETIONS DURATION AGE pi 0/1 4s 4s [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE pi-rzsd8 0/1 ContainerCreating 0 7s
- Job 对象创建成功后,我们可以查看下对象的详细描述信息:
[root@master1 ~]#kubectl describe job pi
Name: pi
Namespace: default
Selector: controller-uid=90530e4b-1776-4221-ba69-516ecf4286ad #注意
Labels: controller-uid=90530e4b-1776-4221-ba69-516ecf4286ad
job-name=pi
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Thu, 22 Dec 2022 21:53:08 +0800
Completed At: Thu, 22 Dec 2022 21:54:02 +0800
Duration: 54s
Pods Statuses: 0 Active (0 Ready) / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=90530e4b-1776-4221-ba69-516ecf4286ad #注意
job-name=pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 2m16s job-controller Created pod: pi-rzsd8
Normal Completed 82s job-controller Job completed
可以看到,Job 对象在创建后,它的 Pod 模板,被自动加上了一个
controller-uid=< 一个随机字符串 >
这样的Label 标签,而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,从而保证了 Job 与它所管理的Pod 之间的匹配关系。而 Job 控制器之所以要使用这种携带了 UID 的 Label,就是为了避免不同 Job 对象所管理的Pod 发生重合。
- 我们可以看到隔一会儿后 Pod 变成了 Completed 状态,这是因为容器的任务执行完成正常退出了,我们可以查看对应的日志:
[root@master1 ~]#kubectl get job NAME COMPLETIONS DURATION AGE pi 1/1 54s 70s [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE pi-rzsd8 0/1 Completed 0 75s [root@master1 ~]#kubectl logs pi-rzsd8 3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
-
上面我们这里的 Job 任务对应的 Pod 在运行结束后,会变成 Completed 状态,但是如果执行任务的 Pod 因为某种原因一直没有结束怎么办呢?同样我们可以在 Job 对象中通过设置字段
spec.activeDeadlineSeconds
来限制任务运行的最长时间,比如:
spec: activeDeadlineSeconds: 100
那么当我们的任务 Pod 运行超过了 100s 后,这个 Job 的所有 Pod 都会被终止,并且的终止原因会变成
DeadlineExceeded
。
测试
activeDeadlineSeconds选项
:
这里我们卸载刚才创建的资源,然后添加下
activeDeadlineSeconds配置
,再次观察效果:
卸载资源:
[root@master1 ~]#kubectl delete -f job-pi.yaml job.batch "pi" deleted
然后添加下
activeDeadlineSeconds配置
:
# job-pi.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
#backoffLimit: 4 #先注视下这个配置
activeDeadlineSeconds: 5 #本来这个程序运行完成大概需要10s的时间,但这里activeDeadlineSeconds配置时间为5s,很明显任务会执行失败的哦。
重新部署,并观察现象:
[root@master1 ~]#kubectl apply -f job-pi.yaml
job.batch/pi created
[root@master1 ~]#kubectl get job
NAME COMPLETIONS DURATION AGE
pi 0/1 10s 10s
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
pi-pkp6w 0/1 ContainerCreating 0 4s
[root@master1 ~]#kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/pi 0/1 17s 17s
NAME READY STATUS RESTARTS AGE
pod/pi-pkp6w 0/1 Terminating 0 17s
[root@master1 ~]#kubectl get job,po
NAME COMPLETIONS DURATION AGE
job.batch/pi 0/1 37s 37s
[root@master1 ~]#kubectl describe job pi
Name: pi
Namespace: default
Selector: controller-uid=20d95fac-b232-4aa9-87a0-46f775c57981
Labels: controller-uid=20d95fac-b232-4aa9-87a0-46f775c57981
job-name=pi
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Fri, 23 Dec 2022 06:44:44 +0800
Active Deadline Seconds: 5s
Pods Statuses: 0 Active (0 Ready) / 0 Succeeded / 1 Failed
Pod Template:
Labels: controller-uid=20d95fac-b232-4aa9-87a0-46f775c57981
job-name=pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedCreate 2m6s job-controller Error creating: Unauthorized
Normal SuccessfulCreate 2m6s job-controller Created pod: pi-pkp6w
Normal SuccessfulDelete 2m1s job-controller Deleted pod: pi-pkp6w
Warning DeadlineExceeded 2m1s job-controller Job was active longer than specified deadline #可以看到,刚创建的pod会被删除,同时任务执行失败,终止原因会变成DeadlineExceeded。(👉注意:这里失败的任务的pod最后是会被删除的)
🍓 测试
restartPolicy选项
如果的任务执行失败了,会怎么处理呢,这个和定义的 restartPolicy 有关系,比如定义如下所示的 Job 任务,定义restartPolicy: Never 的重启策略:
- 配置资源清单:
# job-failed-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
backoffLimit: 6 #所以要创建6次这个pod最终才会认为这个Job是失败的。
