前导知识
E-R图
可以使用“
亿图图示
”绘制
E-R图三要素
1.实体 —用矩形表示
2.属性 —用椭圆表示
3.实体之间的联系 —用菱形表示
E-R图的建立方法
先确定实体和联系,再确定实体和联系的属性,最后在唯一标识符下面画上下划线。
实体之间的联系
1.一对一

2.一对多

3.多对多
学生ID和课程ID是多对多的关系,可以建立一张
关系表
。

CRUD操作
1.MyISAM引擎、
InnoDB引擎
、TokuDB引擎
2.数据插入:
(1).批量插入数据,因为一条数据的问题,全部数据都写入失败,怎么办?
INSERT
IGNORE
INTO user (name) VALUES (‘telami’); —–ignore会忽略报错
(2).如何实现不存在就插入,存在就更新。
ON DUPLICATE KEY UPDATE
需要有在INSERT语句中有存在主键或者唯一索引的列,并且对应的数据已经在表中才会执行更新操作。
3.要不要使用自查询?
mysql数据库默认关闭了缓存,所以每个子查询都是
相关子查询
,相关子查询就是要循环执行多次的子查询。
例如:
查询工资大于编号7499员工的其他员工;这个sql语句每执行一次,因为mysql关闭了缓存,
则子查询每次也都要执行
,这样效率低。
SELECT empno, name
FROM t_emp
WHERE sal > (
SELECT sal
FROM t_emp
WHERE empno = 7499
)
AND empno != 7499
因为MyBatis等持久层框架
开启了缓存
功能,其中
一级缓存就会保存子查询的结果
,所以可以放心使用子查询。
4.如何替代子查询?
使用FROM子查询,替代WHERE子查询;
FROM子查询只会执行一次
,所以不是相关子查询。
SELECT e.empno, e.ename
FROM t_emp e
JOIN (SELECT sal FROM t_emp WHERE empno = 7499) t
ON e.sal > t.sal AND e.empno != 7499
5.外连接的JOIN条件
(1).
内连接
里,查询条件写在ON子句或者WHERE子句,效果相同。
SELECT e.ename, d.dname
FROM t_emp e
JOIN t_dept d ON e.deptno = d.deptno AND d.deptno = 10;
等同于
SELECT e.ename, d.dname
FROM t_emp e
JOIN t_dept d ON e.deptno = d.deptno
WHERE d.deptno =10;
(2).
外连接
里,查询条件写在ON子句或者WHERE子句,效果不同。
-- 保留左表所有数据和右表关联
SELECT e.ename, d.deptno
FROM t_emp e
-- ON 条件如果符合则返回,否则返回null
LEFT JOIN t_dept d ON e.deptno = d.deptno
-- 不强求连接条件,会返回部门ID不等10的部门
AND d.deptno = 10;
| ename | deptno |
|---|---|
| SMITH | 20 |
| ALLEN | 30 |
| WARD | 30 |
-- 左表数据必须满足 where 条件才会返回。
SELECT e.ename, d.name
FROM t_emp e
LEFT JOIN t_dept d ON e.deptno = d.deptno
WHERE d.deptno = 10;
| ename | deptno |
|---|---|
| CLARK | 10 |
| KING | 10 |
| MILLER | 10 |
事务
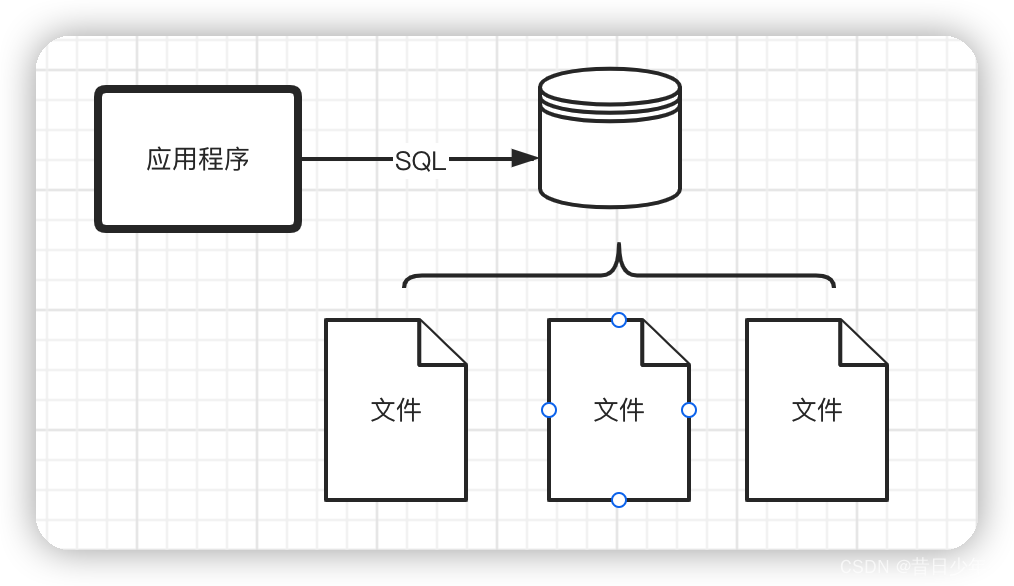
1.避免写入直接操作
数据文件
如果数据的写入直接操作数据文件是非常危险的事情
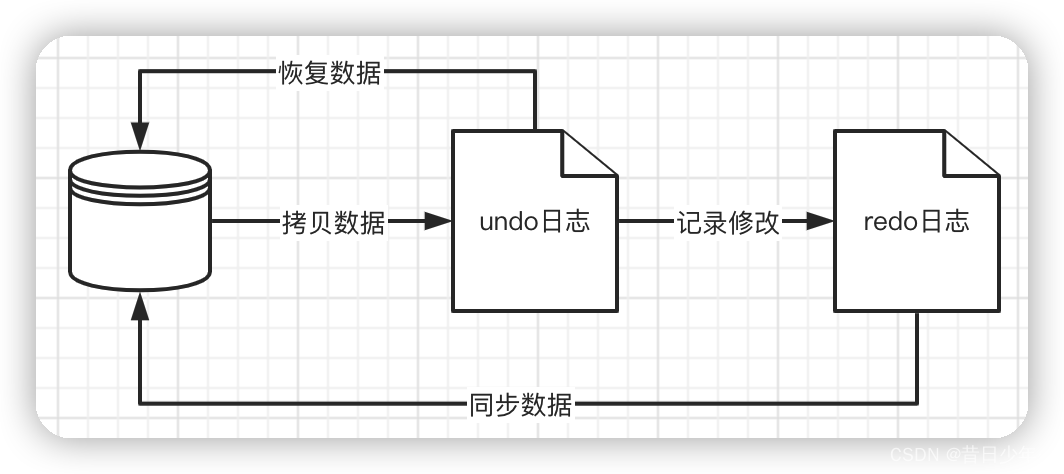
2.利用日志来实现间接写入
Mysql总共有5种日志,其中只有
redo日志
和
undo日志
与事务有关
3.事务机制(Transaction)
事务是一个或者多个SQL语句组成的整体,要么全部执行成功,要么全部执行失败。
开启事务
........
提交事务
4.事务的ACID属性
# 原子性: 一个事务中的所有操作要么全部完成,要么全部失败。事务执行后,不允许停留在中间某个状态。
# 一致性: 不管在任何给定的时间、并发事务有多少,事务必须保证运行结果的一致性。
# 隔离性:要求事务不受其它并发事务的影响,默认情况下每个事务只能看到日志中自己的相关数据。
# 持久性:事务一旦提交,结果便是永久性的。即便发生宕机,仍然可以依靠事务日志完成数据的持久化。
新零售数据结构设计
什么是SPU?
1.SPU=Standard Product Unit(标准化产品单元)
2.SPU是商品信息聚合的最小单位
3.例如:
品牌+型号:苹果5s可以确定一个产品,即SPU
SPU + 颜色 + 尺码,即SKU
SKU是从属于SPU
什么是SKU?
1.SKU(Stock Keeping Unit)是库存进出计量的单位,SKU是物理上不可分割的最小存货单元。
2.SKU与权重:新零售平台主要是B2C的,所以修改SKU对权重的影响不大。但是B2B的平台,修改SKU对权重的影响很大。
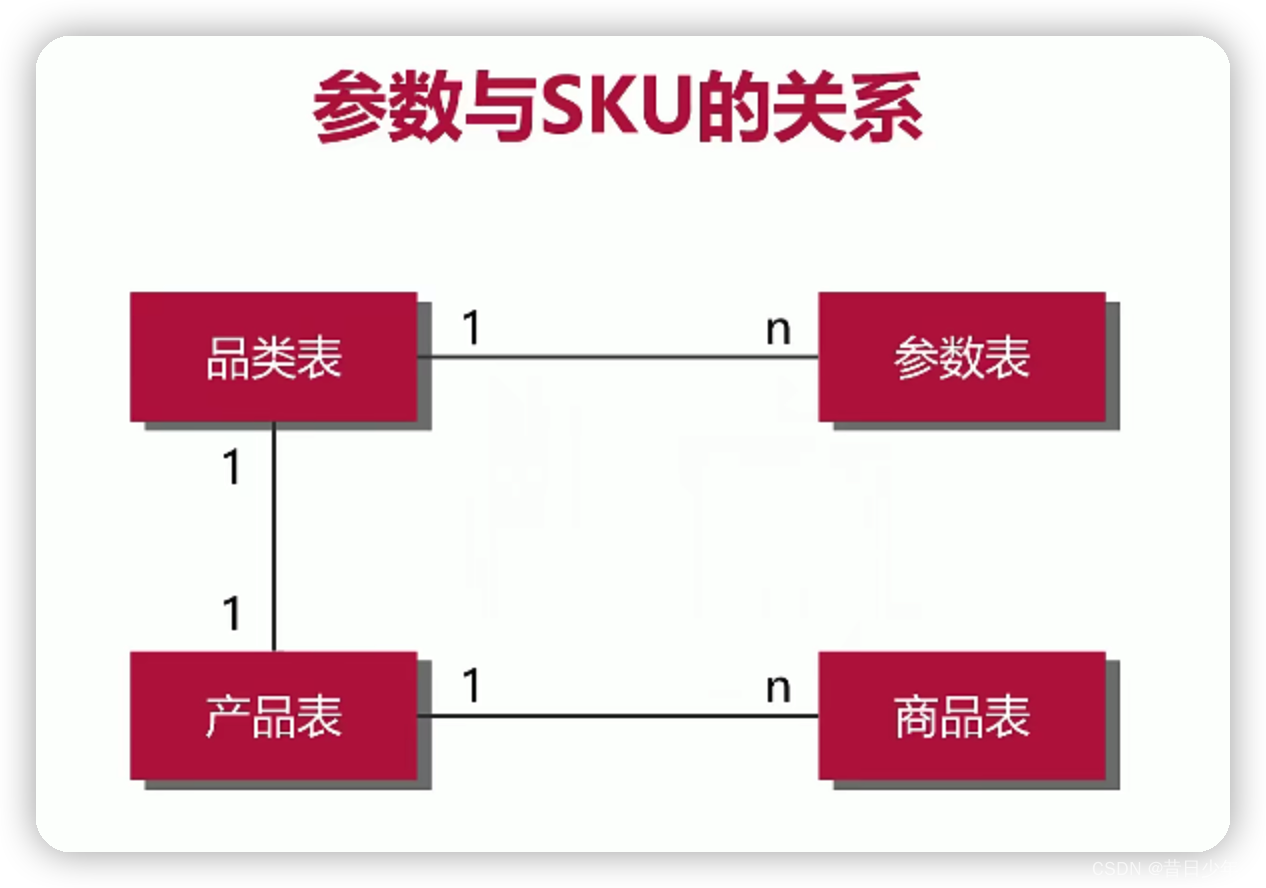
3.SKU与参数如何对应?

4.参数与SKU的关系
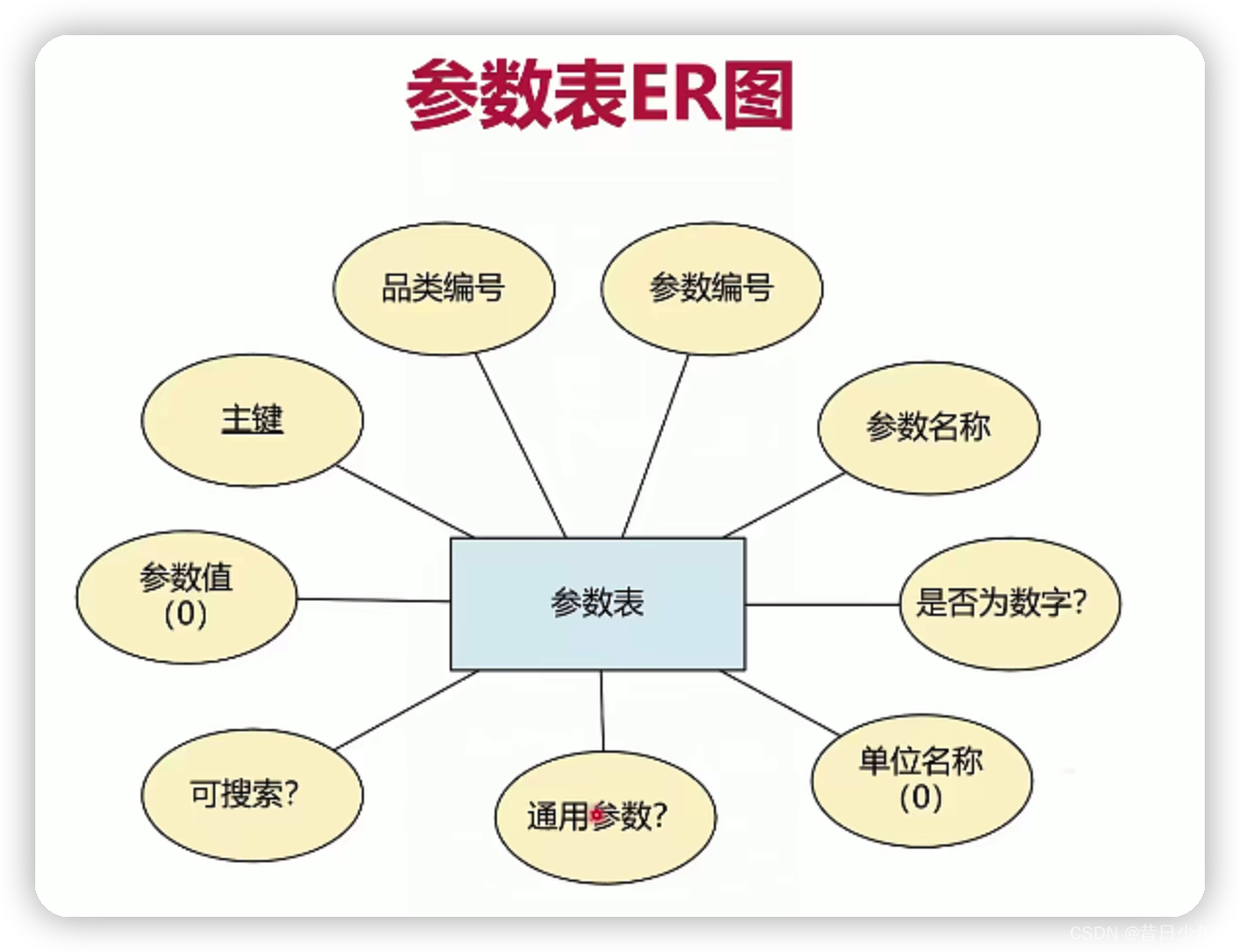
设计品类表和参数表
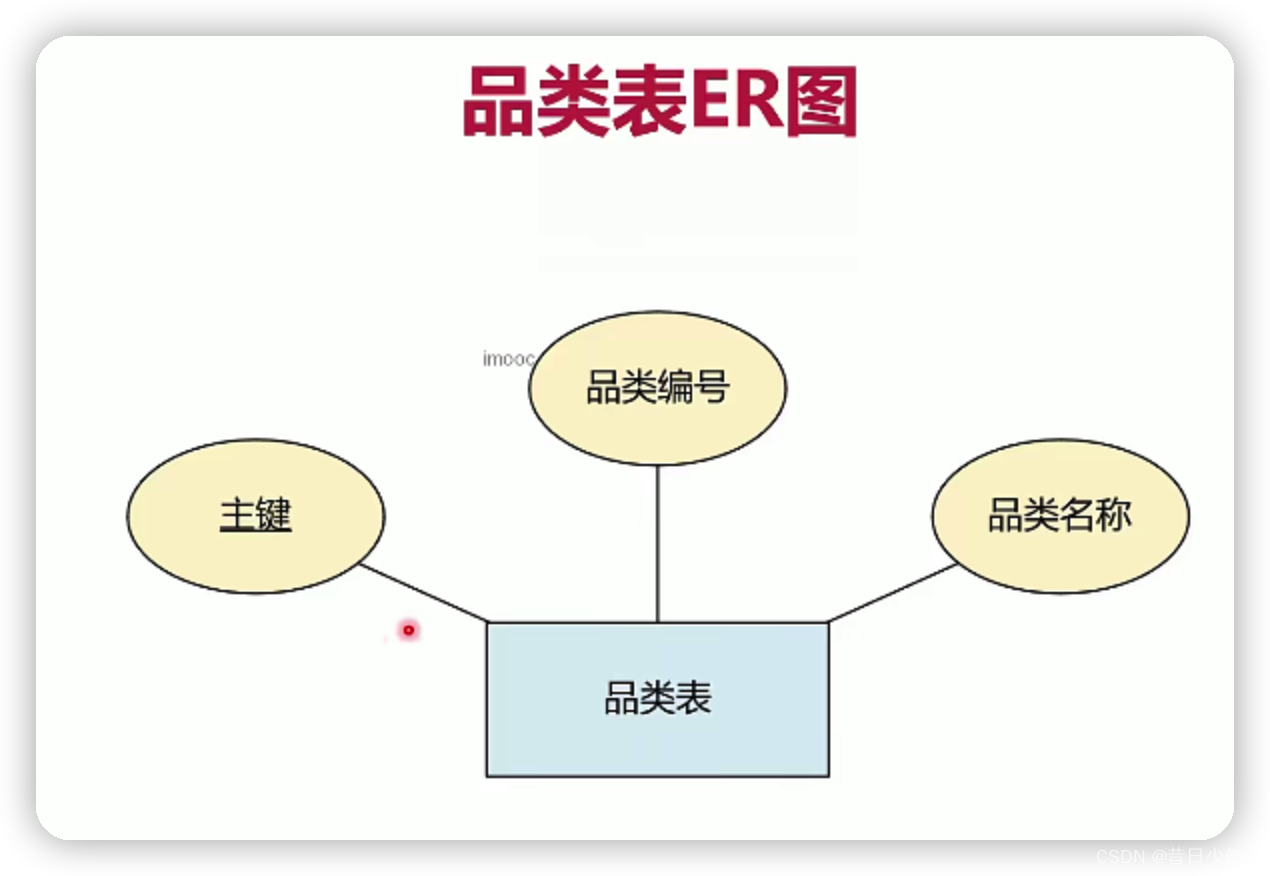
品类表
1.品类表ER图
2.品类表结构图
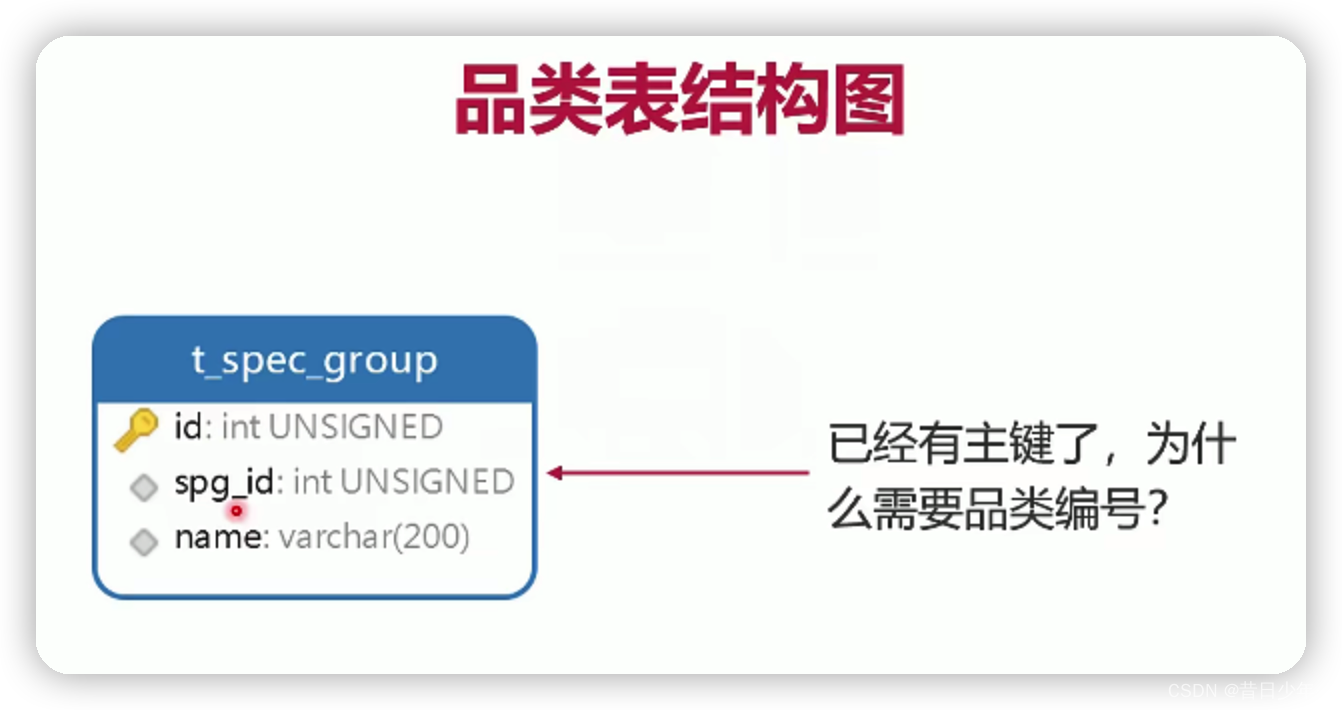
id作为主键,spg_id的编号可以作为分类,比如1000代表手机,1100代表电视机
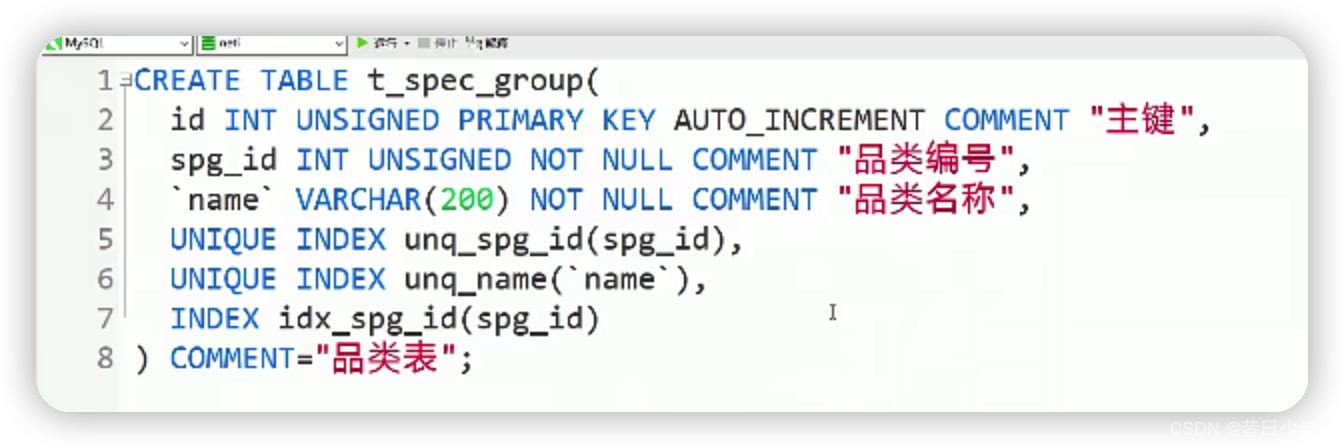
3.sql语句
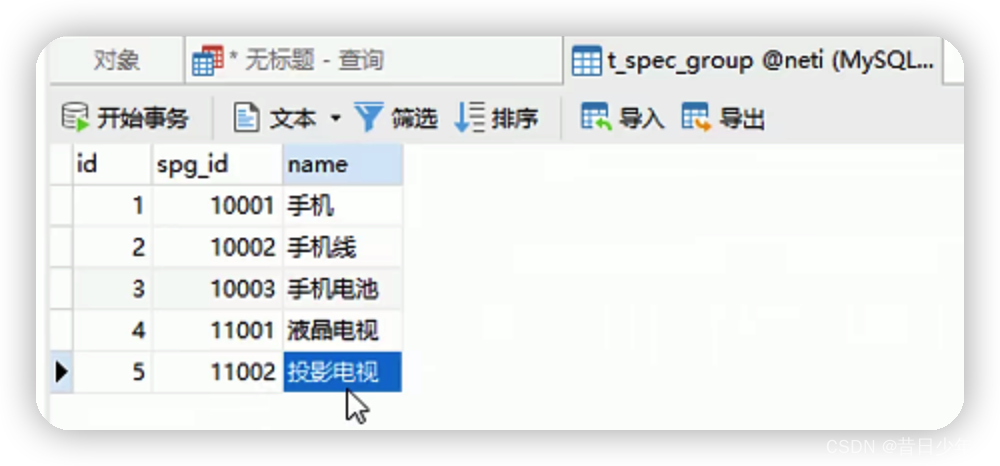
4.品类表
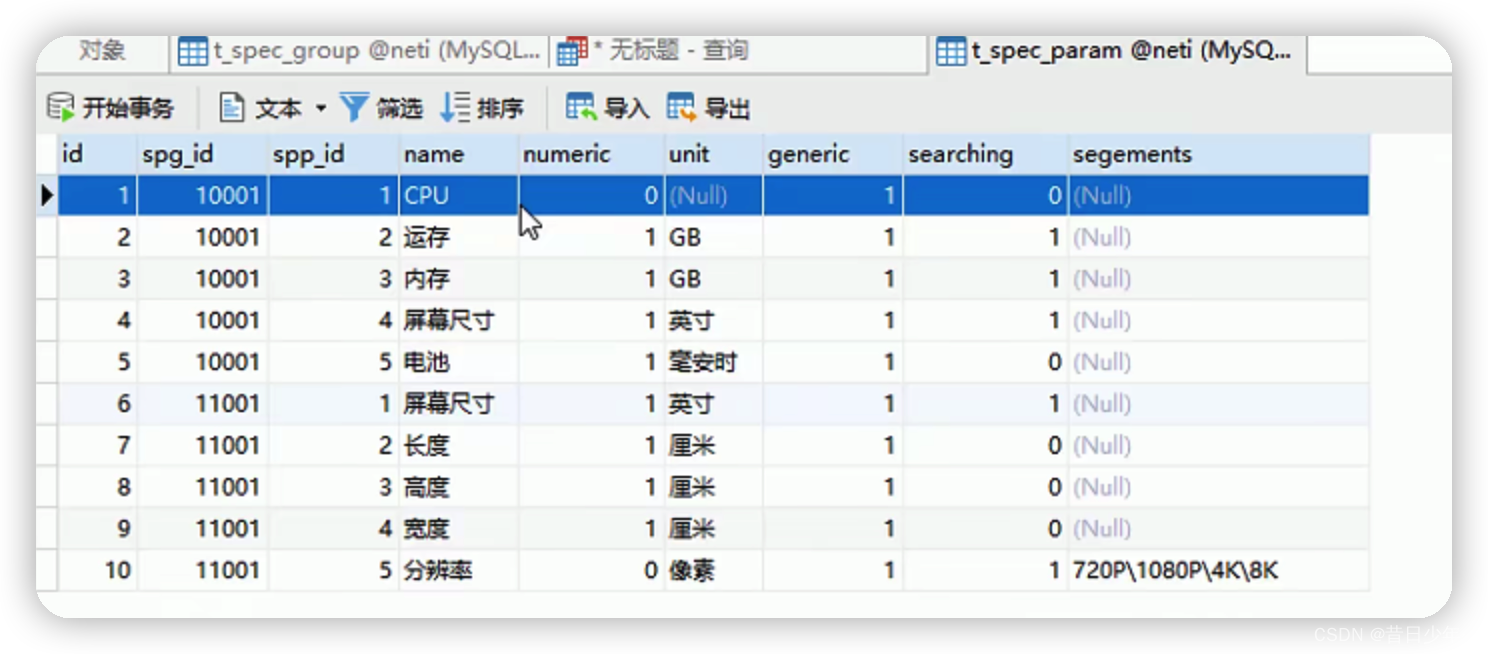
参数表
1.参数表ER图
2.参数表结构图

