C/S存在可扩展性、可靠性等的问题,随着用户的数量越多,服务器就容易负担很重,无法支持很多的用户,如果服务器摊掉的话整个业务就无法运行。
P2P的任何一个节点同时是客户端也是服务器,所以随着用户的数量的增加,请求的节点增加,提供服务的节点也增加。可靠性高,没有一个集中式的服务器,流量是分布式的,提供的业务是由成千上万个peer节点提供的,很难把P2P系统搞摊,而C/S模式只需要把服务器搞摊,整个业务就无法运行。
纯P2P架构
-
没有(或极少)一直运行的服务器
-
任意端系统都可以直接通信
-
利用peer的服务能力
-
peer节点间歇上网,每次IP地址都有可能变化
例子:
-
-
文件分发(BitTorrent)
-
流媒体(KanKan)
-
VoIP(Skype)
-
文件分发:C/S vs P2P
问题:
从一台服务器分发文件(大小F)到N个peer需要多少时间?
-
peer节点上下载能力是有限的资源
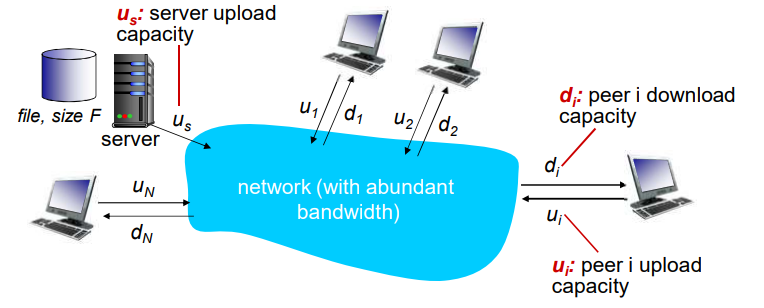
上载带宽是ui,下载带宽是di
文件分发时间:C/S模式
【所有用户都是从服务器下载,整个的下载时间他有一个下限,最终的时间是大于等于这个下限的,理论上的下限,最少需要花这么多时间】
-
服务器传输:
都是由服务器发送给peer,服务器必须顺序传输(上载)N个文件拷贝:

-
客户端:
每个客户端必须下载一个文件拷贝


【用户数量(文件拷贝数量)非常少的时候,客户端的下载速度就是瓶颈;文件拷贝数量非常大的时候,服务器上载速度就是瓶颈,这时候客户端的下载时间相对服务器尚在时间已经可以忽略了】
文件分发时间:P2P模式
-
服务器传输:
最少需要上载一份拷贝
![]()
-
客户端:
每个客户端必须下载一个拷贝
![]()
-
客户端:
所有客户端总体下载量ND
【us + Σui :所有客户端服务器都能提供上载服务】
![]()

Client – Server vs P2P:例子
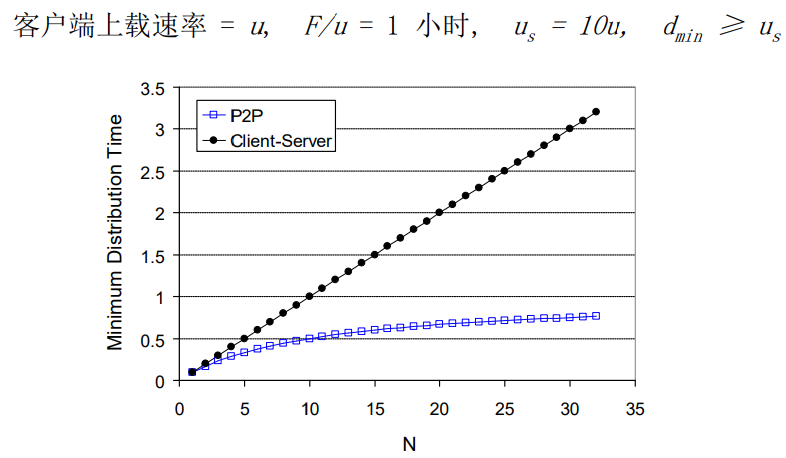
【C/S模式各个结点下载文件的时间,随着n的增加,线性的增加】
【P2P模式:随着n的数量的增加,请求资源的数量在增加,请求资源的节点同时又是提供服务的结点,n的数量越多,P2P比C/S模式节约的时间就越多】
【以文件分发作为例子来说,视频的分发、视频的点播、实时音视频的传播也是同样的道理,P2P比C/S效果要好、性能要高。P2P具备可扩展性,因为在C/S模式下随着客户端的数量的增加,大家都要从服务器那里去下载,因此服务器的服务能力就会变成瓶颈,那么在P2P模式下,随着n的增加,请求资源节点的数量在增加,同时提供服务的节点也在增加,因此整个P2P系统很容易扩充到几千万用户的一个级别】
【P2P比C/S可扩展性要高、性能要好,但是他可管理性不好,因为用户太多,而且节点有时候上线,有时候下线,汇集在P2P系统经常就是动态的,上线之后他具备的资源才能为其他节点提供服务、上线与下线的用户资源、带宽又不同】
【P2P分为非结构化P2P和DHT(结构化)P2P。】