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"] #当我们执行第一条任务的时候,失败,不重启,重新创建新的pod来跑任务。
restartPolicy: Never
- 直接创建上面的资源对象:
[root@master1 ~]#kubectl apply -f job-failed-demo.yaml
job.batch/job-failed-demo created
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
job-failed-demo-2z8dw 0/1 StartError 0 6m30s
job-failed-demo-96r5b 0/1 StartError 0 5m31s
job-failed-demo-jwpbm 0/1 StartError 0 5m52s
job-failed-demo-s97mw 0/1 StartError 0 5m12s
job-failed-demo-t4hxg 0/1 StartError 0 5m49s
job-failed-demo-tt9mb 0/1 StartError 0 6m10s
job-failed-demo-xwrl4 0/1 StartError 0 6m48s
[root@master1 ~]#kubectl get job
NAME COMPLETIONS DURATION AGE
job-failed-demo 0/1 7m3s 7m3s
[root@master1 ~]#kubectl describe job
Name: job-failed-demo
Namespace: default
Selector: controller-uid=658bbc99-11c3-4641-b79e-228d345be1c0
Labels: controller-uid=658bbc99-11c3-4641-b79e-228d345be1c0
job-name=job-failed-demo
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Fri, 23 Dec 2022 07:07:28 +0800
Pods Statuses: 0 Active (0 Ready) / 0 Succeeded / 7 Failed
Pod Template:
Labels: controller-uid=658bbc99-11c3-4641-b79e-228d345be1c0
job-name=job-failed-demo
Containers:
test-job:
Image: busybox
Port: <none>
Host Port: <none>
Command:
echo123
test failed job!
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 7m5s job-controller Created pod: job-failed-demo-xwrl4
Normal SuccessfulCreate 6m47s job-controller Created pod: job-failed-demo-2z8dw
Normal SuccessfulCreate 6m27s job-controller Created pod: job-failed-demo-tt9mb
Normal SuccessfulCreate 6m9s job-controller Created pod: job-failed-demo-jwpbm
Normal SuccessfulCreate 6m6s job-controller Created pod: job-failed-demo-t4hxg
Normal SuccessfulCreate 5m48s job-controller Created pod: job-failed-demo-96r5b
Normal SuccessfulCreate 5m29s job-controller Created pod: job-failed-demo-s97mw
Warning BackoffLimitExceeded 5m26s job-controller Job has reached the specified backoff limit #但是这里任务失败最后确实不会删除pod的,为什么呢??🤣
[root@master1 ~]#
可以看到当我们设置成 Never 重启策略的时候,
Job 任务执行失败后会不断创建新的 Pod
,但是不会一直创建下去,会根据 spec.backoffLimit 参数进行限制,默认为 6,通过该字段可以定义重建 Pod 的次数。
需要注意的是:这里的backoffLimit 参数定义为6,但通过实际测试能够看到,这里的6次为在原来失败的1次基础上再尝试6次的,也就是总共会重建1+backoffLimit 次数的。
[root@master1 ~]#kubectl explain job.spec
backoffLimit <integer>
Specifies the number of retries before marking this job failed. Defaults to
6
我们这里把
spec.backoffLimit 参数
设置为2时,也可以观察下现象,此时会看到pod被重建3次,也符合上面的结论。
# job-failed-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
backoffLimit: 2 #配置次参数
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"]
restartPolicy: Never
[root@master1 ~]#kubectl apply -f job-failed-demo.yaml
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
job-failed-demo-68nf2 0/1 StartError 0 2m47s
job-failed-demo-hs6jg 0/1 StartError 0 3m9s
job-failed-demo-r6cb8 0/1 StartError 0 3m5s
[root@master1 ~]#kubectl get job
NAME COMPLETIONS DURATION AGE
job-failed-demo 0/1 3m12s 3m12s
[root@master1 ~]#kubectl describe job job-failed-demo
Name: job-failed-demo
Namespace: default
Selector: controller-uid=61696ae7-3d18-4304-9c13-d1f317c6b730
Labels: controller-uid=61696ae7-3d18-4304-9c13-d1f317c6b730
job-name=job-failed-demo
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Fri, 23 Dec 2022 07:18:42 +0800
Pods Statuses: 0 Active (0 Ready) / 0 Succeeded / 3 Failed
Pod Template:
Labels: controller-uid=61696ae7-3d18-4304-9c13-d1f317c6b730
job-name=job-failed-demo
Containers:
test-job:
Image: busybox
Port: <none>
Host Port: <none>
Command:
echo123
test failed job!