3.sql语句
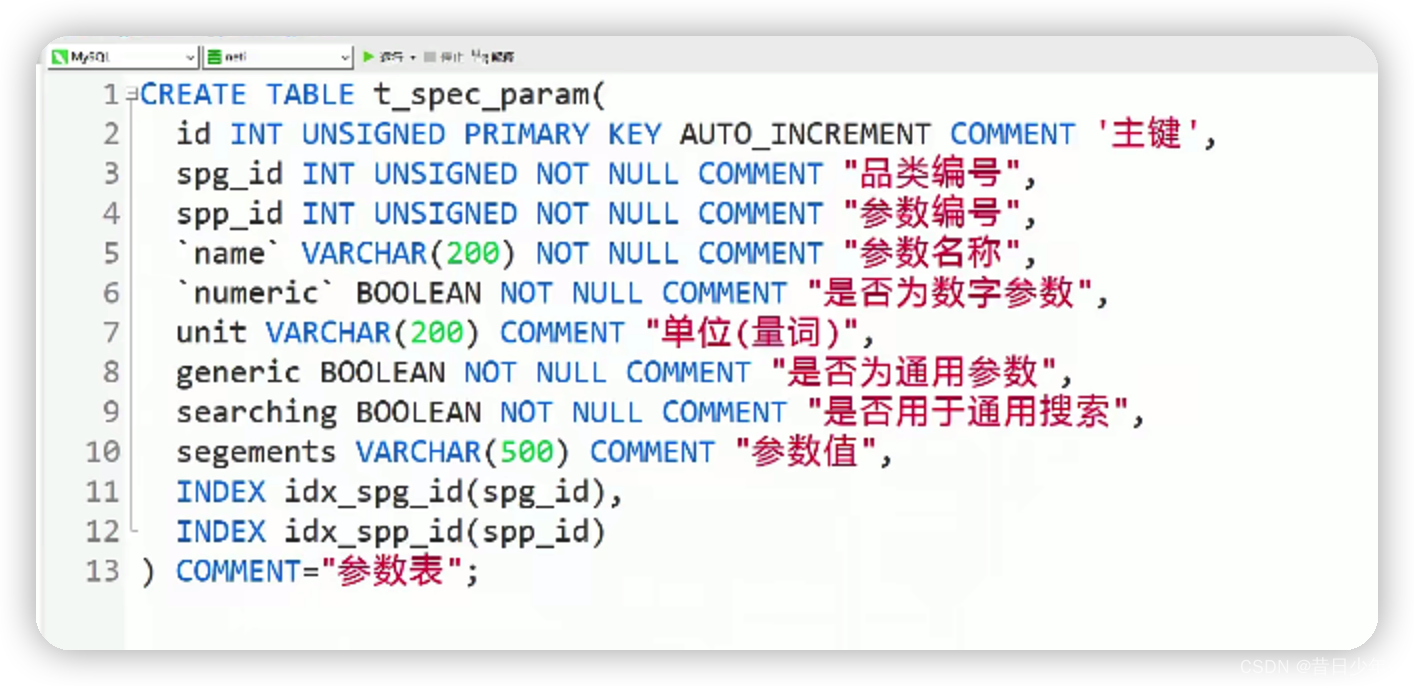
4.参数表
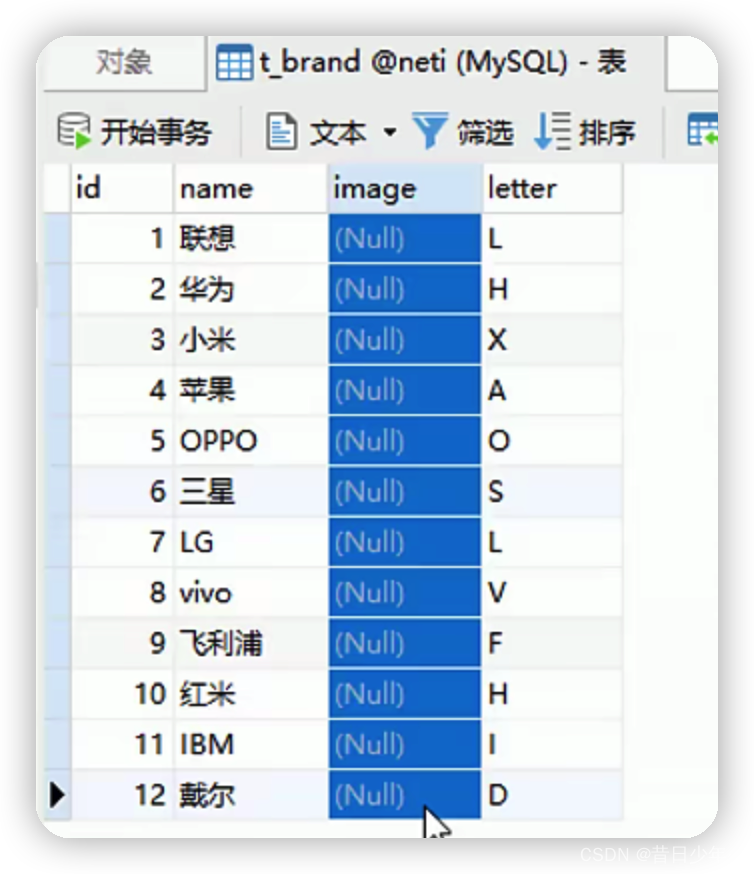
设计品牌表、分类表,以及分类与品牌关联表
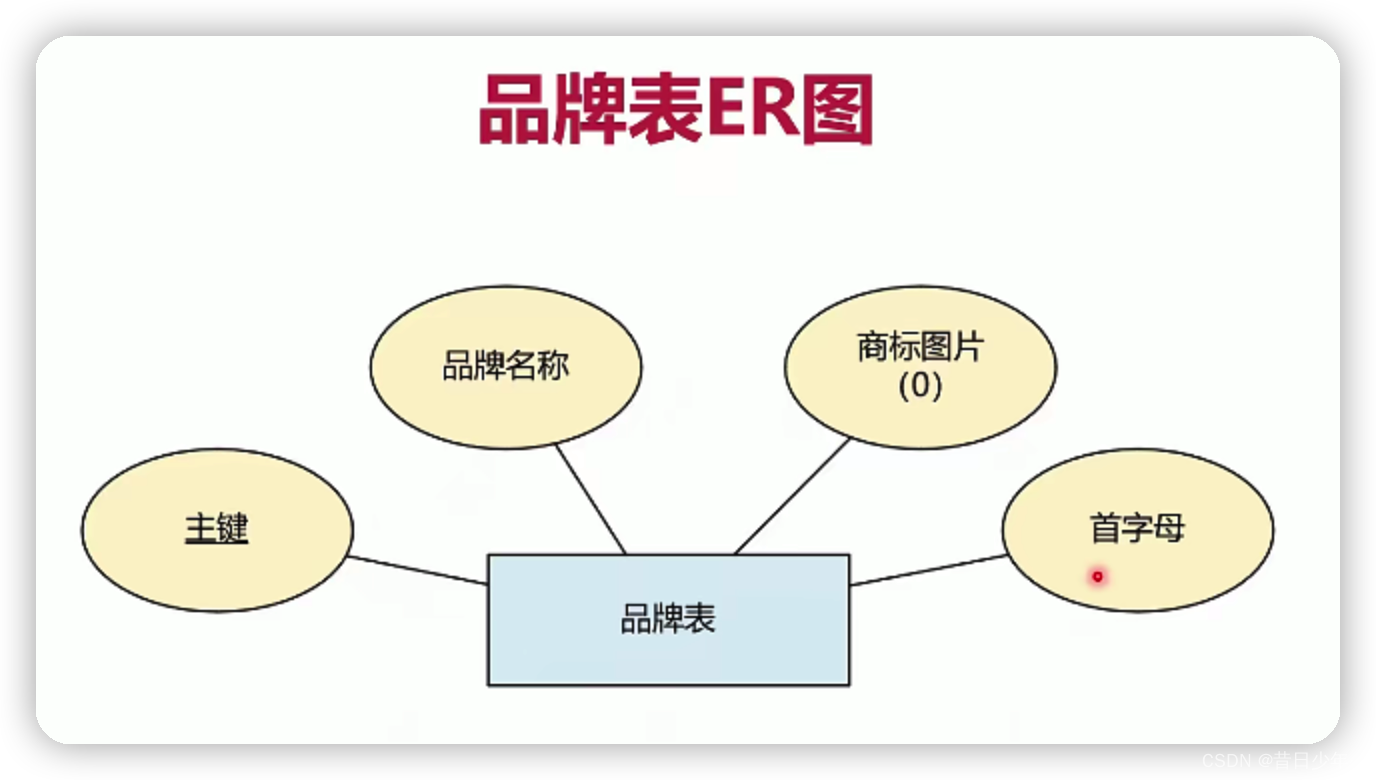
品牌表
1.品牌表ER图
2.品牌表结构图

3.sql语句
4.品牌表
分类表
1.分类界面

2.分类表ER图
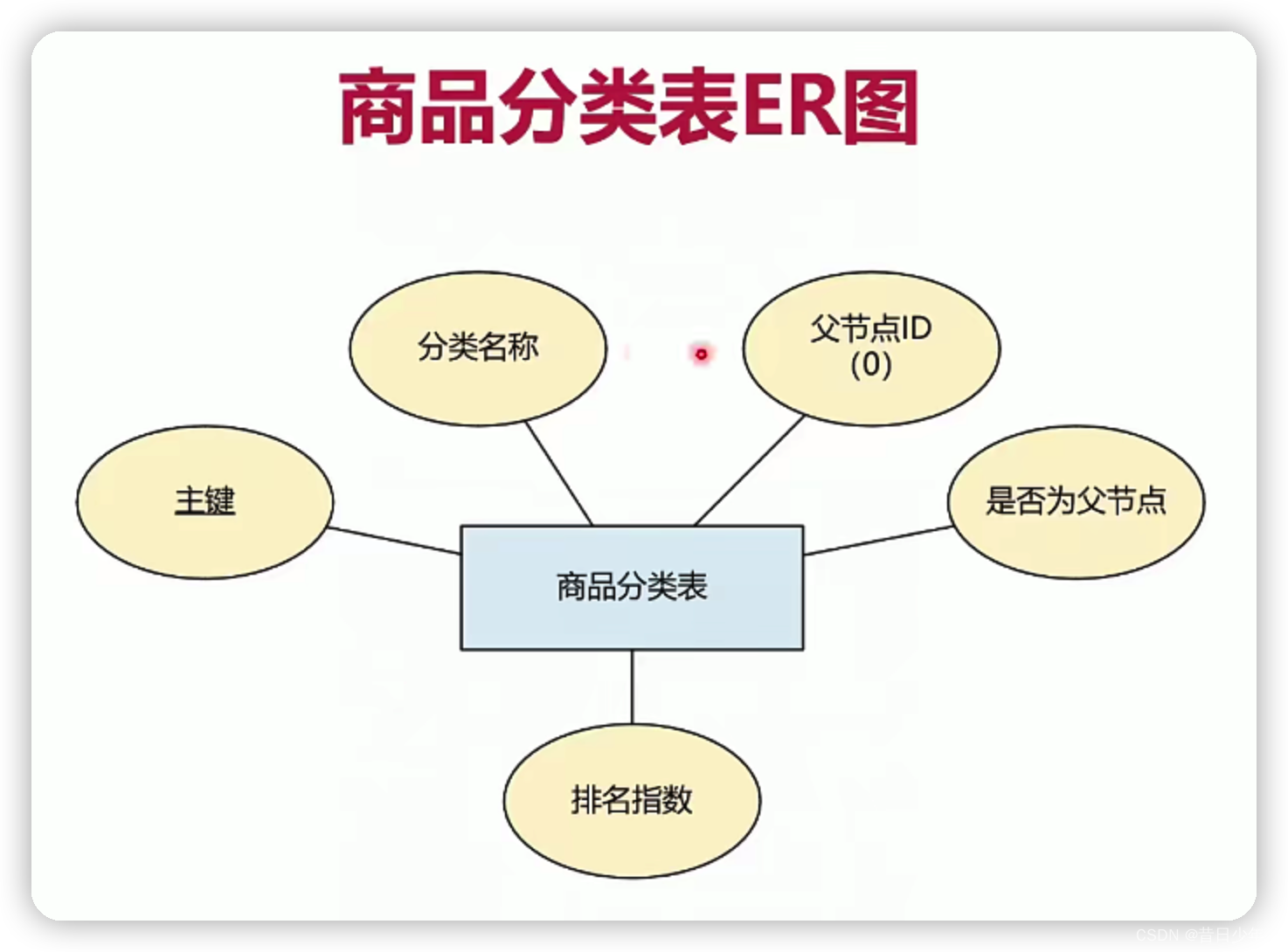
2.分类表结构图
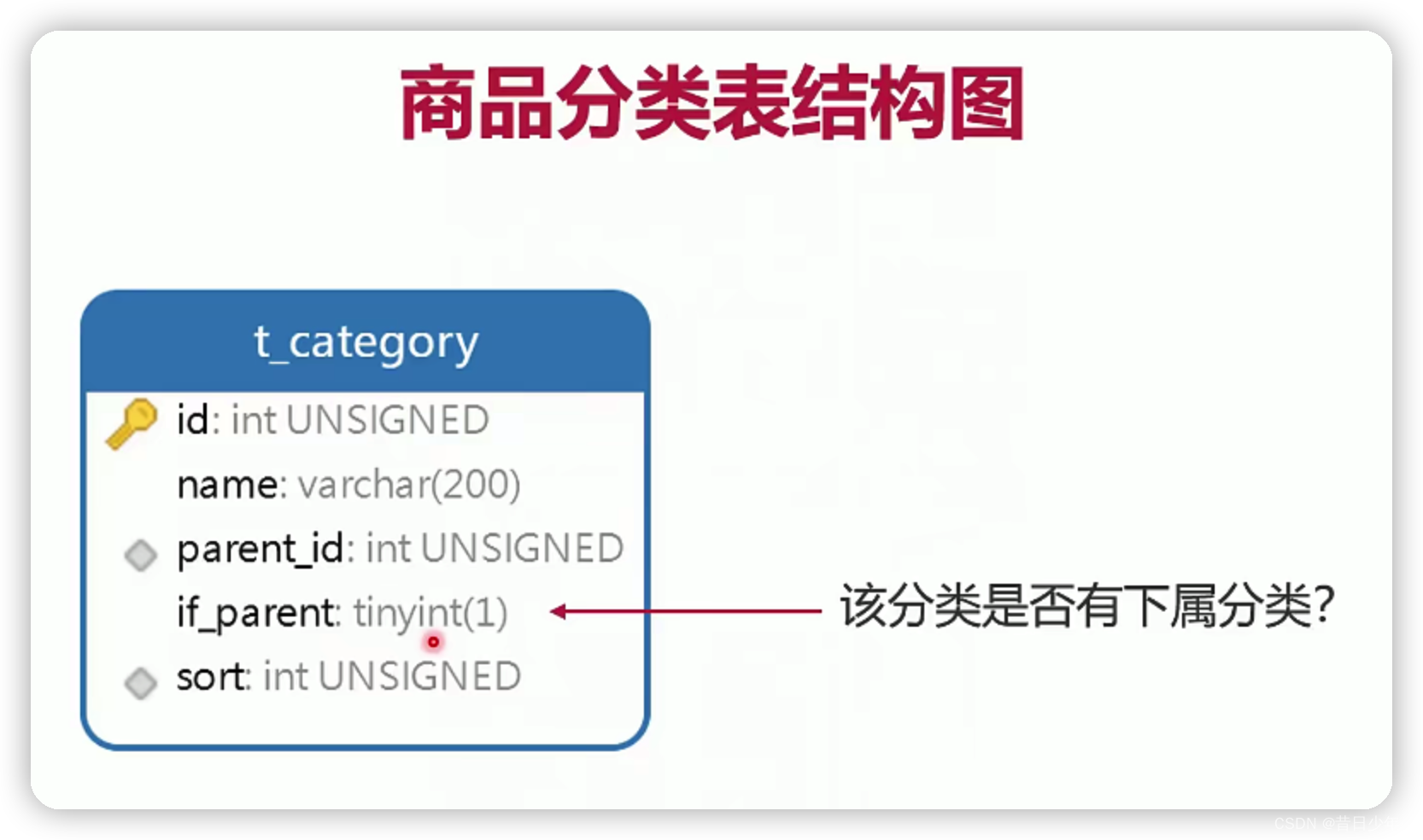
3.sql语句
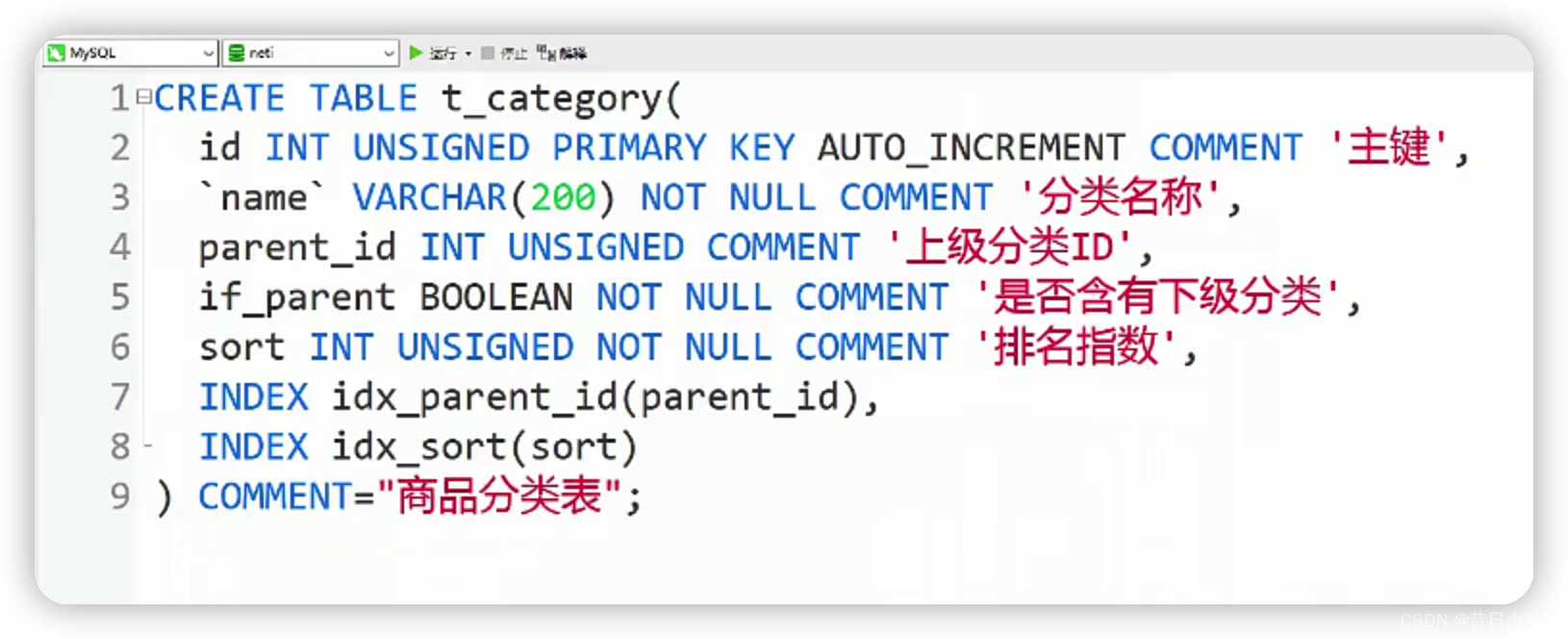
4.分类表
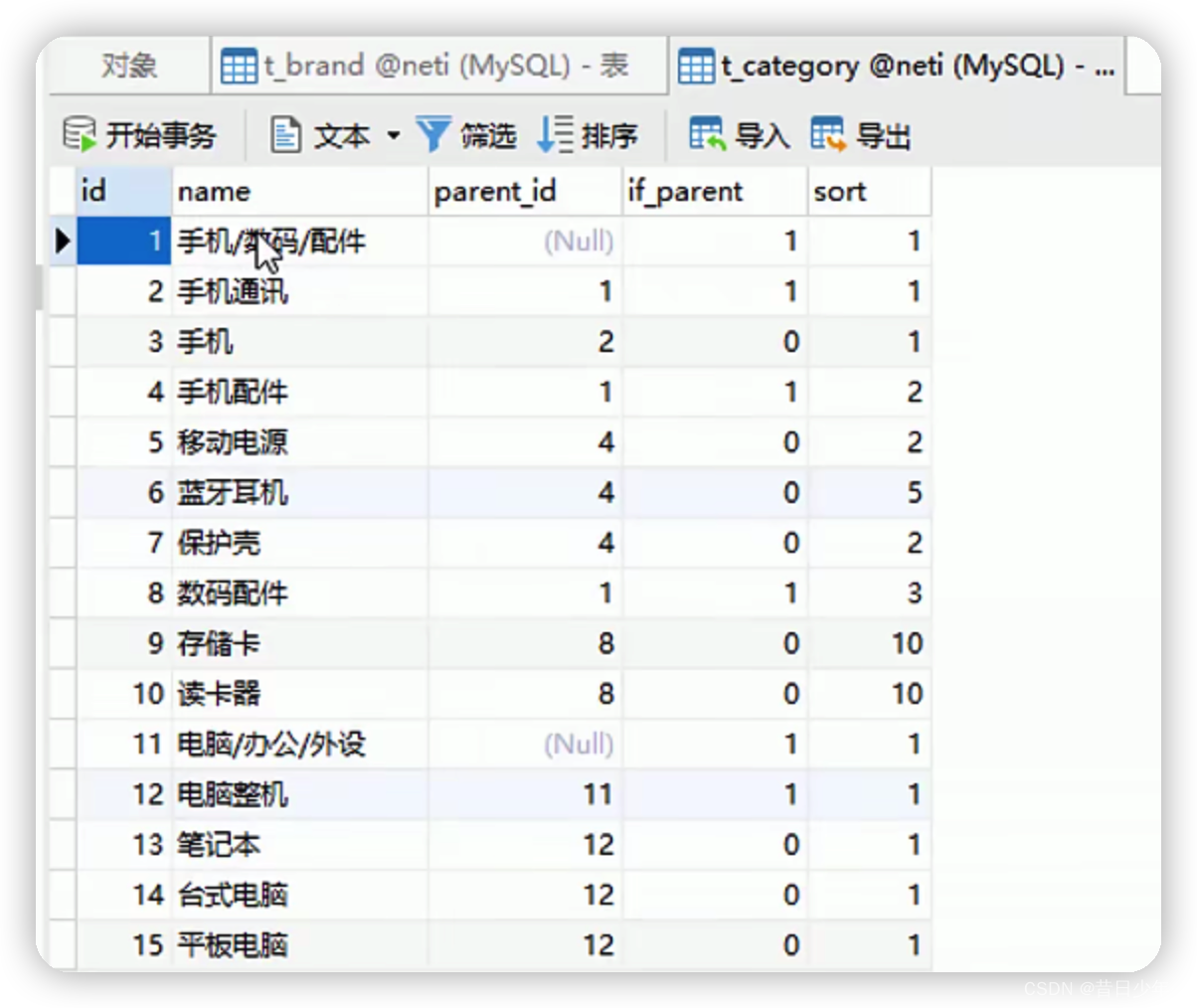
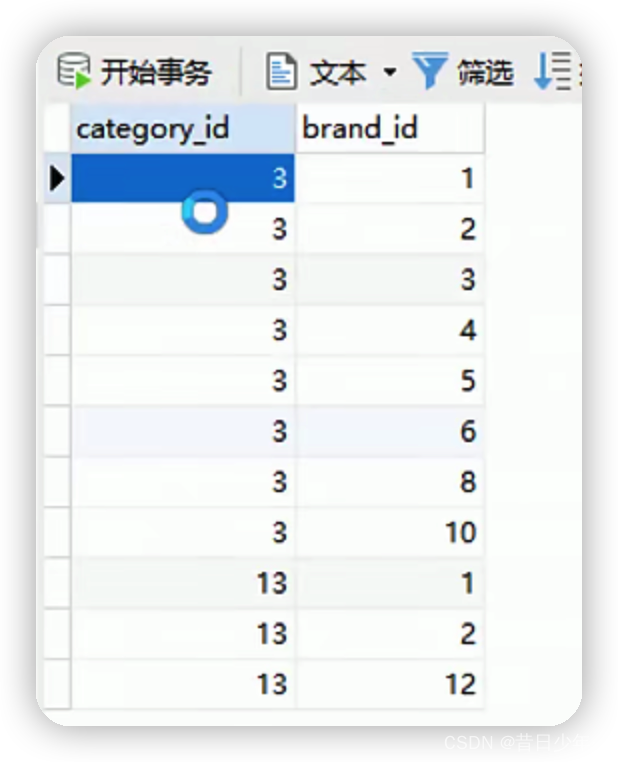
分类与品牌关联表
1.分类与品牌关联表结构图

2.sql语句
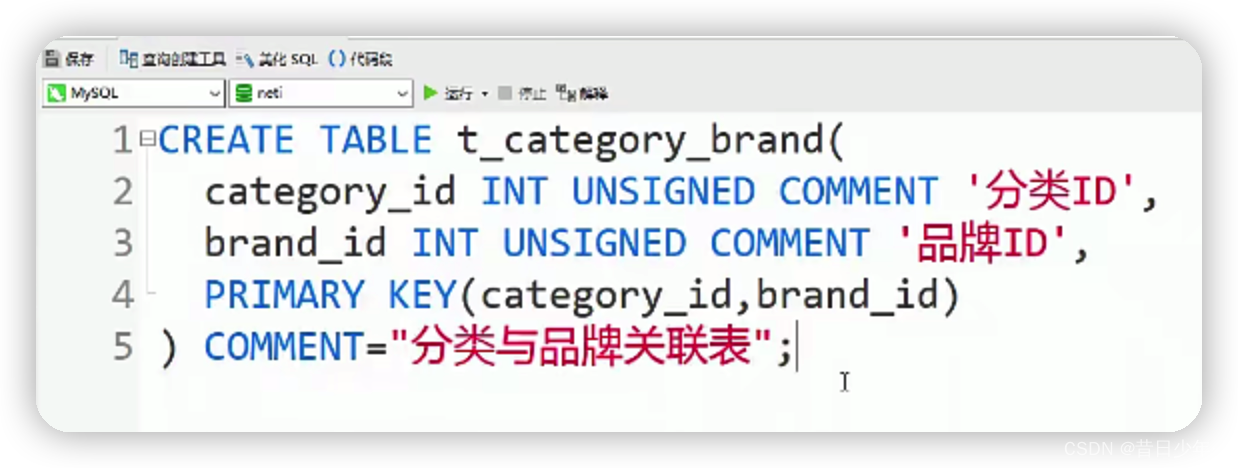
3.品牌分类关系表
设计产品表和商品表
产品表
1.产品表ER图
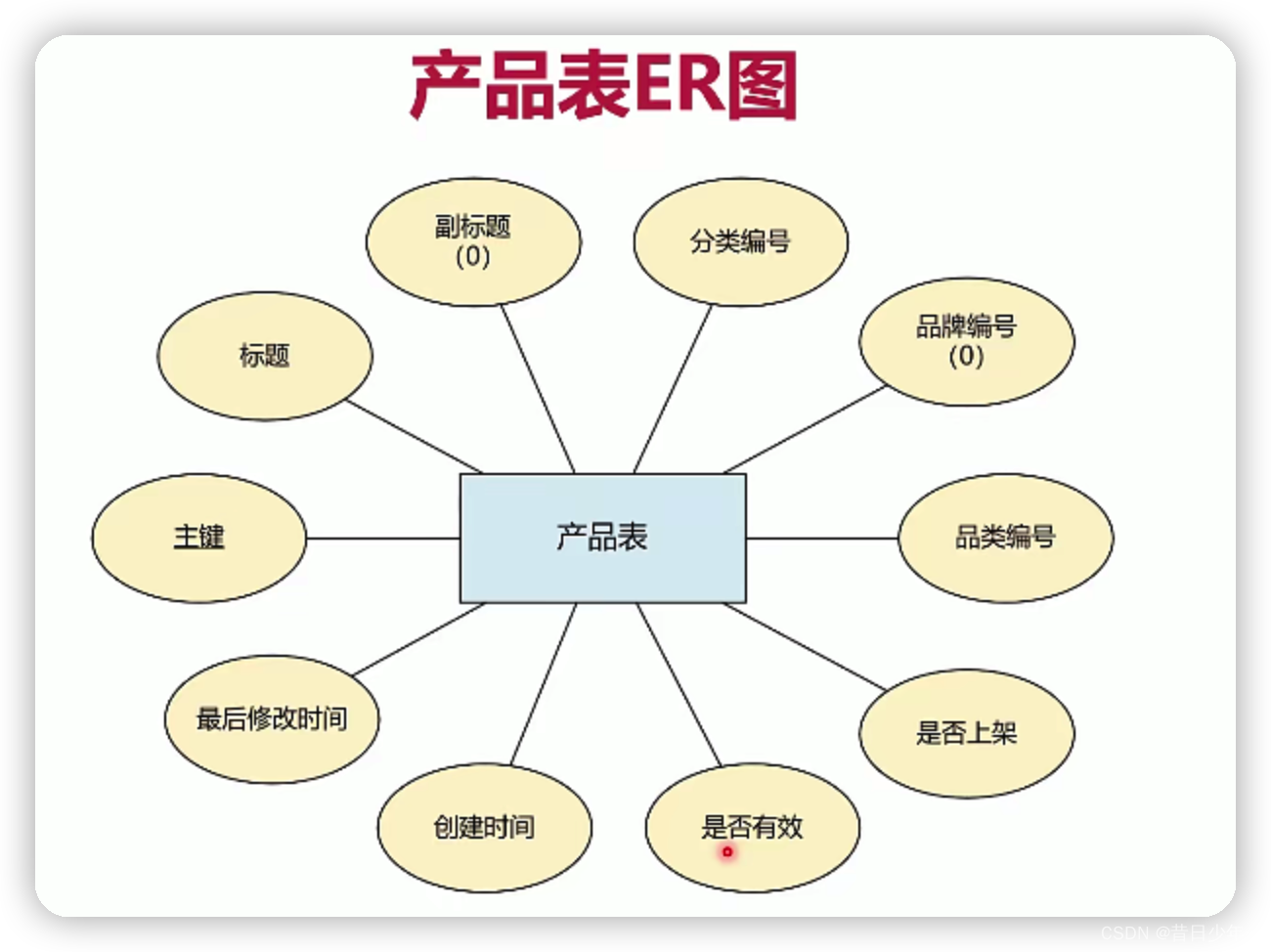
2.产品表结构图