【非结构化P2P:Peer节点和其他peer节点构成邻居关系,就是两个peer之间有一个会话,两个就互为对方的邻居,通过会话的合作关系,相互协作、互通有无。应用层角度来看,我这个peer节点和你这个peer节点建立的tcp的连接或者HTTP的文件的分发关系,就构成了一条边,我们构成一个覆盖网(overlay)。所谓的覆盖网就是应用层面上的一个逻辑的网络,我是一个节点,你是一个节点,我和你之间有一个互通有无的关系,我向你提供文件上载,你向我提供文件下载,我们之间就有条边的关系,这种应用层上面的逻辑的网络,我们就叫他overlay。】
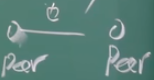
【这个边指的是peer跟peer的协作关系,这种网络是逻辑的网络,不是物理的网络。因为图上这两个节点之间就一跳,边就一条边,但实际上两个peer之间可能经过很多个路由器,很多的物理网络的边,他才能吧两者连在一起,所以说是一个覆盖网。】
【非结构化的P2P:peer节点和peer节点构成的覆盖网络,节点跟节点之间边的关系,是任意的。peer节点所构成的overlay是随机的,我们把它称为非结构化的P2P】
【结构化(DHT)的P2P:peer节点和peer节点可以构成有序的overlay,可以构成一个环、树、或者不断嵌入的关系】
P2P文件共享
例子
-
Alice在其笔记本电脑上运行P2P客户端程序
-
间歇性地连接到Internet,每次从其ISP得到新的IP地址
-
请求“双截棍.MP3”
-
应用程序显示其他有“双截棍.MP3”拷贝的对等方
-
Alice选择其中一个对等方,如Bob.
-
文件从Bob’s PC传送到Alice的笔记本上:HTTP
-
当Alice下载时,其他用户也可以从Alice处下载
-
Alice的对等方既是一个Web客户端,也是一个瞬时Web服务器
所有的对等方都是服务器 = 可扩展性好!
两大问题
-
如何定位所需资源
-
如何处理对等方的加入与离开
可能的方案
-
集中
-
分散
-
半分散
P2P:集中式目录
【Alice在Napster客户端当中键入关键字,然后目录服务器就会返回响应结果,告诉Alice哪些客户端具备这些资源,Napster就会自动的从这些peer节点请求这个文件,去下载,这样Alice就具备了这个文件。】
最初的“Napster”设计
1. 当对等方连接时,它告知中心服务器:
-
IP地址
-
内容
2. Alice查询“双截棍.MP3”
3. Alice从Bob处请求文件
【中心服务器要知道上线的peer节点的IP地址,还要知道每个节点所具备的资源,每个节点需要上报这两个信息:我的IP(我是活的)、我这个IP具备的资源。所以目录服务器就要维护这些信息:哪些IP在线,哪些IP具有哪些资源。下线的时候还要告诉目录服务器我下线了。所以目录服务器维护的就是有效的所有在线的Napster客户端。】
【这种模式下,目录服务是集中式的,而文件分发是P2P模式的】
P2P:集中式目录中存在的问题
-
单点故障
-
性能瓶颈
-
