深度学习
第一章 TensorFlow基础
目录
前言
深度学习,如深度神经网络、卷积神经网络和递归神经网络已被应用计算机视觉、语音识别、自然语言处理、音频识别与生物信息学等领域并获取了极好的效果。与机器学习相比算法更为复杂,应用领域更广泛。注:本篇文章所有函数基于TensorFlow1.0版本,不同版本差别较大。
深度学习框架:
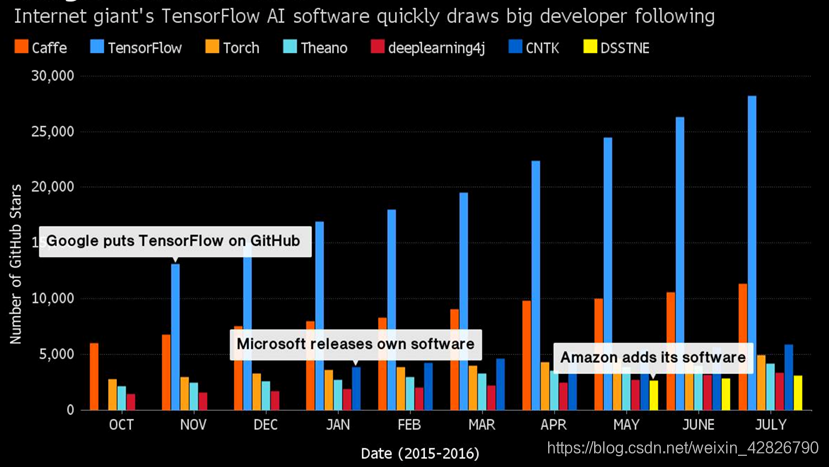
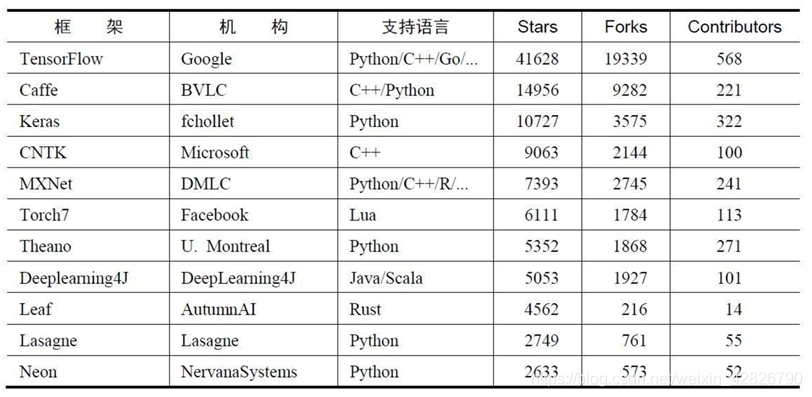
一、TensorFlow介绍
1.1认识TensorFlow
- Google Brain计划产物
- 应用于AlphaGo,Gmail,Google Maps等1000多个产品
- 与2015年11月开源,2017年2月发布1.0版本
-
架构师Jeff Dean
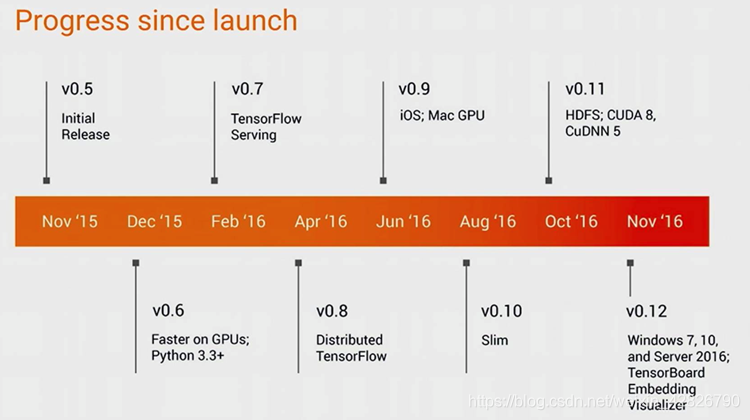
1.2TensorFlow特点
1、真正的可移植性
引入各种计算设备的支持包括CPU/GPU/TPU,以及能够很好地运行在移动端,如安卓设备、ios、树莓派等等
2、多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs,你可以直接写python/c++程序。
3、高度的灵活性与效率
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库能够灵活进行组装图,执行图。随着开发的进展,Tensorflow的效率不算在提高。
4、支持TensorFlow 由谷歌提供支持,谷歌投入了大量精力开发 TensorFlow,它希望TensorFlow 成为机器学习研究人员和开发人员的通用语言。
1.3什么是数据流图(Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
二、图和会话
2.1图
tensor:张量
operation(op):专门运算操作节点,所有操作都是一个op
图graph:整个程序的结构
会话:运算图结构
图默认已经注册,默认的这张图,相当于是给程序分配一段内存,一组表示 tf.Operation计算单位的对象和tf.Tensor
表示操作之间流动的数据单元的对象
哪些是op?