3.sql

4.表

商品表
1.商品表ER图
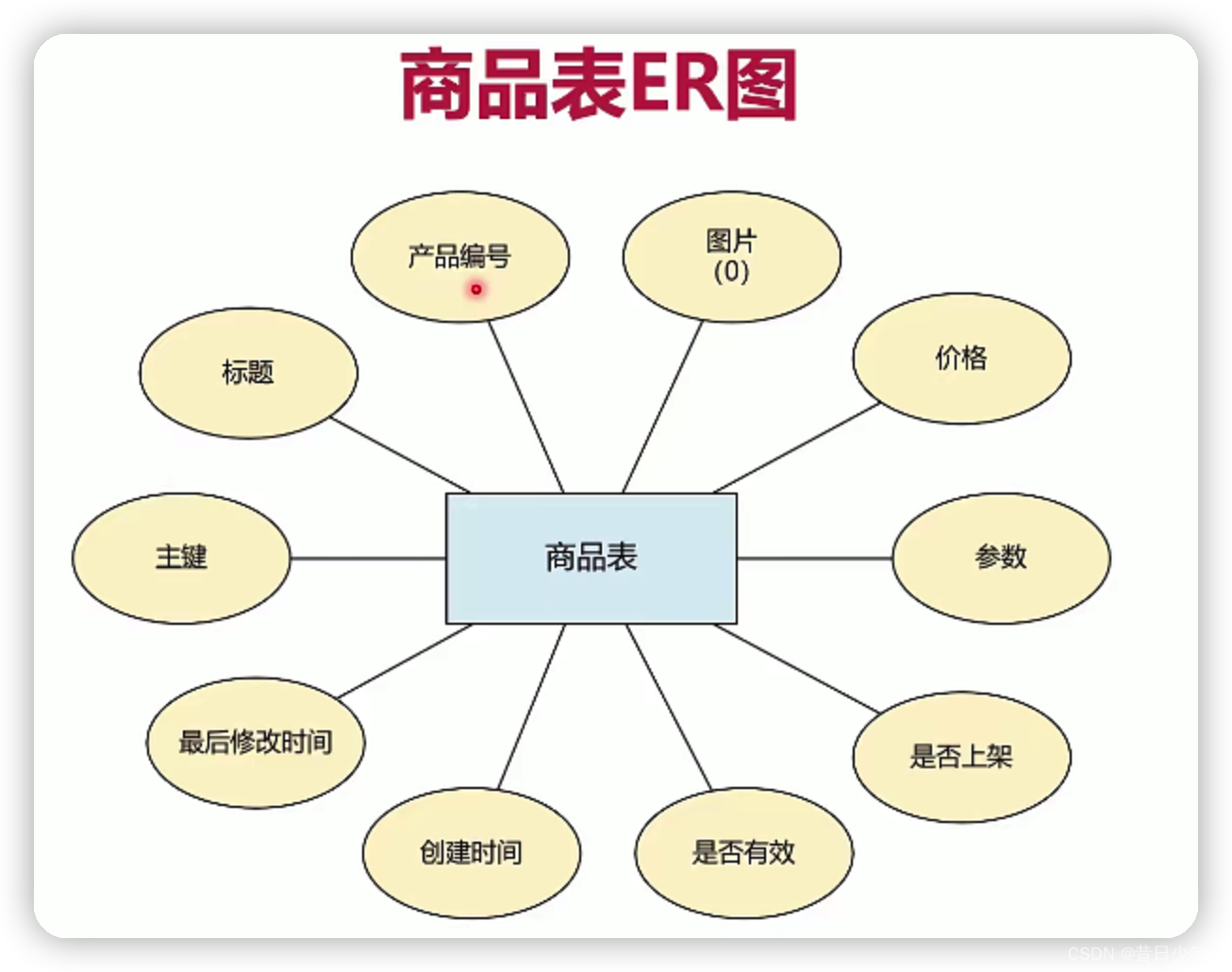
2.商品表结构图

3.sql
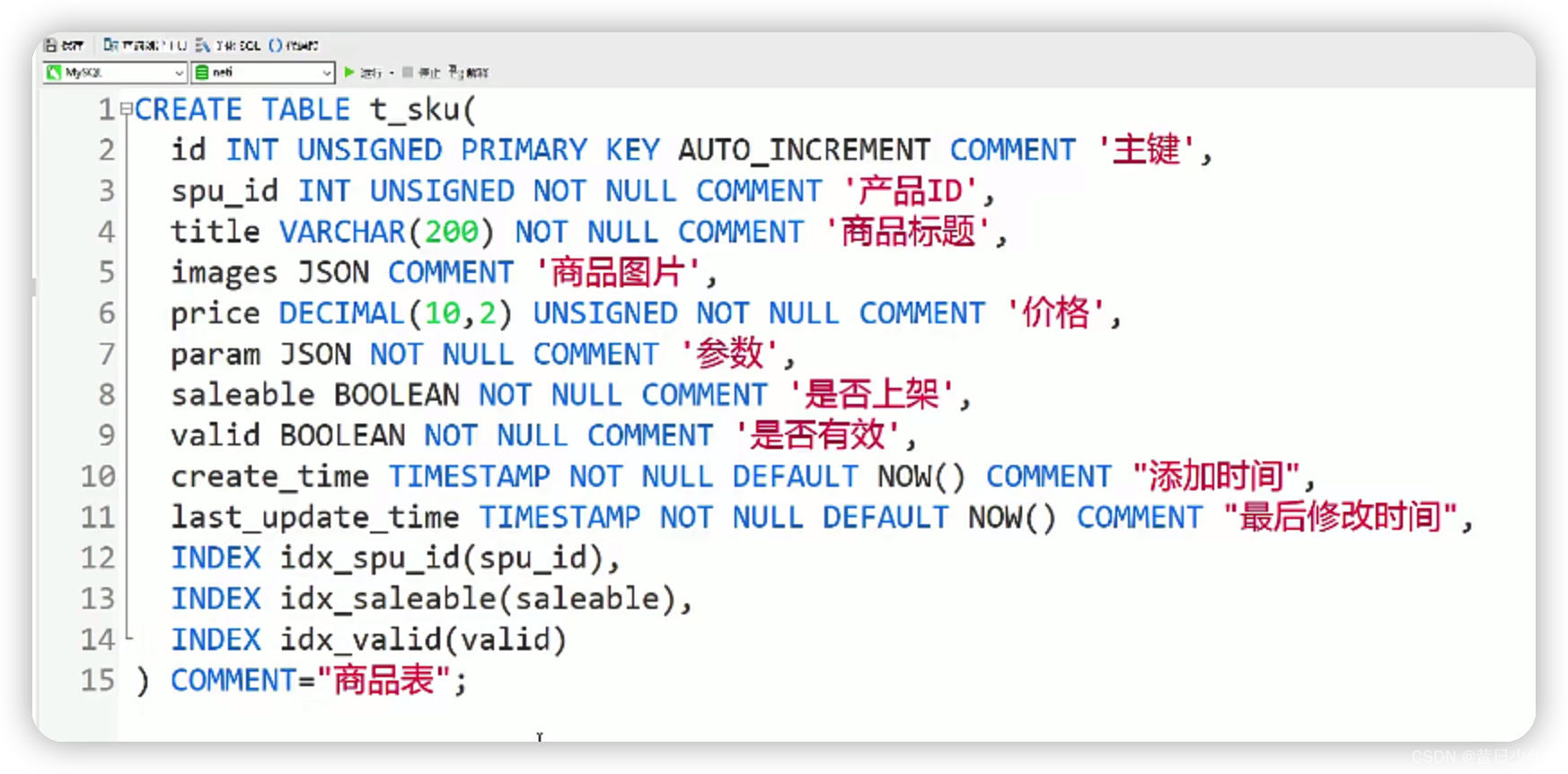
如何设计商品的库存?
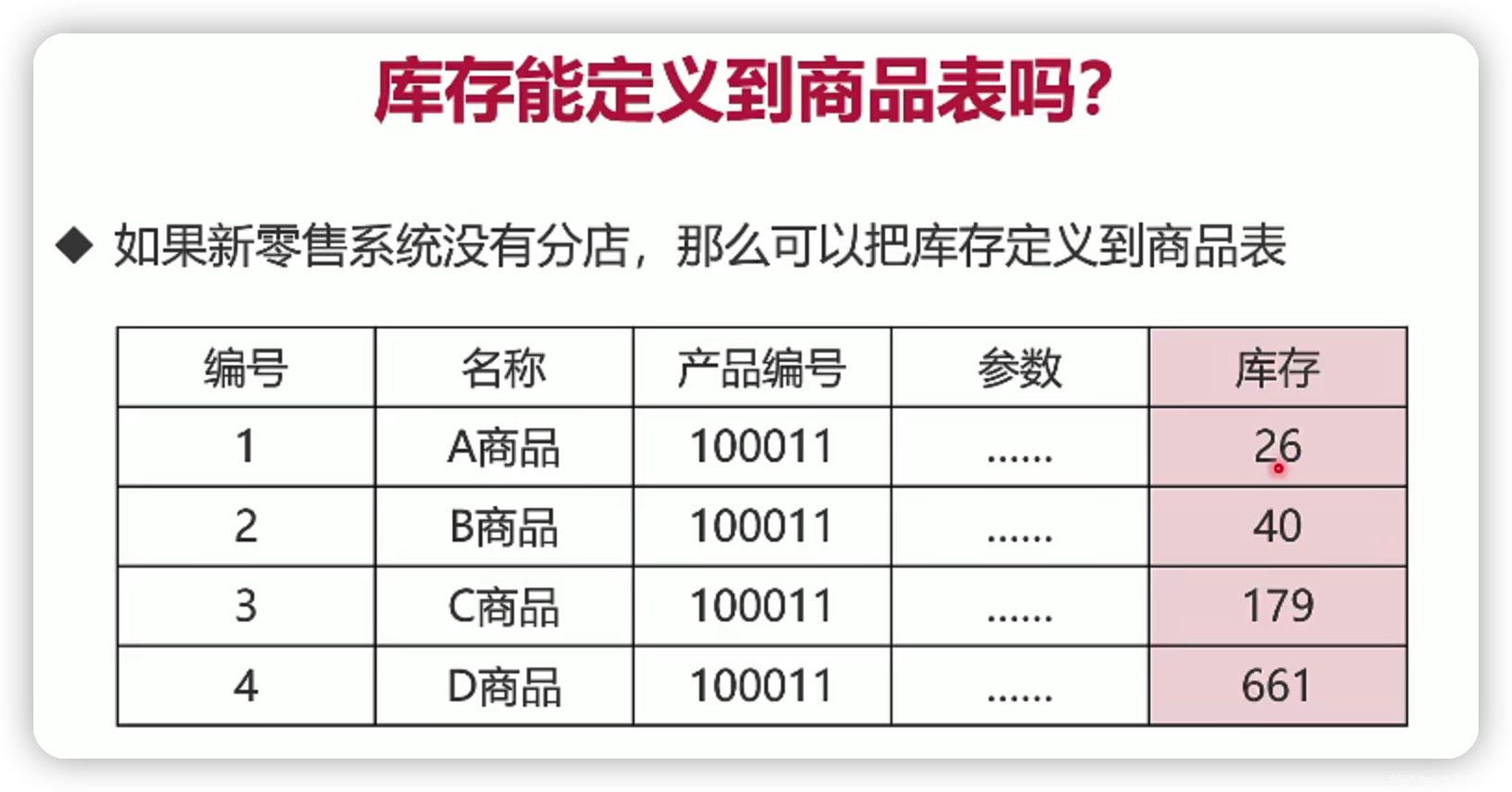
1.零售店、仓库和商品的关系
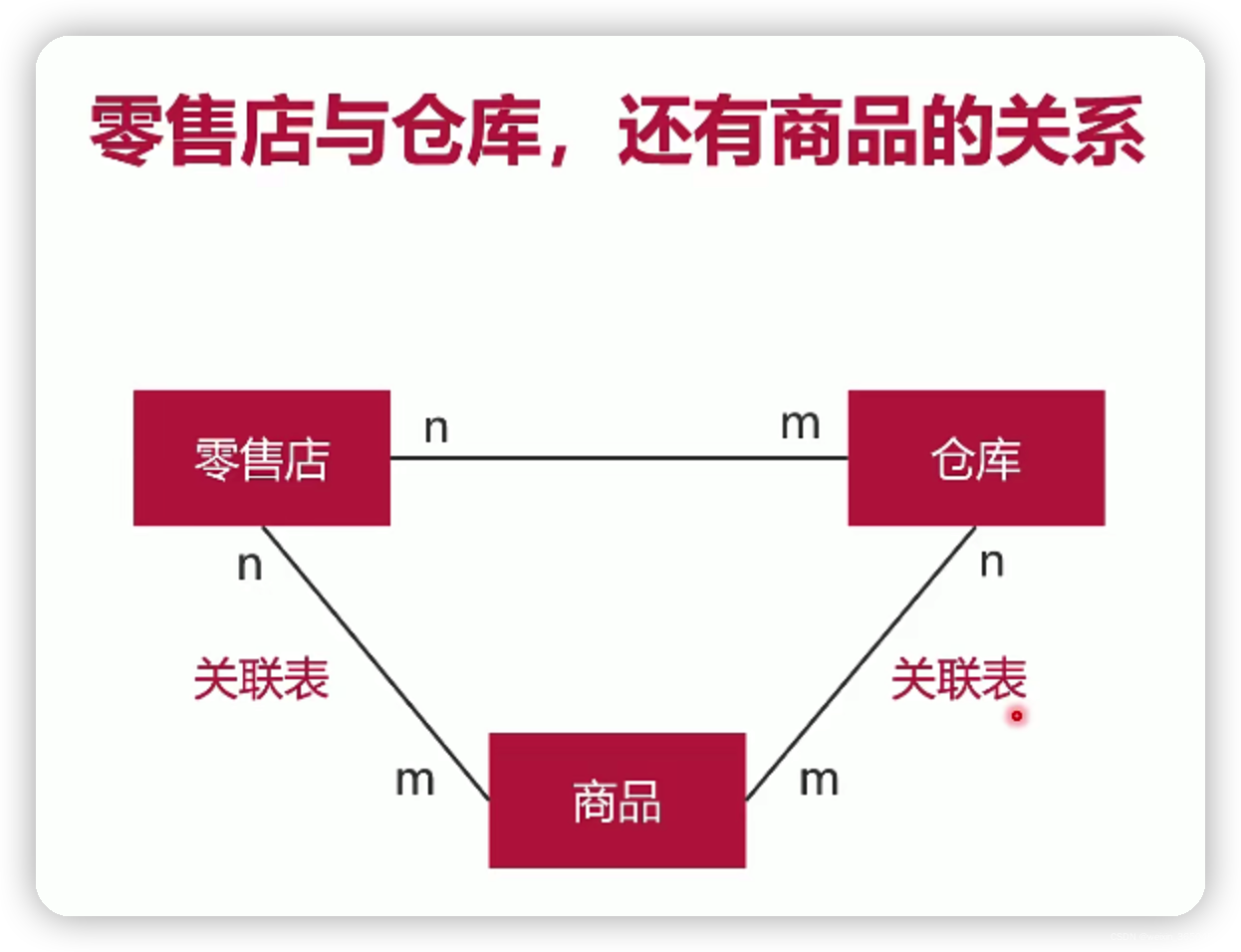
2.省份和城市表
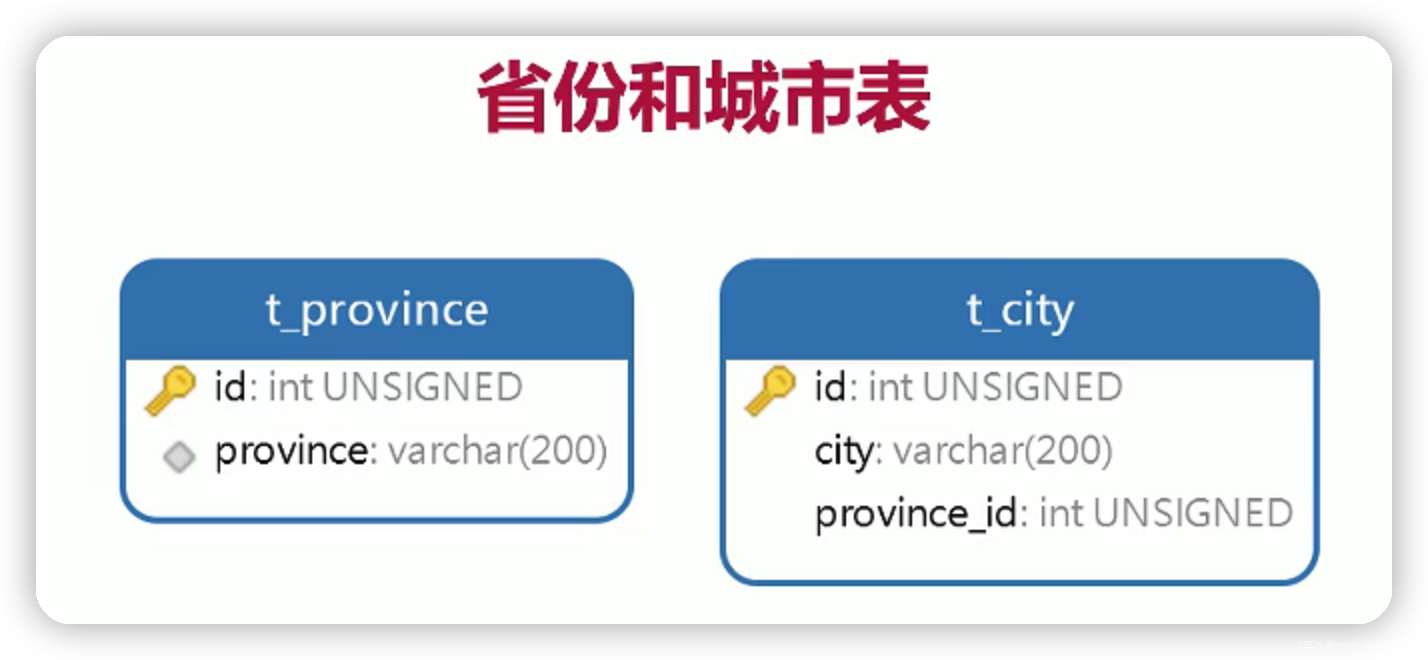
3.sql

仓库与库存
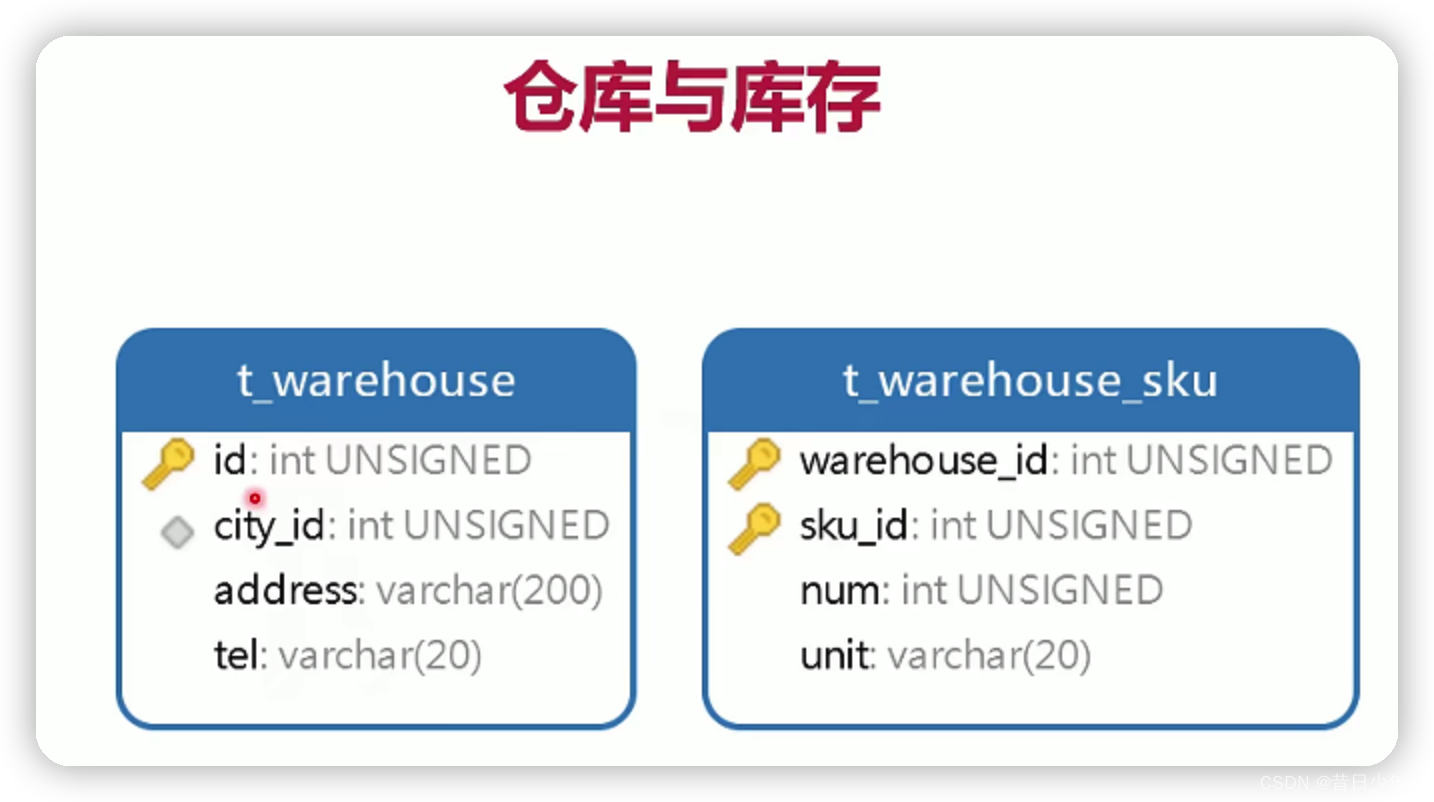
1.仓库表

2.仓库商品库存表

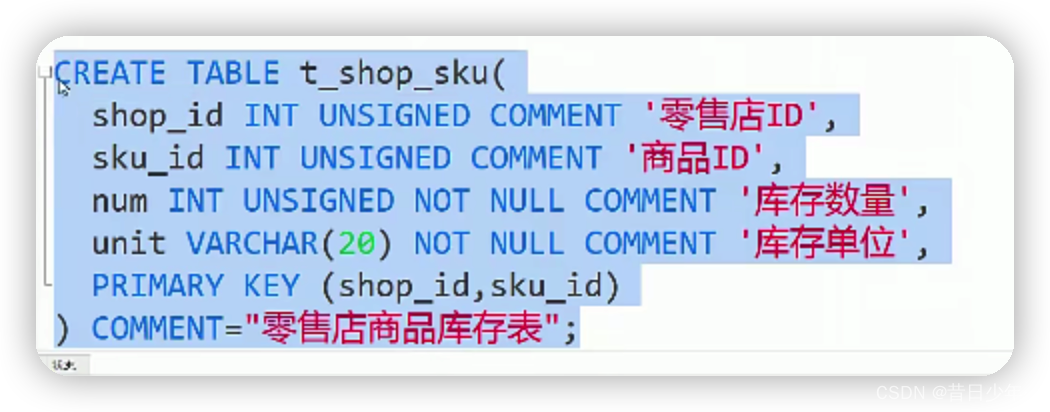
零售店与库存
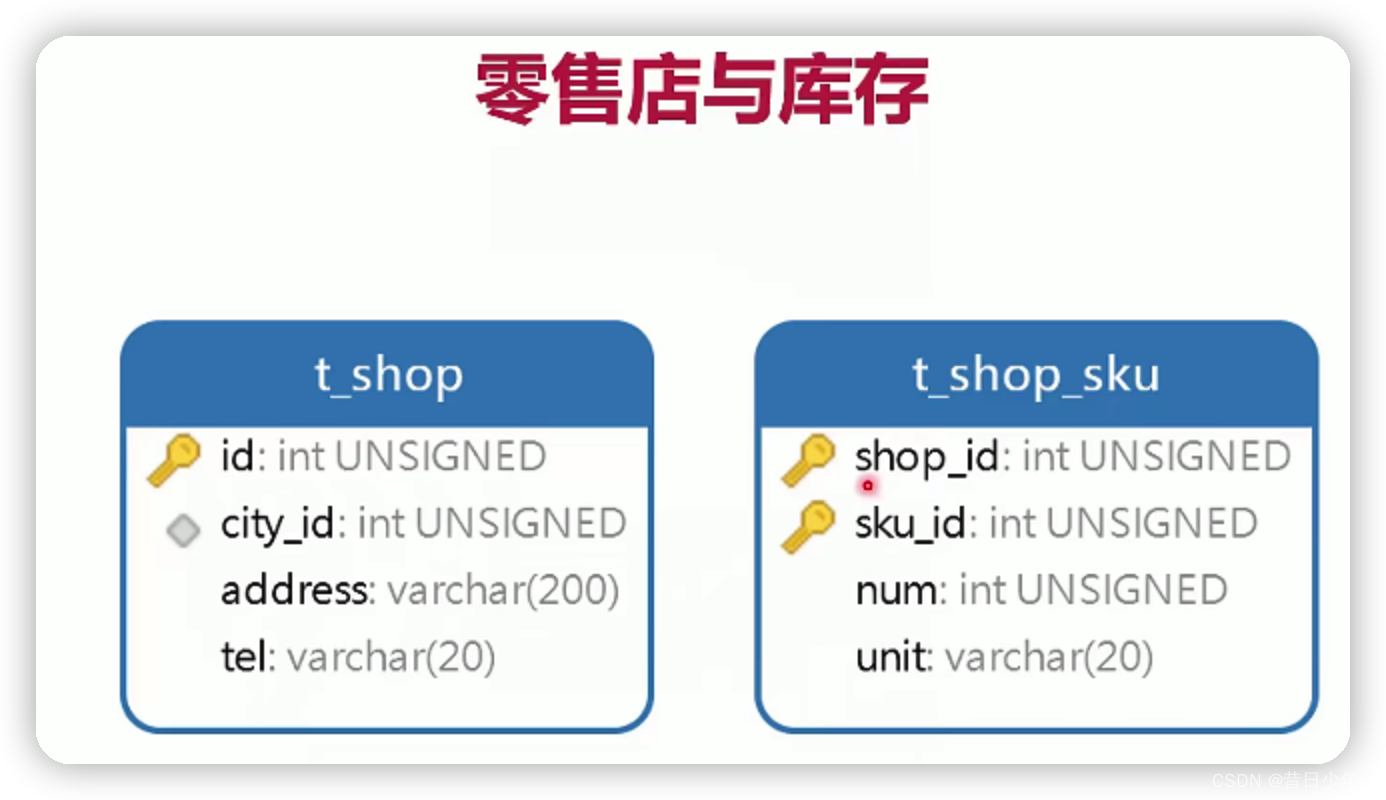
1.零售店表

2.零售店商品库存表
设计客户表
1.会员等级表

2.sql

3.客户表
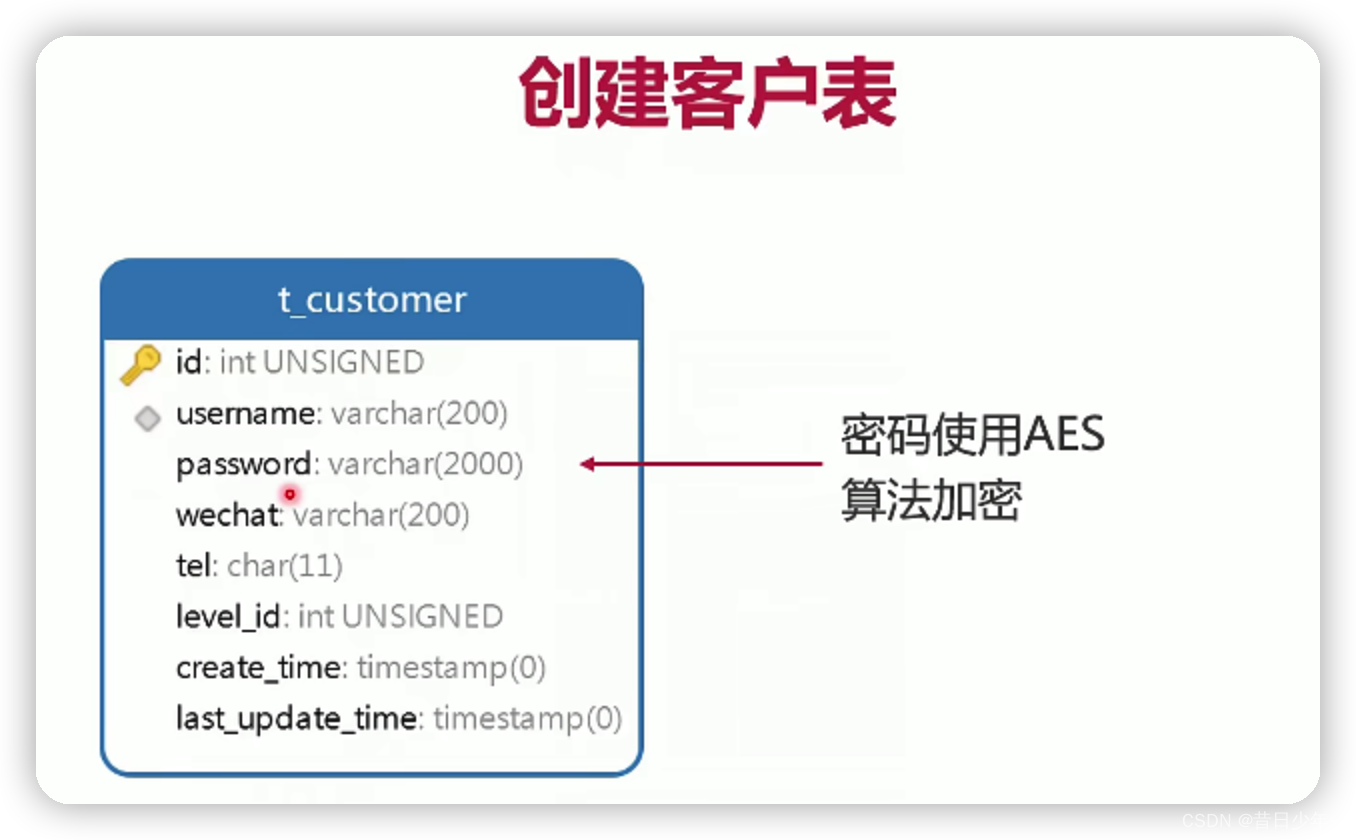
数据库AES加密解密,利用数据库函数

4.sql

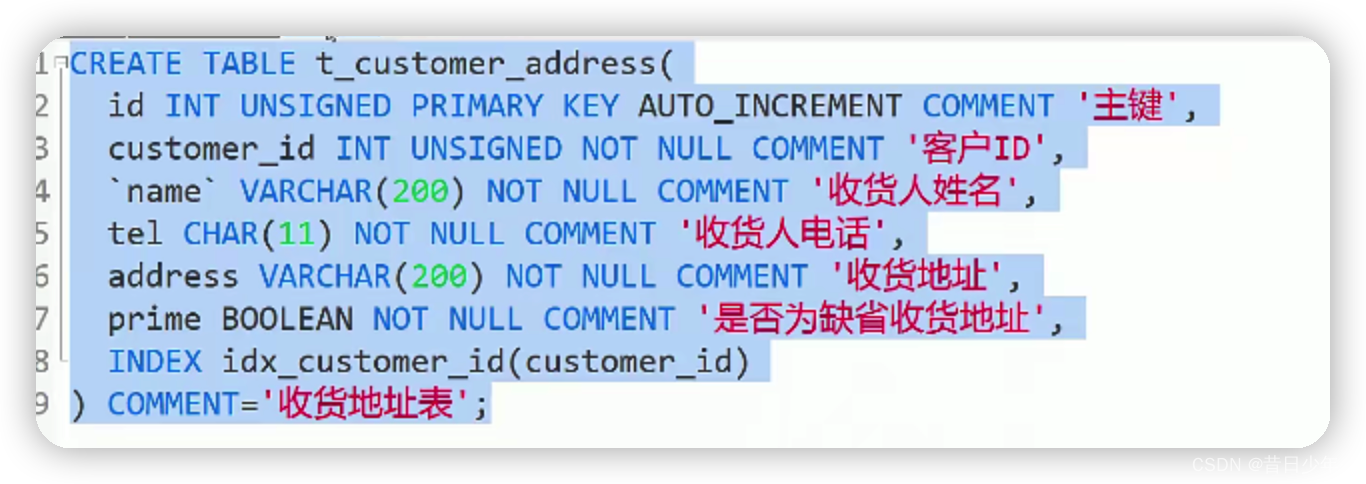
5.创建收货地址表

6. sql
设计购物券
1.购物券表

2.sql

3.客户关联购物券表
voucher_id和customer_id不能使用复合主键,因为同一个客户可以领取多张同样的购物券;

