原始数据
import pandas as pddata = {"grammer":["python","python", "java", "go", ], "score": [2, 5, 3, 4], "fenshu": ["ds","ws","A","s"]}df=pd.DataFrame(data)print(df)看不懂就从前面文章看输出结果

挑选行
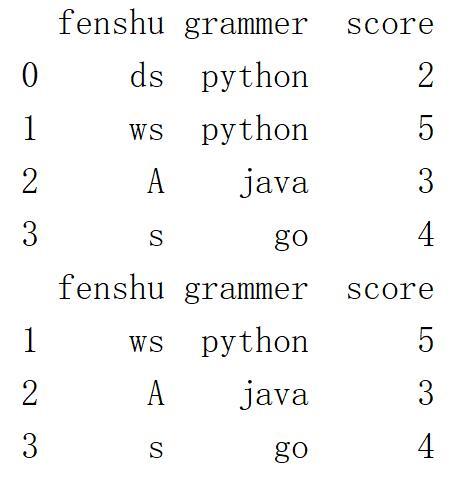
print(df)print( df[ df["score"]>=3 ] )输出score列数据大于等于3的行输出结果
挑选满足多个条件的行
print(df)print( df[ (df["score"]>=3) & (df["score"]<5) ] ) 看不懂看以前文章括号由外向内看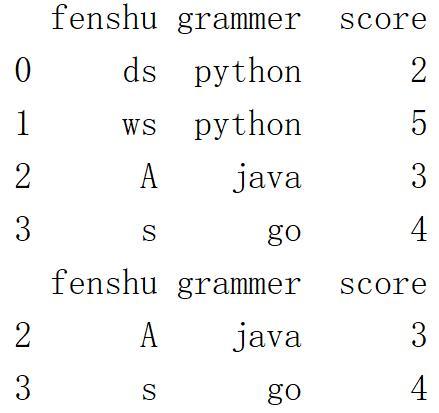
输出结果
提取列最大值中的行
print( df[ df["score"] == df["score"].max() ] )score列中最大值所在的行输出
输出结果
输出最后行数
print(df.tail(2))输出最后两行
增加一行数据
print( df.append (row,ignore_index= True) )
删除最后一行
df.drop( [len(df)-2],删除倒数第二行 inplace=True )print(df)
数据排序
df.sort_values("score",inplace=True)print(df)对score列数据大小进行排序
版权声明:本文为weixin_36212050原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。