layout: post
title: 3D单目(mono 3D)目标检测算法综述
date: 2021-01-22 22:08:39.000000000 +09:00
categories: [算法篇]
tags: [CV, 3D, 综述]
前言
翻译自:
Monocular 3D Object Detection in Automnonmous Driving-A Review
更新monocular 3d object detection相关算法:
- Add RTMD(01/15/2020)
- Add Virtual Camera from Mapillary(02/16/2020)
- Add Decoupled Structured Polygon(02/21/2020)
- Add Refined MPL(03/22/2020)
- Add MonoPair(06/04/2020)
- Add SMOKE(06/05/2020)
- Add The Earth ain’t Flat(06/28/2020)
- Add D4LCN(08/22/2020)
- TODO: Add (PseudoLidar V3, ZoomNet, ApolloCar3D, 6D-VNet and PartParse)
3D检测在自动驾驶领域是一个及其重要的任务.许多该领域内的任务,诸如:任务决策,路径规划以及运动控制都需要涉及无人车周围良好的3D空间的感知与表达.
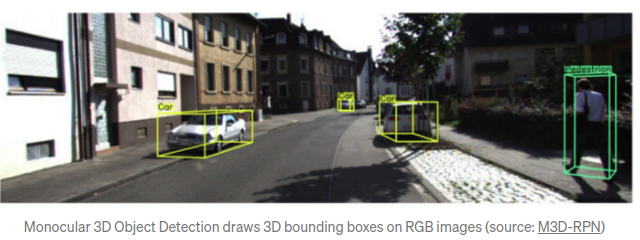
近几年,基于3D Lidar的算法(如重要工作: PointNet, 实现了基于神经网络对点云数据的特征提取)大大提高3D物体检测的精度.但是3D Lidar的缺点在于:Lidar成本较高,且Lidar易受天气环境的影响.而基于RGB摄像头数据的3D检测能够提高检测系统的鲁棒性,尤其是当其他更昂贵的模块失效时.因此,如何基于单/多摄像头数据实现可靠/精确的3D检测显得尤为重要.
单目3D物体检测(mono 3DOD)本身不是一个新的方向,只是近期引发了热点.比较期待2020能够出现更多的想法,因为就目前而言,lidar-based和image-based算法差距还是很大.
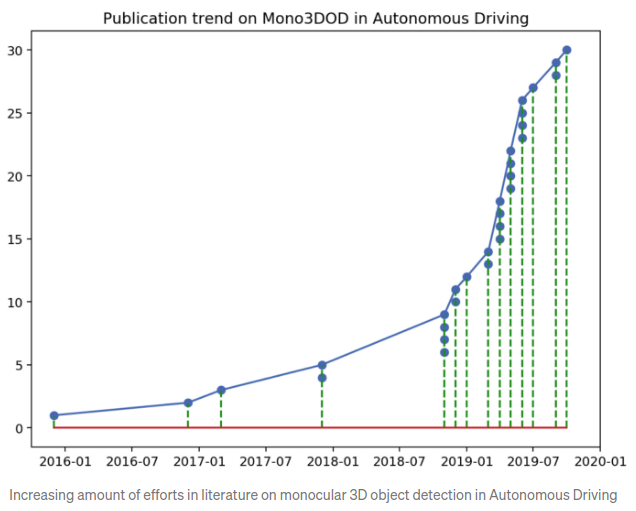
算法调研(相对完善)
下图显示了对于monocular 3D近期的进展.其中介绍了截止到2019/11(之后会不断更新)的相关的文章.所以,本文是一份对于mono 3DOD的相对完善的算法总结,大致可以分为4派别:表达形式转化(representation transform),关键点&&形状(keypoints and shape),2D/3D间几何约束(geometric reasoning based on 2D/3D constraint),以及直接生成3D框(direct generation of 3D bbox).值得一提的是,通常一篇文章都是涉及了多个思路,因此上述的派别的划分是比较宽松的.相关的Paper链接可参照:
Github_DL_Paper

2D升3D问题
直接基于2D图片进行3D检测是困难的,因为理论上这是一个病态的问题,因为本身2D图片中的深度信息是缺失的.但是,在一些特定场景以及一些强先验的情况下,该任务仍然是可实现的.具体在自动驾驶领域,其中比较关注的一些物体,如机动车,属于尺寸大小都相对稳定的刚体,因此机动车的3D信息可以通过单目图像得到.
表达形式(Representation transformation): BEV, Pseudo-Lidar
无人驾驶中,摄像头通常架设在车顶或者类似常见的行车记录仪的安装方式.因此,对于摄像头来说,提供的图像视角都是前视的视角.该视角与真实驾驶的视角保持一致,但是该视角存在的问题是:遮挡和基于距离的物体尺寸变动.
缓解前视视角缺点的一种方式转化前视视角为鸟瞰图视角(Birds-eye-view BEV).在BEV视角中, 机动车的尺寸存在一致性,与离自身车的距离无关,且机动车之间不存在重叠(前提是正常情况下,机动车在不存在上下相叠的情况).反前视角映射(Inverse perspective mapping, IPM)通常应用于BEV图的生成,该方式的先验是所有的生成的像素点都是在地平面上,摄像头的之间的精确的内/外参数一致.但是,实际应用中,IPM对外参精度要求较高,需要进行实时在线校准.
