提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
思路
spark抽取mysql中的数据到hive中,可通过以下2步完成:
1.先将mysql中的数据抽取到存放再hdfs上的一个文件(.csv,.txt)
2.再讲文件通过load命令加载到hive中
下面用具体案例演示
一、案例介绍
本案例是讲mysql中的person表抽取到hive中,其中mysql中的数据如下图所示:

二、具体步骤
1.编写scala程序完成从mysql讲数据导出成csv文件
代码如下(示例):
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("csv").master("spark://master:7077").getOrCreate()
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","123456")
val dataDf = spark.read.option("header","true").jdbc("jdbc:mysql://192.168.233.131:3306/spark","person",prop)
dataDf.write.option("delimiter",",").option("header","false").csv("hdfs://master:9000/spark/person")
}
}
2.打包成jar包提交到集群上
代码如下(示例):
spark-submit --class com.test.Test /root/test.jar
打包成的jar包命名为test.jar,最终运行结束后,查看namenode的UI界面可以看到如下2个文件。
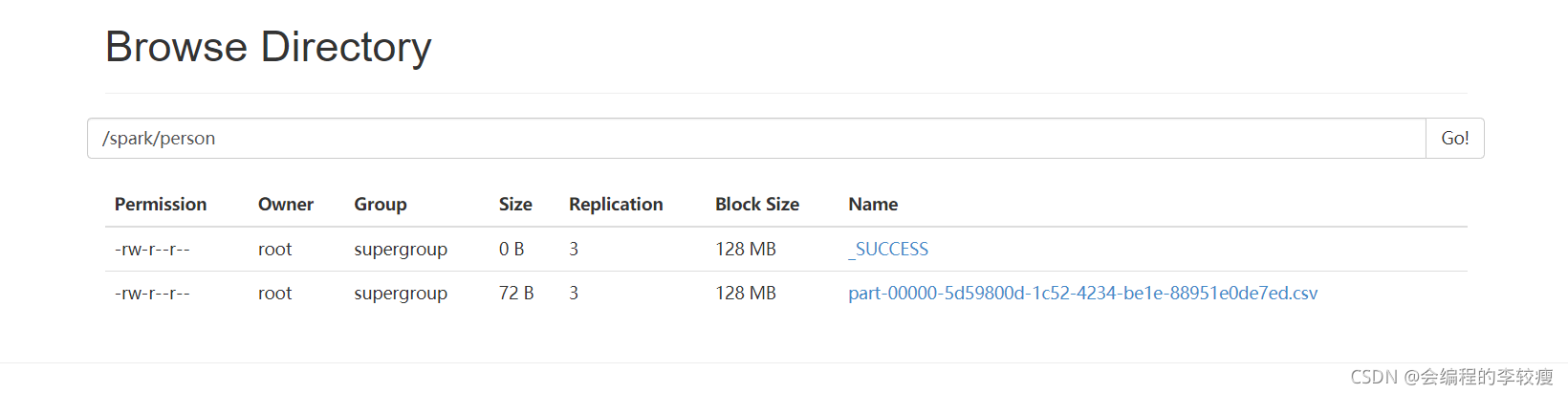
3.将hdfs上的这个文件下载到本地目录下
下载并修改文件名代码如下(示例):
hadoop fs -get /spark/person/part-00000-5d59800d-1c52-4234-be1e-88951e0de7ed.csv /root/
mv part-00000-5d59800d-1c52-4234-be1e-88951e0de7ed.csv person.csv
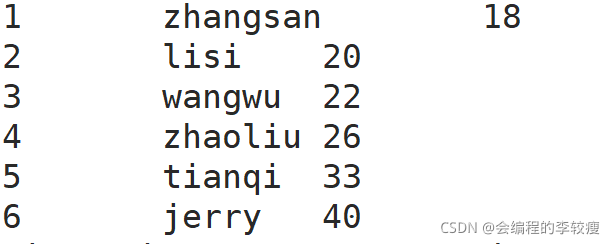
结果如下:

4.将本地数据文件的数据加载到hive中
代码如下(示例):
//新建数据库
create database sparktest;
use sparktest;
//新建表格,并指定分隔符为','
create table person2(ID int,Name string,Age int)
row format delimited fields terminated by ',';
//加载数据
load data local inpath '/root/person.csv' into table person;
//查看表中数据
select * from person;
结果如下(示例):
在这里插入图片描述
在hive中查看表中数据时,希望显示表头时,需要再启动hive后,做如下设置:
set hive.ctl.print.header=true;
总结
这个案例演示了如何从mysql将数据加载到hive的内部表中,用到了sparksql相关的编程知识。
版权声明:本文为Allwordhuier原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。