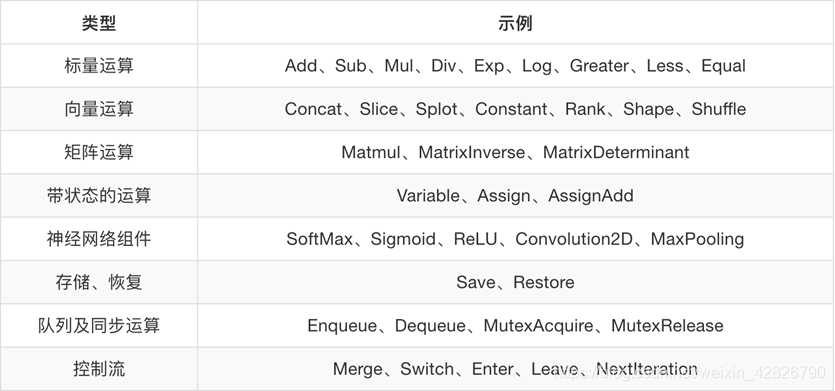
op:只要使用tensorflow的API定义的函数都是OP
图的获取调用:
- tf.get_default_graph()
- op、sess或者tensor 的graph属性
图的创建:
- tf.Graph()
- 使用新创建的图
g = tf.Graph()
with g.as_default():
a = tf.constant(1.0)
assert c.graph is g
2.2会话
-
tf.Session()
运行TensorFlow操作图的类,使用默认注册的图(可以指定运行图) -
会话资源
会话可能拥有很多资源,如 tf.Variable,tf.QueueBase和tf.ReaderBase,会话结束后需要进行资源释放
- sess = tf.Session() sess.run(…) sess.close()
-
使用上下文管理器
with tf.Session() as sess:
sess.run(…)
参数:config=tf.ConfigProto(log_device_placement=True)
交互式:tf.InteractiveSession()
2.3会话的run方法
run(fetches, feed_dict=None,graph=None)
运行ops和计算tensor
-
嵌套列表,元组,
namedtuple,dict或OrderedDict(重载的运算符也能运行) - feed_dict 允许调用者覆盖图中指定张量的值,提供给placeholder使用
-
返回值异常
RuntimeError:如果它Session处于无效状态(例如已关闭)。
TypeError:如果fetches或feed_dict键是不合适的类型。
ValueError:如果fetches或feed_dict键无效或引用 Tensor不存在。
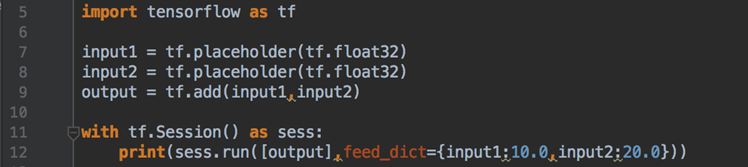
Tensorflow Feed操作:
意义:在程序执行的时候,不确定输入的是什么,提前“占个坑”
语法:placeholder提供占位符,run时候通过feed_dict指定参数
– – – >>>返回目录<<< – – –
三、张量和基本运算
3.1张量的阶、数据类型、属性
张量的阶:
在TensorFlow系统中,张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述.比如,下面的张量(使用Python中list定义的)就是2阶.
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量.