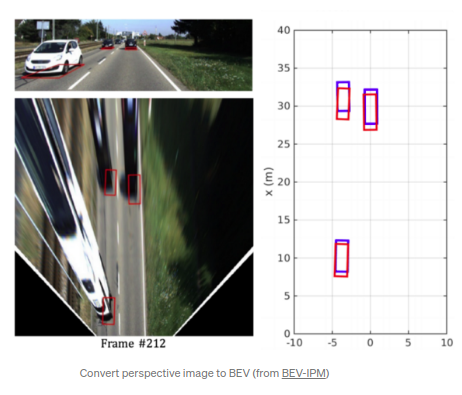
BEV IPM OD(IV 2019)
的思路便是通过IMU数据实现外参的在线校准,从而得到更加精确的IPM图片,同时基于此进行物体检测,demo效果如下:
yotube
.
Orthographic Feature Transform(OFT)(BMVC 2019)
采用实现前视图到BEV图的转换,但是基于深度学习框架.算法思路是采用正交特征转化(orthographic feature transform, OFT)实现了将前视视角特征转化为正交BEV视角.前视视角特征基于ResNet-18提取.通过对image-based特征进行叠加得到voxel-based特征则是(类似于CT图片重构中反向映射过程).voxel-based特征通过在竖直方向上的投影生成正交于地平面的特征.最后,采用类似ResNet的topdown网络实现BEV map层面上的物体检测.
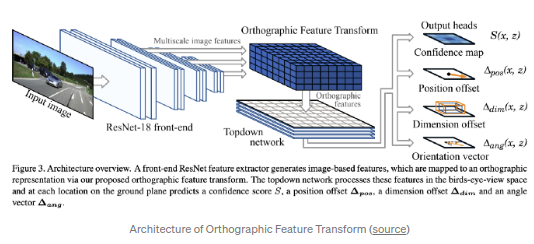
OFT的想法简单而有效.虽然其反向映射的过程可以通过一些启发式的方式实现voxel-based特征更合理的初始化来优化反向映射的方式.如图片中一个比较大的2d检测框不可能映射到非常远的物体.另外该算法依然依赖于精准的外参,该精准外参通常很难在线得到.
另一种将前视视角转换为BEV的方式是
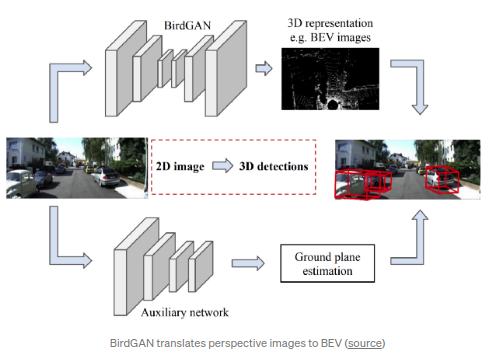
BirdGAN(IROS 2019)
,文章使用了GAN实现了BEV的转换.该方法取得了比较好的结果,但是按照文章所说,其到BEV空间的转换在前视距离10-15m内的效果较好,所以应用范围有限.
接下来的话题是伪雷达(pseudo-lidar).其思路为通过图片预测深度信息,从而产生点云信息,这也得益于近期在单目深度估计上一些进展(其本身也是一个自动驾驶的热门话题).以往基于RGBD图片数据的处理通常是将depth维作为第四channel作为输入,网络采用常规网络只不过在第一层输入上进行调整.
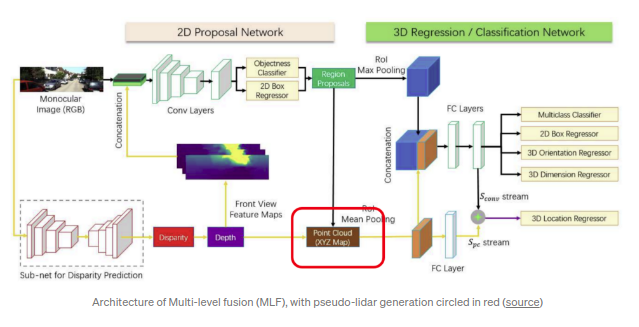
Multi-Level Fusion(MLF, CVPR2018)
是首先将预测深度拓展到3D空间的工作之一.算法利用预测得到的深度信息(以
MonoDepth
参数作为固定网络参数)将RGB图的逐个pixel映射会3D空间,之后生成的点云数据会与图像特征融合用以回归3D检测框.
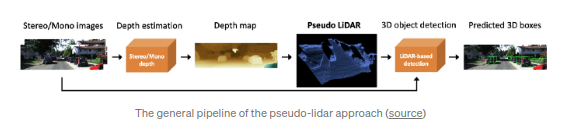
Pseudo-lidar(CVPR2019)
应该是该领域最广为人知的工作了.其受启发于
MLF
,并采用了一种更直接的验证方式:直接采用当前性能最佳的基于Lidar数据的SOTA 3d检测算法.作者的观点是数据的呈现方式是重要的,卷积网络不生效的原因是对深度图来说,即使是相隔很近的像素点,其在3D空间中的深度差距也会比较大.作者后续还提出了
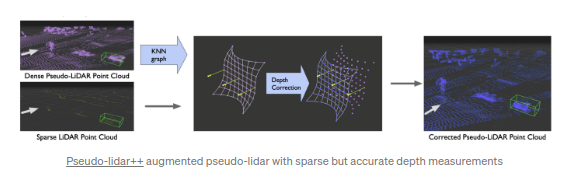
Pseudo-lidar++
.其主要的提升点在于算法能够基于线束更小的低成本lidar数据生成的pseudo-lidar数据.基于摄像图图片生成稠密的3D点云数据,并基于点云数据进行深度预测在自动驾驶领域有较强的实用潜力.
后续基于pseudo-lidar算法主要是基于原始算法的优化.