4.sql

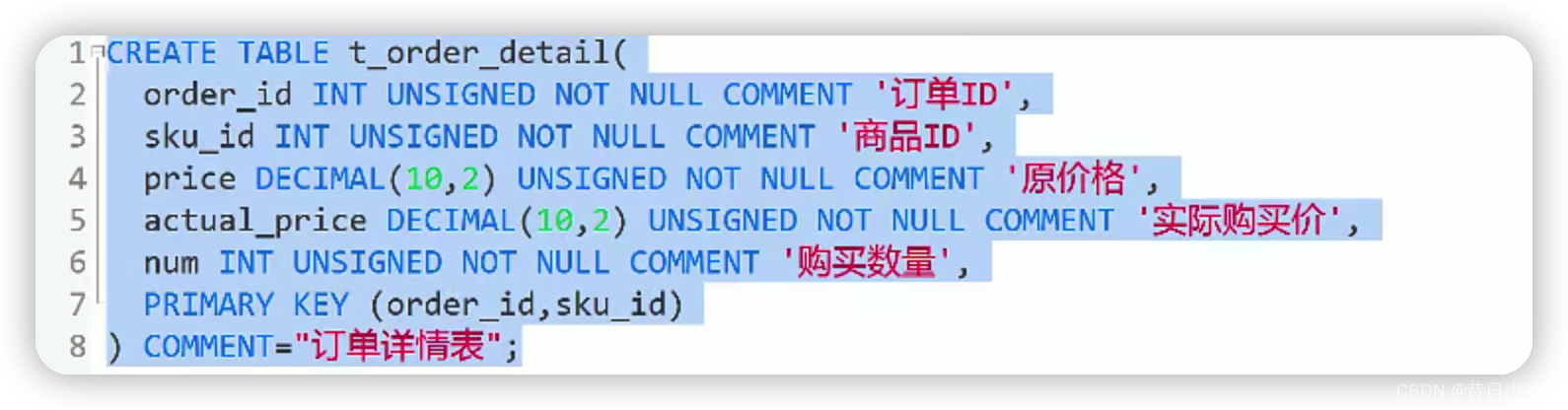
设计订单表
订单表和订单明细表

1.订单表

2.sql


3.订单详情表

4.sql
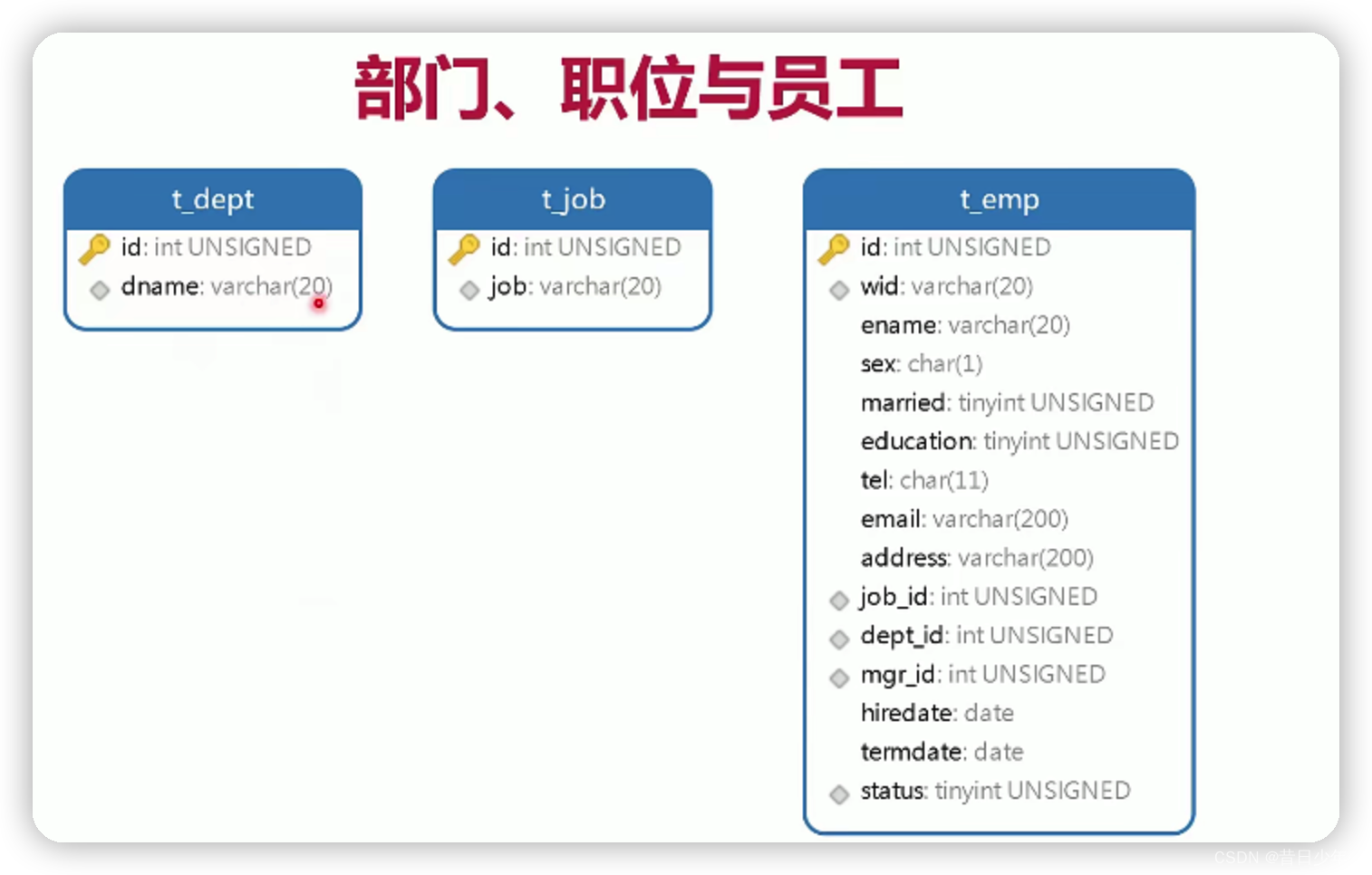
设计员工与用户表
1.部门、职位、员工
2.sql



3.用户与角色
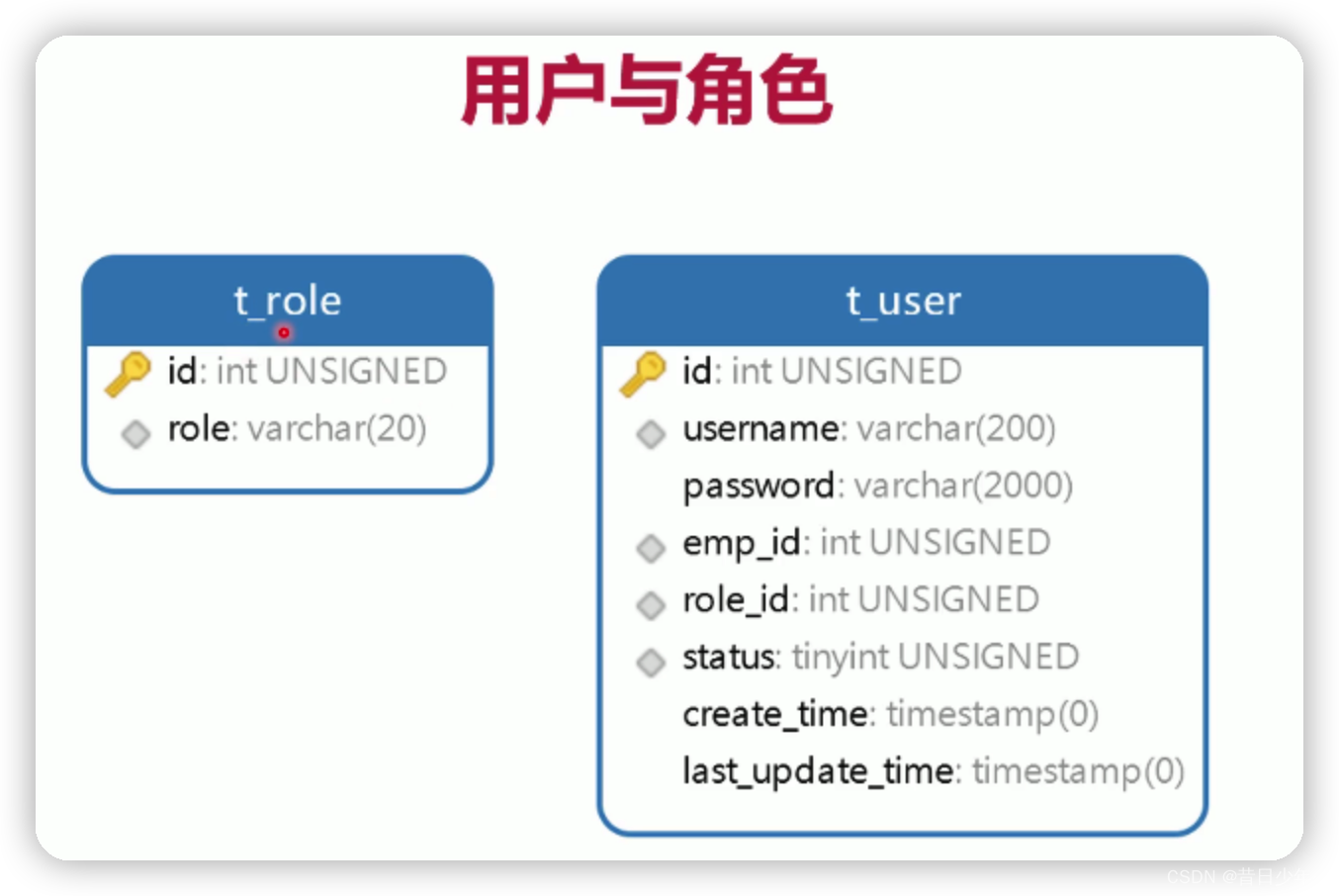
4.角色表

5.用户表
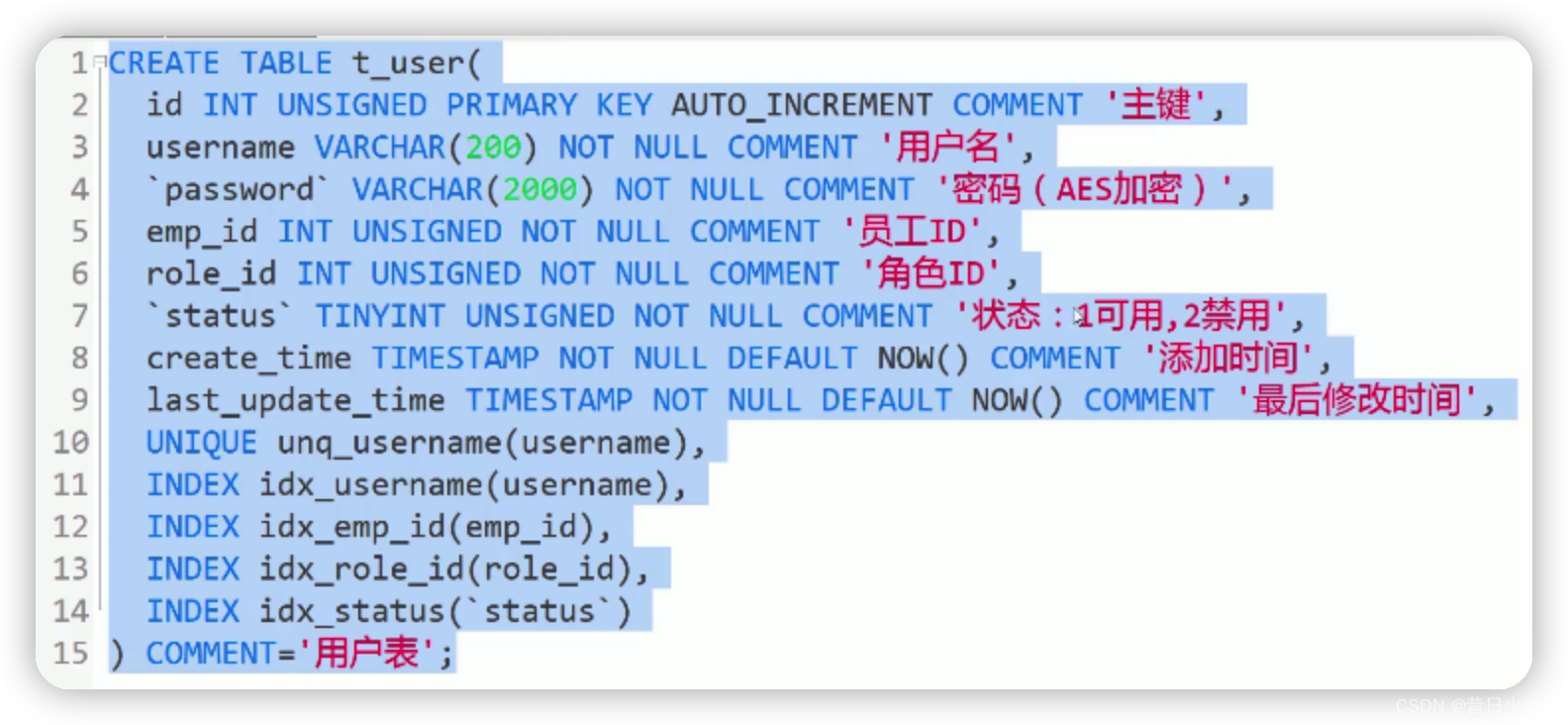
设计快递表和退货表
1.快递表
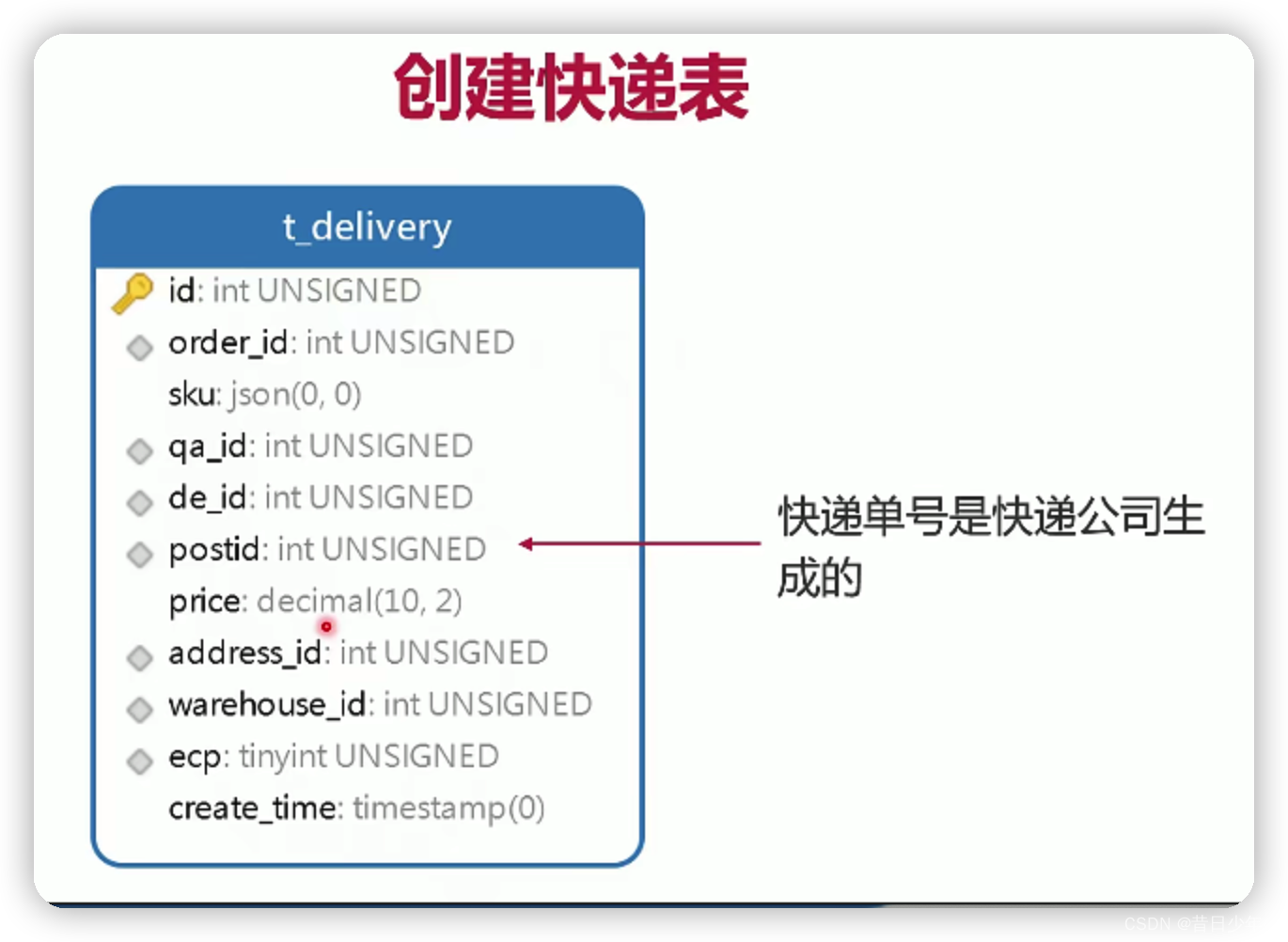
2.sql
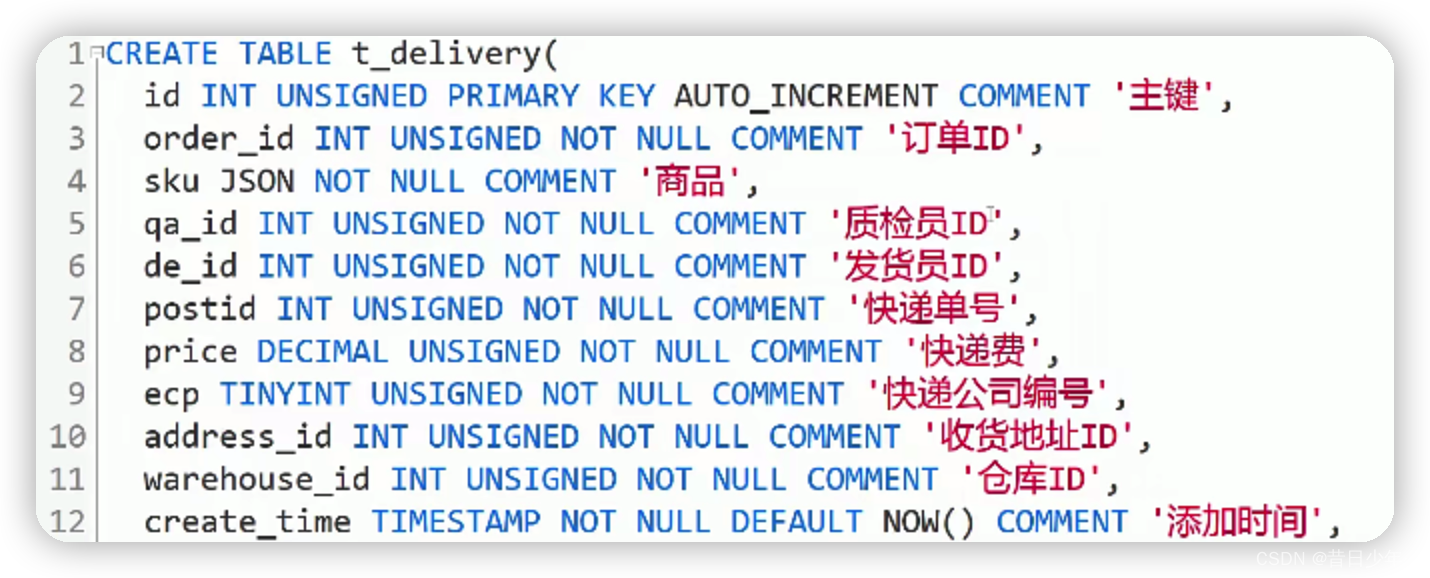

3.退货表
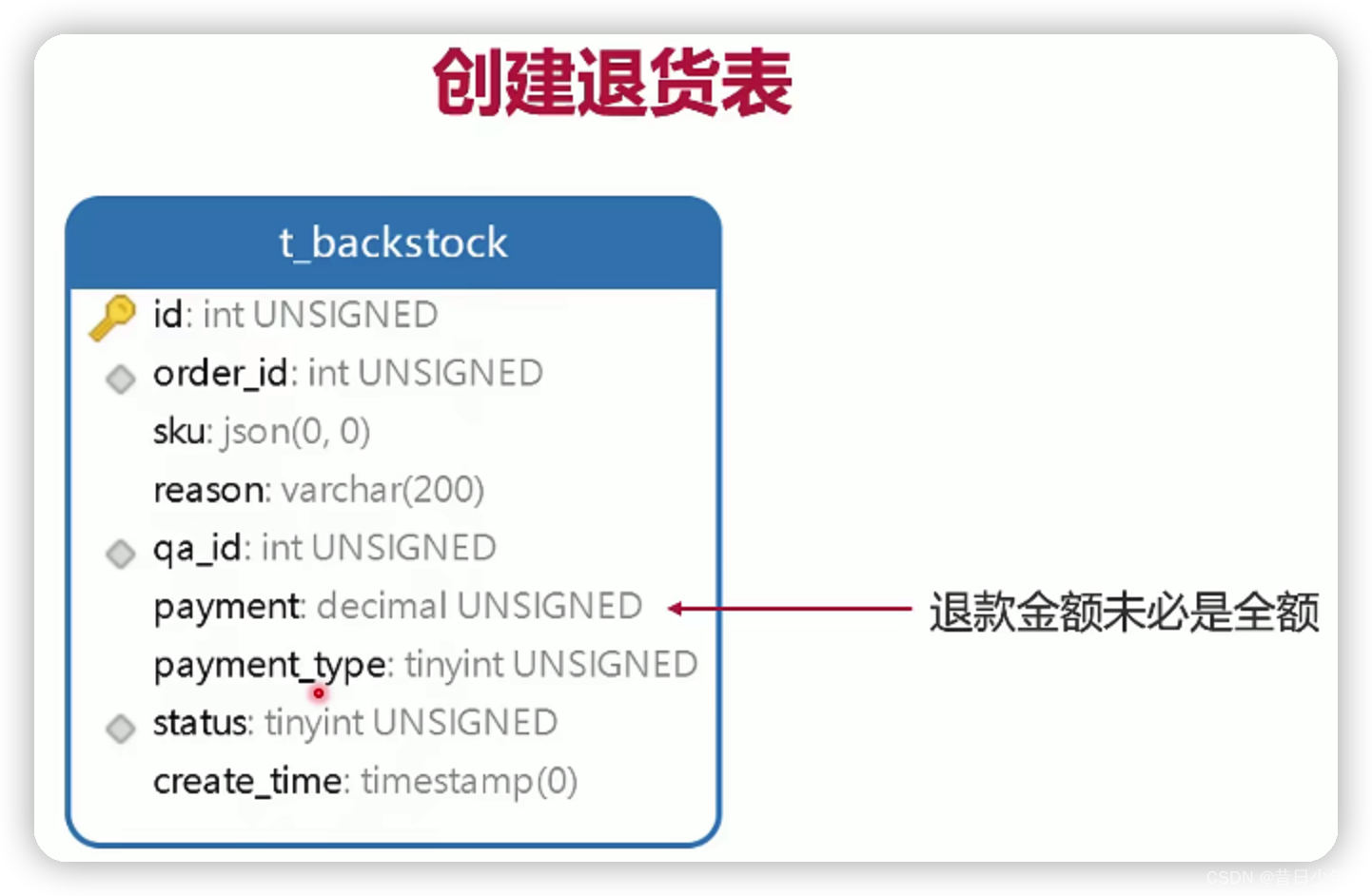
4.sql

设计评价表
1.评价表
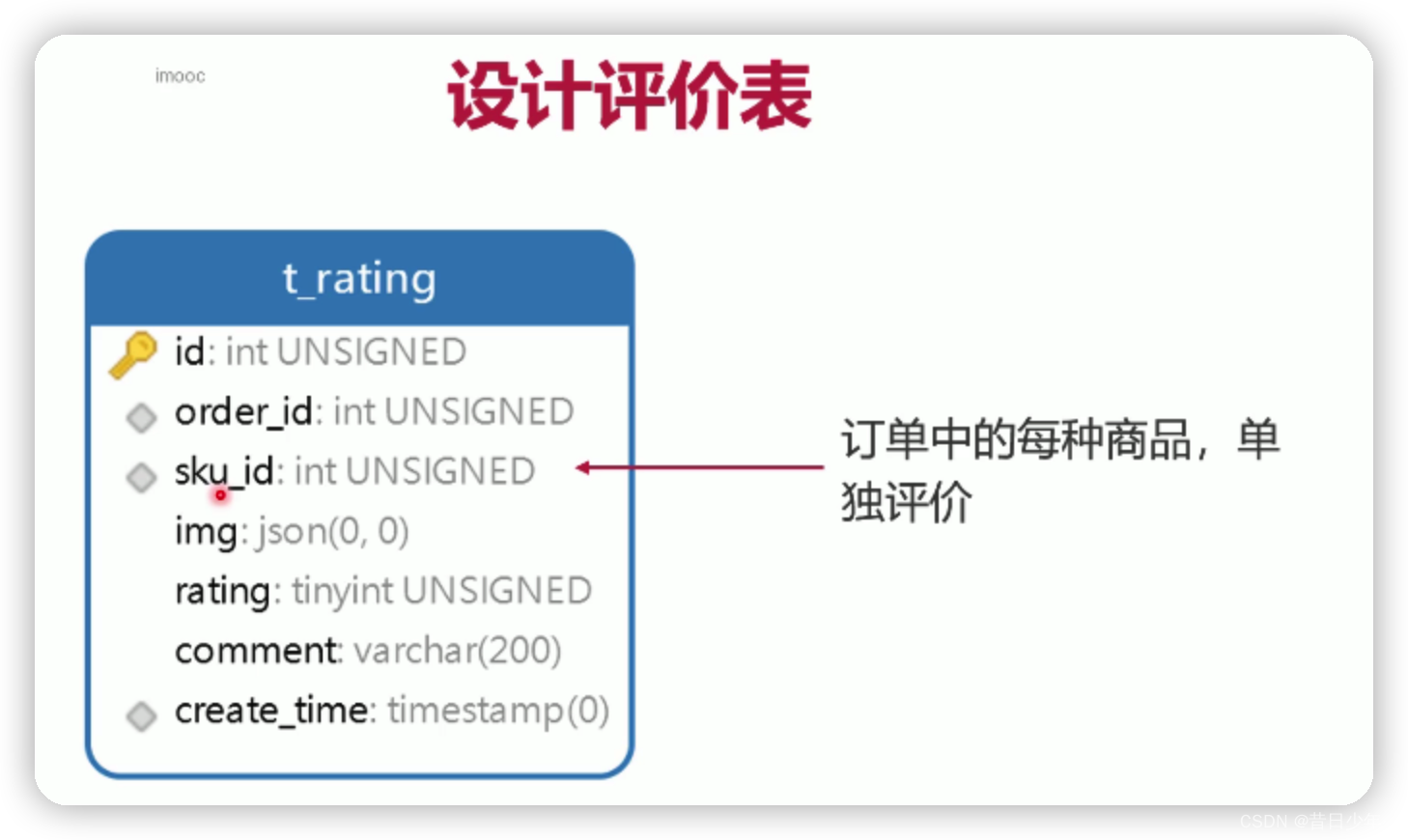
2.sql

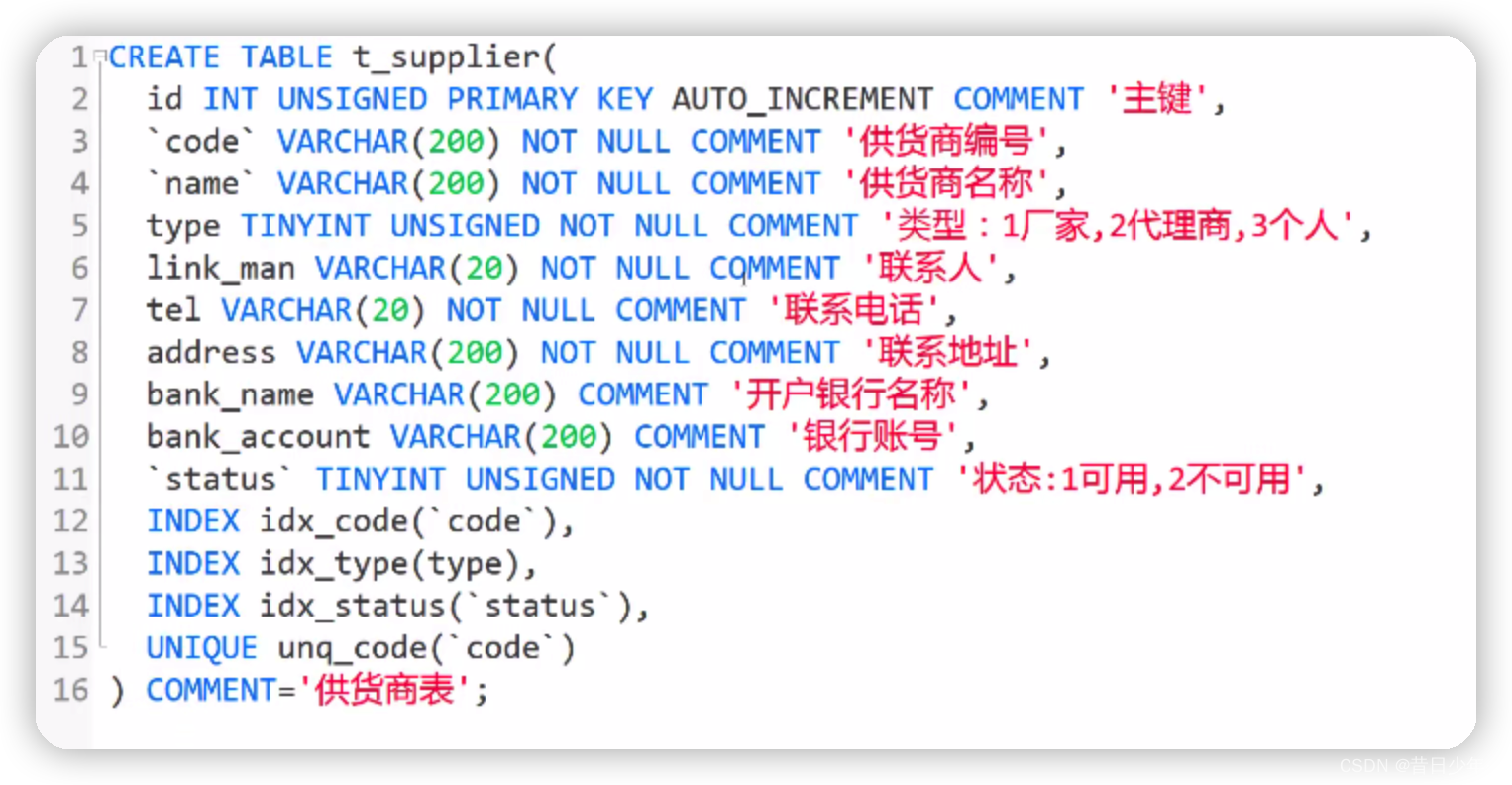
设计供货商数据表


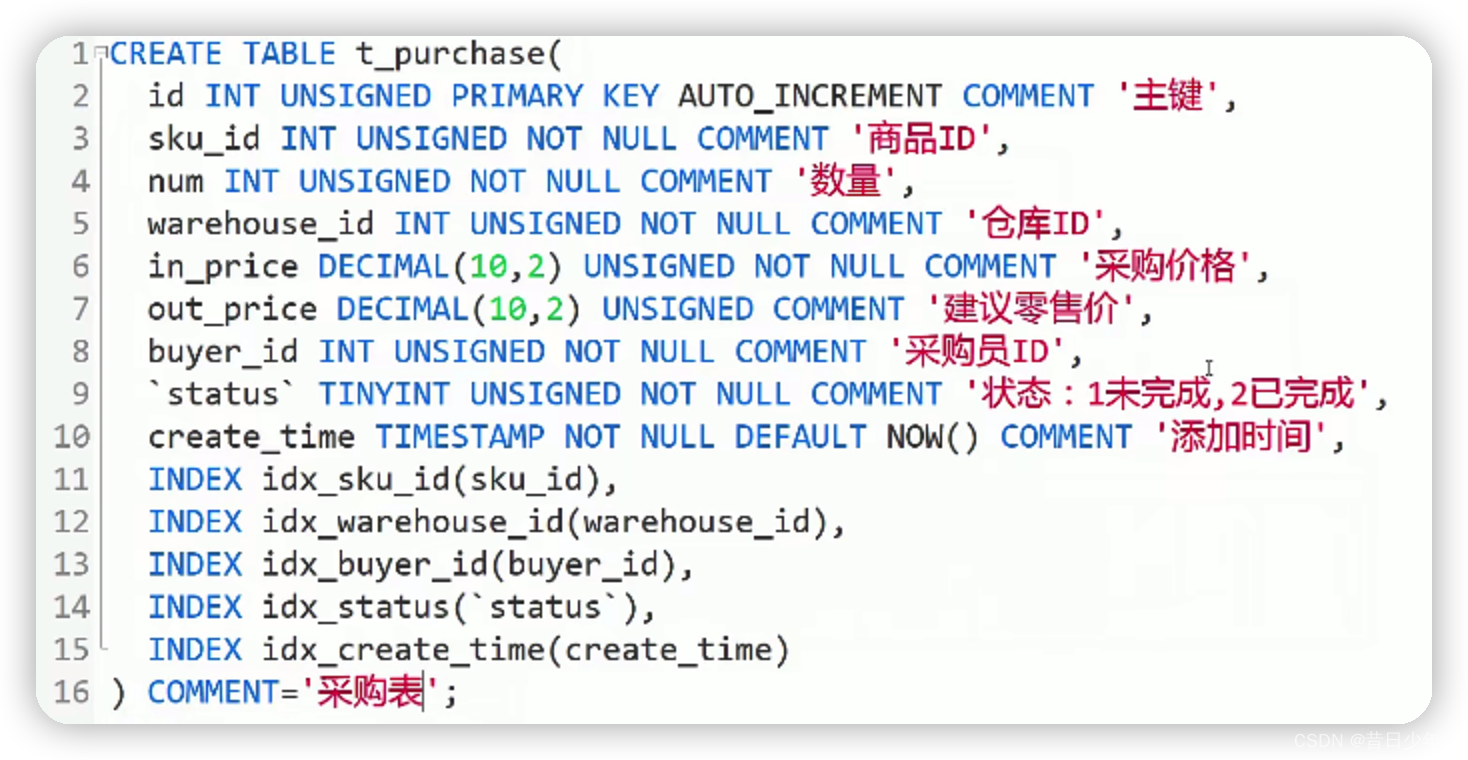
设计采购与入库数据表

1.采购表
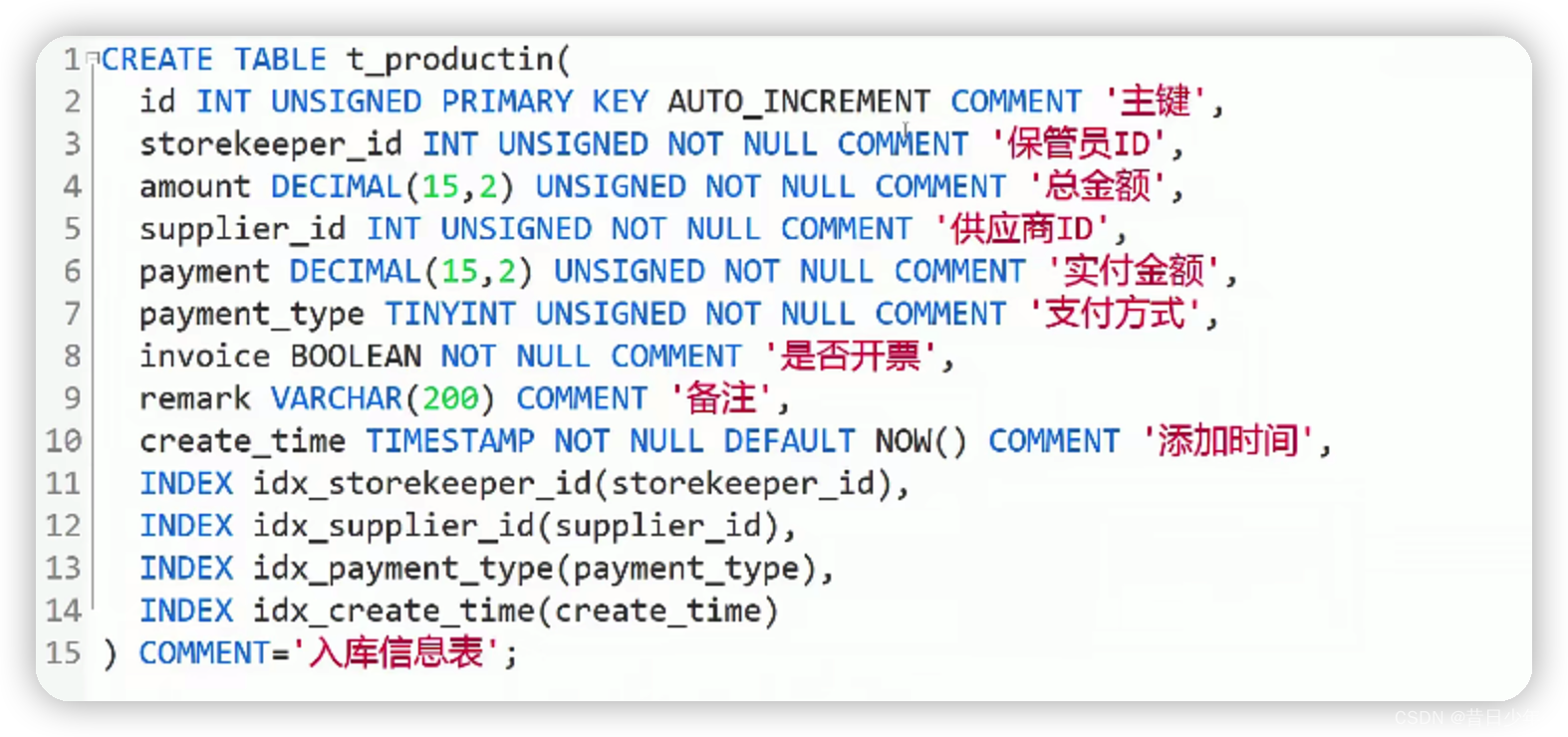
2.入库信息表
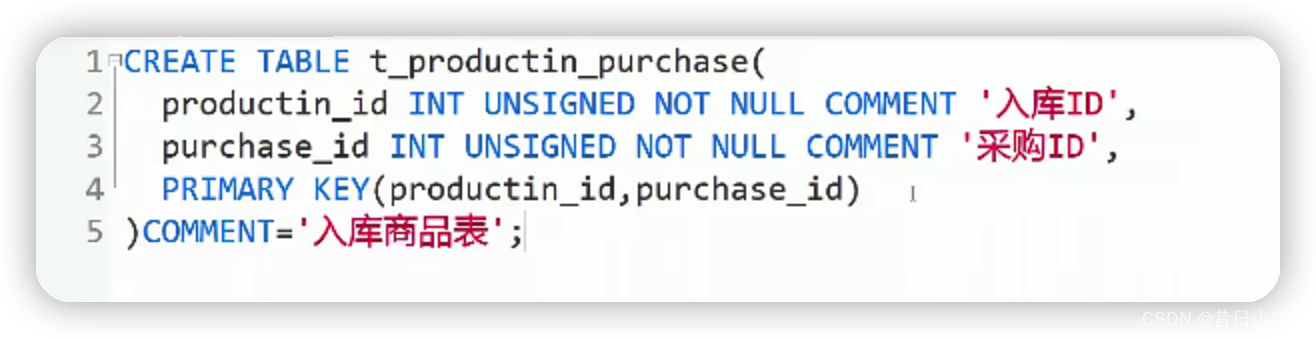
3.入库商品表

常见问题与企业级解决方案
1.表的主键用数字还是UUID
1.什么是UUID?