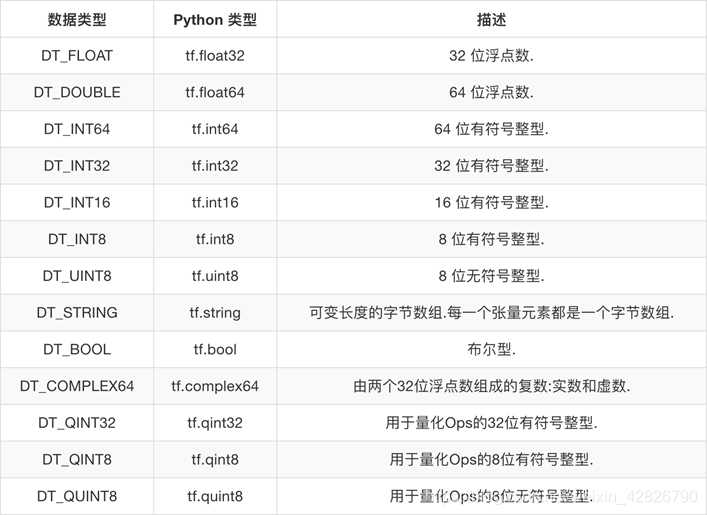
张量的数据类型:
张量属性:
- graph 张量所属的默认图
- op 张量的操作名
- name 张量的字符串描述
- shape 张量形状
张量的动态形状与静态形状:
-
静态形状:
创建一个张量或者由操作推导出一个张量时,初始状态的形状
tf.Tensor.get_shape:获取静态形状
tf.Tensor.set_shape():更新Tensor对象的静态形状,通常用于在不能直接推断的情况下 -
动态形状:
一种描述原始张量在执行过程中的一种形状
tf.reshape:创建一个具有不同动态形状的新张量
注意:
1、转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
2、 对于已经固定或者设置静态形状的张量/变量,不能再次设置静态形状
3、tf.reshape()动态创建新张量时,元素个数不能不匹配
3.2张量操作-生成张量:
固定值张量:
-
tf.zeros(shape, dtype=tf.float32, name=None)
创建所有元素设置为零的张量。此操作返回一个dtype具有形状shape和所有元素设置为零的类型的张量。 -
tf.zeros_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为零相同的类型和形状的张量。 -
tf.ones(shape, dtype=tf.float32, name=None)
创建一个所有元素设置为1的张量。此操作返回一个类型的张量,dtype形状shape和所有元素设置为1。 -
tf.ones_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为1 相同的类型和形状的张量。 -
tf.fill(dims, value, name=None)
创建一个填充了标量值的张量。此操作创建一个张量的形状dims并填充它value。 -
tf.constant(value, dtype=None, shape=None, name=‘Const’)
创建一个常数张量。
用常数张量作为例子
t1 = tf.constant([1, 2, 3, 4, 5, 6, 7])
t2 = tf.constant(-1.0, shape=[2, 3])
print(t1,t2)
在没有运行的时候,输出值为:
(<tf.Tensor 'Const:0' shape=(7,) dtype=int32>, <tf.Tensor 'Const_1:0' shape=(2, 3) dtype=float32>)
一个张量包含了以下几个信息:
- 一个名字,它用于键值对的存储,用于后续的检索:Const: 0
- 一个形状描述, 描述数据的每一维度的元素个数:(2,3)
- 数据类型,比如int32,float32
创建随机张量:
-
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32,
seed=None, name=None)
从截断的正态分布中输出随机值,和 tf.random_normal() 一样,但是所有数字都不超过两个标准差 -
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32,
seed=None, name=None)
从正态分布中输出随机值,由随机正态分布的数字组成的矩阵 -
tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32,
seed=None, name=None)
从均匀分布输出随机值。生成的值遵循该范围内的均匀分布 [minval, maxval)。下限minval包含在范围内,而maxval排除上限。 -
tf.random_shuffle(value, seed=None, name=None)
沿其第一维度随机打乱 -
tf.set_random_seed(seed)
设置图级随机种子
为什么需要正态分布的变量值?