Pseudo-Lidar Color(CVPR 2019)
融合了深度信息和RGB信息,直接利用concatenation将(x,y,z)转化为(x,y,z,r,g,b)或者采用attention-based的方式选择性地传入RGB信息.文章同时采用了一种简单而高效的点云分割方式,主要借鉴于
Frustum PointNet(CVPR 2018)
并采用其视锥中的平均深度.
Pseudo-Lidar end2end(ICCV 2019)
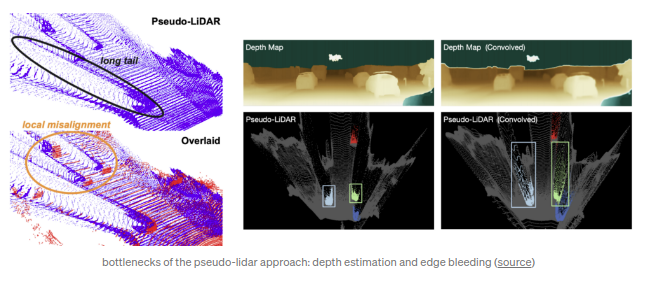
提出pseudar-lidar的瓶颈在于两个方面:因为深度估计误差引起的匹配误差(local misalignment)以及深度数据在物体边缘突变引起的lidar数据的长尾(long tail)现象.该文章采用了语义分割的mask而不是Frustum PointNet中的bbox,并且引入2D/3D框的一致性损失.
ForeSeE
也提出了相似的观点,并且提出在深度估计任务中并不是所有的像素信息都是同等重要的.该算法没有采用直接可用的深度估计模型,而是各自训练了两个深度估计模型,分别预测前景和背景的深度信息,并且在infer的过程中选择性地融合深度图.
RefinedMPL
探讨了pseudo-lidar中的点云密度引起的问题.文章指出pseudo-lidar的点云密度远高于64线真实lidar得到的点云数据密度.尤其是更多的背景点云数据反而会引起的更多的误报(false positives)同时也增大了计算量.所以,文章中提出了用以点云数据的结构稀疏化的两个步骤:首先定义得到前景点,然后进行稀疏化处理.前景点通过两种方式得到:其一为监督学习,其二为非监督学习.其中监督学习方式通过训练一个2D的检测器,并使用2D检测器得到的2D bbox的mask作为前景点的mask来去除背景点.非监督方式使用的是LoG(Laplacian of Gaussian)特征用以关键点检测同时采用最近邻算法(k=2)得到点作为前景点.最后得到的前景点被划分到固定的深度区域(depth bins)进行均匀稀疏化.RefinedMPL指出即使只用10%的点,3D物体的检测性能依然没有变差,甚至略由于原始的baseline.同时论文指出pseudo-lidar与真是lidar的性能差距在于其不准确的深度估计.
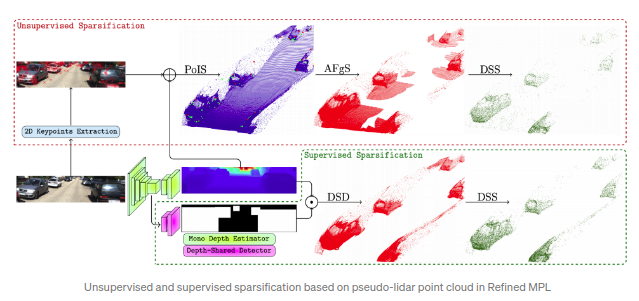
整体上看,上述思路是更可行的.意味着只需要对前景物体的较为精确估计即可(不需要稠密点云),而这可以通过较为稀疏的深度测量方式得到,如低成本的四线lidars.
关键点&&形状
机动车等通常都为已知物体构件组成的几何刚体,因此其通常是可以采用landmarks/keypoints来得到检测/分类/识别结果.而在3D检测中,尤其是无人驾驶领域,机动车/行人等对象的尺寸大小和关键点也是大体可知的.所以,尺寸信息可以作为估计距离的依据.
基于上述原理,大部分相关的工作都是基于当前的2D物体检测框架(one-stage如Yolo/RetinaNet,或者two-stage如Faster RCNN)进行关键点的检测.
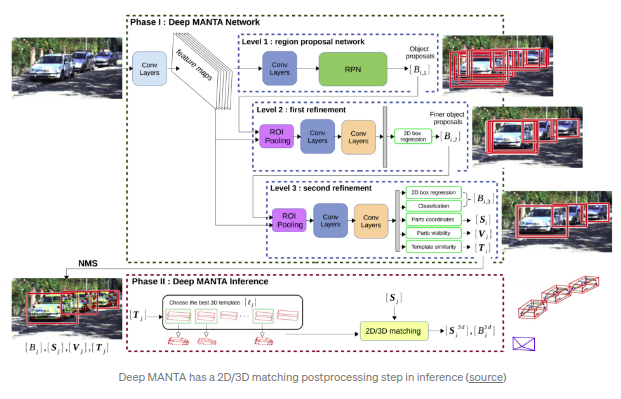
Deep MANTA(CVPR 2017)
是该思路下的先驱工作.其中阶段一(training && inference)通过cascadeed faster RCNN得到2d bbox,分类结果,2d keypoints, 可见性以及模块相似度(template similarity).其中模板相似度由3d bbox的参数(w,h,l)得到.阶段二(仅应用于inference),通过模板相似度来得到匹配成都最高的3D CAD模型,然后通过2D/3D匹配(
EPnP算法
)重建3D位置和朝向.