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 3m14s job-controller Created pod: job-failed-demo-hs6jg
Normal SuccessfulCreate 3m10s job-controller Created pod: job-failed-demo-r6cb8
Normal SuccessfulCreate 2m52s job-controller Created pod: job-failed-demo-68nf2
Warning BackoffLimitExceeded 2m33s job-controller Job has reached the specified backoff limit
[root@master1 ~]#
- 但是如果我们设置的 restartPolicy: OnFailure 重启策略,则当 Job 任务执行失败后不会创建新的 Pod 出来,只会不断重启 Pod,比如将上面的 Job 任务 restartPolicy 更改为 OnFailure 后查看 Pod:
# job-failed-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
backoffLimit: 2
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"]
restartPolicy: OnFailure
- 部署并测试:
[root@master1 ~]#kubectl apply -f job-failed-demo.yaml
job.batch/job-failed-demo created
[root@master1 ~]#kubectl get po -w
NAME READY STATUS RESTARTS AGE
job-failed-demo-ldvd8 0/1 RunContainerError 0 (4s ago) 20s
job-failed-demo-ldvd8 0/1 RunContainerError 1 (1s ago) 32s
job-failed-demo-ldvd8 0/1 CrashLoopBackOff 1 (2s ago) 33s
job-failed-demo-ldvd8 0/1 RunContainerError 2 (0s ago) 62s
job-failed-demo-ldvd8 0/1 Terminating 2 (1s ago) 63s
job-failed-demo-ldvd8 0/1 Terminating 2 63s
job-failed-demo-ldvd8 0/1 Terminating 2 63s
job-failed-demo-ldvd8 0/1 Terminating 2 64s
job-failed-demo-ldvd8 0/1 Terminating 2 64s
[root@master1 ~]#kubectl get po
No resources found in default namespace.
[root@master1 ~]#kubectl get job
NAME COMPLETIONS DURATION AGE
job-failed-demo 0/1 83s 83s
[root@master1 ~]#kubectl describe job job-failed-demo
Name: job-failed-demo
Namespace: default
Selector: controller-uid=c944db54-ea48-494d-84a7-31104f4f6195
Labels: controller-uid=c944db54-ea48-494d-84a7-31104f4f6195
job-name=job-failed-demo
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Fri, 23 Dec 2022 07:27:40 +0800
Pods Statuses: 0 Active (0 Ready) / 0 Succeeded / 1 Failed
Pod Template:
Labels: controller-uid=c944db54-ea48-494d-84a7-31104f4f6195
job-name=job-failed-demo
Containers:
test-job:
Image: busybox
Port: <none>
Host Port: <none>
Command:
echo123
test failed job!
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 92s job-controller Created pod: job-failed-demo-ldvd8
Normal SuccessfulDelete 29s job-controller Deleted pod: job-failed-demo-ldvd8
Warning BackoffLimitExceeded 29s job-controller Job has reached the specified backoff limit #这里任务失败最后会删除pod的
[root@master1 ~]#
🍓 测试
spec.parallelism 参数
除此之外,我们还可以通过设置
spec.parallelism
参数来进行并行控制,该参数定义了一个 Job 在任意时间最多可以有多少个 Pod 同时运行。并行性请求(.spec.parallelism )可以设置为任何非负整数,
如果未设置,则默认为 1
,如果设置为 0,则 Job 相当于启动之后便被暂停,直到此值被增加。
spec.completions 参数可以定义 Job 至少要完成的 Pod 数目
。
- 如下所示创建一个新的 Job 任务,设置允许并行数为 2,至少要完成的 Pod 数为 8:
# job-para-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-para-test
spec:
parallelism: 2
completions: 8
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo", "test paralle job!"]
restartPolicy: Never
- 创建完成后查看任务状态:
[root@master1 ~]#kubectl apply -f job-para-demo.yaml job.batch/job-para-test created [root@master1 ~]#kubectl get po -w NAME READY STATUS RESTARTS AGE job-para-test-r7jxq 0/1 Pending 0 0s job-para-test-r7jxq 0/1 Pending 0 0s job-para-test-np7gj 0/1 Pending 0 0s job-para-test-r7jxq 0/1 ContainerCreating 0 0s job-para-test-np7gj 0/1 Pending 0 0s job-para-test-np7gj 0/1 ContainerCreating 0 0s job-para-test-r7jxq 0/1 Completed 0 16s job-para-test-np7gj 0/1 Completed 0 16s job-para-test-r7jxq 0/1 Completed 0 18s job-para-test-np7gj 0/1 Completed 0 18s job-para-test-r9l7r 0/1 Pending 0 0s job-para-test-l2r2h 0/1 Pending 0 0s job-para-test-r9l7r 0/1 Pending 0 0s job-para-test-l2r2h 0/1 Pending 0 0s job-para-test-np7gj 0/1 Completed 0 19s job-para-test-r7jxq 0/1 Completed 0 19s job-para-test-r9l7r 0/1 ContainerCreating 0 0s job-para-test-l2r2h 0/1 ContainerCreating 0 0s job-para-test-l2r2h 0/1 Completed 0 16s job-para-test-r9l7r 0/1 Completed 0 17s job-para-test-l2r2h 0/1 Completed 0 18s job-para-test-r9l7r 0/1 Completed 0 19s job-para-test-b2wq8 0/1 Pending 0 0s job-para-test-b2wq8 0/1 Pending 0 0s job-para-test-nff6l 0/1 Pending 0 0s job-para-test-nff6l 0/1 Pending 0 0s job-para-test-b2wq8 0/1 ContainerCreating 0 0s job-para-test-r9l7r 0/1 Completed 0 19s job-para-test-l2r2h 0/1 Completed 0 19s job-para-test-nff6l 0/1 ContainerCreating 0 0s job-para-test-b2wq8 0/1 Completed 0 16s job-para-test-nff6l 0/1 Completed 0 17s job-para-test-nff6l 0/1 Completed 0 18s job-para-test-b2wq8 0/1 Completed 0 18s job-para-test-hzhdf 0/1 Pending 0 0s job-para-test-hzhdf 0/1 Pending 0 0s job-para-test-6nlmx 0/1 Pending 0 0s job-para-test-6nlmx 0/1 Pending 0 0s job-para-test-b2wq8 0/1 Completed 0 19s job-para-test-nff6l 0/1 Completed 0 19s job-para-test-hzhdf 0/1 ContainerCreating 0 0s job-para-test-6nlmx 0/1 ContainerCreating 0 0s job-para-test-6nlmx 0/1 Completed 0 2s job-para-test-6nlmx 0/1 Completed 0 4s job-para-test-6nlmx 0/1 Completed 0 5s job-para-test-hzhdf 0/1 Completed 0 16s job-para-test-hzhdf 0/1 Completed 0 18s job-para-test-hzhdf 0/1 Completed 0 19s [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE job-para-test-6nlmx 0/1 Completed 0 16s job-para-test-b2wq8 0/1 Completed 0 35s job-para-test-hzhdf 0/1 Completed 0 16s job-para-test-l2r2h 0/1 Completed 0 54s job-para-test-nff6l 0/1 Completed 0 35s job-para-test-np7gj 0/1 Completed 0 73s job-para-test-r7jxq 0/1 Completed 0 73s job-para-test-r9l7r 0/1 Completed 0 54s [root@master1 ~]#kubectl get job NAME COMPLETIONS DURATION AGE job-para-test 8/8 76s 77s
