大家好,我是咔咔
不期速成,日拱一卒
之前ElasticSearch系列文章中提到了如何处理空值,若为Null则会直接报错,因为在ElasticSearch中当字段值为null时、空数组、null值数组时,会将其视为该字段没有值,最终还是需要使用
exists
或者
null_value
来处理空值
大多数ElasticSearch的数据都来自于各类数据库,这里暂且只针对于MySQL,各个开源软件中都默认兼容各种Null值,空数组等等
若从根源上截断就可以省很多事,直到现在很多开发小伙伴还是坚韧不拔的给字段的默认值还是
Null
本期就来聊一聊为什么不建议给字段的默认值设置为
Null
本期环境为:
MySQL8.0.26

一、案例数据
创建表user
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`age` tinyint(4) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
添加数据,共计10条数据,有两条数据的name值为Null
INSERT INTO `user` (`name`, `age`) VALUES ('kaka', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('niuniu', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('yangyang', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('dandan', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('liuliu', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('yanyan', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('leilie', 26);
INSERT INTO `user` (`name`, `age`) VALUES ('yao', 26);
INSERT INTO `user` (`name`, `age`) VALUES (NULL, 26);
INSERT INTO `user` (`name`, `age`) VALUES (NULL, 26);
一、count数据丢失
在这期
MySQL统计总数就用count,别花里胡哨的《死磕MySQL系列 十》
文章中,已经对count的使用说的非常明白了。
那借着这个案例,来分析一下为什么数据会丢失,先看结果
select count(*) as num1 ,count(name) as num2 from user;

使用count字段名时出现了数据丢失,很明显是因为主键ID9、10这两条记录的name值为空造成的。
为什么会出现这种情况?
当count除了主键字段外,会有两种情况:
一种是字段为null,执行时,判断到有可能是null,但还要把值取出来再判断下,不是null的进行累加
另一种是字段为not null,执行时,逐行从记录里边读出这个字段,判断不是null,才进行累加
此时,咱们遇到的问题是name字段的值存在了null值,所以会走第一种情况,不进行统计null值
为什么建议大家都使用count(*)?
MySQL对于count做了专门的优化,跟字段不同的是并不是把所有带了
*
的值取出来,而是指定了
count(*)
肯定不是null,只需要按行累加即可
MySQL团队对count(*)做了什么优化?
MySQL系列文章至今已经更新了第十八期了,你有没有猜到原因呢?
现在你应该知道主键索引结构中叶子节点存储的是整行数据,而普通索引叶子节点存储的是主键ID
那对于普通索引来说肯定会比主键索引小,因为对于MySQL来说,不管遍历哪个索引结果都一样,所以优化器会主动去找到那颗最小的树进行遍历。
在逻辑正确的前提下,尽量减少访问数据量,是数据库系统设计通用法则之一。
最后给大家留一个问题,为什么Innodb存储引擎不跟Myisam存储一样存储一个count值呢?
如果不知道的话,可以看上文提到的count文章
二、为distinct打抱不平
在开发工作中使用
Distinct
进行去重的场景十分的少,大多数情况都是使用group by完成的
select distinct name from user;
可以看到此时的数据依然是正确的,对Null值做了去重的操作