2. 为什么有人想要使用UUID?
在数据库集群中,为了避免每个mysql各自生成的主键产生重复,所以有人考虑采用UUID方式
3.UUID的优点
(1).使用UUID,分布式生成主键,降低了全局节点的压力,使得主键生成速度更快;
(2).使用UUID生成的主键值
全局唯一
;
(3).跨服务器合并数据很方便;
4.UUID的缺点
(1).UUID占用16个字节,比4字节的INT类型和8字节的BIGINT类型
更加占用存储空间
;
(2).UUID是字符串类型,查询速度很慢;
(3).UUID不是顺序增长的,作为主键,数据写入IO随机性很大;
5.主键自动增长的优点
(1).INT和BIGINT类型占用存储空间较小;
(2).MySQL检索数字类型的速度远快过字符串;
(3).主键值自动增长,所以IO写入连续性较好;
6.分布式环境下的主键自动增长
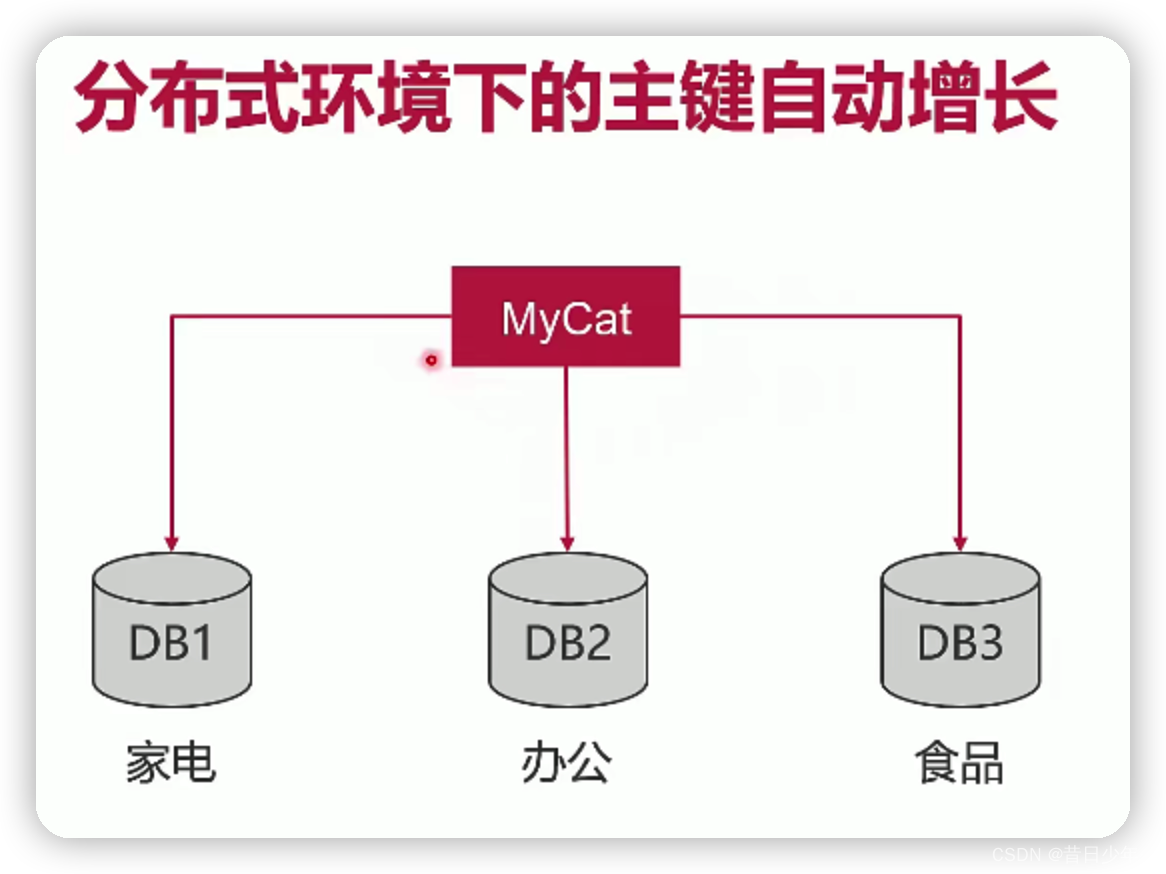
7.总结
无论什么场合,都不推荐使用UUID作为数据表的主键。
在线修改表结构
1.在线修改表结构必须慎重
(1).在业务系统运行的过程中随意删改字段,会造成重大事故
(2).常规的做法是业务停机,维护表结构
(3).但是不影响正常业务的表结构是允许在线修改的
2.ALTER TABLE修改表结构的弊病
(1).由于修改表结构是
表级锁
,因此在修改表结构时,影响表写入操作;
(2).如果修改表结构失败,必须还原表结构,所以耗时更长;
(3).大数据表记录多,修改表结构锁表时间很长;
3.使用
PerconaTookit
工具
(1).Percona公司提供了维护MySQL的PerconaTookit工具包
(2).pt-online-schema-change可以完成在线修改表结构


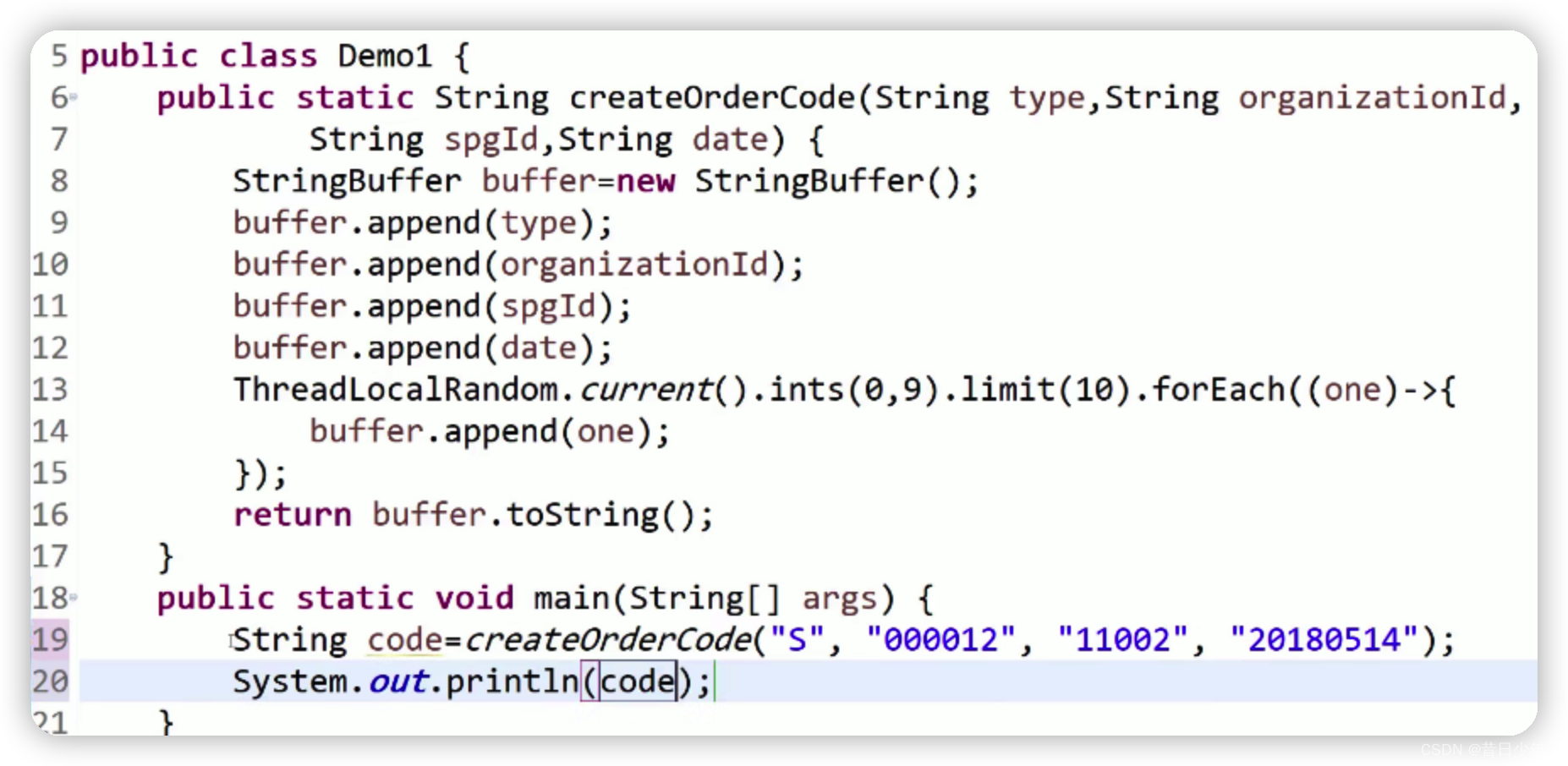
谈谈订单号和流水号的关系

使用
ThreadLocalRandom
生成随机数;
逻辑删除还是物理删除
1.物理删除
(1).物理删除就是用DELETE、TRUNCATE、DROP语句删除数据
(2).物理删除是把数据从硬盘中删除,可以释放存储空间,缩小数据表的体积,对性能提升有帮助
2.物理删除的代价
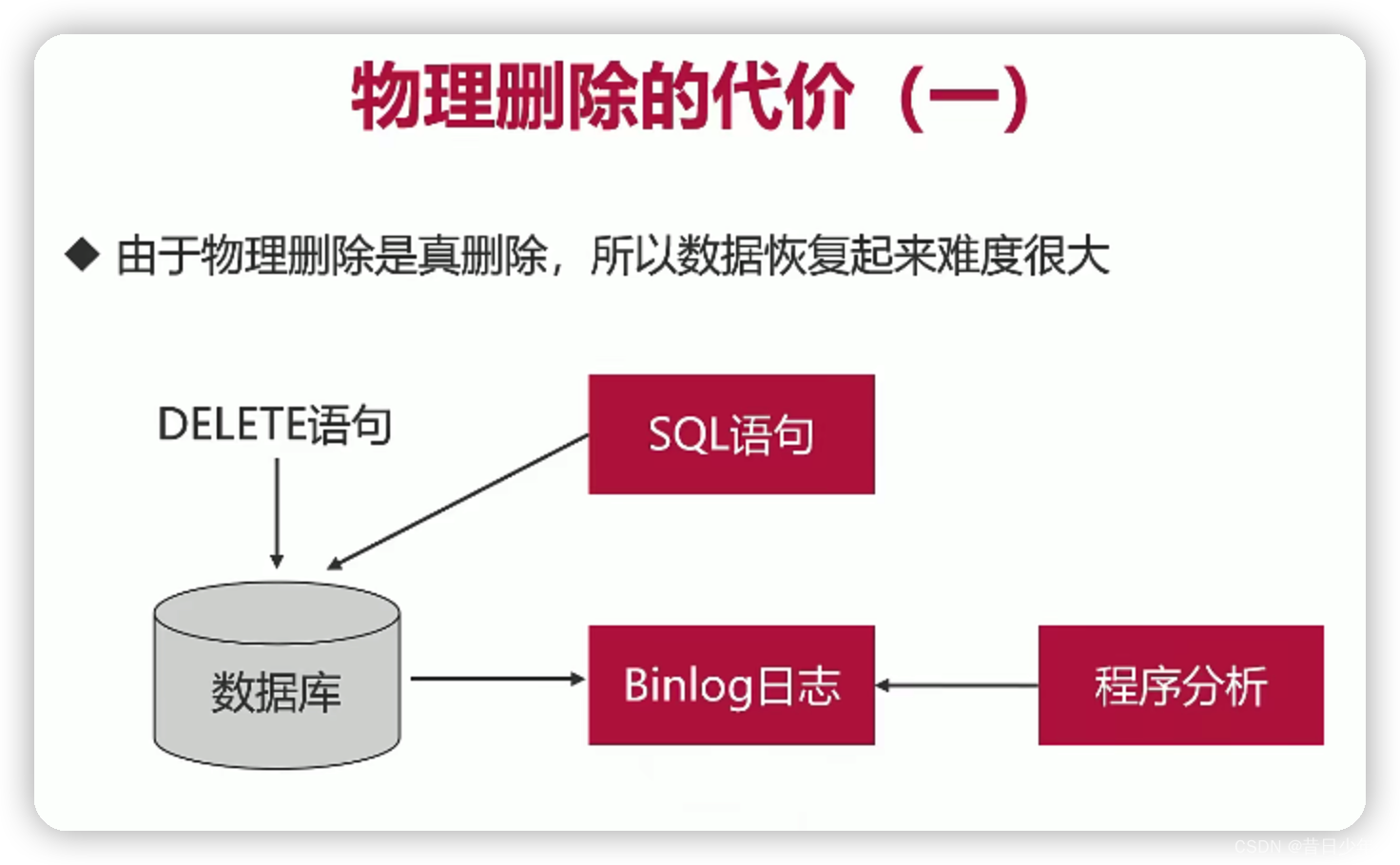
可以使用Binlog日志进行恢复,或者冗余一台mysql,设置延时同步,作数据备份。

3.什么样的数据不适合物理删除?
(1).
核心业务表的数据
不建议做物理删除,只做状态变更。比如订单作废、账号禁用、优惠券作废等等。
(2).既不删除数据,又能缩小数据表体积,可以
把记录表转移到历史表
。
业务表 —-转移—-> 历史表
4.逻辑删除
逻辑删除就是在数据表添加一个字段(is_deleted),用字段值标记该数据已经逻辑删除,查询的时候跳过这些数据
SELECT.....FROM.....WHERE is_deleted=0
核心业务数据表,必须要采用逻辑删除
5.历史表的创建
CREATE TABLE 历史表 LIKE 业务表
千万记录,如何快速商品分页
1.用java程序创建1千万条数据,输出到txt文件中,并导入到数据库中
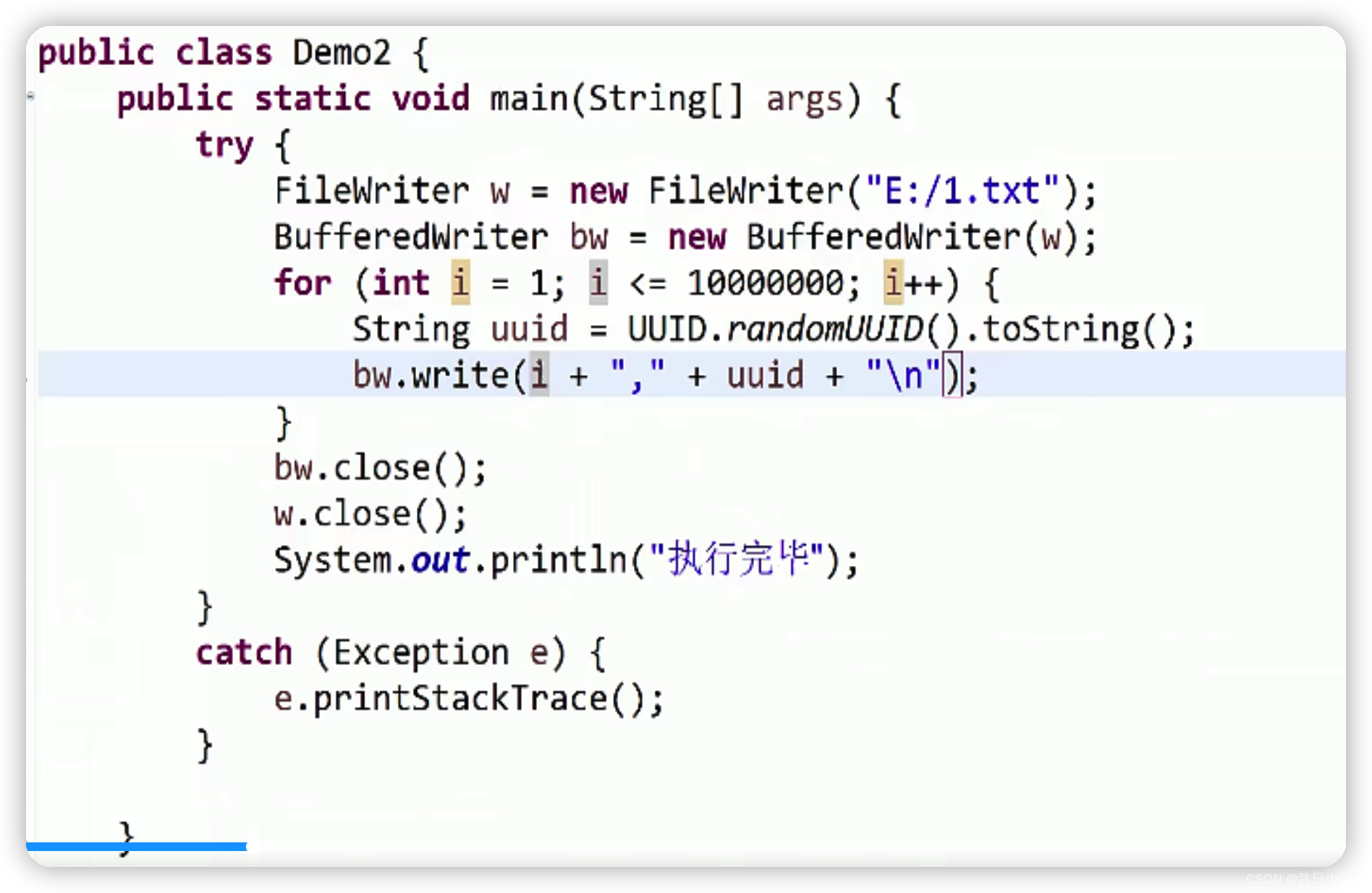
2.用LIMIT语句分页查询,看每条sql的耗时
SELECT id,val FROM t_test LIMIT 100,10;
SELECT id,val FROM t_test LIMIT 10000,10;
SELECT id,val FROM t_test LIMIT 1000000,10;
SELECT id,val FROM t_test LIMIT 5000000,10;
3.用LIMIT会全表查询,很耗时
优化方法1:利用
主键索引
来加速分页查询
SELECT * FROM t_test WHERE id>=5000000 LIMIT 100;
SELECT * FROM t_test WHERE id>=5000000 AND id<=5000000 + 10;
上面用ID区间范围分页,如果
主键值不连续
,怎么分页?
1.使用逻辑删除,不会造成主键不连续;
2.利用主键索引加速,再做表连接查询
SELECT t.id,t.name FROM t_test t JOIN (SELECT id FROM t_test LIMIT 5000000,100) tmp ON t.id = tmp.id;
3.其它解决办法