可以看到一次可以有 2 个 Pod 同时运行,需要 8 个 Pod 执行成功,如果不是 8 个成功,
那么会根据restartPolicy 的策略进行处理,可以认为是一种检查机制
。
🍓
.spec.completionMode
测试
此外带有确定完成计数的 Job,即 .spec.completions 不为 null 的 Job, 都可以在其.spec.completionMode 中设置完成模式:
-
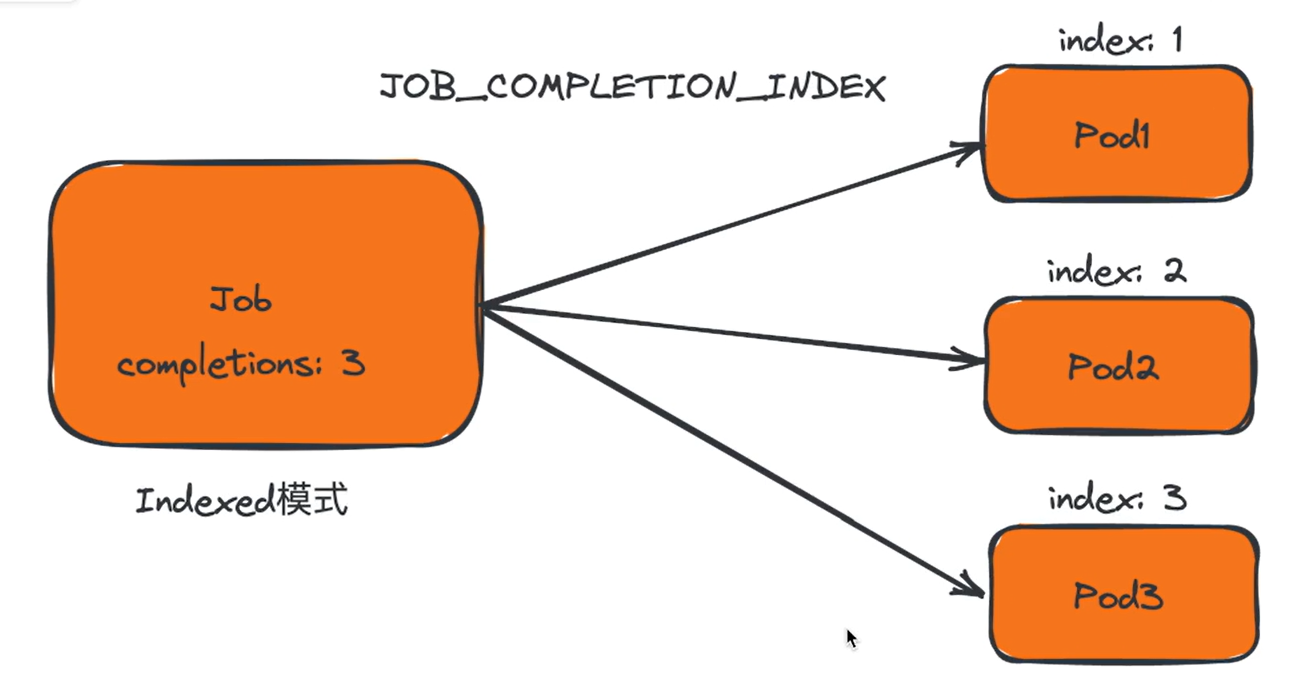
NonIndexed(默认值) :当成功完成的 Pod 个数达到 .spec.completions 所设值时认为 Job 已经完成。换言之,
每个 Job 完成事件都是独立无关且同质的
。要注意的是,当 .spec.completions 取值为 null 时,Job被默认处理为NonIndexed 模式。 -
Indexed:
Job 的 Pod 会获得对应的完成索引
,取值为 0 到 .spec.completions-1,该索引可以通过三种方式获取:
-
- Pod 的注解 batch.kubernetes.io/job-completion-index。
- 作为 Pod 主机名的一部分,遵循模式 $(job-name)-$(index)。当你同时使用带索引的 Job(IndexedJob)与服务(Service),Job 中的 Pod 可以通过 DNS 使用确切的主机名互相寻址。
-
对于容器化的任务,在环境变量
JOB_COMPLETION_INDEX
中可以获得。
当每个索引都对应一个成功完成的 Pod 时,Job 被认为是已完成的
。
索引完成模式
下面我们将运行一个使用多个并行工作进程的 Kubernetes Job,每个 worker 都是在自己的 Pod 中运行的不同容器。Pod 具有控制平面自动设置的索引编号(index number), 这些编号使得每个 Pod 能识别出要处理整个任务的哪个部分。
Pod 索引在注解 batch.kubernetes.io/job-completion-index 中呈现,具体表示为一个十进制值字符串。为了让容器化的任务进程获得此索引,我们可以使用 downward API 机制来获取注解的值。而且控制平面会自动设置 Downward API 在 JOB_COMPLETION_INDEX 环境变量中暴露索引。
- 我们这里创建一个如下所示的 Job 资源清单文件:
# job-indexed.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: indexed-job
spec:
completions: 5
parallelism: 3
completionMode: Indexed
template:
spec:
restartPolicy: Never
initContainers:
- name: "input"
image: "bash"
command:
- "bash"
- "-c"
- |
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
volumeMounts:
- mountPath: /input
name: input
containers:
- name: "worker"
image: "busybox"
command:
- "rev"
- "/input/data.txt"
volumeMounts:
- mountPath: /input
name: input
volumes:
- name: input
emptyDir: {}
在该资源清单中我们设置了 completionMode: Indexed,表示这是一个 Indexed 完成模式的 Job 任务。这里我们还使用了 Job 控制器为所有容器设置的内置 JOB_COMPLETION_INDEX 环境变量。 Init 容器将索引映射到一个静态
值,并将其写入一个文件,该文件通过 emptyDir 卷 与运行 worker 的容器共享。
rev (reverse)
命令用于将文件中的每行内容以字符为单位反序输出,即第一个字符最后输出,最后一个字符最先输出,以此类推。
- 直接创建该资源对象并验证:
[root@master1 ~]#kubectl apply -f job-indexed.yaml job.batch/indexed-job created [root@master1 ~]#kubectl get job NAME COMPLETIONS DURATION AGE indexed-job 0/5 21s 21s
当你创建此 Job 时,控制平面会创建一系列 Pod,你指定的每个索引都会运行一个 Pod。.spec.parallelism 的值决定了一次可以运行多少个 Pod, 而 .spec.completions 决定了 Job 总共创建了多少个 Pod。
因为 .spec.parallelism 小于 .spec.completions, 所以控制平面在启动更多 Pod 之前,将等待第一批的某些Pod 完成。