侵犯版权【因为是集中式的,所以可以很快定位到哪个peer节点侵权,所以很容易被告】
文件传输是分散的,而定位内容则是高度集中的
P2P:完全分布式
完全分布式的一个例子——查询洪泛:Gnutella
【所有节点都一样,没有任何一个节点维护一个全局的目录信息。所有的节点首先构建起一个overlay,每个peer大概有8-10个邻居。】
-
全分布式
-
没有中心服务器
-
-
开放文件共享协议【代码是开放的,所以所有人都可以下载来剖析他、看他。因为是open的,所以他的协议也是公开的,实现也是开源的方式来实现的。所以有很多Gnutella的变种,只要遵守协议,不同的Gnutella的版本都可以协作。】
-
许多Dnutella客户端实现了Gnutella协议
-
类似HTTP有许多的浏览器
-
覆盖网络:图
-
如果x和y之间有一个TCP连接,则二者之间存在一条边
-
所有活动的对等方和边就是覆盖网络
-
边不是物理链路
-
给定一个对等方,通常所连接的节点少于10个
Gnutella:协议
-
在已有的TCP连接上发送查询报文
-
对等方转发查询报文
-
以反方向返回查询命中报文
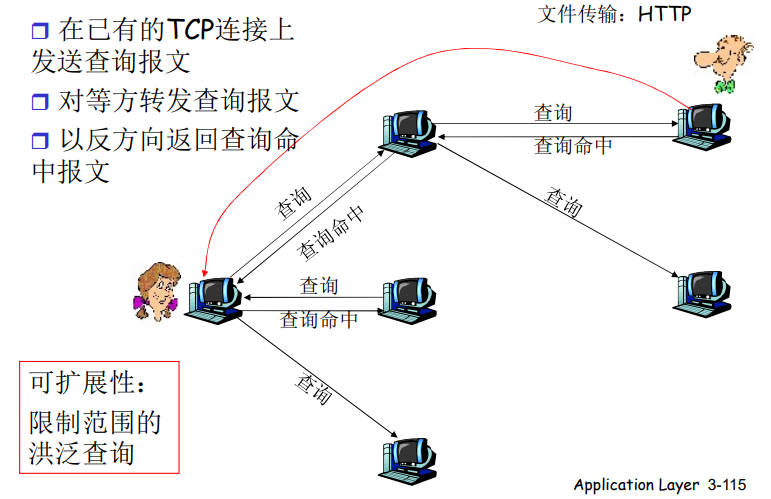
【假如overlay已经建立起来了,Alice要查询某个资源,她向她所有的邻居发出查询(除了root这一端),她的邻居收到查询之后,再向她所有的邻居(Alice的邻居的邻居)发出查询,我们把这种方式叫做泛洪。这样很快遍布全网,拥有这个资源的节点反向给出应答。Alice就知道哪些节点有,目录的问题就解决了,解决了拥有的问题之后,再向拥有这些资源的节点发出请求,他再给Alice发出相应,这个文件Alice就有了。】
【这种泛洪太耽误时间,很可能绕回来或者遍布全网,解决方法就是TTL,每个n跳就结束了,就不再查了,有限的泛洪。另一种方法是,让中转的节点记住,下次再绕回来的时候就不再泛洪了。还有很多种方法可以限制泛洪的作用,同时又能有效的把查询包遍及全网】
Gnutella:对等方加入
【如何建立overlay?答:安装Gnutella软件,同时安装软件配置了死党列表,加入Gnutella网络的节点要向死党列表发出ping,所有收到ping的节点,一方面向原节点发出pong,另外一方面转发ping,所有收到ping的节点都要向原节点发出pong,然后随机地选取若干节点8-10个,按照协议跟他做邻居关系,这样构建overlay】
1. 对等方x必须首先发现某些已经在覆盖网络中的其他对等方:使用可用对等方列表
自己维持一张对等方列表(经常开机的对等方的IP)
联系维持列表的Gnutella站点
2. x接着试图与该列表上的对等方建立TCP连接,直到与某个对等方y建立连接
3. x向y发送一个ping报文,y转发该ping报文
4. 所有收到ping报文的对等方以pong报文响应
IP地址、共享文件和数量以及总字节数
5. x收到许多pong报文,然后它能建立其他TCP连接
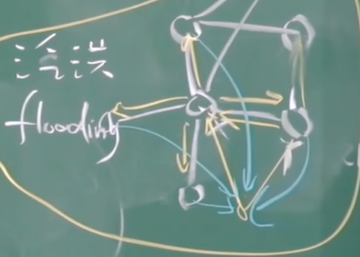
黄线:ping,蓝线:pong
对等方离开?