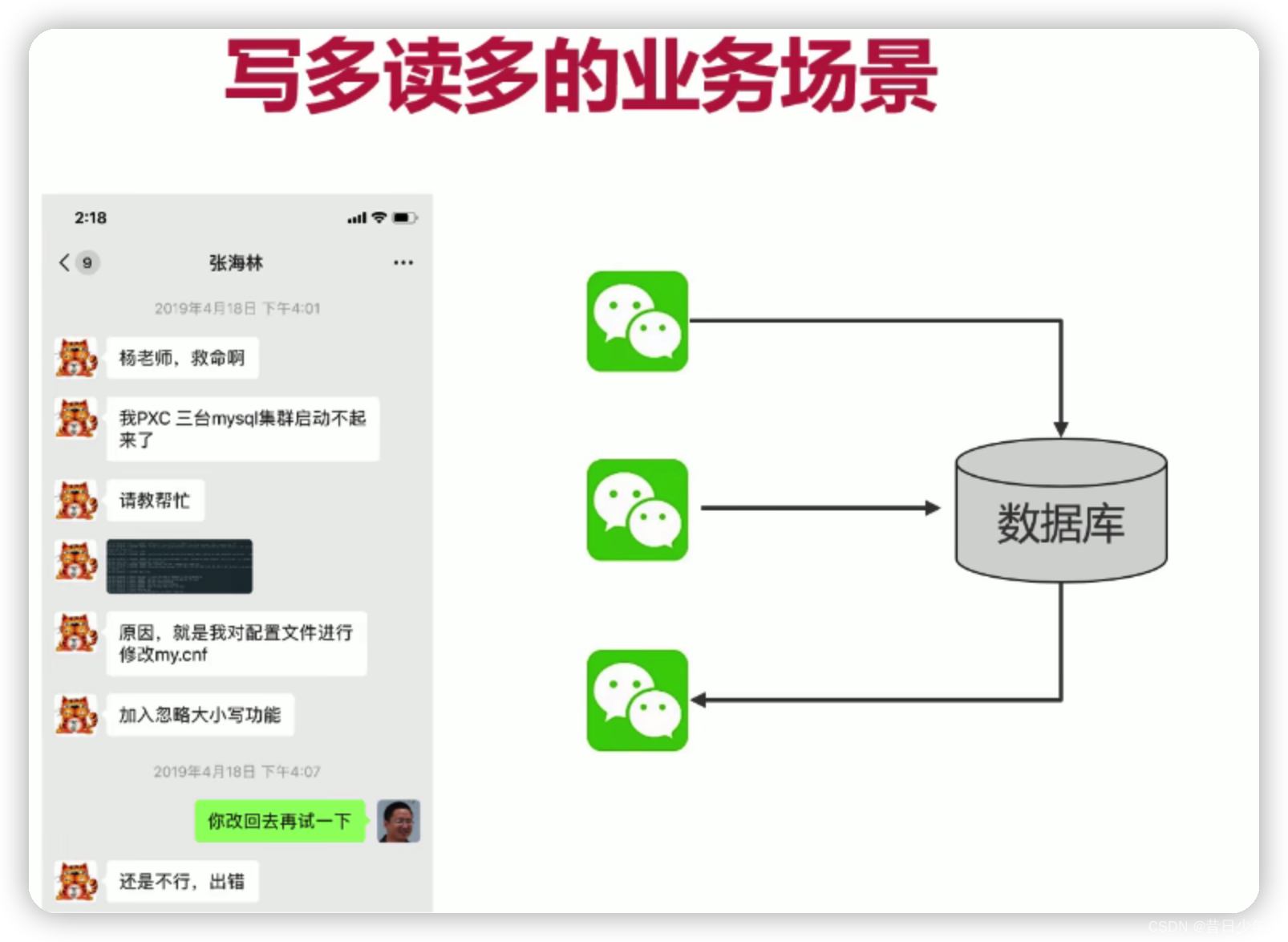
读多写少、读多写多、读少写多
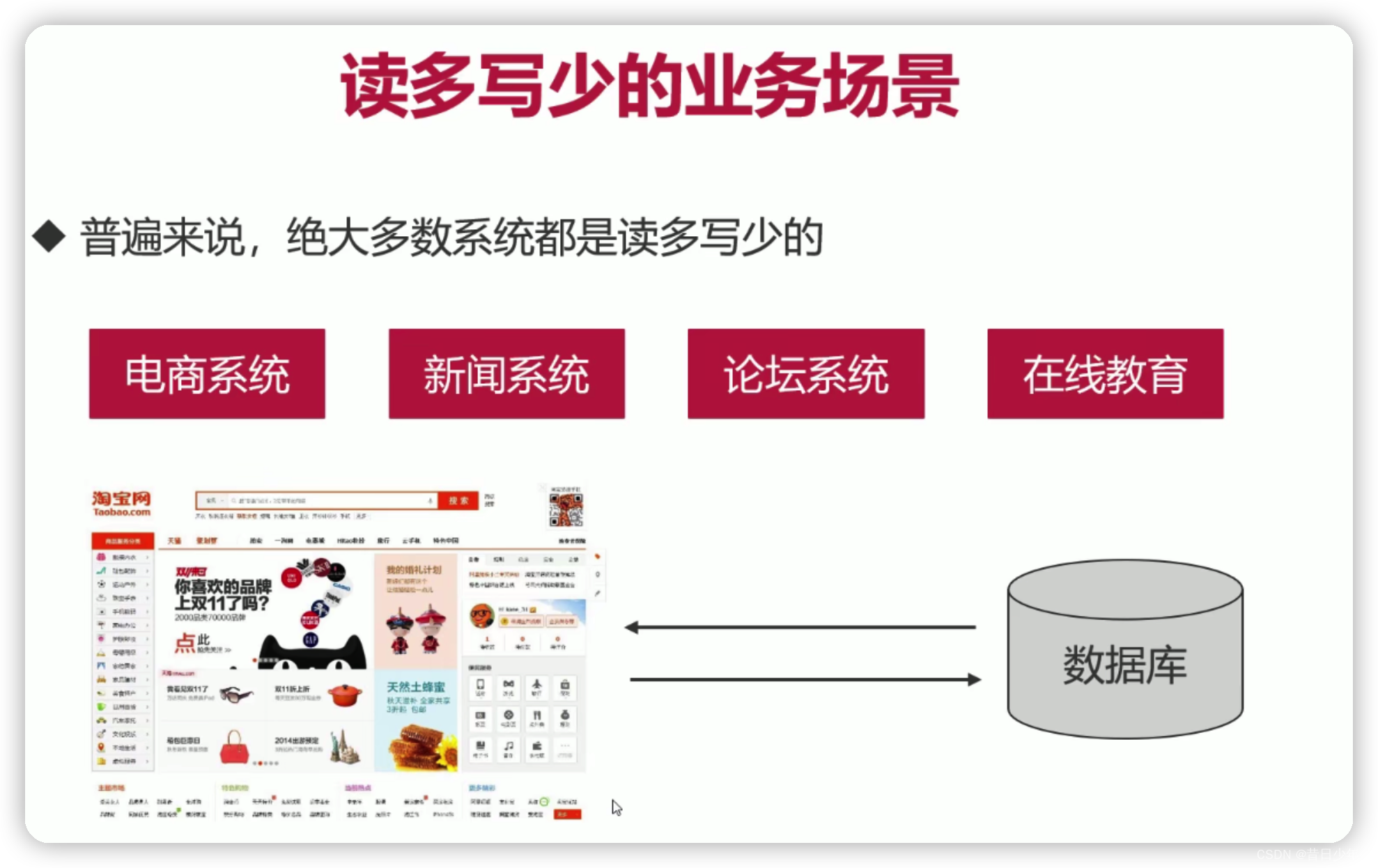
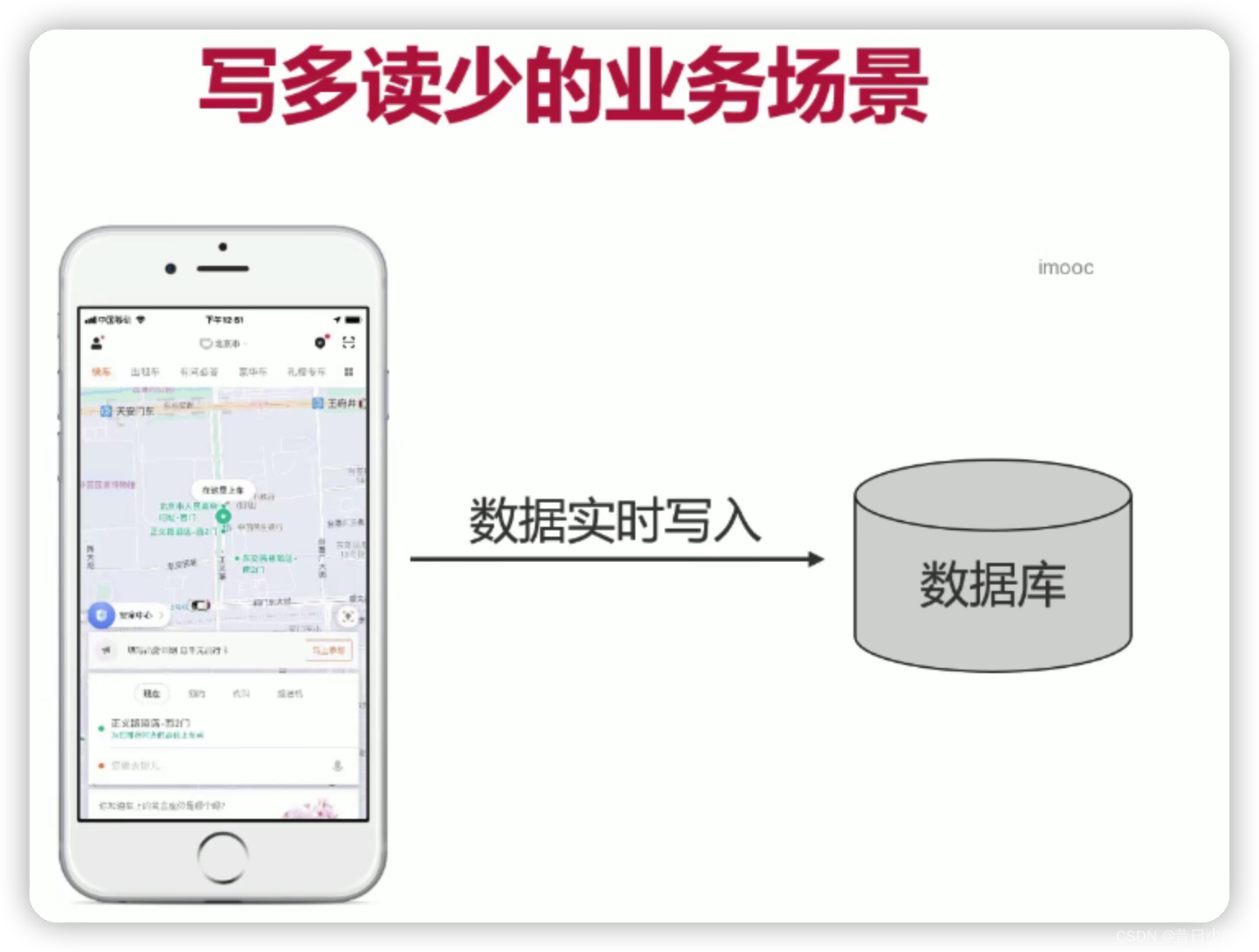
写多读少的解决方案
1.如果是
低价值的数据
,可以采用
NoSQL
数据库来存储这些数据
2.如果是
高价值的数据
,可以用
TokuDB
来保存,TokuDB写入速度是InnoDB的9~20倍
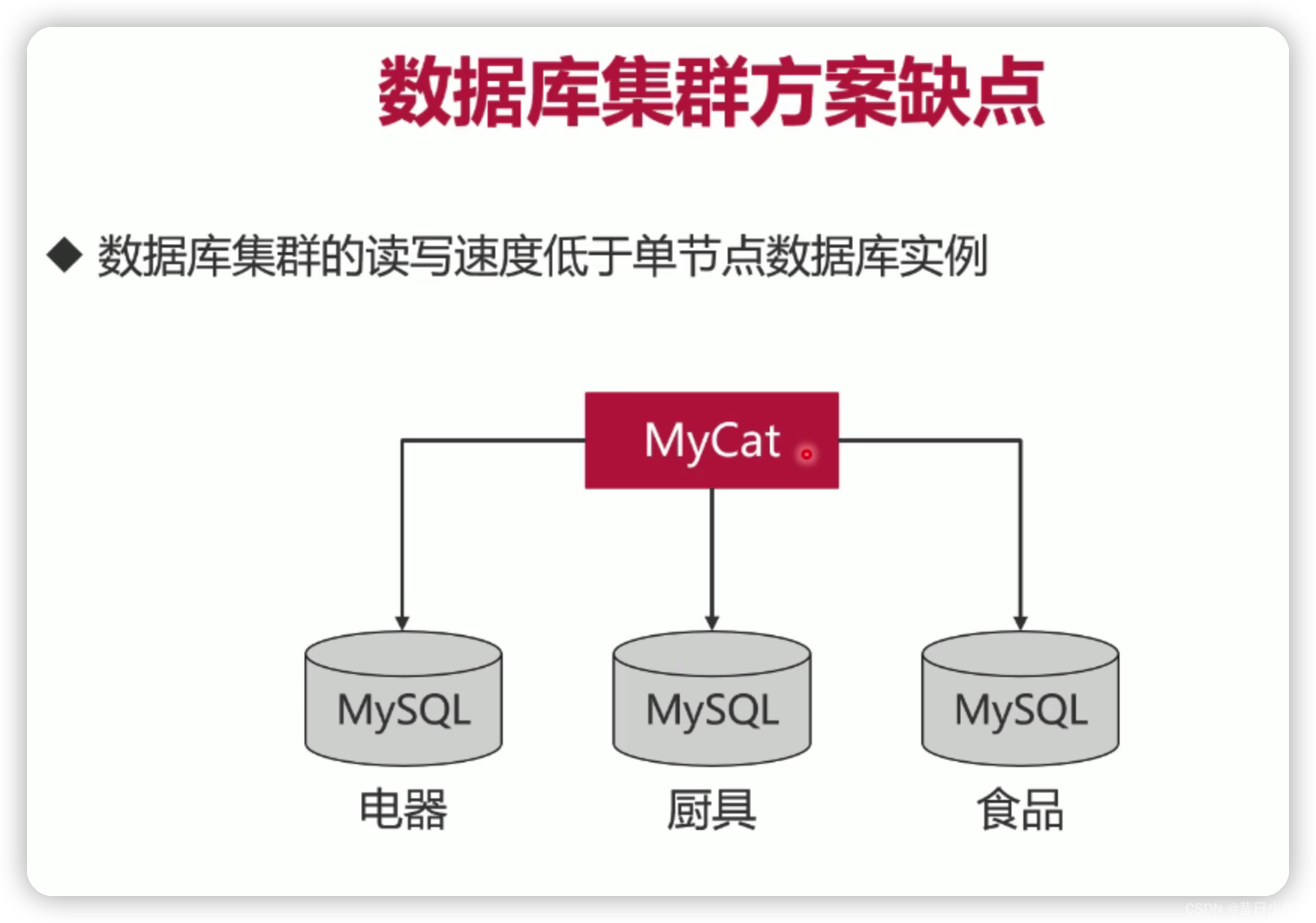
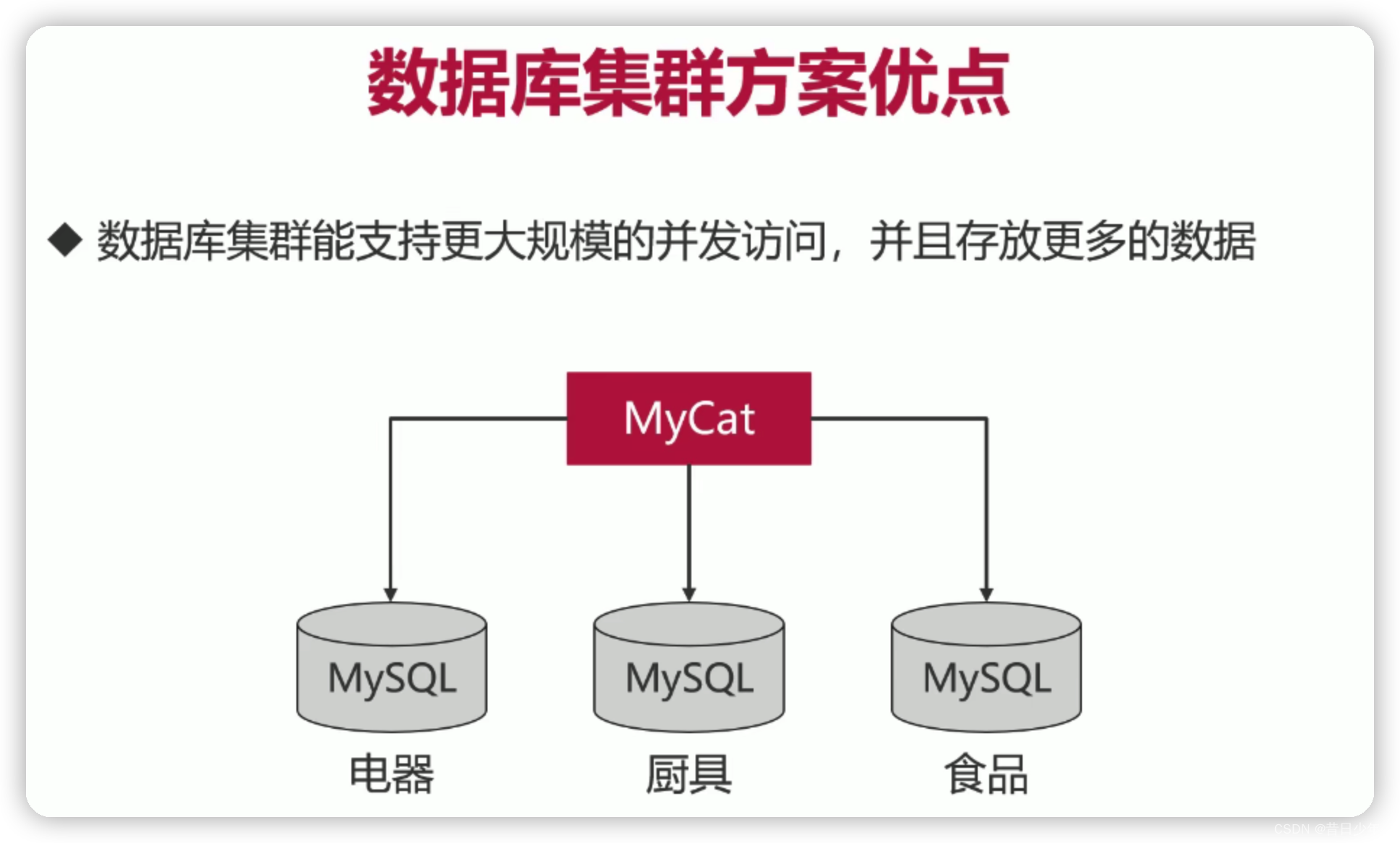
删改数据如何避免锁表?
1.InnoDB采用的是行级锁,删改数据的时候,MySQL会锁住记录。
共享锁
1.只有serializable事务隔离级别,才会给数据读取添加共享锁
SELECT ..... FROM .....LOCK IN SHARE MODE;
2.添加了共享锁,其它事务只能读取加锁数据,而不能修改和删除。
排它锁
1.MySQL默认会给添加、修改和删除记录,设置排它锁
SELECT ... FROM ....FOR UPDATE;
2.排它锁不允许对数据再添加其它锁
如何减少并发操作的锁冲突
1.把复杂的SQL语句拆分成多条简单的SQL语句
如何实现商品秒杀
超售
:卖出了超过预期数量的商品
怎么预防数据库超售现象?
方案1
设置数据库事务的隔离级别Serializable (性能太低)

方案2
在数据表上设置乐观锁字段
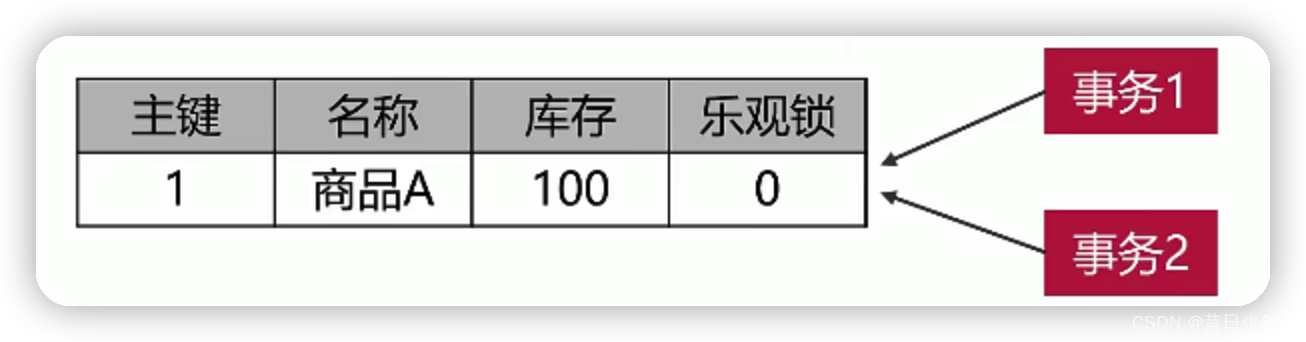
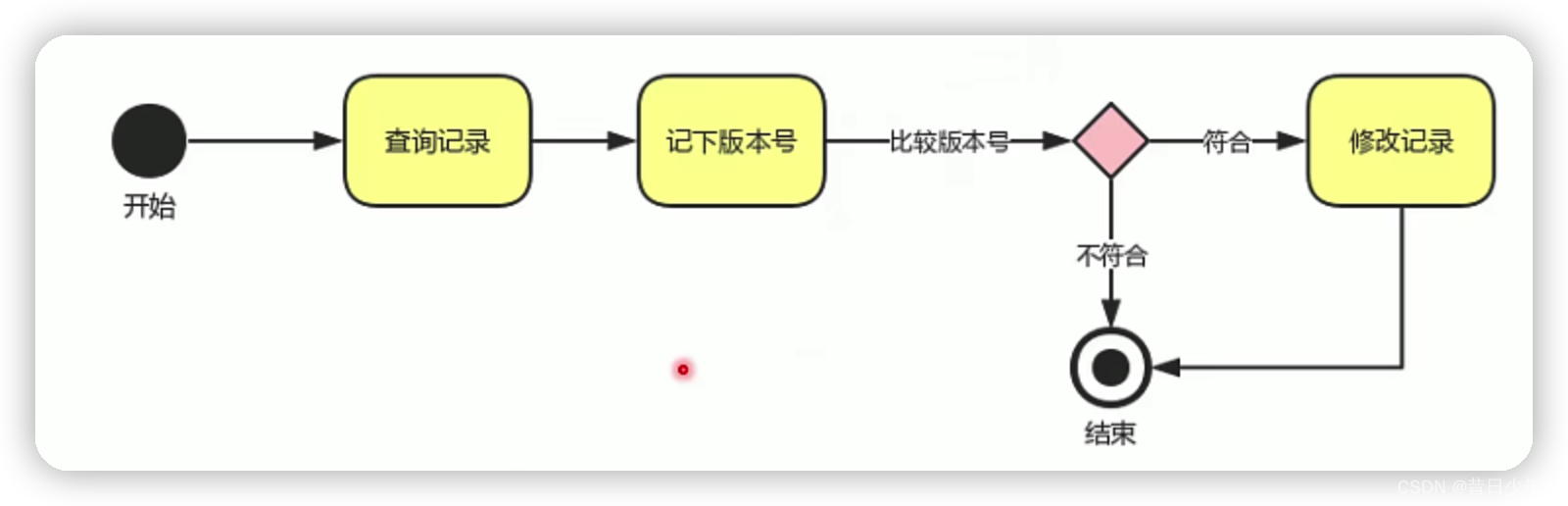
什么表需要设置乐观锁?
1.出现同时修改同一条记录的业务,相应的数据表要设置乐观锁,如:库存表
2.不会出现同时修改统一记录的数据表,就不需要设置乐观锁,如:用户表、商品表、订单表、地址表
方案3
利用Redis防止超售
1.redis特点
(1).Redis是开源免费的Nosql数据库产品,它使用内存缓存数据
(2).Redis的读写性能2万/秒,Mysql读性能5千/秒,写入3千/秒
(3)Redis是单线程的NoSQL数据库,但是采用的是
非阻塞执行
Redis使用不当,也会导致超售现象,因为Redis的单线程是非阻塞执行的,所以并发修改数据容易产生超售现象
如何避免Redis超售现象呢?
Redis引入了事务机制(批处理),一次性把多条命令传给Redis执行,这就避免了其它客户段中间插队从而导致超售。
Redis事务机制
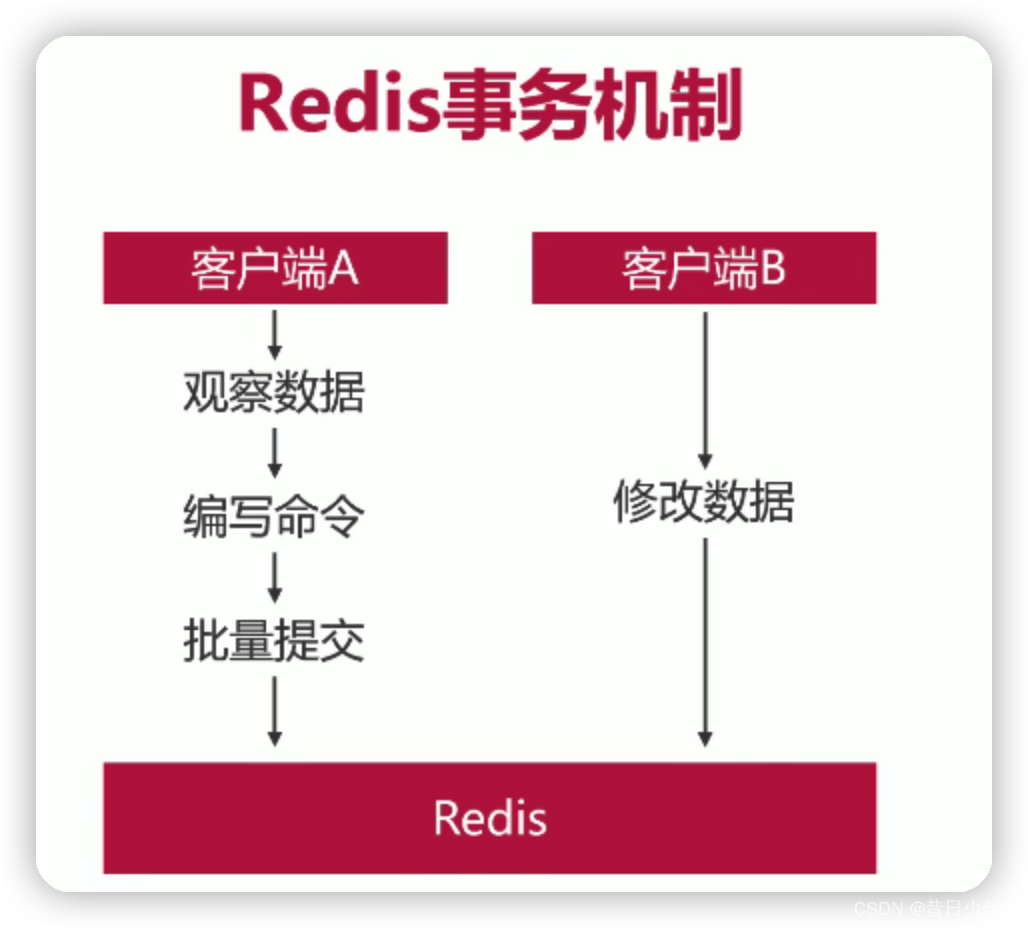
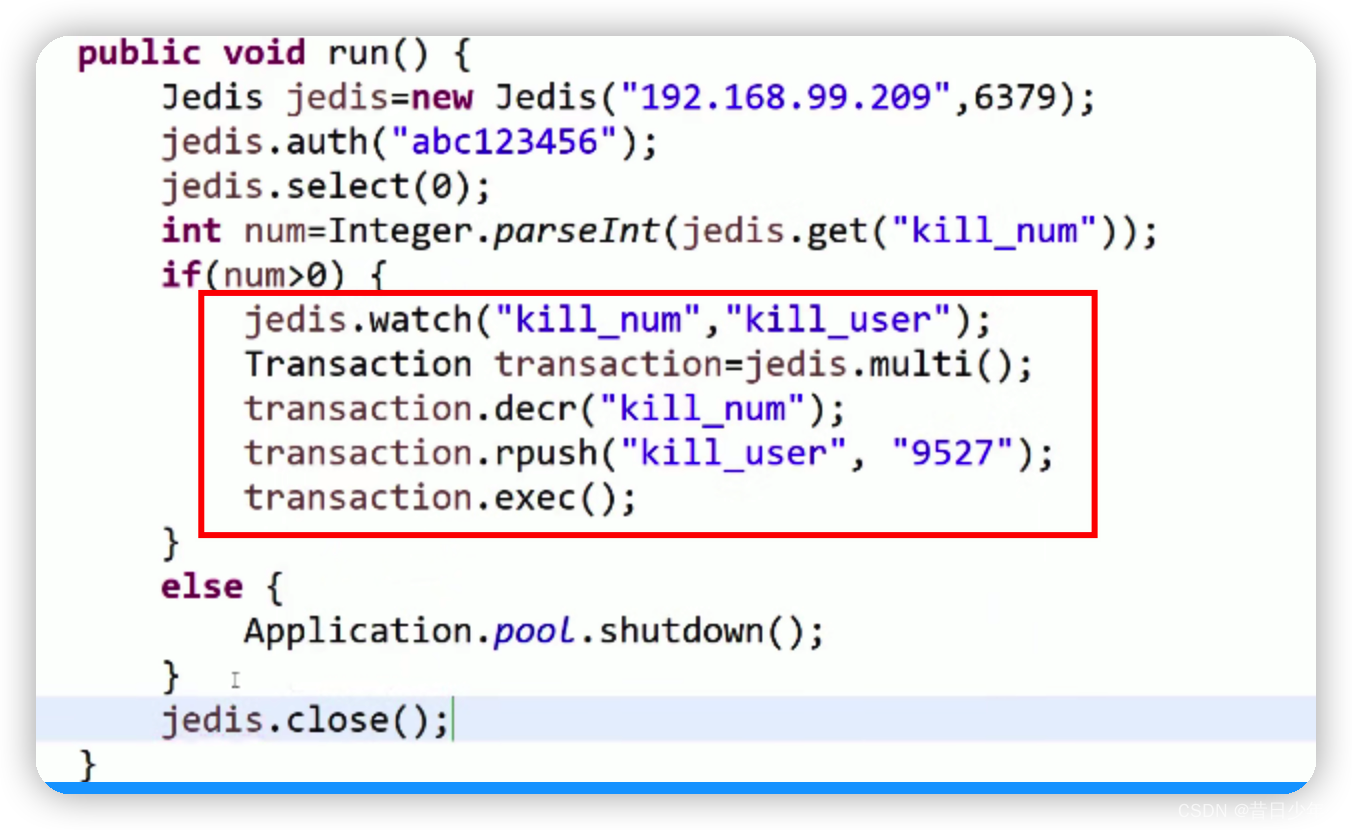
1.如何保证事务一致性
为了保证事务的一致性,在开启事务之前必须要用WATCH命令监视要操作的记录
# kill_num表示库存,kill_user表示秒杀成功的用户
redis > Watch kill_num kill_user
如何开启事务?
利用MULTI命令可以开启事务
redis > MULTI
开启事务后的所有操作都不会立即执行,只有执行EXEC命令的时候才会
批处理执行
redis > DECR kill_num
redis > RPUSH kill_user 9502
redis > EXEC
java代码实现:
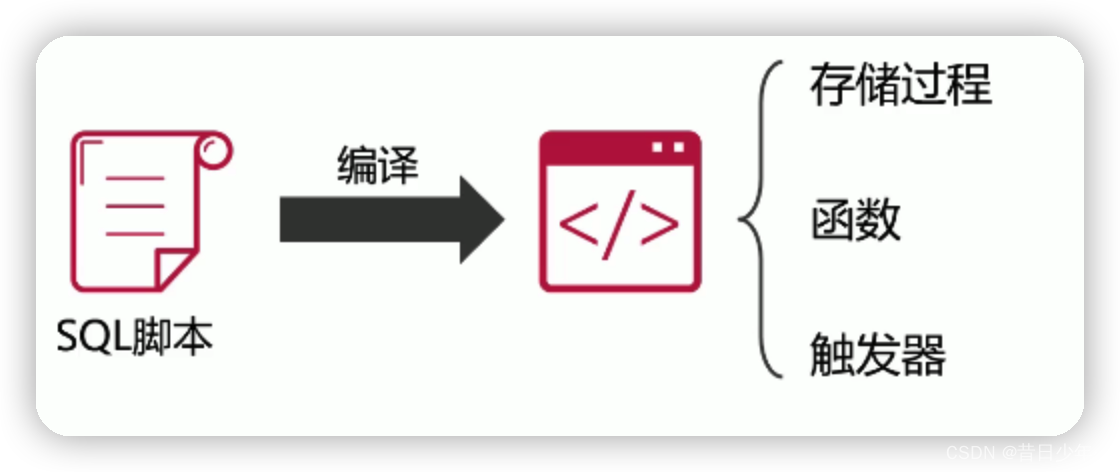
什么是存储过程?
存储过程是一个编译后的SQL脚本集合,可以单独调用,但是不能用在SQL语句中。
数据库编程:
存储过程的优点:
1.存储过程是编译过的SQL脚本,所以执行的速度非常快;
2.实现了SQL编程,可以降低锁表的时间和锁表的范围;
3.对外封装了表结构,提升了数据库的安全性;
具体案例可以参照《MYSQL数据库开发与管理实战》
什么是函数
存储函数可以理解为小粒度的存储过程,可以用在SQL语句中。存储函数通常用来封装一个公式或者一个业务规则,以便在SQL语句或者存储程序中复用。
1.创建存储函数
DELIMITER $$
CREATE FUNCTION func_name(
param_1,
param_2,...
)
RETURNS datatype
[NOT] DETERMINISTIC
BEGIN
...
END $$
DELIMITER;
什么是触发器?
MySQL中数据插入、更新、删除动作都属于一个事件,有时会希望在此类事件发生之后能够自动执行一段自定义的处理逻辑,这种需求救可以通过使用触发器来实现。触发器的操作主要包括触发器的创建、查看、删除。
为什么放弃存储过程、触发器和自定义函数
在数据库集群场景里,因为存储过程、触发器和自定义函数,都是在本地数据库执行,所以无法兼容集群场景。
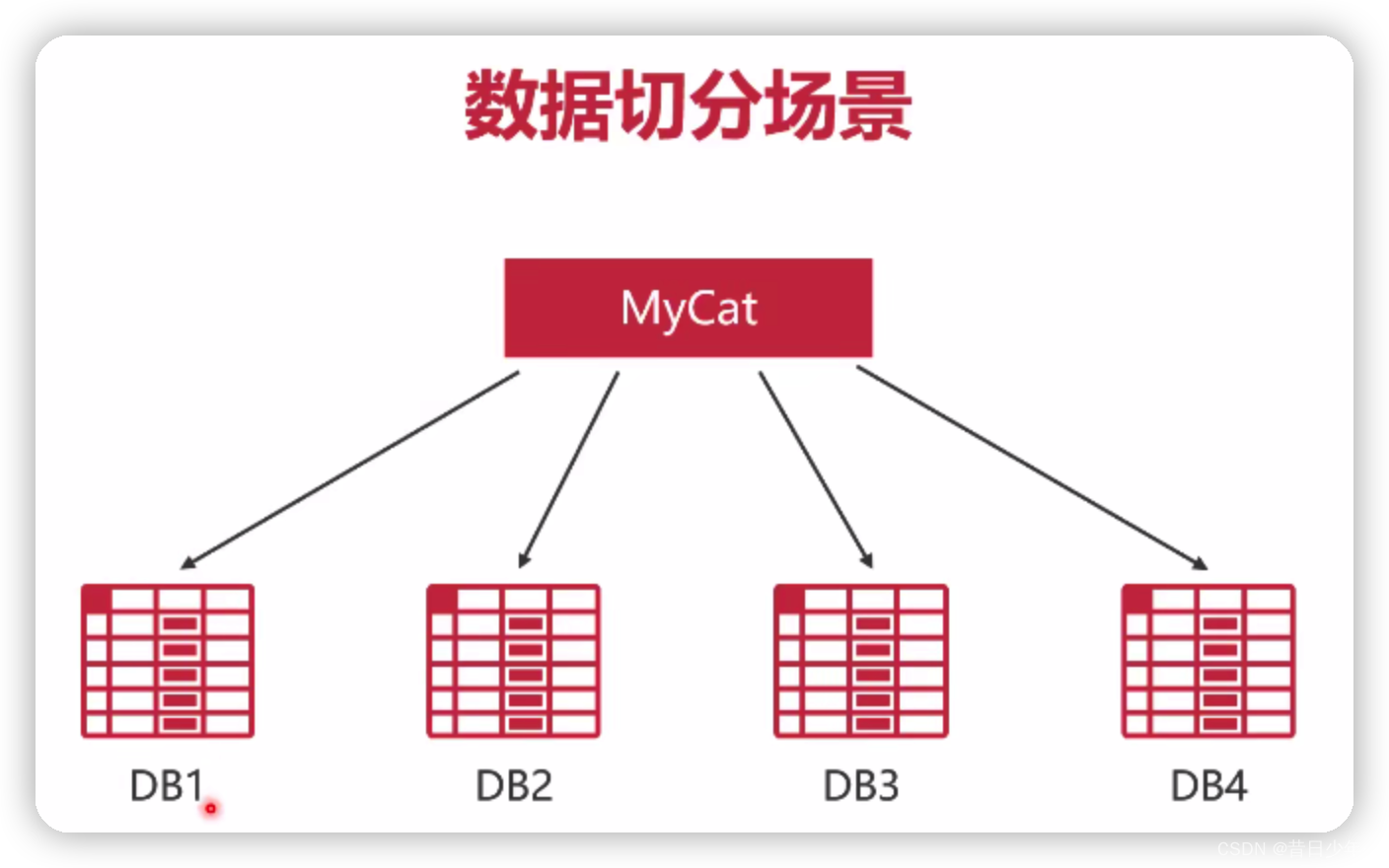
如何避免偷换交易中的商品信息?
1.B2B电商平台,通常采用保存历次商品修改信息、降低搜索排名;
2.B2C电商平台,只需要保存历次商品修改信息即可;
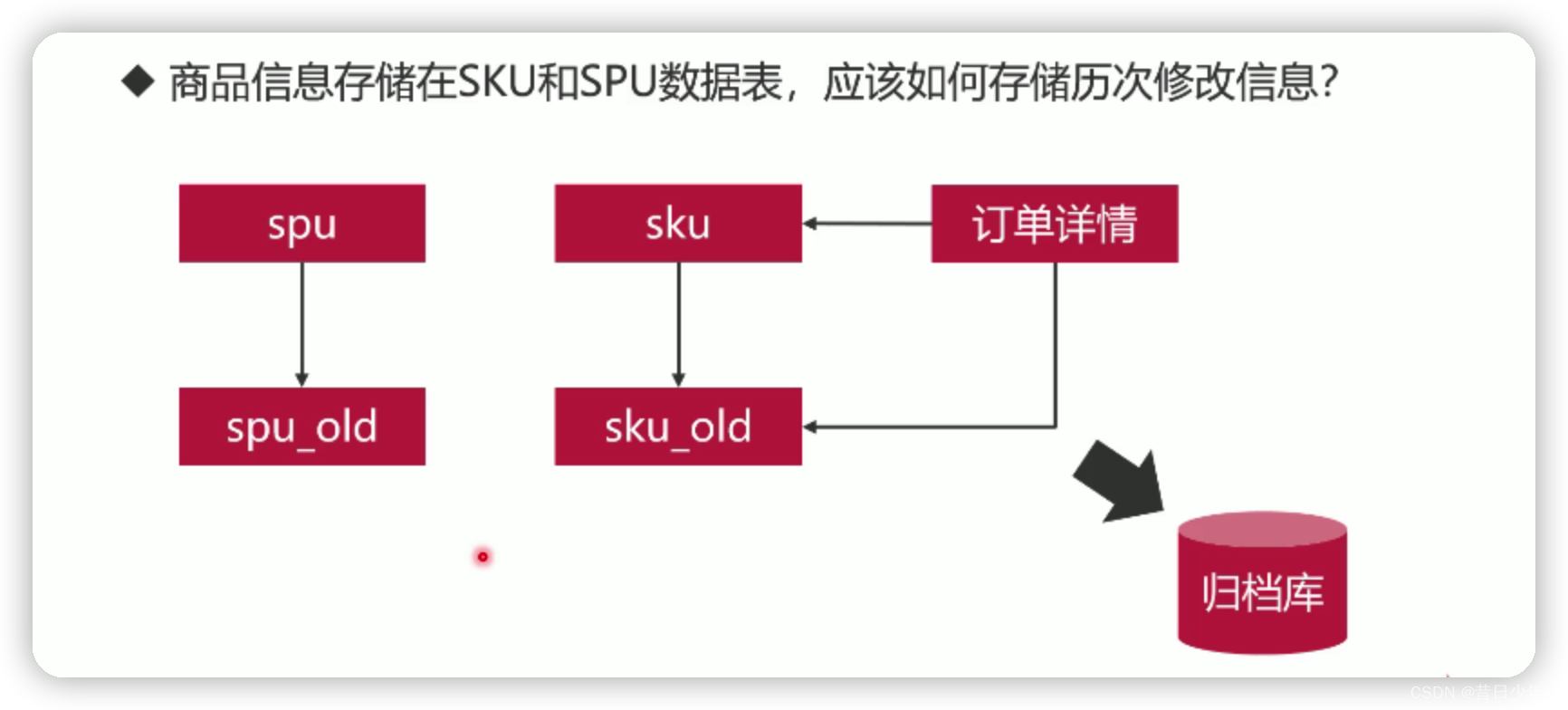
如何抵御XSS攻击?
1.XSS(跨站脚本)攻击,是让浏览器渲染DOM的时候意外的执行了恶意JS代码
2.XSS攻击的原理是在网页中嵌入一个恶意脚本
<img src="null" onerror='alert(document.cookie)'/>