The Earth ain’t Flat(IROS 2018)
旨在基于单目进行非平坦道路的机动车3D重建.本文框架的核心点为从单目图片中估计得到3D的形状和6DOF的姿态.其中Keypoiunt检测框架依然采用了MANTA的36点检测方式.它的区别在于不再简单的获取3D模板的最佳匹配,而是得到一组基本向量和变形参数来捕获最终的机动车形状.这种通过一系列基本形状,然后结合变形参数的思路类似于3D-RCNN和RoI-10D.其中,关键点检测模型基于ShapeNet的2.4百万的综合3D CAD模型数据集得到(通过900个3D CAD模型渲染生成),且作者发现其在真实数据场景上具备一定的泛化能力.该mono3DoD的方式也被应用于其他工作,如
Multi-object Monocular SLAM(IV 2020)
.

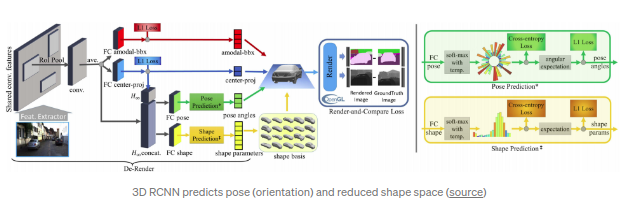
3D-RCNN(CVPR2018)
基于Faster RCNN设计,能够预测机动车的形状,姿态以及尺寸参数,并同时进行场景的渲染.其得到的mask会和深度图中的GT进行”rander-and-compare”loss的计算.PCA(Principal Component Analysis)被用于提取尺寸空间的主特征(10-d).位姿和尺寸参数利用RoIPooled特征(与原始RoI Pooling方式不同,此处结合三维空间特点,提出了underlying 2D transformation)通过基于分类结果回归(如将距离划分多个区间,通过分类结果得到距离结果)得到.该方案的输入比较复杂:2D bbox,3D bbox,3D CAD模型,3D语义分割结果以及相机内参.同时,”render-and-compare”loss需要基于OpenGL得到,需要一定的工程技巧.
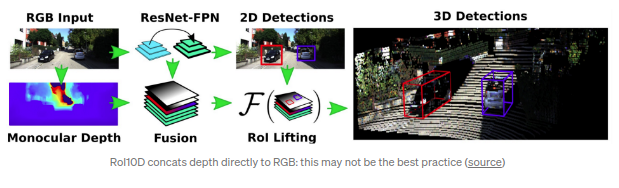
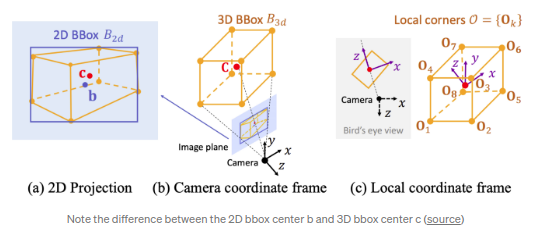
RoI-10D(CVPR 2019)
,其名字10D指的是6DoF位姿+3DoF的3D bbox的大小(w,h,l),额外的一维指的是形状空间(shape space).类似3D RCNN,RoI-10D获取的是形状空间的6-d特征,且采用了3D自编码方式(3D auto-encoder).RGB得到的特征通过估计得到的深度信息进行增强,之后通过RoIPooled(参考3D-RCNN)回归得到旋转角度q(quaternion),RoI相对的2D中心位置(x,y),深度(z)以及尺寸参数(w,h,l).通过上述参数,便可以估计得到3D bbox的8个顶点.Corner loss可以通过预测得到的8个顶点和GT得到.其中shape的GT是基于KITTI3D数据,通过最小化重映射loss线下标注的.shape的使用比较engineering-heavy的.
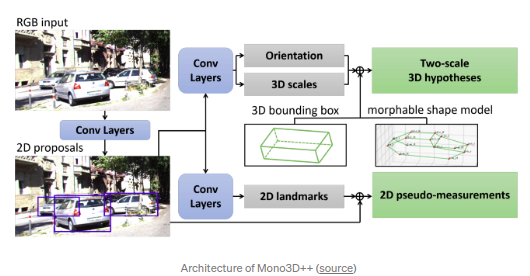
Mono3D++(AAAI2019)
通过3D和2D的一致性得到3DOD,主要通过landmark点和形状得到.文章通过14个landmarks点得到可变形线框模型(morphable wireframe model).其中形状的低维表示是通过
EM-Gaussian
方式基于2D landmarks得到.算法类似于3D RCNN以及RoI 10D.本文还估计得到了深度和地平面以此得到多个预测分支间的一致性loss.但是算法的很多关键细节在文中并未披露.
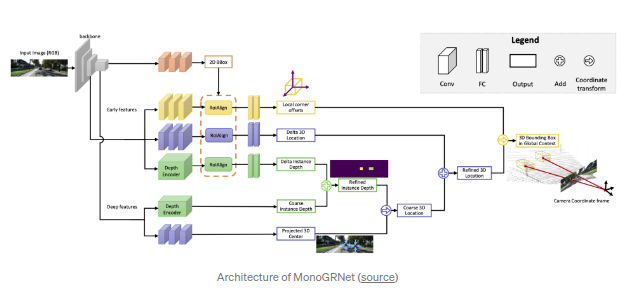
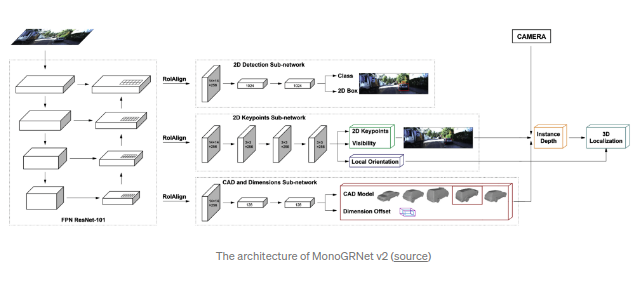
MonoGRNet(AAAI2019)
能够回归得到映射到的3D中心点,粗略的instance深度以及两者之间的大致3D位置.文章强调了2D bbox中心和3D bbox中心映射到2D图片的差异.映射得到的3D中心点可以认为一个额外添加的关键点,类似于
GPP
.与其他算法不同的是,文章并不是回归相对容易的观测角度(observation angle)而是直接回归3D中心点的8个顶点的相对偏差得到.