【对等方向他的8-10个邻居说下线,邻居知道他的有序离开,他再从网络再挑一个节点补充一下从,这样的话,维持一个连接强度,使得他的度能够满足他在网络正常运行的最低要求。】
【目录查询和文件分发都是采用P2P的方式,但是这个网络理论上很好,可是实际上运行非常不成功,既有技术上的问题,也有非技术上的问题,主要是技术上的问题。】
P2P:混合式
利用不匀称性:KaZaA
-
每个对等方要么是一个组长,要么隶属于一个组长【这些组员都属于某个组】
-
对等方与组长之间有TCP连接【类似Napster】
-
组长对之间有TCP连接【类似Gnutella】
-
-
组织跟踪其所有的孩子的内容【组员向组长发出查询,那么组长就跟组员说这个查询在组内有,你去负责向他们提出请求】
-
组长与其他组长联系
-
转发查询到其他组长【如果组长发现组内没有,他就再向其他组长发出查询】
-
获得其他组长的数据拷贝
-
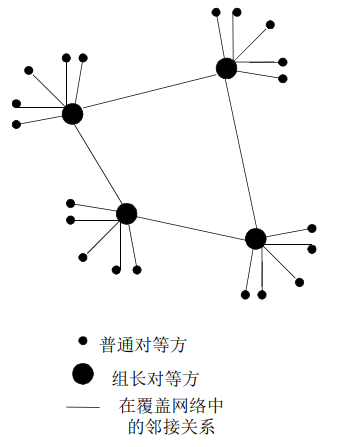
【组内是集中式的,组长之间是分布式的,采用这种方法可以提高他的查询速率】
KaZaA:查询
-
每个文件有一个散列标识码和一个描述符【描述符:这个文件是干什么的;哈希值是作为文件的唯一标识】【资源的提供方除了提供资源本身之外,还需要提供资源的一些描述(源信息)】【文件本身在上载文件的时候需要,文件的描述,在上载文件建目录的时候也是需要的,文件在上载之后要建索引的时候把哈希值算出来,这个ID值是作为文件的唯一标识】
-
客户端向其组长发送关键字查询【匹配描述,组长把匹配度最高的结果返回给用户,用户就可以把匹配出来的结果所对应的哈希值,作为文件的唯一标识来请求这个文件。】【查询发出去之后,组长或一些目录服务器匹配的是关键字和描述的匹配,匹配完了之后把匹配的结果给用户,用户去点这个结果,实际上就是发出了哈希值、这个文件的请求。】
-
组长用匹配进行响应:
-
对每个匹配:元数组、散列标识码和IP地址
-
-
如果组长将查询转发给其他组长,其他组长也以匹配进行响应
-
客户端选择要下载的文件
-
向拥有文件的对等方发送一个带散列标识码的HTTP请求
-
KaZaA小技巧
-
请求排队
-
限制并行上载的数量
-
确保每个被传输的文件从上载节点接收一定量的带宽
-
-
激励优先权
-
鼓励用户上载文件
-
加强系统的扩展性
-
-
并行下载
-
从多个对等方下载同一个文件的不同部分
-
HTTP的字节范围首部
-
更快地检索一个文件
-
-
P2P文件分发:BitTorrent
【洪流:一些peer节点的列表,和他们服务和被服务之间的关系】
【bitmap:节点是否拥有块的具体信息,目录信息定期交换bitmap,让所有节点都能实时的知道每个节点所拥有的这些块的情况】
-
文件被分为一个个块256KB
-
网络中的这些peers发送接收文件块,相互服务
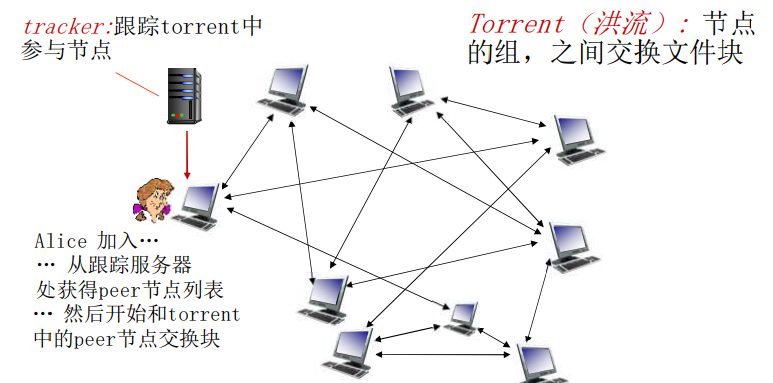
P2P文件分发:BitTorrent
-
peer加入torrent:
-
一开始没有块,但是将会通过其他节点处累计文件块【选择下载文件的方式是随机的,随机的去请求其他的节点,它拥有4块之后,它就请求在这个洪流当中比较稀缺的块,
稀缺优先
,对于整个洪流来说,这些稀缺块就得以补齐,得以增加,变得不稀缺了,具有稀缺块的节点下线之后,这个稀缺块在其他节点还有】
-
【请求的时候请求稀缺的。作为提供方而言,向那些对我服务好的节点先服务。】
【Alice拿到稀缺块的节点,被别人请求的概率就增加了,这样Alice向别的节点提供的字节数量越多,别人按照tit-for-tat策略(一报还一报),Alice得到别人的带宽就越大。这样就巧妙地把集体利益和个人利益结合在一起。】