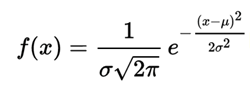
概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ
决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
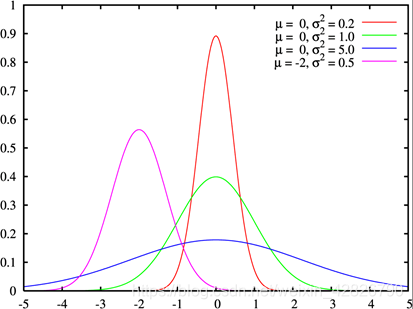

一般我们经常使用的随机数函数 Math.random() 产生的是服从均匀分布的随机数,能够模拟等概率出现的情况,例如 扔一个骰子,1到6点的概率应该相等,但现实生活中更多的随机现象是符合正态分布的,例如20岁成年人的体重分布等。
假如我们在制作一个游戏,要随机设定许许多多 NPC 的身高,如果还用Math.random(),生成从140 到 220 之间的数字,就会发现每个身高段的人数是一样多的,这是比较无趣的,这样的世界也与我们习惯不同,现实应该是特别高和特别矮的都很少,处于中间的人数最多,这就要求随机函数符合正态分布。
3.3张量操作-张量变换:
改变类型:
- tf.string_to_number(string_tensor, out_type=None, name=None)
- tf.to_double(x, name=‘ToDouble’)
- tf.to_float(x, name=‘ToFloat’)
- tf.to_bfloat16(x, name=‘ToBFloat16’)
- tf.to_int32(x, name=‘ToInt32’)
- tf.to_int64(x, name=‘ToInt64’)
- tf.cast(x, dtype, name=None)
形状和变换:可用于确定张量的形状并更改张量的形状
- tf.shape(input, name=None)
- tf.size(input, name=None)
- tf.rank(input, name=None)
- tf.reshape(tensor, shape, name=None)
- tf.squeeze(input, squeeze_dims=None, name=None)
- tf.expand_dims(input, dim, name=None)
切片与扩展:TensorFlow提供了几个操作来切片或提取张量的部分,或者将多个张量加在一起
- tf.slice(input_, begin, size, name=None)
- tf.split(split_dim, num_split, value, name=‘split’)
- tf.tile(input, multiples, name=None)
- tf.pad(input, paddings, name=None)
- tf.concat(concat_dim, values, name=‘concat’)
- tf.pack(values, name=‘pack’)
- tf.unpack(value, num=None, name=‘unpack’)
- tf.reverse_sequence(input, seq_lengths, seq_dim, name=None)
- tf.reverse(tensor, dims, name=None)
- tf.transpose(a, perm=None, name=‘transpose’)
- tf.gather(params, indices, name=None)
- tf.dynamic_partition(data, partitions, num_partitions, name=None)
- tf.dynamic_stitch(indices, data, name=None)
3.4提供给Tensor运算的数学函数
https://www.tensorflow.org/versions/r1.0/api_guides/python/math_ops
- 算术运算符
- 基本数学函数
- 矩阵运算
- 减少维度的运算(求均值)
- 序列运算
四、变量和模型保存加载
变量也是一种OP,是一种特殊的张量,能够进行存储持久化,它的值就是张量。
变量的创建:
tf.Variable(initial_value=None,name=None)
创建一个带值initial_value的新变量
-
assign(value)
为变量分配一个新值
返回新值 -
eval(session=None)
计算并返回此变量的值 - name属性表示变量名字
变量的初始化:
tf.global_variables_initializer()
添加一个初始化所有变量的op
在会话中开启
tensorflow变量作用域:
作用:让模型代码更加清晰,作用分明
tf.variable_scope(<scope_name>) 创建指定名字的变量作用域
with tf.variable_scope("itcast") as scope:
print("----")
嵌套使用变量作用域
with tf.variable_scope("itcast") as itcast:
with tf.variable_scope("python") as python:
print("----")
4.1可视化学习