MonoGRNet V2
在2D图片中回归关键点并采用3D CAD模型infer得到深度数据.训练过程基于3D CAD模型(3D KP点标注较少)得到,其中2D KP点通过3D bbox半自动得到(类似Deep MANTA).整体算法框架类似于Mask RCNN框架,额外添加了两个head分支.其中一个分支用以回归2D KP点,可见性以及自身旋转角度;另外一个CAD&&形状分支负责选择CAD模型并且回归3D尺寸偏差.对象的距离通过挡风玻璃的高度得到的(原始的Mask RCNN物体检测分支参与模型训练,因为能够稳定训练过程,但是在infer过程中不会使用.其中KP点的回归则是通过全连接层回归得到关键点坐标而是按照原paper中先得到heatmap).
除了3D CAD模型外,Deep MANTA还采用了半自动的方式通过将CAD模型布置到3D bbox gt中得到3D关键点.Deep MANTA在103个CAD模型上都标注了36个关键点.MonoGRNet V2在5个CAD模型上标注了14个关键点.Mono3D++同样也标注了相同的14个关键点.
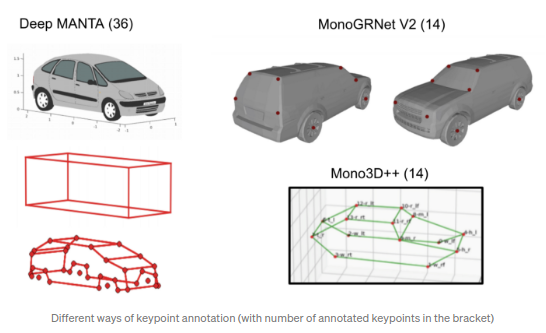
通常来说,大批量的机动车的稠密关键点标注是非常复杂且耗时的.Baidu的ApolloScape,尤其是ApolloCar 3D,作为主数据集上派生出来的子数据集,是唯一以点云形式,提供稠密的关键点和形状标注的.
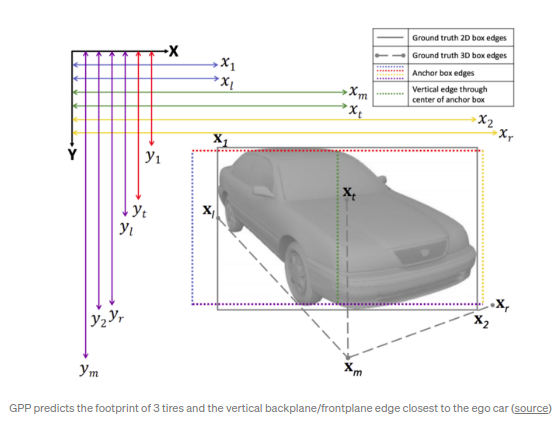
Ground Plane Polling(GPP)
通过3D bbox标注生成虚拟的2D KP点.算法预测得到一些需求外的属性值来得到3D bbox(over-determined),目的是通过所有得到的预测值取计算最接近的拟合结果,类似与RANSAC算法,使得算法计算外边缘的鲁棒性更强.
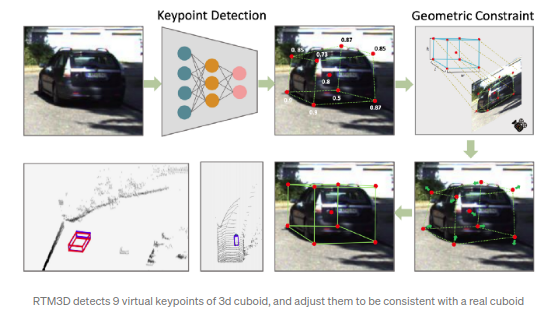
RTM3D(real-time mono-3D)
同样采用了虚拟的关键点,算法采用了CenterNet类似的框架直接检测得到所有3D立方体的八个顶点和中心点.文章同时还直接回归了距离,角度,尺寸.回归得到的所有属性值可以作为先验来初始化离线的优化器来得到3D bbox,而不是直接得到3D bbox.文章声称是第一个实时的单目3D(monocular 3D)物体检测算法框架(0.055 sec/frame).
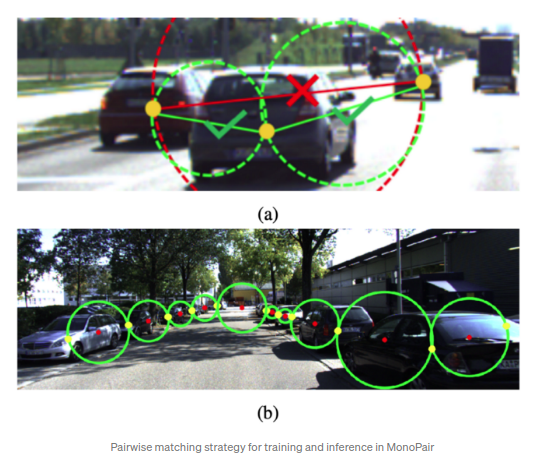
MonoPair
从CenterNet得到了诸多启发,并且通过成对车之间的空间关系来改善最终的检测结果.相较于CenterNet直接预测得到3D bbox,同时还预测得到虚拟成对匹配车之间的约束点.匹配关键点定义为:最近两个物体之间的各自的中心点对.该“成对关键点(relationship keypoints)”类似于
Pixels to Graphs(NIPS 2017)
中的定义.MonoPair的出发点在于全局优化,通过将深度估计过程中的不确定性包含在预测过程中可以提升模型性能.MonoPair同时还通过物体之间的绝对位置的旋转变化来确保局部坐标系下的视点不变性.MonoPair同样实现了57ms/frame的实时性能.