【一开始稀缺的块少,得到的时间长,这个时候也就不能得到别人很好的服务,所以最开始就随机的拿了4块再说,然后再请求最稀缺的内容,他被别人请求的概率就越大,他向别人提供好的服务,别人向他提供好的服务的概率就越大。因此他整个下载的时间就更短,性能就会来的更高】
-
-
向跟踪服务器注册,获得peer节点列表,和部分peer节点构成邻居关系(“连接”)
-
【怎么样知道其他节点拥有这些块的情况呢,通过bitmap的交换】
-
当peer下载时,该peer可以同时向其他节点提供上载服务
-
peer可能会变换用于交换块的peer节点
-
扰动churn:
peer节点可能会上线或者下线【整个洪流保持动态性,汇集到整个P2P系统的洪流的数量仍然不少,有很多节点上载,有很多节点下载,仍然构成供销两旺的动态平衡系统】
-
一旦一个peer拥有整个文件(peer拥有整个文件他就是种子,否则的话他就是吸血鬼),它会(自私的)离开或者保留(利他主义)在torrent中
BitTorrent:请求,发送文件块
【请求的角度看:一个节点什么都没有,先随即弄4块,之后在稀缺优先的请求哪些块;从被请求的角度来看,3个周期中的2个是上个周期为他服务比较好的4个节点排在前面,1个周期是优化疏通4个,随机的选,提供一个震荡的机会,让节点和节点之间并行协作的带宽来的比较大】
请求块:
-
在任何给定时间,不同peer节点拥有一个文件块的子集
-
周期性的,Alice节点向邻居询问他们拥有哪些块的信息
-
Alice向peer节点请求它希望的块,稀缺的块
发送块:一报还一报 tit-for-tat
-
Alice向4个peer发送块,这些块向Alice它自己提供最大带宽的服务
-
其他peer被Alice阻塞(将不会从Alice处获得服务)【后面的请求资源的节点,谁向我提供的带宽比较好我优先得发给谁】
-
每10秒重新评估一次:前4位【前两个周期】
-
-
每个30秒:随机选择其他peer节点,向这个节点发送块【再一个周期,第三个周期】
-
“优化疏通”这个节点【通过这个策略,希望整个网络的吞吐量比较高】
-
新选择的节点可以加入这个 top4
-
Alice“优化疏通”Bob
-
Alice变成了Bob的前4位提供者;Bob答谢Alice
-
Bob变成了Alice的前4提供者
-
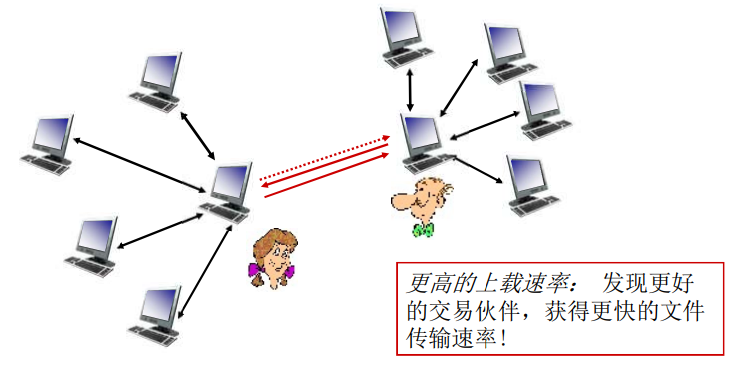
【BT网络怎么加入洪流的:带外解决。通过跟踪服务器来找到这些节点,跟踪服务器怎么找到的,是网站来维护的,在洪流的源文件的描述当中来描述的。】
【BT客户端在一些文件分发的网站去检索,返回列表,点击列表,下载torrent(洪流)文件,在torrent文件当中包括了关于这个资源、这个文件的跟踪服务器(tracking server),然后再向tracking server发出请求,tracking server就分配一些peer节点的列表给你,然后你再跟他们互通有无】
Distributed Hash Table(DHT)
【分发的内容通过哈希来唯一的标识这个内容;节点按照IP地址、哈希,每个节点有ID值。内容的ID值和节点的ID值一个空间,内容存在哪这种信息是约定的,这样就可以用很少的副本就能查到需要的内容。节点和节点之间构成一个有序的拓扑;节点和内容之间,他的空间,ID是重叠的;内容、ID在什么地方,在哪些节点ID之上是一种约定;然后通过有序的节点节点之间的环状或者树状拓扑,很快的就能找到这些节点,从而找到内容所在的位置,从而快速的做内容的分发。所以基于DHT的P2P系统,在现在的文件分发系统应用的还是比较多的。】
-
哈希表
-
DHT方案
-
环形DHT以及覆盖网络
-
peer波动