[root@master1 ~]#kubectl get po -w NAME READY STATUS RESTARTS AGE indexed-job-0-cfnjb 0/1 Pending 0 0s indexed-job-0-cfnjb 0/1 Pending 0 0s indexed-job-2-hgf5b 0/1 Pending 0 0s indexed-job-1-bzszz 0/1 Pending 0 0s indexed-job-2-hgf5b 0/1 Pending 0 0s indexed-job-1-bzszz 0/1 Pending 0 0s indexed-job-0-cfnjb 0/1 Init:0/1 0 0s indexed-job-2-hgf5b 0/1 Init:0/1 0 0s indexed-job-1-bzszz 0/1 Init:0/1 0 0s indexed-job-2-hgf5b 0/1 PodInitializing 0 1s indexed-job-0-cfnjb 0/1 PodInitializing 0 1s indexed-job-1-bzszz 0/1 PodInitializing 0 16s indexed-job-0-cfnjb 0/1 Completed 0 17s indexed-job-0-cfnjb 0/1 Completed 0 19s indexed-job-3-fmktp 0/1 Pending 0 0s indexed-job-3-fmktp 0/1 Pending 0 0s indexed-job-0-cfnjb 0/1 Completed 0 20s indexed-job-3-fmktp 0/1 Init:0/1 0 0s indexed-job-2-hgf5b 0/1 Completed 0 32s indexed-job-2-hgf5b 0/1 Completed 0 34s indexed-job-4-htzhm 0/1 Pending 0 0s indexed-job-4-htzhm 0/1 Pending 0 0s indexed-job-2-hgf5b 0/1 Completed 0 35s indexed-job-4-htzhm 0/1 Init:0/1 0 0s indexed-job-3-fmktp 0/1 PodInitializing 0 16s indexed-job-3-fmktp 0/1 Completed 0 17s indexed-job-3-fmktp 0/1 Completed 0 19s indexed-job-3-fmktp 0/1 Completed 0 20s indexed-job-1-bzszz 0/1 Completed 0 47s indexed-job-4-htzhm 0/1 PodInitializing 0 12s indexed-job-1-bzszz 0/1 Completed 0 49s indexed-job-1-bzszz 0/1 Completed 0 50s indexed-job-4-htzhm 0/1 Completed 0 28s indexed-job-4-htzhm 0/1 Completed 0 30s indexed-job-4-htzhm 0/1 Completed 0 31s [root@master1 ~]#kubectl get po NAME READY STATUS RESTARTS AGE indexed-job-0-cfnjb 0/1 Completed 0 84s indexed-job-1-bzszz 0/1 Completed 0 84s indexed-job-2-hgf5b 0/1 Completed 0 84s indexed-job-3-fmktp 0/1 Completed 0 64s indexed-job-4-htzhm 0/1 Completed 0 49s [root@master1 ~]#kubectl get job NAME COMPLETIONS DURATION AGE indexed-job 5/5 66s 97s
创建 Job 后,稍等片刻,就能检查进度:
[root@master1 ~]#kubectl describe job indexed-job
Name: indexed-job
Namespace: default
Selector: controller-uid=be1f722a-a889-42e5-bc25-e242c8d3cc63
Labels: controller-uid=be1f722a-a889-42e5-bc25-e242c8d3cc63
job-name=indexed-job
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 3
Completions: 5
Completion Mode: Indexed
Start Time: Fri, 23 Dec 2022 21:18:30 +0800
Completed At: Fri, 23 Dec 2022 21:19:36 +0800
Duration: 66s
Pods Statuses: 0 Active (0 Ready) / 5 Succeeded / 0 Failed
Completed Indexes: 0-4
Pod Template:
Labels: controller-uid=be1f722a-a889-42e5-bc25-e242c8d3cc63
job-name=indexed-job
Init Containers:
input:
Image: bash
Port: <none>
Host Port: <none>
Command:
bash
-c
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Containers:
worker:
Image: busybox
Port: <none>
Host Port: <none>
Command:
rev
/input/data.txt
Environment: <none>
Mounts:
/input from input (rw)
Volumes:
input:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 116s job-controller Created pod: indexed-job-0-cfnjb
Normal SuccessfulCreate 116s job-controller Created pod: indexed-job-1-bzszz