<p>{{content}}</p>
3.解决办法:
AntiSamy
是开源的java类库,可以用来过滤XSS恶意代码
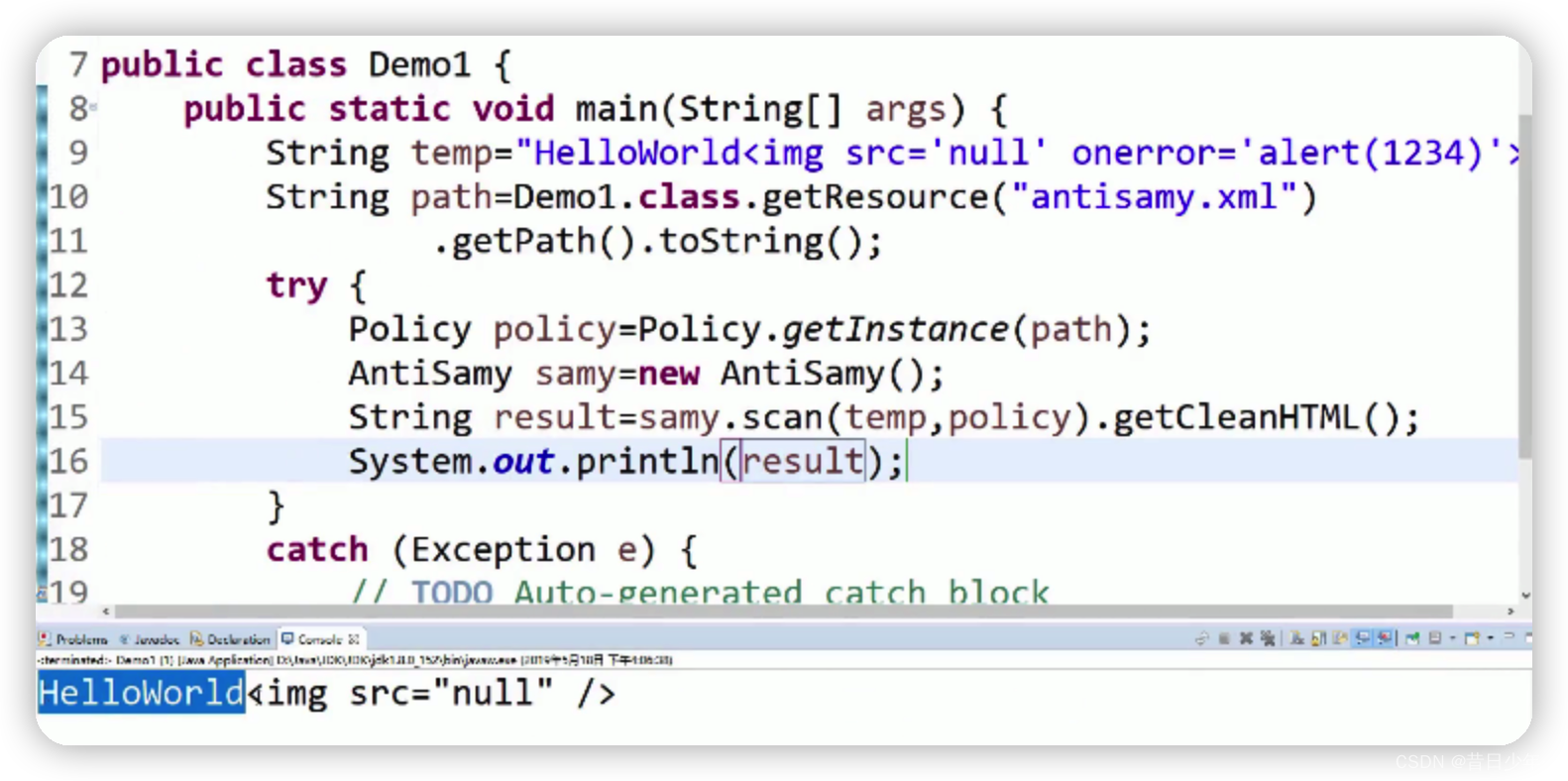
数据库缓存、程序缓存应该选择哪个?
数据库性能:
1.MySQL每秒可以处理5000次读取,或者3000次写入;
2.响应时间通常在10ms以内,但是在1万并发的时候,要保证10ms以内的响应速度,任何数据库都做不到;
数据库缓存:
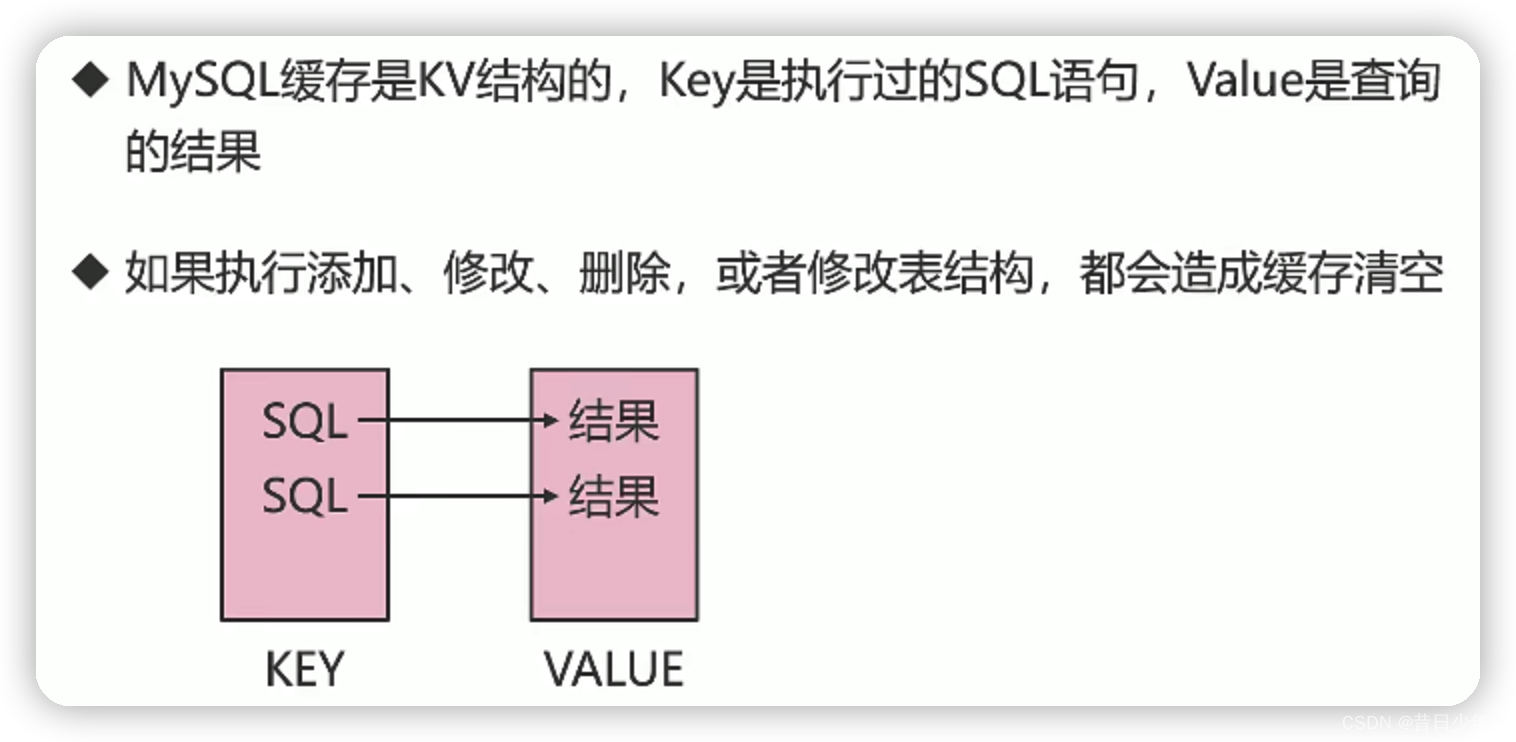
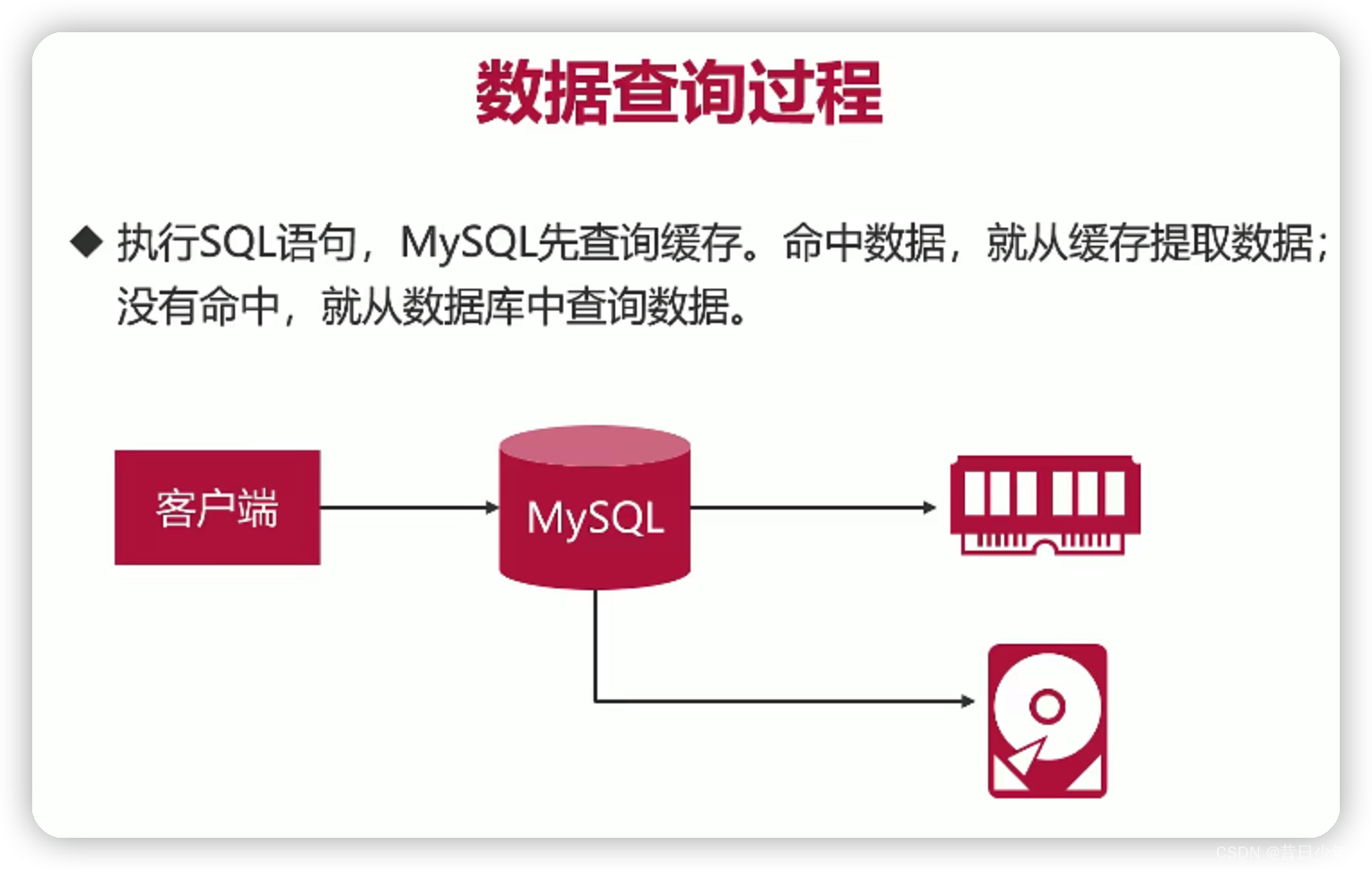
数据库缓存注意事项
1.所有对数据加锁的事务中,不会使用查询缓存;
2.查询语句必须一模一样,才有机会命中缓存;
那么该不该使用数据库缓存呢?
1.MySQL8.0去除了查询缓存,Oracle官方也不推荐使用查询缓存;
SHOW VARIABLES LIKE '%query_cache%';
2.当MySQL缓存了很多结果的时候,一条更新语句就会让缓存全部作废,这严重的加重了内存管理的负担;
程序缓存的优势
Redis、Memcached这些缓存产品,结合Spring框架,在程序中可以细颗粒度的,设置哪些查询需要缓存,哪些查询不需要缓存。
SpringCache技术
1.方法声明加上了@Cacheable注解,该方法执行的时候,Spring先查找缓存,根据命中的情况决定返回缓存,还是查询数据库
@Cacheable("Cache1")
public User get(Long id){
//执行查询
//返回的结果会被缓存
return User对象;
}
2.给方法声明加上@CacheEvict, Spring 执行完数据库操作后,删除缓存记录
@CacheEvict(value="Cache1")
public void delete(Long id){
//执行删除操作
}
就近发货的实现
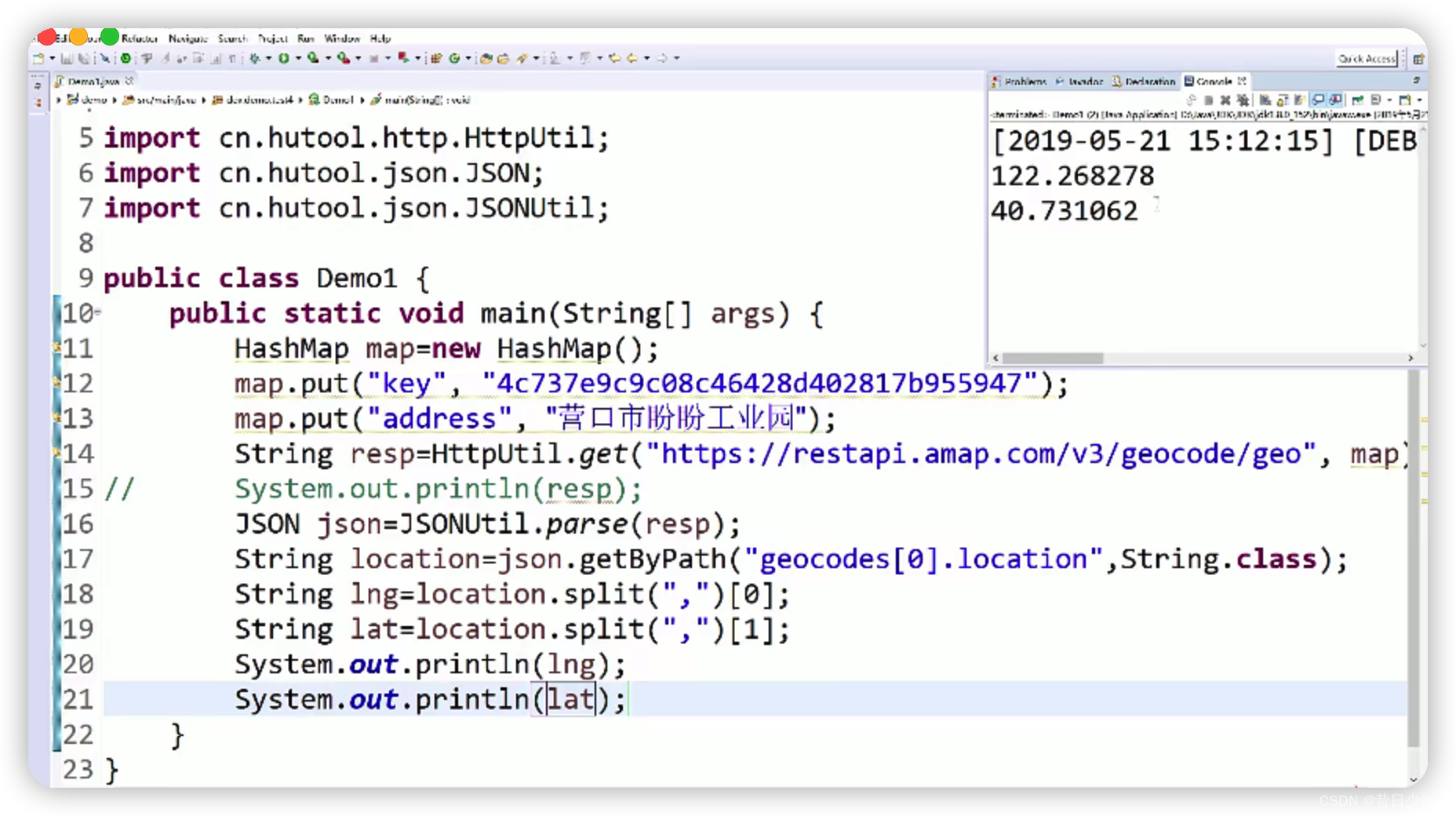
java中一个很好用的工具:
Hutool
1.Hutool是java里面工具集合的一个依赖包,可以使用它的网络类,发送请求,查询地理坐标;
2.通过高德地图API,获取地理位置的经纬度;
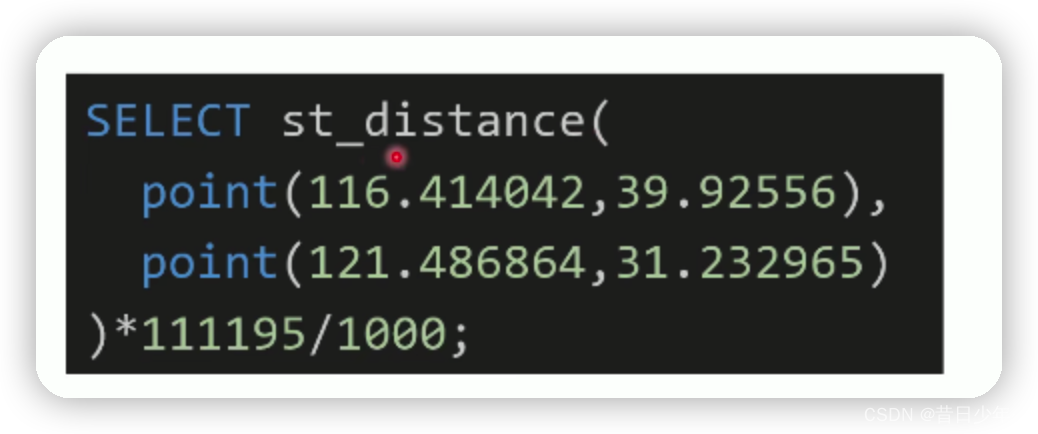
3.利用MySQL计算两点之间的距离
st_distance函数
可以计算两个坐标之间相差的度数
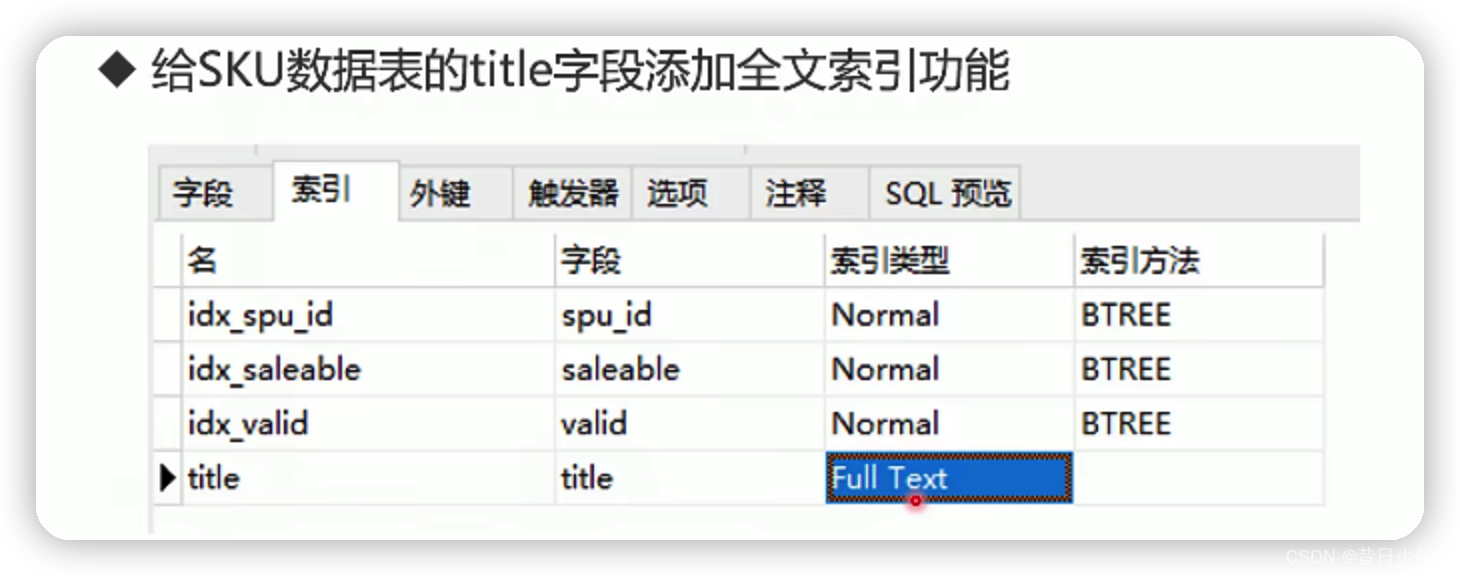
中文分词技术
MySQL的全文索引(不推荐)
1.MySQL的全文检索功能,既支持英文也支持中文;
2.MySQL全文检索对英文支持很好,但是对中文支持的不好。不能按照语义切词,只能按照字符切词;
3.创建全文索引
4.执行全文索引查询
全文检索的条件写在WHERE子句中
SELECT id,title,images,price
FROM t_sku
WHERE MATCH(title) AGAINST("小米9")
5.全文索引的弊病
1.中文字段创建全文索引,切词结果太多,占用大量存储空间;
2.更新字段内容,全文索引不会更新,必须定期手动维护;
3.在数据库集群中维护全文索引难度很大;
使用专业的全文检索引擎
1.
Lucene
是Apache基金会的开源全文检索引擎,支持中文分词;
2.Lucene自带的中文分词插件功能较弱,需要引入第三方中文分词插件,对中文内容准确分词;
3.引入
hanlp
第三方中文分词插件
第三方中文分词插件
创建Lucene索引
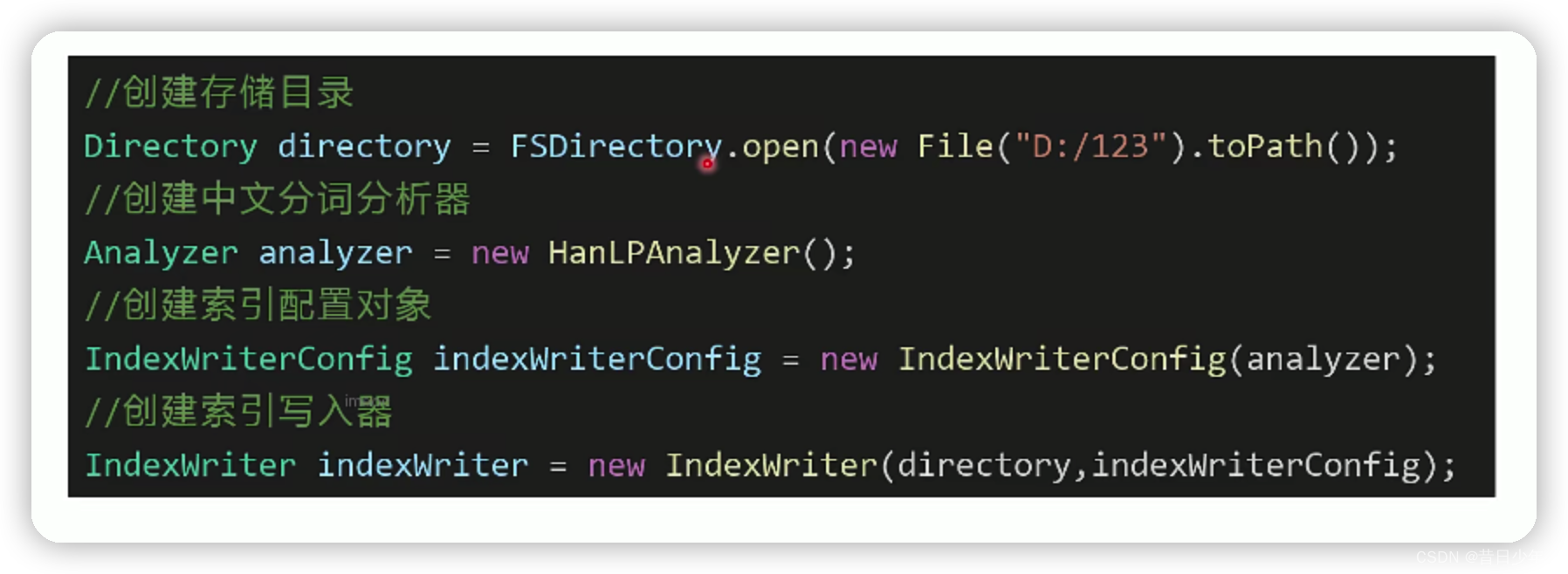
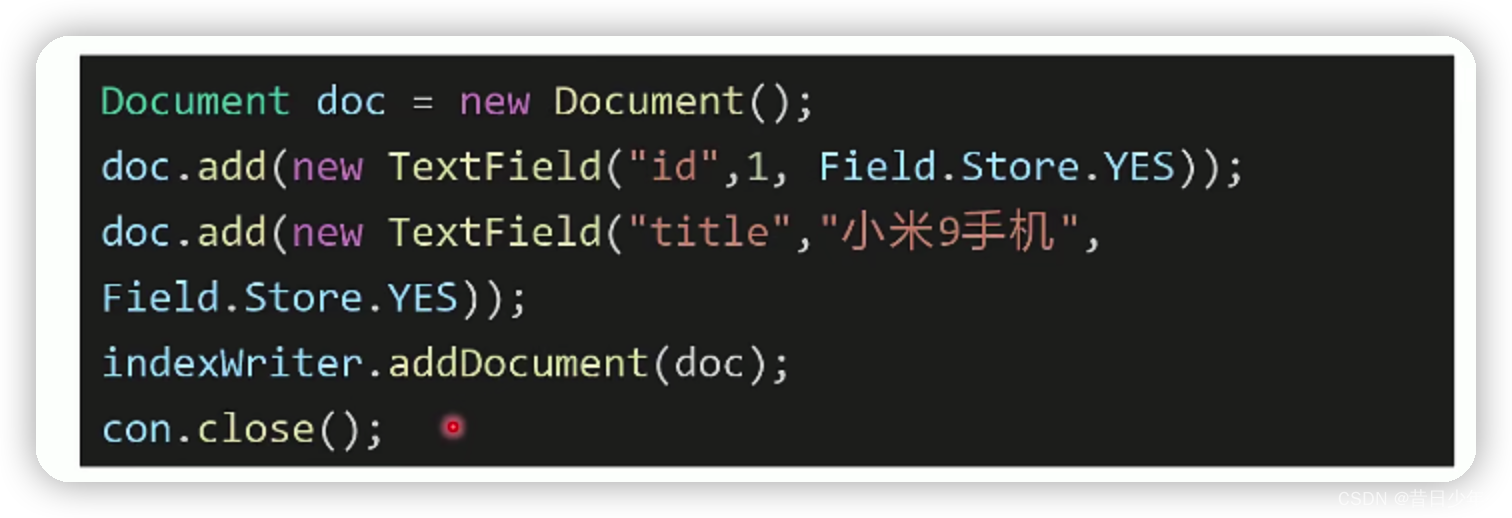
从数据库查询数据,将每条数据封装成Document对象,存放到Lucene里
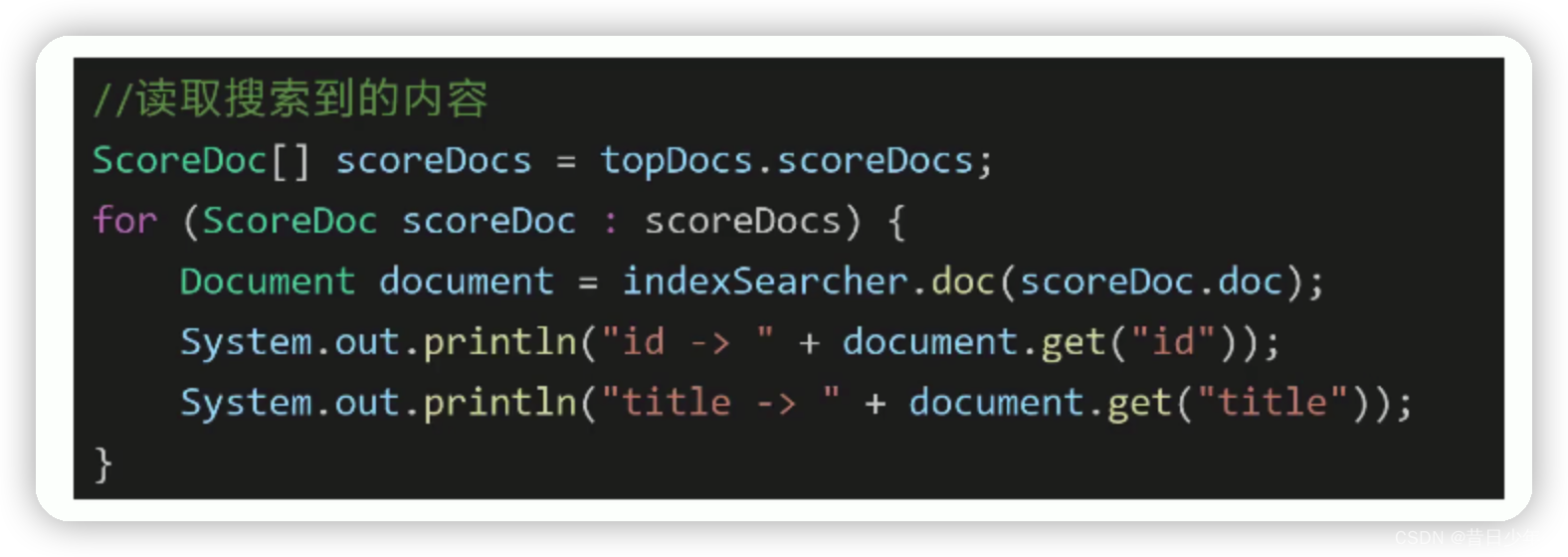
全文检索