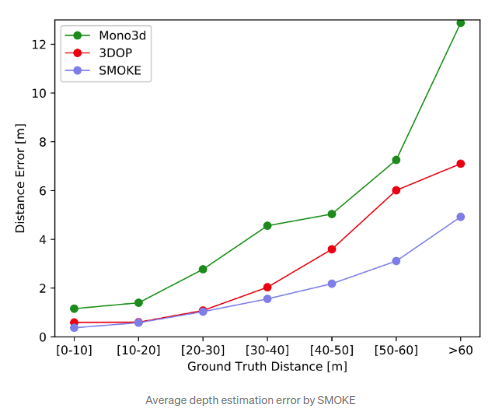
SMOKE(CVPRW2020)
同样受启发于CenterNet,且不再回归2D bbox而是直接回归3D bbox.其采用的3D bbox的encoding方式为映射得到的3D立方体中心点,以及其他参数(尺寸,距离,旋转角度)作为补充参数.Loss采用的是3D corner loss(L1 loss),参考自
MonoDIS
.该Loss的表示方式,与通过对各类loss函数求取加权和来预测7DoF参数相反,而是隐式地通过不同loss对整体3D bbox预测的贡献进行加权实现.算法性能为60m内的距离误差为5%以内,为单目深度预测的SOTA算法.代码开源:
code
.
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation(AAAI 2020)
首次提出3D顶点的2D投影估计是与深度估计可脱离的(文中称之为Structured Polygon).其采用了和RTM3D类似的方案得到映射后的立方体顶点,且虚拟的边缘高度作为强先验来得到距离估计.通过该方式可以得到粗略的3D检测框.该3D框作为BEV视角的初始位置(可以通过类似
Pseudo-Lidar
的方法得到),之后可以基于该位置进行finetuning.该方案可以取得比monocular Pseudo-Lidar更好的效果.

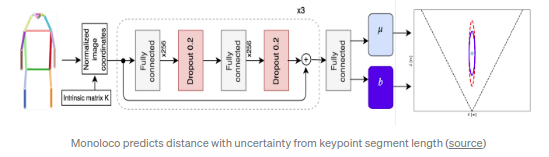
Monoloco(ICCV 2019)
和上述算法的不同点在于其注意点主要在于行人的位置,行人3D位置的获取相较于机动车通常会更具有挑战性,因为行人通常都为非刚体物体,存在不同姿态和变形.算法采用了关键点检测模型(top-down框架,如:Mask RCNN,bottom-up框架,如:Pif-Paf)得到人体关键点.类似于MonoGRNet V2和GS3D的预测深度的方式:利用人体肩膀到胯部中点的距离(~50cm)来预测深度,可以以此结果作为baseline.文章最后采用的是以所有关键点段的长度为输入,通过多层全连接层来预测深度,性能明显优于baseline.同时文章还构建了不确定性模型以此进行不确定性的预测,该功能在一些安全要求高的场景,如无人驾驶,尤为重要.
整体上看,直接基于2D图片获取2D关键点并基于此得到3D信息而不需要来自lidar的3D GT的监督是有一定潜力的.但是该方案的问题是关键点的标注成本较高,且3D模型转化层面通常较为复杂,工作量较大.
通过2D/3D约束进行距离估计
该方向上的工作为通过2D/3D的一致性来实现2D转3D.其开创性工作为
deep3DBox(CVPR2016)
.类似于上述利用关键点/形状的方案,这部分工作也是通过在原始2D物体检测框架的基础上添加分支来回归局部坐标系下的旋转角(或者称为:observation angle)以及相比子类别平均尺寸的偏差.通过这些几何约束信息,算法便可以解决过度约束的优化问题以获取3D位置,实现2D bbox到3D bbox的转化.
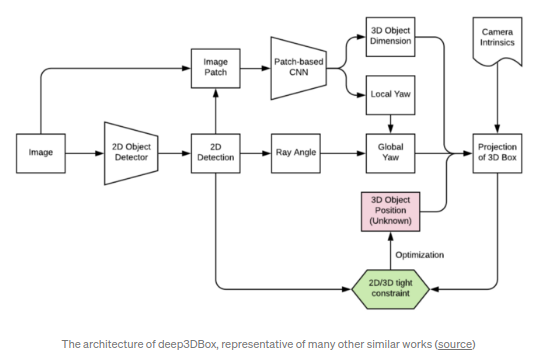
Deep3DBox的劣势在于以下两点:
- 算法依赖于精确的2D bbox坐标:较小的2D检测框的误差往往会引发3D的更大的误差
- 优化算法单纯依赖于bounding bbox的尺寸和位置,而没有利用到图片信息.