可视化学习Tensorboard:
-
数据序列化-events文件
TensorBoard 通过读取 TensorFlow 的事件文件来运行 -
tf.summary.FileWriter(’/tmp/tensorflow/summary/test/’,
graph=default_graph)
返回filewriter,写入事件文件到指定目录(最好用绝对路径),以提供给tensorboard使用 -
终端开启
tensorboard –logdir=/tmp/tensorflow/summary/test/
一般浏览器打开为127.0.0.1:6006
注:修改程序后,再保存一遍会有新的事件文件,打开默认为最新
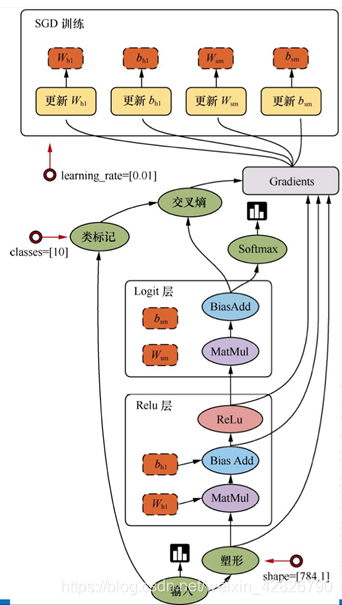
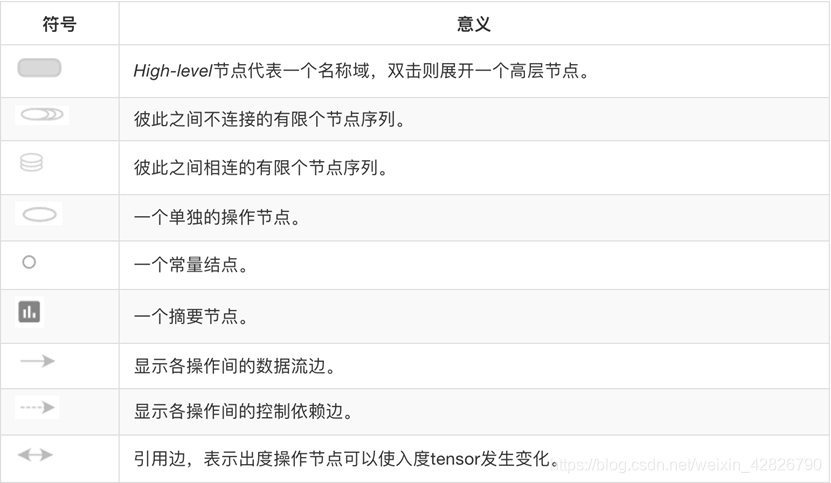
图中的符号意义:
import tensorflow as tf
# 变量op
# 1、变量op能够持久化保存,普通张量op是不行的
# 2、当定义一个变量op的时候,一定要在会话当中去运行初始化
# 3、name参数:在tensorboard使用的时候显示名字,可以让相同op名字的进行区分
a = tf.constant(3.0, name="a")
b = tf.constant(4.0, name="b")
c = tf.add(a, b, name="add")
var = tf.Variable(tf.random_normal([2, 3], mean=0.0, stddev=1.0), name="variable")
print(c, var)
# 必须做一步显示的初始化op
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
# 必须运行初始化op
sess.run(init_op)
# 把程序的图结构写入事件文件, graph:把指定的图写进事件文件当中
filewriter = tf.summary.FileWriter("./test/", graph=sess.graph)
print(sess.run([c, var]))

4.2线性回归原理及实现
Tensorflow运算API:
- 矩阵运算: tf.matmul(x, w)
- 平方: tf.square(error)
- 均值: tf.reduce_mean(error)
梯度下降API:
tf.train.GradientDescentOptimizer(learning_rate) 梯度下降优化
- learning_rate:学习率,一般为
- method:
- return:梯度下降op
import tensorflow as tf
def myregression():
"""
自实现一个线性回归预测
:return: None
"""
# 1、准备数据,x 特征值 [100, 1] y 目标值[100]
x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name="x_data")
# 矩阵相乘必须是二维的
y_true = tf.matmul(x, [[0.7]]) + 0.8
# 2、建立线性回归模型 1个特征,1个权重,多少个特征就有多少个weight, 一个偏置 y = x w + b
# 随机给一个权重和偏置的值,让他去计算损失,然后再当前状态下优化
# 用变量定义才能优化
# trainable参数:指定这个变量能跟着梯度下降一起优化
weight = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(0.0, name="b")
y_predict = tf.matmul(x, weight) + bias
# 3、建立损失函数,均方误差
loss = tf.reduce_mean(tf.square(y_true - y_predict))
# 4、梯度下降优化损失 leaning_rate: 0 ~ 1, 2, 3,5, 7, 10
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()
# 通过会话运行程序
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
# 打印随机最先初始化的权重和偏置
print("随机初始化的参数权重为:%f, 偏置为:%f" % (weight.eval(), bias.eval()))
# 循环训练 运行优化
for i in range(500):
sess.run(train_op)
print("第%d次优化的参数权重为:%f, 偏置为:%f" % (i, weight.eval(), bias.eval()))
return None
if __name__ == "__main__":
myregression()
4.3trainable,学习率调整,梯度爆炸
trainable参数:指定这个变量能跟着梯度下降一起优化
trainable一般设置为0.01
学习率和步数问题:协调好
梯度爆炸:
在极端情况下,权重的值变的非常大,以至于溢出,导致NaN值
如何解决梯度爆炸问题?