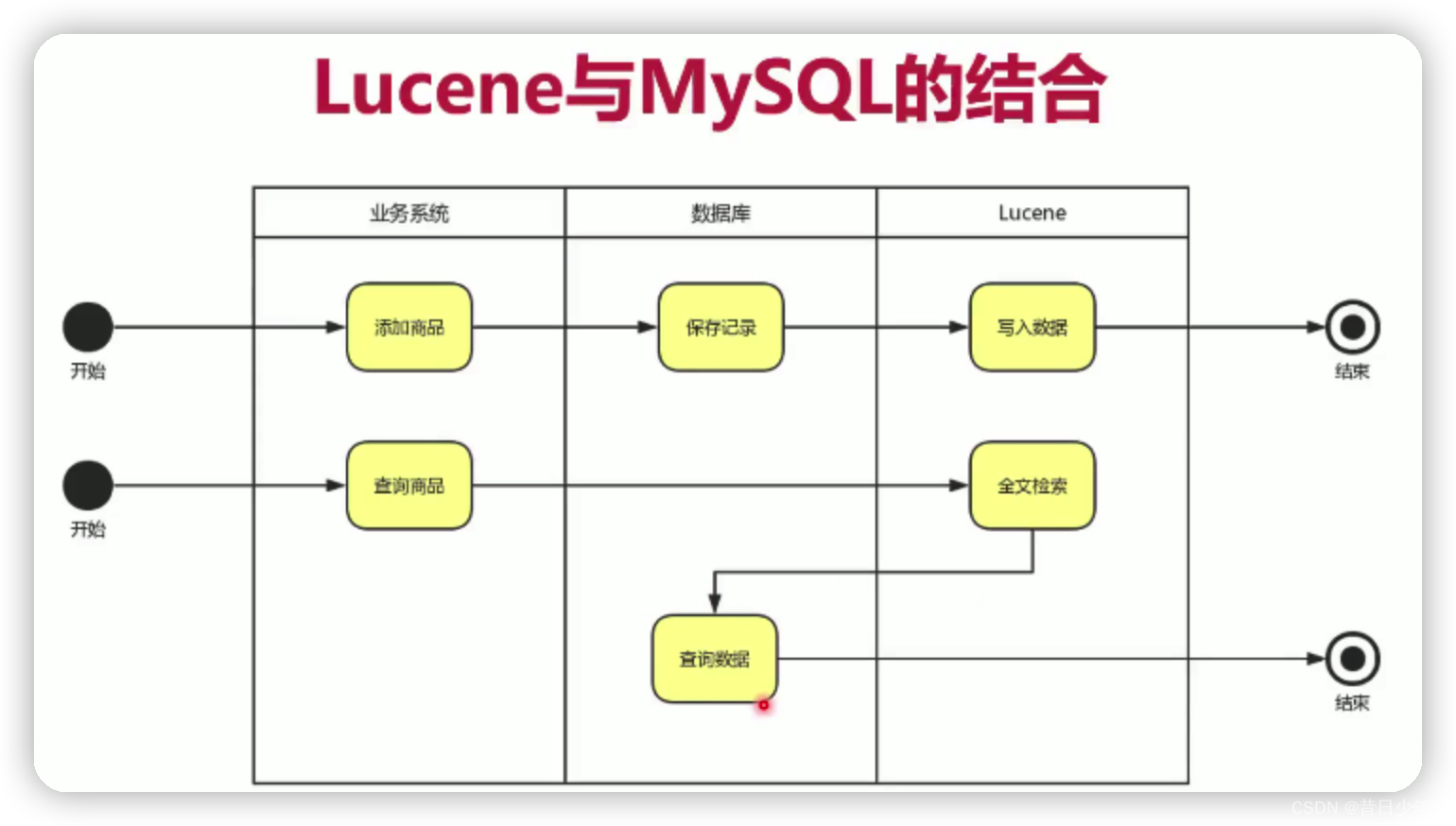
Lucene注意事项
1.不是所有数据表的记录,都要保存到Lucene上面。
只对需要全文检索的字段
(数据库部分字段)使用Lucene即可;
新零售系统数据库性能调优
MySQL压力测试
什么是压力测试
压力测试是针对系统的一种性能测试,但是测试数据与业务逻辑无关,更加简单直接的测试读写性能;
压力测试的指标
QPS:每秒钟处理完请求的次数
TPS: 每秒钟处理完的事务次数
响应时间:一次请求所需要的平均处理时间
并发量:系统能同时处理的请求数
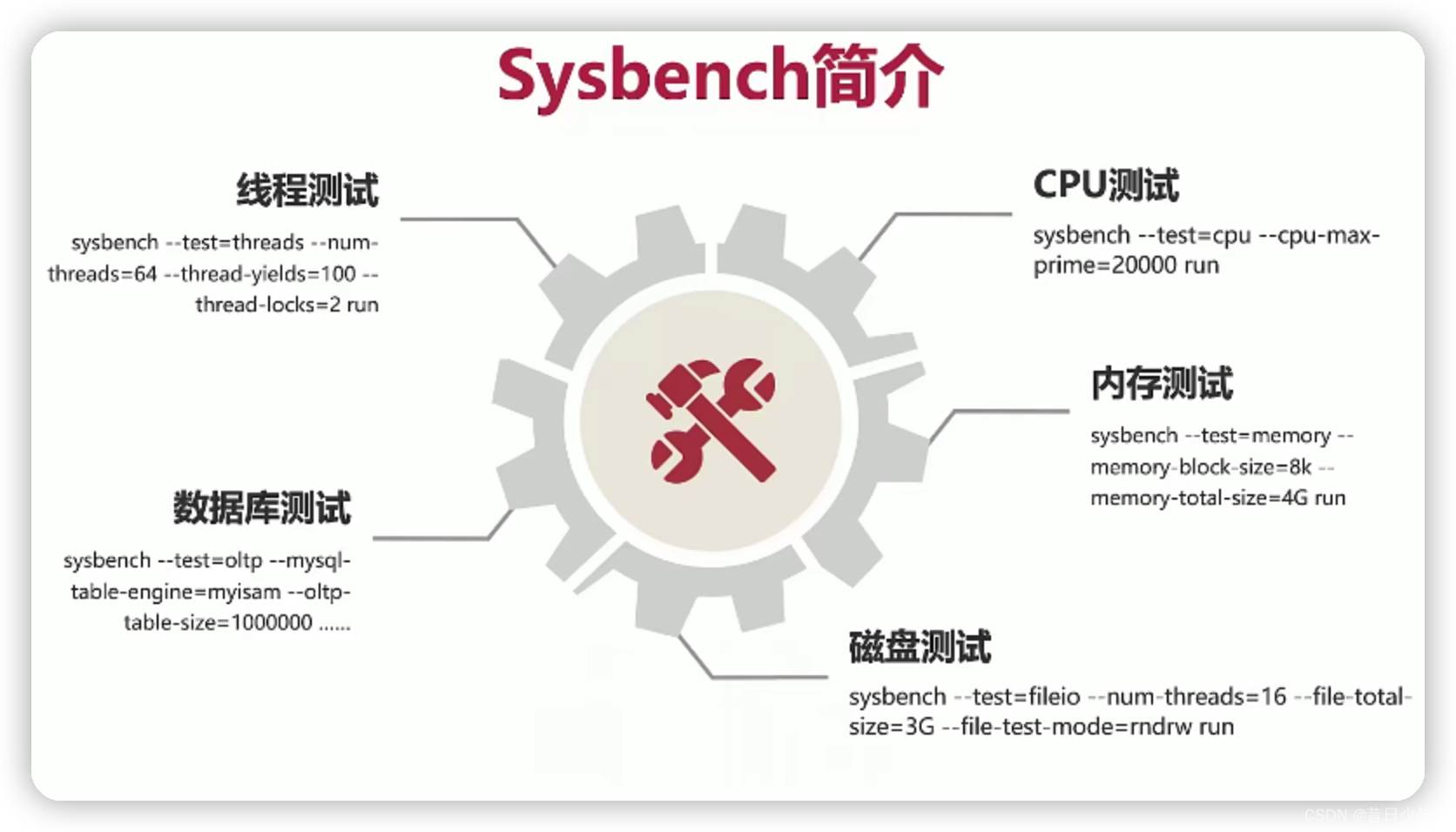
压力测试工具
1.Mysqlslap
2.Sysbench(推荐)
3.Jmeter
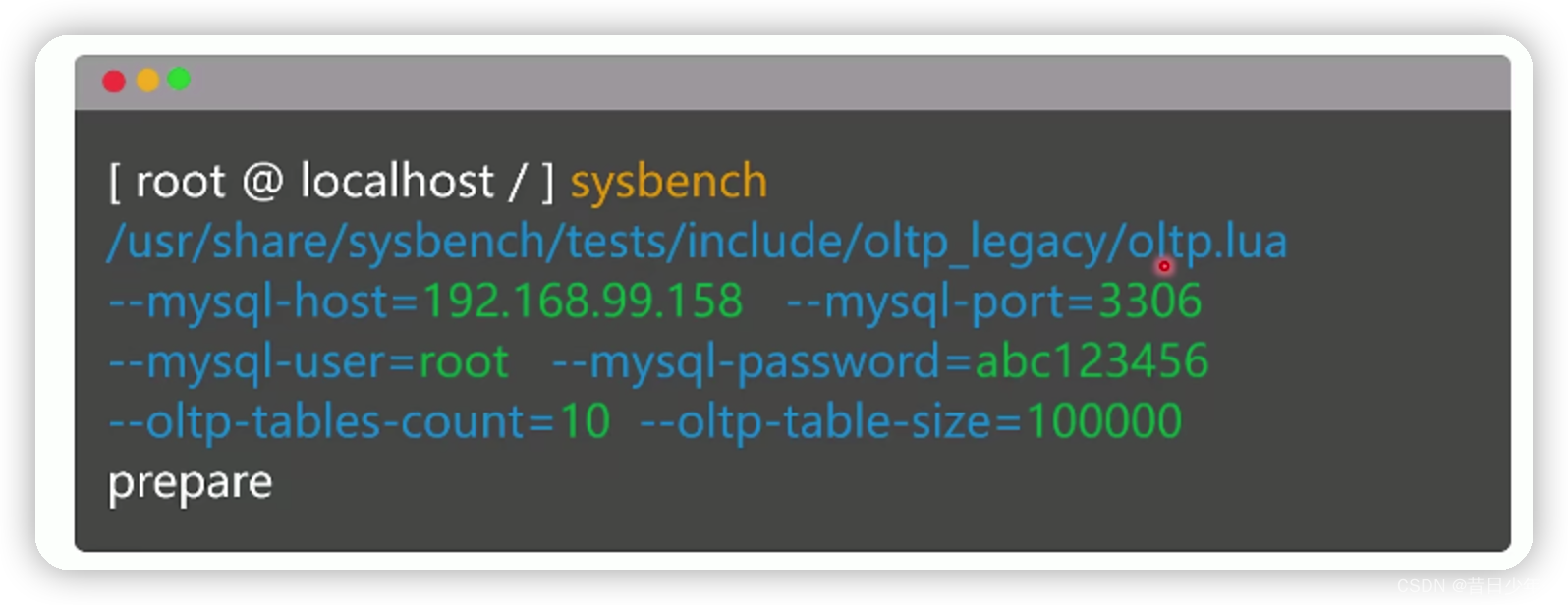
1.准备测试数据
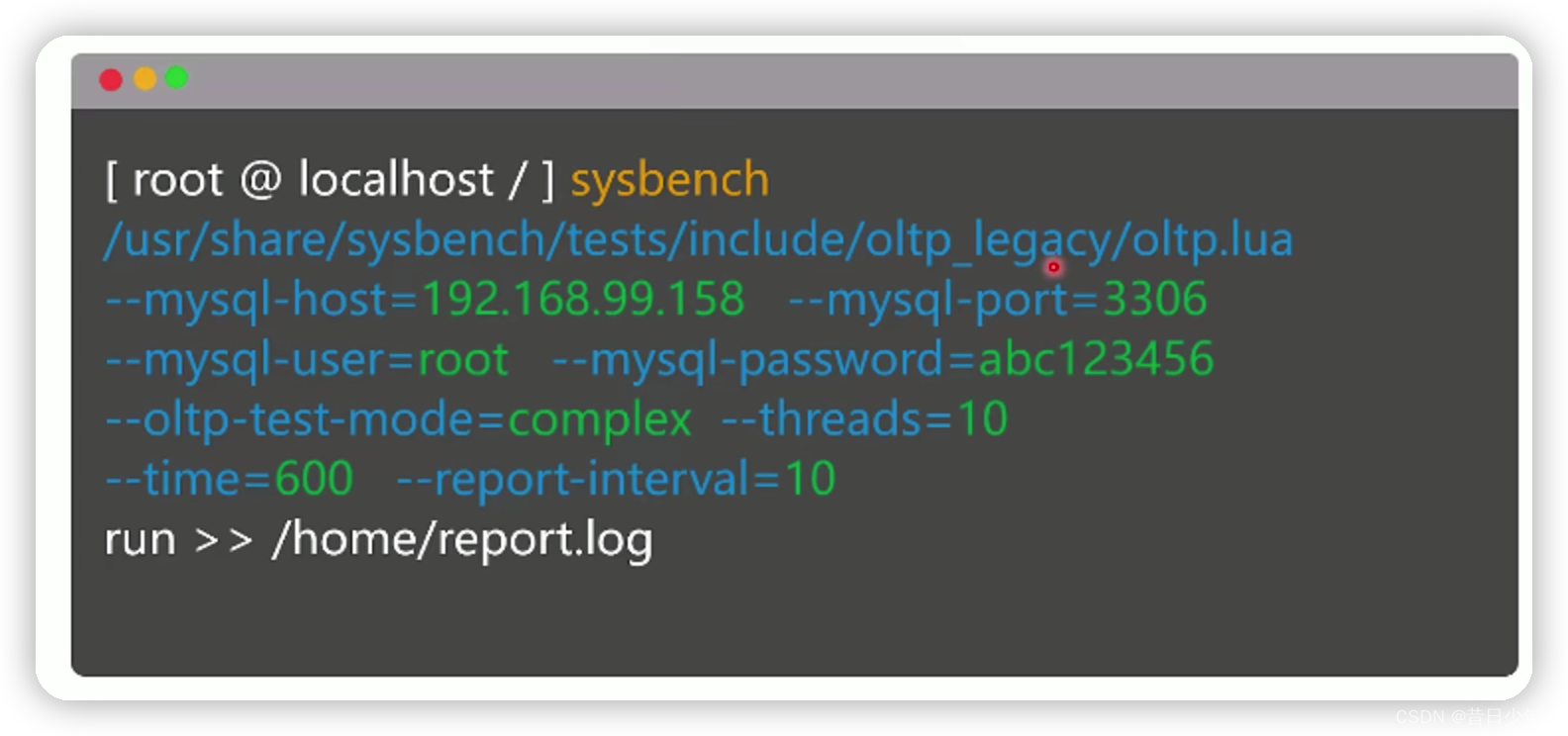
2.执行测试
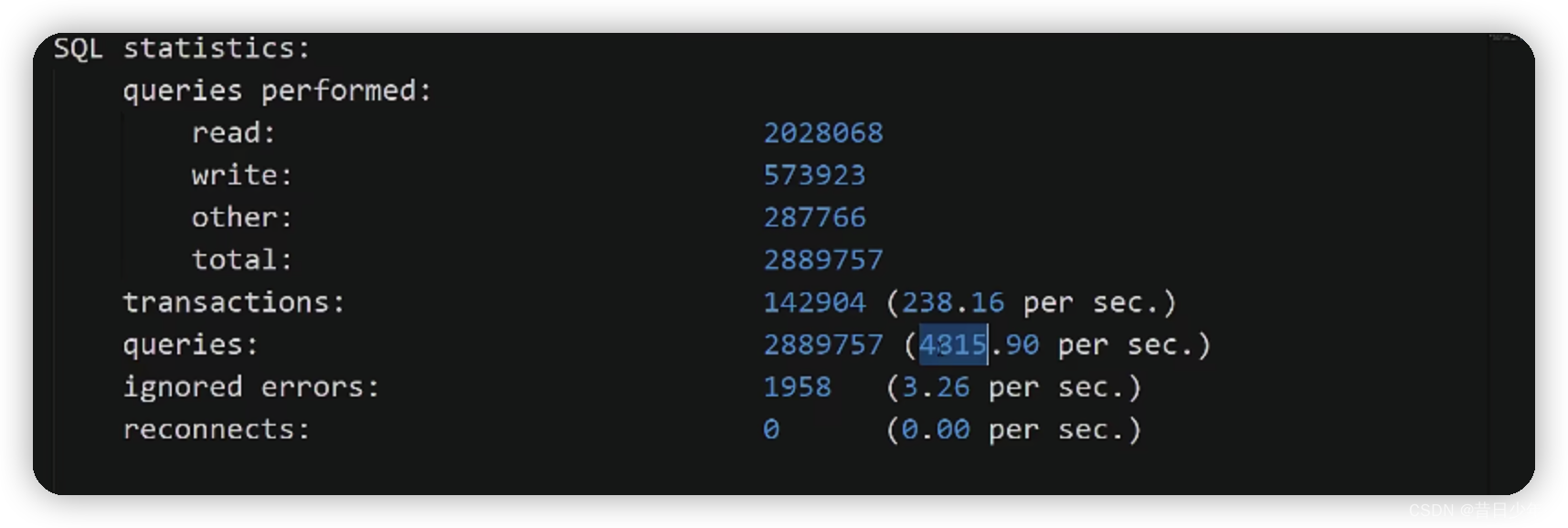
3.测试报告
SQL语句的优化
1.不要把SELECT子句子写成SELECT *, 这样查询所有字段
SELECT * FROM t_emp;
2.谨慎使用模糊查询
//会执行全表扫描
SELECT ename FROM t_emp WHERE ename LIKE '%S%';
//优化
SELECT ename FROM t_emp WHERE ename LIKE 'S%';
3.对ORDER BY排序的字段设置索引
SELECT ename FROM t_emp ORDER BY deptno;
4.少用IS NULL 和 IS NOT NULL
SELECT ename FROM t_emp WHERE comm IS NULL;
//优化
SELECT ename FROM t_emp WHERE comm = -1;
SELECT ename FROM t_emp WHERE comm IS NOT NULL;
//优化
SELECT ename FROM t_emp WHERE comm >= 0;
5.尽量少用!=运算符
SELECT ename FROM t_emp WHERE deptno != 20;
//优化
SELECT ename FROM t_emp WHERE deptno < 20 AND deptno > 20;
6.尽量少用OR运算符
SELECT ename FROM t_emp WHERE deptno = 20 OR deptno = 30;
//优化
SELECT ename FROM t_emp WHERE deptno = 20
UNION ALL
SELECT ename FROM t_emp WHERE deptno = 30;
7.尽量少用IN和NOT IN运算符
SELECT ename FROM t_emp WHERE deptno IN (20,30);
//优化
SELECT ename FROM t_emp WHERE deptno = 20
UNION ALL
SELECT ename FROM t_emp WHERE deptno = 30;
8.避免条件语句中的数据类型转换
SELECT ename FROM t_emp WHERE deptno = '20';
9.在表达式左侧使用运算符和函数都会让索引失效
SELECT ename FROM t_emp WHERE salary*12 >= 100000;
//优化
SELECT ename FROM t_emp WHERE salary >= 100000/12;
SELECT ename FROM t_emp WHERE year(hiredate)>=2000;
//优化
SELECT ename FROM t_emp WHERE hiredate >= '2000-01-01 00:00:00';
MySQL参数优化
1.优化最大连接数
max_connections是MySQL最大并发连接数,默认值是151
MySQL允许的最大连接数上限16384
实际连接数是最大连接数的85%较为合适
show variables like 'max_connections';
show status like 'max_used_connections';
MySQL为每个连接创建缓冲区,所以不应该盲目上调最大连接数;
#消耗约800M内存
max_connections=3000
2.优化请求堆栈
back_log是存放执行请求的堆栈大小,默认值是50;
3.修改连接超时
wait_timeout是超时时间,单位秒
连接默认超时是8小时,连接长期不用又不销毁,浪费资源
#10分钟超时
wait-timeout=600
3.修改InnoDB缓存大小
innodb_buffer_pool_size是InnoDB的缓存容量,默认是128M
InnoDB缓存的大小可以设置为主机内存的70%-80%
MySQL 慢查询日志
1.慢查询日志会把查询耗时超过规定规定时间的SQL语句记录下来
2.利用慢查询日志,定位分析性能的瓶颈
show variables like 'slow_query%';
| Variable_name | Value |
|---|---|
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/localhost-slow.log |
开启慢查询日志
1.slow_query_log可以设置慢查询日志的开闭状态
2.long_query_time可以规定查询超时的时间,单位是秒
slow_query_log = ON
long_query_time = 1
分析SQL语句
EXPLAIN …
第9章 新零售平台的数据库集群
单节点和集群哪个读写更快?
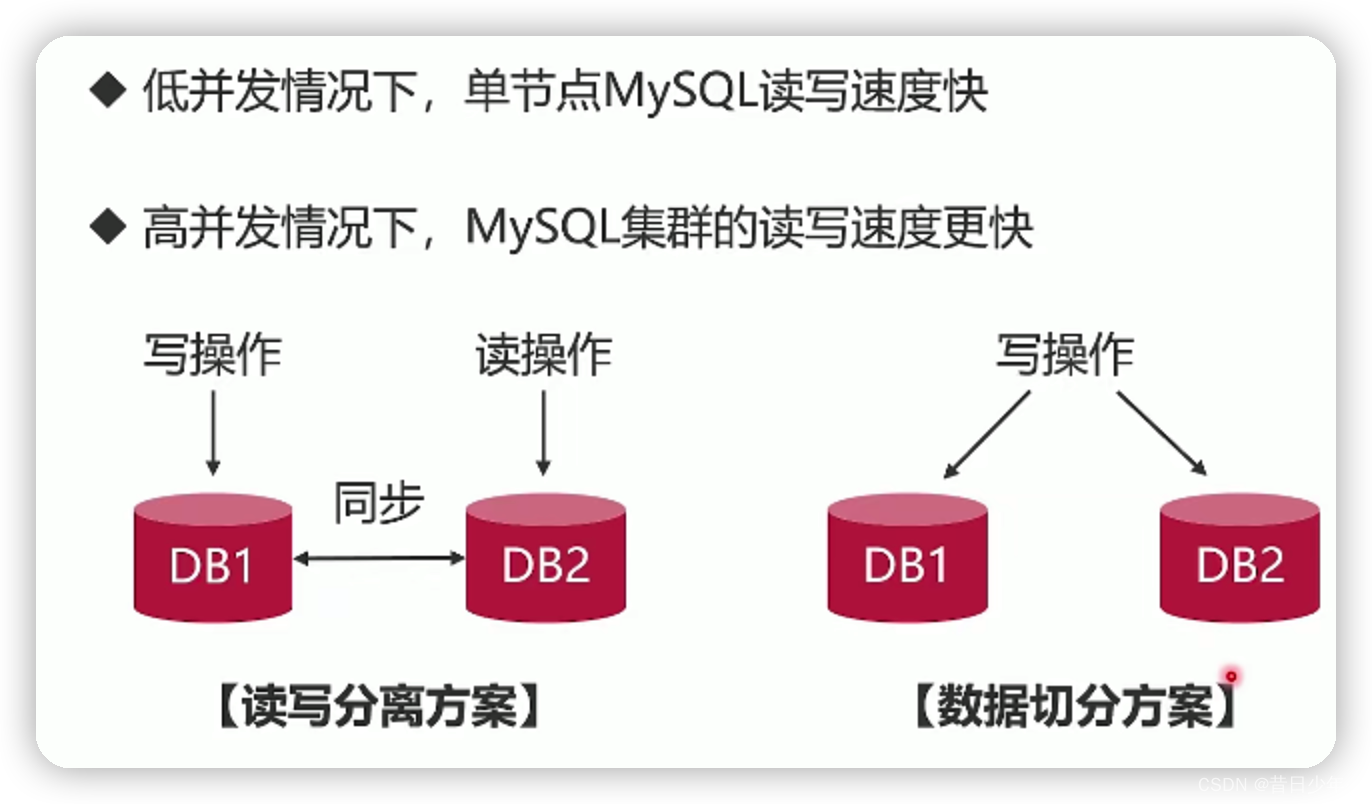
单节点数据库的弊病
1.大型互联网程序用户群里庞大,所以架构必须要特殊设计;
2.单节点的数据库无法满足性能上的要求;
3.单节点的数据库没有冗余设计,无法满足高可用;
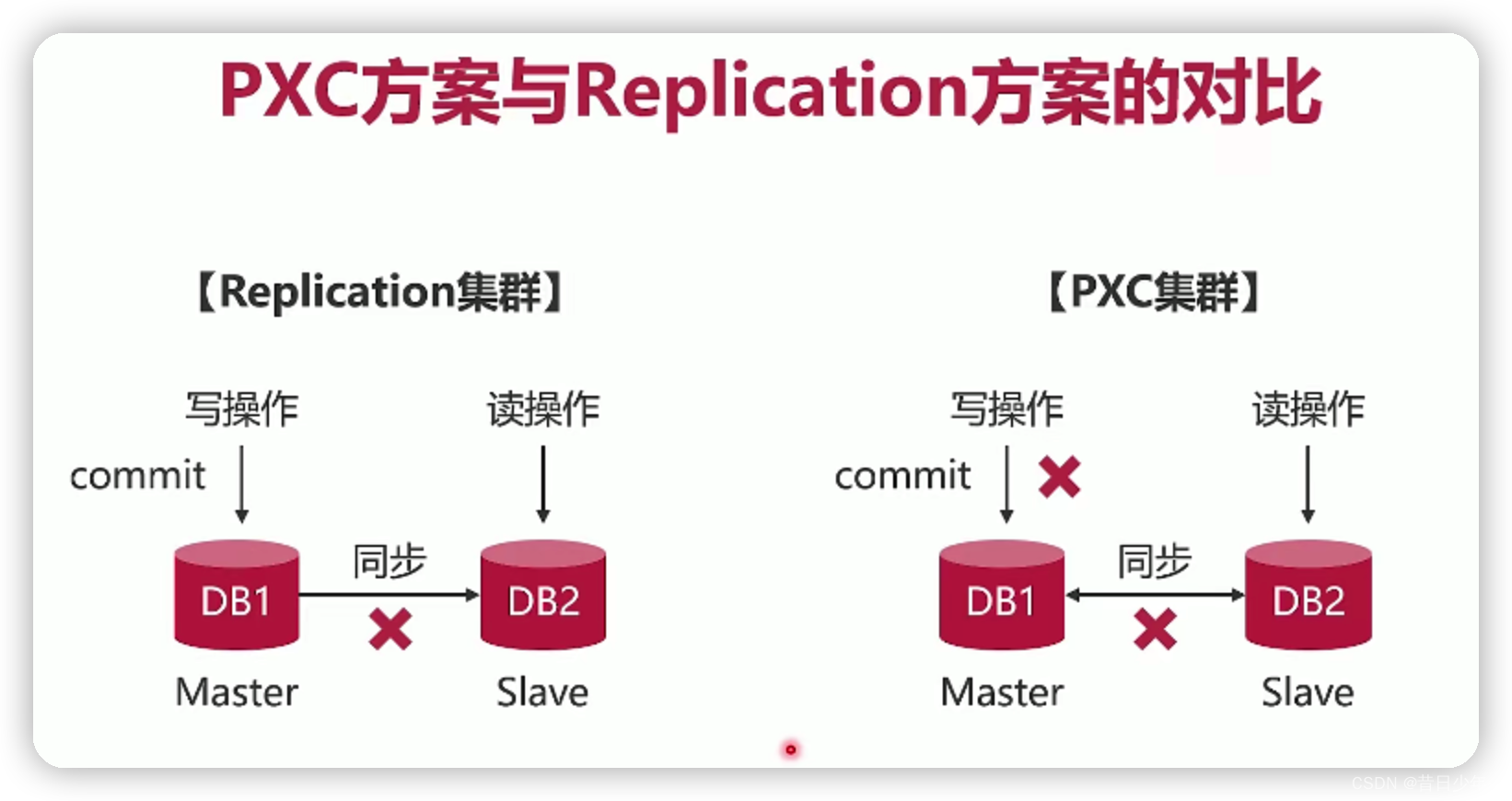
常见MySQL集群方案
1.常见的MySQL集群方案有PXC和Replication
2.两种集群方案有各自的特点,PXC集群适合保存少量高价值数据,Replicaiton适合保存大量数据
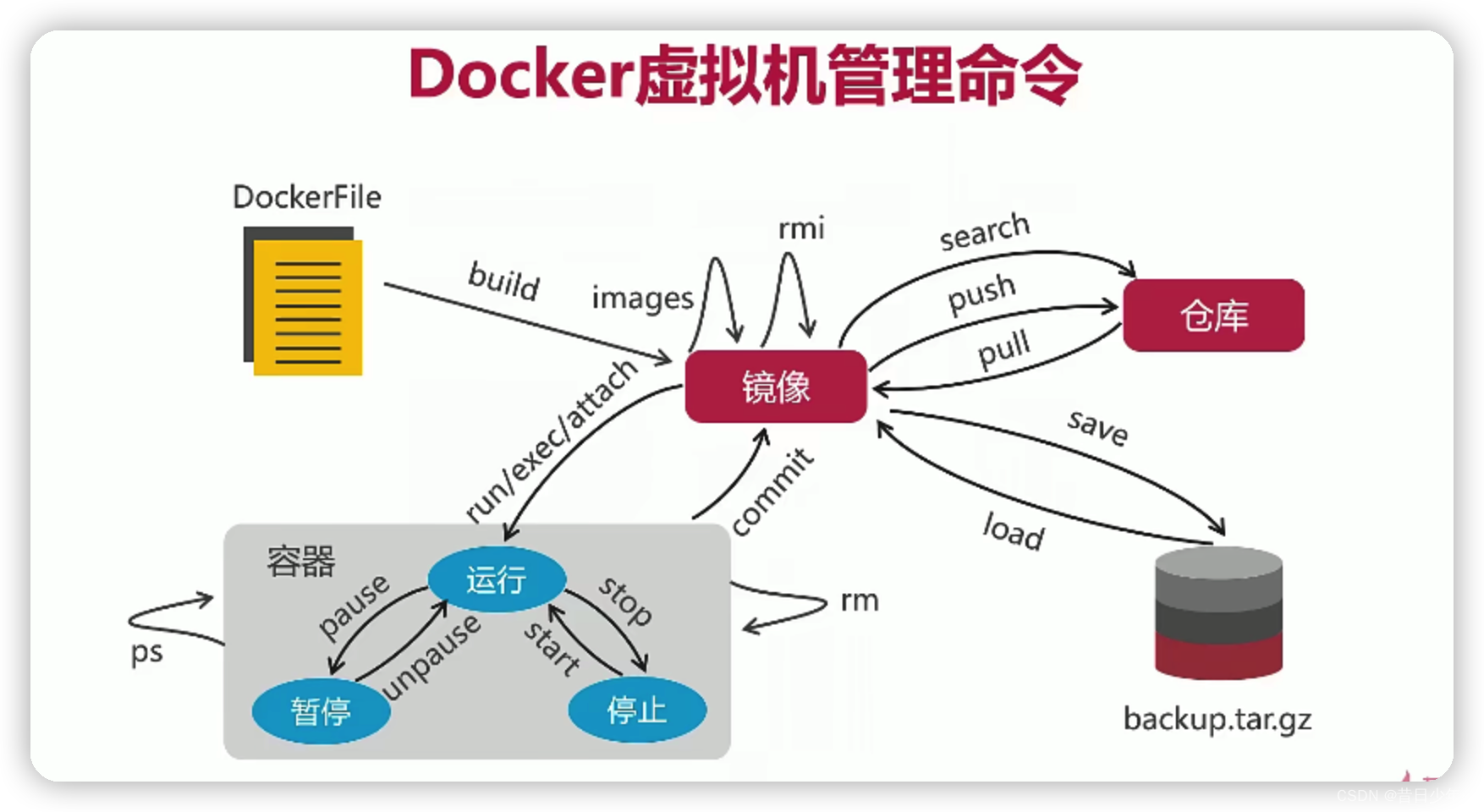
Docker