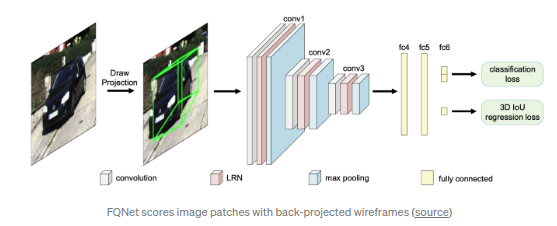
FQNet(CVPR 2019)
将Deep3DBBox的思路进行了一定的拓展,使其不再局限于紧密约束内(tight-fitting).算法在Deep3DBox的基础上添加了优化步骤:通过在预估得到的3D初始位置上进行稠密采样(3D初始位置通过2D/3D的紧密约束得到),然后通过采样得到的3D渲染线框位置对2D区域进行打分.但是,稠密采样方式较为耗时且计算较为低效.
Shift R-CNN(ICIP 2019)
通过主动回归Deep3DBox候选区域(proposal)的偏移值来避免候选区域的稠密采样.算法将所有已知的2D/3D bbox信息作为输入,通过简单的全连接层(称为ShiftNet)来优化最终的3D位置.

Cascade Geometric Constraints
通过预测3D bbox的地面中心点以及对视角的分类来实现3D bbox的预测.同时,它能够基于infer得到的3D信息去除2D检测结果的误报,例如:检测box的下底面的深度值顺序,以及深度相近的相邻2D检测框.
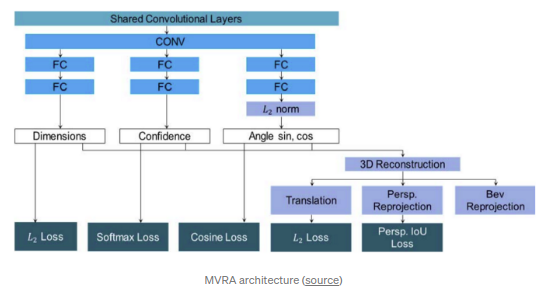
MVRA(Multi-View Reprojection Architecture, ICCV 2019)
将2D/3d间的空间约束直接在神经网络中实现并且采用迭代的方式来优化截断的case.算法引入了3D重构层实现2D转3D,而不是按之前的方式通过过约束的等式来得到.网络Loss包含了两部分:1)前视视角的IoU loss,其语义在于映射后的3D bbox以及原始2D bbox之间的IoU loss;2)BEV loss,其语义为BEV视角下的预测深度和GT深度的L2 loss.同时,文章指出deep3DBox没有处理好截断的case,因为2d box的四边并不是和真实机动车物理边相对应的.文章采用了迭代优化的方式来优化截断case的旋转角度,优化过程中不再采用原始的4个约束,而是去除xmin(左边截断)或者xmax(右边截断),只采用3个约束进行优化.另外全局的yaw角则通过以pi/8和pi/32为间隔的两个迭代,通过反复试验按照误差大小最终得到.
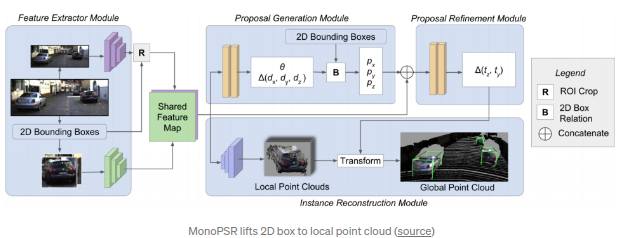
MonoPSR(CVPR2019)
作者为另一篇前融合算法AVOD的作者.文章的方案是先生成3D的候选区域然后再重构局部坐标系下对应运动物体的点云数据.其中质心获取模块主要依靠2D box高度以及回归得到的3D物体高度进行深度预测,从而将2D框的中心映射到3D空间对应的深度位置.该阶段的实用性和精确度都很高(绝对的深度误差约~1.5m).其中重构分支回归得到局部点云,并且和真实点云数据以及其投射到camera视角下的点云数据进行比较进行回归.本文再次声明了和MonoGRNet以及
TLNet
的观点:对整个场景的的深度预测对于3D物体检测任务来说是比较困难的(overkill).而聚焦于检测物体中点则能使任务变得更简单,避免了大范围的深度回归.
GS3D(CVPR 2019)
很大程度上基于Faster RCNN框架,在其基础上添加了额外的角度回归检测头.其基于局部坐标系下的角度和由2D检测框估计得到的3D深度得到一个粗略的3D位置.其中深度的估计采用了基于训练集的统计先验:将3D检测框映射到2D图片中的映射框高度为2D bbox的0.93倍左右.同时它还采用了物体表面的特征提取模块(基于RoIAlign拓展的仿射模块)进行3D检测框的优化.

综上,该思路是基于2D物体检测拓展为3D检测结果的最为实用的方向.其中,Deep3DBox的开拓性工作的影响是最为深远的.
直接生成3D候选区域(proposal)
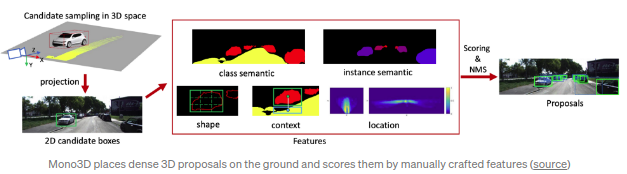
该方向的先驱性工作之一为Uber ATG提出的
Mono3D(CVPR16)
.算法旨在直接生成稠密的3D候选区域,其算法先验为机动车都是布置在地面上的.得到候选区域后,算法通过一系列的手工设计的特征对每个候选区域进行打分,从而通过NMS得到最后的检测结果.从某种层面上看,该方案类似于
FQNet
:通过反向映射3D线框对3D bbox候选区域进行打分.但是FQNet的3D候选区域基于Deep3DBox的原始位置得到的.