- 重新设计网络
- 调整学习率
- 使用梯度截断
- 使用激活函数
4.4增量损失值等变量显示
增加变量显示:
目的:观察模型的参数、损失值等变量值的变化
1、收集变量
-
tf.summary.scalar(name=’’,tensor)
收集对于损失函数和准确率等单值变量,name为变量的名字,tensor为值 - tf.summary.histogram(name=‘’,tensor) 收集高维度的变量参数
- tf.summary.image(name=‘’,tensor) 收集输入的图片张量能显示图片
2、合并变量写入事件文件
- merged = tf.summary.merge_all()
- 运行合并:summary = sess.run(merged) 每次迭代都需运行
- 添加:FileWriter.add_summary(summary,i) i表示第几次的值
4.5模型的保存与加载
在我们训练或者测试过程中,总会遇到需要保存训练完成的模型,然后从中恢复继续我们的测试或者其它使用。模型的保存和恢复也是通过tf.train.Saver类去实现,它主要通过将Saver类添加OPS保存和恢复变量到checkpoint。它还提供了运行这些操作的便利方法。
tf.train.Saver(var_list=None, reshape=False, sharded=False, max_to_keep=5, keep_checkpoint_every_n_hours=10000.0, name=None, restore_sequentially=False, saver_def=None, builder=None, defer_build=False, allow_empty=False, write_version=tf.SaverDef.V2, pad_step_number=False)
- var_list:指定将要保存和还原的变量。它可以作为一个dict或一个列表传递.
- max_to_keep:指示要保留的最近检查点文件的最大数量。创建新文件时,会删除较旧的文件。如果无或0,则保留所有检查点文件。默认为5(即保留最新的5个检查点文件。)
- keep_checkpoint_every_n_hours:多久生成一个新的检查点文件。默认为10,000小时
保存:
保存我们的模型需要调用Saver.save()方法。save(sess, save_path, global_step=None),checkpoint是专有格式的二进制文件,将变量名称映射到张量值。
恢复:
恢复模型的方法是restore(sess, save_path),save_path是以前保存参数的路径,我们可以使用tf.train.latest_checkpoint来获取最近的检查点文件(也恶意直接写文件目录)
例如:saver.save(sess, ‘/tmp/ckpt/test/model’)
saver.restore(sess, ‘/tmp/ckpt/test/model’)
保存文件格式:checkpoint文件
import tensorflow as tf
a = tf.Variable([[1.0,2.0]],name="a")
b = tf.Variable([[3.0],[4.0]],name="b")
c = tf.matmul(a,b)
saver=tf.train.Saver(max_to_keep=1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(c))
saver.save(sess, '/tmp/ckpt/test/matmul')
# 恢复模型
model_file = tf.train.latest_checkpoint('/tmp/ckpt/test/')
saver.restore(sess, model_file)
print(sess.run([c], feed_dict={a: [[5.0,6.0]], b: [[7.0],[8.0]]}))
4.6自定义命令行参数
tf.app.run(),默认调用main()函数,运行程序。main(argv)必须传一个参数。
tf.app.flags,它支持应用从命令行接受参数,可以用来指定集群配置等。在tf.app.flags下面有各种定义参数的类型
- DEFINE_string(flag_name, default_value, docstring)
- DEFINE_integer(flag_name, default_value, docstring)
- DEFINE_boolean(flag_name, default_value, docstring)
- DEFINE_float(flag_name, default_value, docstring)
- 第一个也就是参数的名字,路径、大小等等。第二个参数提供具体的值。第三个参数是说明文档
tf.app.flags.FLAGS,在flags有一个FLAGS标志,它在程序中可以调用到我们前面具体定义的flag_name.
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('data_dir', '/tmp/tensorflow/mnist/input_data',
"""数据集目录""")
tf.app.flags.DEFINE_integer('max_steps', 2000,
"""训练次数""")
tf.app.flags.DEFINE_string('summary_dir', '/tmp/summary/mnist/convtrain',
"""事件文件目录""")
def main(argv):
print(FLAGS.data_dir)
print(FLAGS.max_steps)
print(FLAGS.summary_dir)
print(argv)
if __name__=="__main__":
tf.app.run()