flink sql 调试-注意点
-
1、布尔类型的坑
-
2、cdc 表[kafka/pg等],要写对表主键,特别是flink sql 有group by 的情况
-
3、Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/flink/table/api/bridge/java/StreamTableEnvironment
-
4、flink sql cdc kafka 数据连接超时优化
-
5、flink sql cdc 写入到pg 与 flink sql 转换后的pg sql 数据量不一致问题
-
6、flink sql DAG 图实时任务很多
-
7、物理内存溢出
-
8、两张 pg 表合并后写入 kafka , 数据丢失解决
-
9、pg拆表采集到kafka后, 去除delete操作,union all 再sink 到 upsert-kafka , 再 kafka 出来join/left join 后出现数据丢失
-
10、flink sql 读取 kafka source 数据没有变化
-
11、flink sql 没有消费完kafka数据,flink 任务正常, 但消费进度条已经显示不消费了
-
12、Caused by: org.apache.flink.table.api.ValidationException: Cannot discover a connector using option: ‘connector’=’jdbc
1、布尔类型的坑
数据库 deleted = 'false' , flink sql 要替换为 deleted is false
2、cdc 表[kafka/pg等],要写对表主键,特别是flink sql 有group by 的情况
现象:a 表主键是三个字段的联合主键[PRIMARY KEY (id,parent_id,entity_farm_id) NOT ENFORCED],cdc 写 [PRIMARY KEY (id)] ,多表join 或查询单个表的 sql 里面有group by 主键的操作,数据会存在丢失
原因:flink sql cdc 读取数据后,会优先进行group by 后,再进行select 或多表join 操作,导致后面的数据会覆盖前面的数据
解决:写对联合主键
3、Exception in thread “main” java.lang.NoClassDefFoundError: org/apache/flink/table/api/bridge/java/StreamTableEnvironment
原因:
1、jar 找不到
2、此属性为编译期会打包进去, 运行期不一定打包进去,故再运行时报找不到类
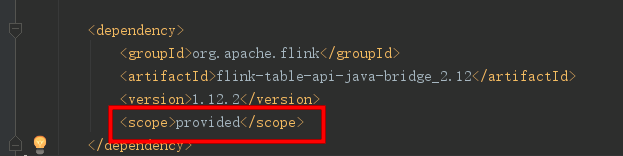
解决:
1、 注释此行即可
排查路径:
复制运行的jar 包加载路径, 查找是否有对应的 jar 包

4、flink sql cdc kafka 数据连接超时优化
报错:org.apache.kafka.common.errors.DisconnectException
解决:在配置里面添加:‘properties.request.timeout.ms’ = ‘90000’
详情看:https://stackoverflow.com/questions/66042747/error-sending-fetch-request-sessionid-invalid-epoch-initial-to-node-1001-org
5、flink sql cdc 写入到pg 与 flink sql 转换后的pg sql 数据量不一致问题
现象:flink sql 转换为 pg sql 后查询的数据量比flink sql cdc kafka 多
原因:flink sql cdc kafka 的 source 表的主键没有包含完整
解决:完善表主键字段
6、flink sql DAG 图实时任务很多
现象:
1、出现很多count(1) finish 的任务
2、出现很多非 Join 的条件任务[case when 等算法任务]
3、代码里存在 view 视图
原因:
1、case when a = b then d else c end as aa ; DAG会生成一个 新的 job 任务
2、view 视图会增加数据中间状态存储
解决:
1、减少 右边 case when 操作;可以使用左表的 case when 操作
2、使用 udf 、udtf 函数[不会产生新的 job , 待尝试]
7、物理内存溢出
报表信息:
Container [pid=12539,containerID=container_e166_1650382930878_534192_01_000014] is running 32768B beyond the ‘PHYSICAL’ memory limit. Current usage: 2.0 GB of 2 GB physical memory used; 4.1 GB of 4.2 GB virtual memory used. Killing container.
原因分析:
参考:https://developer.aliyun.com/article/780954
解决:
- 在配置文件flink-conf.yaml中添加参数:containerized.taskmanager.env.MALLOC_ARENA_MAX: 1
- rockdb 优化,显示rockdb 使用内存,并0.9后刷新到磁盘
8、两张 pg 表合并后写入 kafka , 数据丢失解决
现象:
1、两张表:当前表和历史表,当前表保存历史表两年内的数,历史表保存两年后的数据
2、flink sql pg cdc 后表数据 union all 写入kafka[upsert-kafka] , delete 与 insert 先
后顺序问题,当insert 在前,delete 在后,写入kafka 的数据会被删除,数据就会丢失
解决方案:
方案1:
第一次的 flink sql pg cdc source 与 kafka sink 使用 upsert-kafka [分两个topic] ,
分别去除 delete 数据, 再使用两个 kafka source 读取数据,flink sql union all 后再
sink 到kakfa [连接模式:kakfa , 不做更新]
方案2:
9、pg拆表采集到kafka后, 去除delete操作,union all 再sink 到 upsert-kafka , 再 kafka 出来join/left join 后出现数据丢失
现象:
数据对比后,数据缺失
原因:
1、消费kafka的topic数据,发现delete操作在最后才出现;导致对应id数据被删除
排查方向:
1、使用表字段的 event_time 作为watermark
2、delete 操作的kafka 记录只是多了一个delete 标签
3、一个任务里面,多个 view , 且多个 view 之间互相调用
4、Flink sql 多表 join / left join 导致数据乱序
select *
from A
left join B on B.id = A.id
left join C on C.id = B.id
10、flink sql 读取 kafka source 数据没有变化
报错:[Consumer clientId=consumer-agg_dt_center_dwd_fpf_anc_female_farrow_event3-3, groupId=agg_dt_center_dwd_fpf_anc_female_farrow_event3] Node 1 was unable to process the fetch request with (sessionId=399926327, epoch=1702454): FETCH_SESSION_ID_NOT_FOUND.
报错原因:无法拉取kafka数据,之前重启kafka任务,没有留意任务是否有问题
解决:重启任务,暂时没有深究
11、flink sql 没有消费完kafka数据,flink 任务正常, 但消费进度条已经显示不消费了
现象分析:
1、flink 任务状态撑爆了flink 集群分配的内存空间,无法继续消费且缓存数据;可以看到 taskmanager 等内存消耗的进度条无法显示
解决:增加内存解决
12、Caused by: org.apache.flink.table.api.ValidationException: Cannot discover a connector using option: ‘connector’=’jdbc
flink 运行环境下的lib目录 jdbc jar包出现不同版本的jdbc导致冲突了,删除其中一个即可