-不管三七二十一,先上代码
-读取需要掌握的函数
# 相关函数
# cv.VideoCapture() 初始化摄像头,0开启第一个摄像头,1开启第2个摄像头,返回摄像头对象,一般会自动打开摄像头
# cap.read() 读取摄像头帧,返回值1表示是否成功读取帧,返回值2表示该帧
# cv.cvtColor(frame,mode) 转换图片的色彩空间
# cap.release() 关闭摄像头
# cap.isOpened() 检查摄像头是否打开
# cap.open() 打开摄像头
# cap.get(propld) 获得该帧的大小
# cap.set(propld,value) 设置该帧的大小
-
基于混合高斯的原理图
我们可以认为时域中的同一个点的像素值看做是一个像素的变化过程,由一组像素组成,如果这里只考虑灰度图的话,对于点
x0
x_0
x
0
,
y0
y_0
y
0
处于时间
tt
t
的像素历史值为
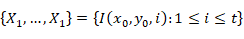
其中
II
I
代表着图像序列,在生活中,我们会遇到很多干扰因素,例如光照亮度,风吹动树叶,行走中的汽车。环境中的背景对于我们来说往往不是完全不变的。由于这种变化的产生,我们经常会发现,随着时间的推移,在图像中,也就是即随着帧数的增加,像素点的值的分布较为分散,尤其是前景与背景交叉的区域。由于像素点的变化是多个的,适应单个像素变化的高斯模型,针对二维图片来说,那将是一个多维的变化,一般高斯模型变化无法适应。那么我们将针对每一个模型进行高斯的建模,这样多个像素得到的概率密度函数为:
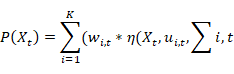
KK
K
是该点对应的高斯模型的最大数目,
wi
w_i
w
i
是时间
tt
t
时的第
ii
i
个高斯模型的权重,即当前高斯模型对于该像素点对应的所有模型占得权重,
ui
,
t
u_{i,t}
u
i
,
t
是时间t时的第i个高斯模型的期望,
∑i
,
t
\sum{i,t}
∑
i
,
t
是时间 t时的第 i个高斯模型的协方差矩阵,
η\eta
η
代表高斯概率密度方程:
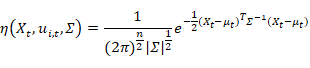
-
一般考虑到考虑到程序的空间与时间复杂度,
KK
K
的取值一般为3-5.而且协方差矩阵被简化为
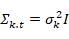
判断一个像素点是否服从高斯分布条件:像素值是否位于高斯分布的2.5倍标准差内。对于每个像素点对应的高斯模型,如果该像素值匹配到了某个高斯模型,则更新公式如下:
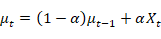
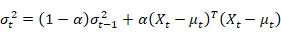
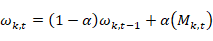
对于没有匹配到的高斯模型,其方差与期望不变,权重的更新按照上述公式。其中当像素点匹配了某个高斯模型的时候
a(
M
k
,
t
)
a(M{k,t})
a
(
M
k
,
t
)
设置值为1,否则值为0。
每个像素值对应的各个高斯分布的参数会一直发生改变,当一个物体趋于静止的时候,对应的像素高斯分布的方差会趋于更小,其对应的权重会趋于变得更大,相对于一个运动的物体,他一般不会匹配到像素对应的高斯模型,运动的物体会让高斯模型的方差变得更大,权重变得更低。
我们按照高斯模型的权重与方差的比值进行降序排列,由阈值T(程序中取值为0.7)选出B个高斯分布作为当前像素判断是否属于背景的模型:
如果一个新的像素值服从该B 个高斯模型中的某一个,我们就认为该像素属于背景。但是如果该像素服从某个高斯分布,但是该高斯分布位于该B 个高斯模型之后,该像素仍然会被判定为前景。T的取值不宜过大,否则会产生一个多峰分布模型,背景模型如果是单峰值的话,会选出一个可能性最高的高斯分布。
效果图
-提取效果图

上代码
import cv2 as cv
import numpy as np
video = cv.VideoCapture(0,cv.CAP_DSHOW)
# 设置编码格式
# MP4
fourcc = cv.VideoWriter_fourcc(*"mp4v")
# avi
fourcc_2 = cv.VideoWriter_fourcc(*'XVID')
out_video = cv.VideoWriter('output.mp4',fourcc, 20.0, (640,480))
out_video_2 = cv.VideoWriter('ori.avi',fourcc, 20.0, (640,480))
# 背景减法器 基于自适应混合高斯背景建模的背景减除法
# history:用于训练背景的帧数,默认为500帧,如果不手动设置learningRate,history就被用于计算当前的learningRate,此时history越大,learningRate越小,背景更新越慢;
# varThreshold:方差阈值,用于判断当前像素是前景还是背景。一般默认16,如果光照变化明显,如阳光下的水面,建议设为25,36,具体去试一下也不是很麻烦,值越大,灵敏度越低;
# detectShadows:是否检测影子,设为true为检测,false为不检测,检测影子会增加程序时间复杂度,如无特殊要求,建议设为false
backsub = cv.createBackgroundSubtractorMOG2(history=500,varThreshold=16,detectShadows=False)
while True:
# ret 读取状态,frame image data
ret,frame = video.read()
# 获取掩码
if ret:
mask = backsub.apply(frame)
# print(frame.shape)
# print(mask.shape)
# 扩充维度
mask = np.expand_dims(mask,axis=2).repeat(3,axis=2)
out_video.write(mask)
out_video_2.write(frame)
cv.imshow("frame",mask)
if cv.waitKey(30) & 0xFF ==ord('q'):
break
# 释放资源
video.release()
out_video.release()
out_video_2.release()
cv.destroyAllWindows()
```