Normal SuccessfulCreate 116s job-controller Created pod: indexed-job-2-hgf5b
Normal SuccessfulCreate 96s job-controller Created pod: indexed-job-3-fmktp
Normal SuccessfulCreate 81s job-controller Created pod: indexed-job-4-htzhm
Normal Completed 50s job-controller Job completed
这里我们使用的每个索引的自定义值运行 Job,我们可以检查其中一个 Pod 的输出:
[root@master1 ~]#kubectl logs indexed-job-3-fmktp xuq
我们在初始化容器中执行了如下所示的命令:
items=(foo bar baz qux xyz)
echo ${items[$JOB_COMPLETION_INDEX]} > /input/data.txt
当 JOB_COMPLETION_INDEX=3 的时候表示我们将 items[3] 的 qux 值写入到了 /input/data.txt 文件中,然后通过 volume 共享,在主容器中我们通过 rev 命令将其反转,所以输出结果就位 xuq 了。
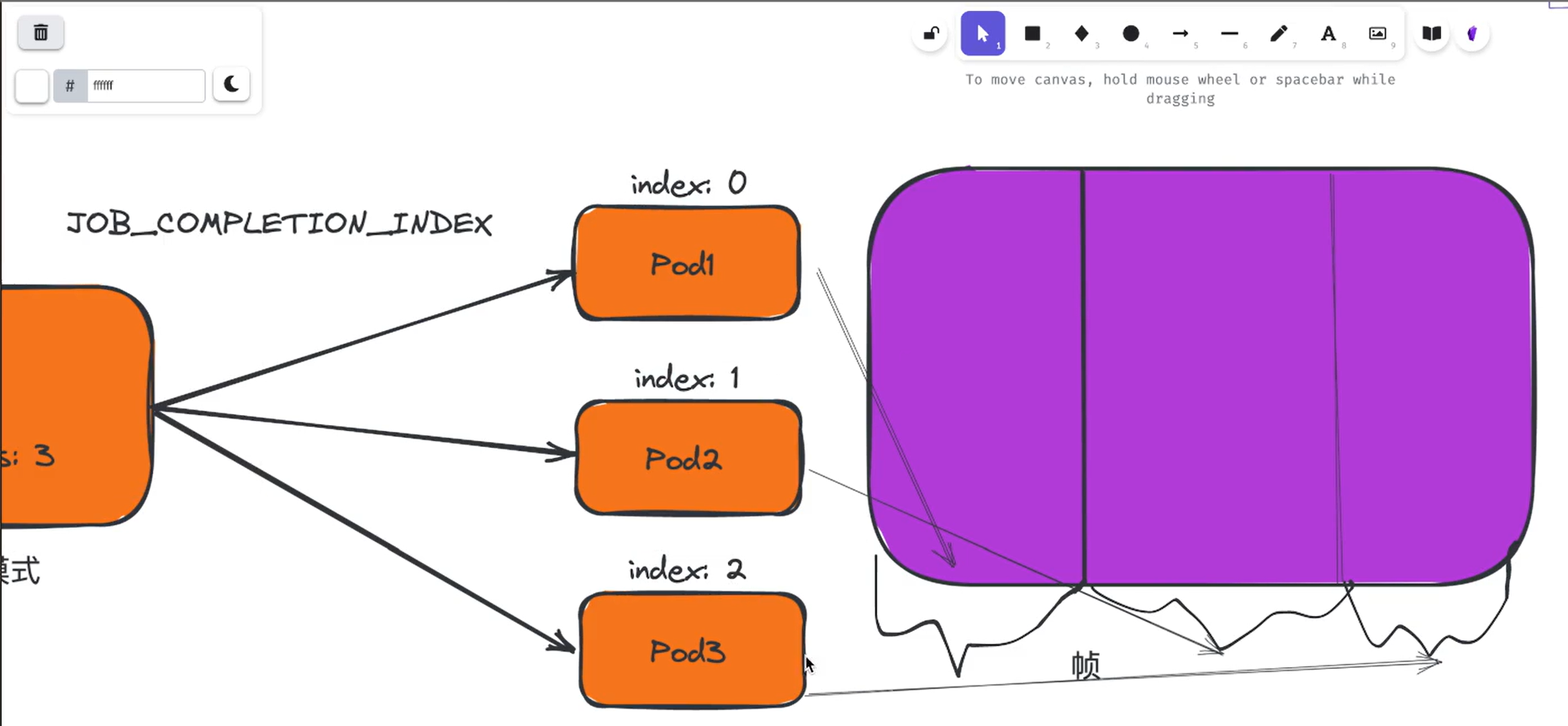
上面我们这个示例中每个 Pod 只做一小部分工作(反转一个字符串)。 在实际工作中肯定比这复杂,比如你可能会创建一个基于场景数据制作 60 秒视频任务的 Job,此视频渲染 Job 中的每个工作项都将渲染该视频剪辑的特定帧,索引完成模
式意味着 Job 中的每个 Pod 都知道通过从剪辑开始计算帧数,来确定渲染和发布哪一帧,这样就可以大大提高工作任务的效率。
2、CronJob
CronJob
其实就是在
Job
的基础上加上了时间调度,我们可以在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。这个实际上和我们 Linux 中的
crontab
就非常类似了。
一个
CronJob
对象其实就对应中
crontab
文件中的一行,它根据配置的时间格式周期性地运行一个
Job
,格式和
crontab
也是一样的。
crontab 的格式为:
分 时 日 月 星期 要运行的命令
。
# ┌───────────── 分钟 (0 - 59) # │ ┌───────────── 小时 (0 - 23) # │ │ ┌───────────── 月的某天 (1 - 31) # │ │ │ ┌───────────── 月份 (1 - 12) # │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日) # │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat # │ │ │ │ │ # │ │ │ │ │ # * * * * *
- 第1列分钟 0~59
- 第2列小时 0~23
- 第3列日 1~31
- 第4列月 1~12
- 第5列星期 0~7(0和7表示星期天)
- 第6列要运行的命令
所有 CronJob 的 schedule 时间都是基于 kube-controller-manager 的时区
,如果你的控制平面在 Pod 中运行了 kube-controller-manager, 那么为该容器所设置的时区将会决定 CronJob 的控制器所使用的时区。官方并不支持设置如 CRON_TZ 或者 TZ 等变量,这两个变量是用于解析和计算下一个 Job 创建时间所使用的内部库中一个实现细节,不建议在生产集群中使用它。
但是如果在 kube-controller-manager 中启用了
CronJobTimeZone
这个 Feature Gates,那么我们就可以为CronJob 指定一个时区(如果你没有启用该特性门控,或者你使用的是不支持试验性时区功能的 Kubernetes 版本,集群中所有 CronJob 的时区都是未指定的)。启用该特性后,你可以将 spec.timeZone 设置为有效时区名称。
💘 实战:CronJob测试-2022.12.22(成功测试)
- 实验环境
1、win10,vmwrokstation虚机; 2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点 k8s version:v1.20 CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
-
老样子,首先我们来看下
CronJob
的字段:
[root@master1 ~]#kubectl explain CronJob.spec
FIELDS:
concurrencyPolicy <string>
Specifies how to treat concurrent executions of a Job. Valid values are: -
"Allow" (default): allows CronJobs to run concurrently; - "Forbid": forbids
concurrent runs, skipping next run if previous run hasn't finished yet; -
"Replace": cancels currently running job and replaces it with a new one
#单词说明:concurrentcy 并发,并行 executions执行册数,运行次数
failedJobsHistoryLimit <integer>
The number of failed finished jobs to retain. Value must be non-negative
integer. Defaults to 1.