为什么要说这个,因为咔咔在其它的平台上看到过有人这么使用
count(distinct name,mobile)
,然后说是统计出来的数据不准确。
这种用法依然是count(字段)的用法,distinct本身是会对Null进行去重,去重后依然是需要判断name的值不为null时,才会进行累计。
所以,不要把锅甩给
distinct
三、使用表达式数据丢失
在一些值为null时,使用表达式会造成数据的不一致,接下来一起看下
select * from user where name != 'kaka';
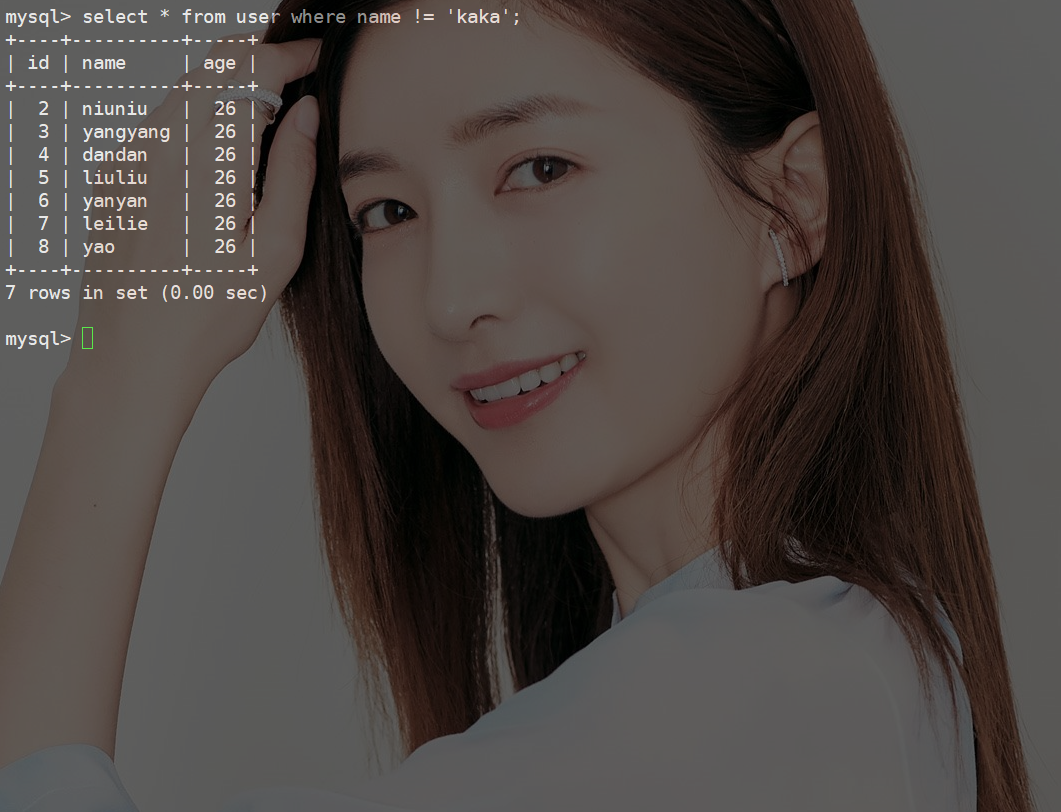
这跟我们的预期结果不大一致,预期是想返回id2~10的数据
当然,这个问题也不是无解,MySQL同样也提供了方法
要解决这个问题,只能再加一个条件就是把字段值为null的再单独处理一下

四、空指针问题
如果一个列存在null值,使用MySQL的聚合函数后返回结果是null,而并非是0,就会造成程序执行时的指针异常
CREATE TABLE user_order (
id INT PRIMARY KEY auto_increment,
num int
) ENGINE='innodb';
insert into user_order(num) values(3),(6),(6),(NULL);
创建用户订单数量表,并插入4条数据,接下来演示一下产生的问题
select sum(num) from goods where id>4;

可以看到当字段为null时,使用聚合函数返回值就是null,并非是0,那么这个问题要怎么处理呢?
同样MySQL也给大家提供了对应函数,就是ifnull
select ifnull(sum(num), 0) from goods where id>4;

五、这是在难为谁?
当一个字段的值存在null值,若要进行null值查询时,必须要使用isnull或者ifnull进行匹配查询,又或者使用is null,is not null。
而常用的表达式就不能再进行使用了,有工作经验的还好的,要是新人的话会很难受。
接下来看几个新人经常犯的错误
错误一
对存在null值的字段使用表达式进行过滤,正确用法应该是is null 或者 is not null
select * from user where name<>null;

错误二
依然是使用表达式,同样可以使用isnull

六、总结
说了这么多也都感觉到了字段设置为null的麻烦之处,不过幸好的是MySQL对使用is null、isnull()等依然可以使用上索引。
咔咔目前所在的公司存在大量字段默认值就是null,于是代码中就大量存储ifnull、is null、is not null等代码。
一般字段数值类型的默认值就给成0,字符串的给个空也行,千万不要给null了哈!
推荐阅读
闯祸了,生成环境执行了DDL操作《死磕MySQL系列 十四》
MySQL对JOIN做了那些不为人知的优化《死磕MySQL系列 十七》
坚持学习、坚持写作、坚持分享是咔咔从业以来所秉持的信念。愿文章在偌大的互联网上能给你带来一点帮助,我是咔咔,下期见。