初读
光流的概念:光流是三维运动向量在成像平面的投影,是序列图像上亮度图案的表观运动。光流场不仅包含图像内物体与背景的运动信息,而且含有丰富的三维结构和表面信息。光流通常是用于跳过某些帧的计算,将前一帧或前几帧的特征迁移(Warp)到当前帧,在一定程度上也起到了特征增强的作用。因此,光流被定义为两张图像之间对应像素移动的向量。
场景解析或语义分割中影响性能最重要的两个影响:细节信息(高分辨率,计算量大)和语义信息(低分辨率,缺乏细节信息)。
其中deeplab系列和pspnet都是基于backbone+Context Modeling方式。PSPnet提出的ppm模块是对每个像素的特征都进行建模【avgpool+conv】,从而获得全局信息。

deeplab系列是提出了ASPP模块,通过不同的膨胀率来提取不同尺度的上下文信息并结合全局的上下文融合来提高表征能力。

关于多尺度的上下文信息获取的方式主要有:
1)通过不同膨胀卷积或不同的池化来获得不同的感受野
2)利用multi-level
3)注意力机制
idea:在视频语义分割中,光流来对相邻的视频帧进行运动对齐。那同一图像的任意两张特征图可以视为某一特征图中像素向另一特征图像素的移动。在主流的encoder-decoder架构中,通常采用插值算法来恢复分辨率,但这种方法简单粗暴会导致语义不对齐的问题,并且残差连接引入的不对齐问题更加复杂。–>
提出利用流对齐模块(FAM)来学习相邻尺度之间的语义流特征图,建立起特征之间映射关系,以解决误对齐的问题
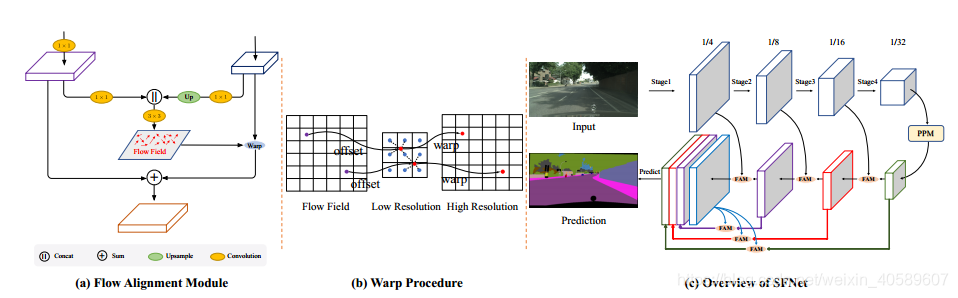
整体网络:
encoder:backbone+ PPM(与backbone的最后一个残差模块相同的分辨率大小)
decoder:FPN中自上而下的连接中引入FAM来代替双线性上采样,来对齐顶层的特征图,并且加入到相应的底层特征图上。decoder中每个stage的特征图都是上采样到输入图像的1/4,然后将这些concat【图c中表示最后统一大小不同颜色 的特征图】起来,用于做最终的预测。考虑不同层之间的对齐关系,在这里也同样采用FAM替换上采样操作。
其中FAM模块:
输入:两个相邻层的输入特征图Fl(低分辨率),Fl-1(高分辨率)
Fl和Fl-1分别通过1×1卷积压缩,然后Fl上采样后与Fl-1进行concate后通过3×3卷积生成光流场flow_field。将flow_field warp到当前的Fl中。
其中warp模块:
def flow_warp(self, input, flow, size):
out_h, out_w = size # 对应高分辨率的low-level feature的特征图尺寸
n, c, h, w = input.size()# 对应低分辨率的high-level feature的4个输入维度
norm = torch.tensor([[[[out_w, out_h]]]]).type_as(input).to(input.device)
w = torch.linspace(-1.0, 1.0, out_h).view(-1, 1).repeat(1, out_w) #从[-1,1]均匀间隔的out_h个点,返回一个1维张量
#view(-1, 1) -1表示不确定几行,1表示一列,总长度不变;repeat:维度重复
# w.shape = [out_h,out_w]
h = torch.linspace(-1.0, 1.0, out_w).repeat(out_h, 1) # 生成w的转置矩阵
grid = torch.cat((h.unsqueeze(2), w.unsqueeze(2)), 2) #升维[out_h,out_w,2]
grid = grid.repeat(n, 1, 1, 1).type_as(input).to(input.device) #[batchsize,out_h,out_w,2]
grid = grid + flow.permute(0, 2, 3, 1) / norm
#grid由input空间维度归一化的采样像素位置,其大部分值应该在[ -1, 1]的范围内
output = F.grid_sample(input, grid)
return output
F.grid_sample(input, grid, mode=‘bilinear’, padding_mode=‘zeros’, align_corners=None)
提供一个input的Tensor以及一个对应的flow-field网格(比如光流,体素流等),然后根据grid中每个位置提供的坐标信息(这里指input中pixel的坐标),将input中对应位置的像素值填充到grid指定的位置,得到最终的输出。

Summary:
1)提出学习一种语义流来对齐特征金字塔产生的多级特征图
2)舍弃膨胀卷积(计算量大),采用光流对齐来丰富底层特征的语义表示。因为低分辨率的高级特征图上的语义信息很好地流向了高分辨率的低级特征图中,在精度和速度之间达到很好的平衡