#单词说明:non-negative非负的,正的
jobTemplate <Object> -required->
Specifies the job that will be created when executing a CronJob.
schedule <string> -required->
The schedule in Cron format, see https://en.wikipedia.org/wiki/Cron.
startingDeadlineSeconds <integer>
Optional deadline in seconds for starting the job if it misses scheduled
time for any reason. Missed jobs executions will be counted as failed ones.
successfulJobsHistoryLimit <integer>
The number of successful finished jobs to retain. Value must be
non-negative integer. Defaults to 3.
suspend <boolean>
This flag tells the controller to suspend subsequent executions, it does
not apply to already started executions. Defaults to false.
#单词说明:suspend v.悬挂;暂停,中止 subsequent 分布式
[root@master1 ~]#
-
现在,我们用
CronJob
来管理我们上面的
Job
任务,定义如下所示的资源清单:
# cronjob-demo.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-demo
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: hello
image: busybox
args:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
这里的 Kind 变成了
CronJob
了,要注意的是
.spec.schedule
字段是必须填写的,用来指定任务运行的周期
,格式就和
crontab
一样。另外一个字段是
.spec.jobTemplate
, 用来指定需要运行的任务,格式当然和
Job
是一致的。还有一些值得我们关注的字段
.spec.successfulJobsHistoryLimit
(默认为3) 和
.spec.failedJobsHistoryLimit
(默认为1),表示历史限制,是可选的字段,指定可以保留多少完成和失败的
Job
。然而,当运行一个
CronJob
时,
Job
可以很快就堆积很多,
所以一般推荐设置这两个字段的值
,如果设置限制的值为 0,那么相关类型的
Job
完成后将不会被保留。
- 我们直接新建上面的资源对象:
[root@master1 ~]#kubectl apply -f cronjob-demo.yaml cronjob.batch/cronjob-demo created
- 然后可以查看对应的 Cronjob 资源对象:
[root@master1 ~]#kubectl get cronjobs NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE cronjob-demo */1 * * * * False 1 14s 16s
- 稍微等一会儿查看可以发现多了几个 Job 资源对象,这个就是因为上面我们设置的 CronJob 资源对象,每1分钟执行一个新的 Job:
[root@master1 ~]#kubectl get po,job NAME READY STATUS RESTARTS AGE pod/cronjob-demo-27291254--1-m54nz 0/1 Completed 0 79s pod/cronjob-demo-27291255--1-m8l8v 0/1 ContainerCreating 0 19s NAME COMPLETIONS DURATION AGE job.batch/cronjob-demo-27291254 1/1 22s 79s job.batch/cronjob-demo-27291255 0/1 19s 19s [root@master1 ~]# 再过一段时间查看: [root@master1 ~]#kubectl get po,job NAME READY STATUS RESTARTS AGE pod/cronjob-demo-27291254--1-m54nz 0/1 Completed 0 2m10s pod/cronjob-demo-27291255--1-m8l8v 0/1 Completed 0 70s pod/cronjob-demo-27291256--1-d449d 0/1 ContainerCreating 0 10s NAME COMPLETIONS DURATION AGE job.batch/cronjob-demo-27291254 1/1 22s 2m10s job.batch/cronjob-demo-27291255 1/1 21s 70s job.batch/cronjob-demo-27291256 0/1 10s 10s [root@master1 ~]#
- 这个就是 CronJob 的基本用法,一旦不再需要 CronJob,我们可以使用 kubectl 命令删除它:
[root@master1 ~]#kubectl delete cronjob cronjob-demo cronjob "cronjob-demo" deleted
不过需要注意的是这将会终止正在创建的 Job,但是运行中的 Job 将不会被终止,不会删除 Job 或 它们的 Pod。
测试结束。😘
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 语雀
语雀博客 · 语雀
《语雀博客》

🍀 博客
www.onlyyou520.com
🍀 csdn
一念一生~one的博客_CSDN博客-k8s,Linux,git领域博主
🍀 知乎

最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