MonoDIS(ICCV 2019)
基于拓展后的RerinaNet框架直接回归得到2D检测框和3D检测框.文章提出不再直接监督2D/3D输出的所有参数,而是从回归得到的bbox整体出发,通过2D(带符号)IoU loss以及3D角点损失(corner loss).直接基于上述loss进行训练会比较困难,所以本文提出了一种解耦的方法:先只训练单独部分的参数而固定其他部分的参数为gt,然后计算损失,即训练过程中只会训练未固定部分的模型参数.该选择性的训练过程会不断循环直到所有需要得到的参数都被训练更新,同时最终的损失也会在单次预测过程中进行累计.该解耦训练的方式使得模型能够进行2D/3D检测框的端到端训练,并且能够拓展到其他应用中.
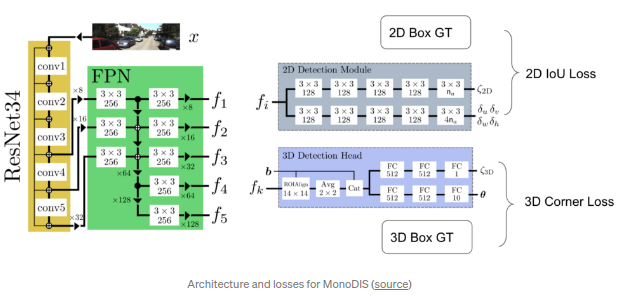
MonoDIS的作者之后还借鉴了
Virtual Cameras
的思路,进一步提升了算法的性能.该算法的核心观点是:模型能学习到不同距离的机动车的特征,但是模型缺乏训练范围外的机动车的泛化性.为了得到更大的检测范围,必须提高模型远距离机动车的检测能力同时增加对应的训练数据.Virtual Camera能够将整张图片分割为多个图片patch,每个patch都至少包含了一辆完整的机动车,且存在一定范围内的深度变化.前向推理过程中,会生成类似金字塔形的图片.其中图片的每一行都对应着固定范围的深度,同一行的不同位置意味着横向距离的变化.


CenterNet
是一个可拓展性很强的多功能算法框架,能够被拓展为很多检测相关的任务,如:关键点检测,深度预测,旋转角度预测,等.其首先回归得到heat map图(检测物体中心点confidence热力图),并以此回归得到其他物体属性.将CenterNet拓展为2D/3D的物体检测框架是比较简单直观的.
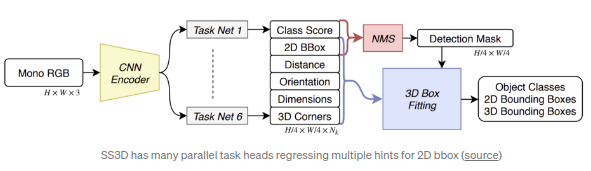
SS3D
正是采用了类似CenterNet的检测框架,算法先得到候选区域的中心位置,然后回归得到2D和3D的检测框坐标.其中回归任务往往会回归得到更多的参数用以优化2D/3D检测框坐标.算法中涉及到2D/3D的检测框相关参数有26组.所以,最终得到的loss为加权后的26组loss之和,其中loss的权重是通过动态学习得到的.训练过程中,loss可能收敛于局部最优点,所以基于启发式算法得到的较好的初始状态是重要的.
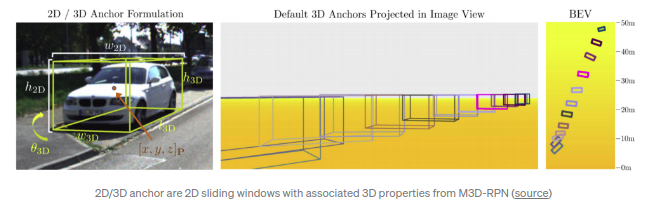
M3D-RPN(ICCV 2019)
通过对每个2D anchor的3D均值的预计算可以同时回归得到2D和3D检测框参数.其最终得到回归得到的是2D/3D检测框参数为11+num_class,类似于SS3D(得到26组参数).文章的亮点在于提出了2D/3D anchors.尤其是3D anchors是基于2D anchor生成的,所有3D Anchor本质上是2D anchor具备了3D属性.3D anchor的3D属性是基于2D anchor位置和先验信息得到的.M3D RPN对特征图的不同行采用了分离的不同卷积核记性计算(depth-aware convolution),因为深度信息在不同行之间往往存在较大差异尤其是在自动驾驶领域.
D4LCN(CVPR2020)
借鉴了M3D-RPN的depth-aware convolution思路更进一步引入动态filter预测分支.外加的分支以深度预测值为输入生成filter特征量,用以生成指定位置的卷积参数,包括权重和膨胀率(空洞卷积参数).D4LCN也参考了M3D-RPN的2D/3D anchors,同时回归了2D/3D检测框(每个anchor对应35+4 classes参数).
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jFSt1IYY-1629534290509)(https://cdn.jsdelivr.net/gh/ZhengWG/Imgs_blog/2021-01-22-3D%E5%8D%95%E7%9B%AE%28mono_3D%29%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95%E7%BB%BC%E8%BF%B0/39.png)]
TLNet(CVPR 2019)
主要关注于双目图像,但是该算法还是有比较solid的单目图像baseline的.算法的单目baseline的方案是将3D anchors布置在2D检测框所对的视锥内.文章重申了MonoGRNet的观点:像素级别的深度图对于3DOD问题来说过于困难,或者说是奢侈(too expansive)的,对象级别(object level)的深度已经足够.其参照
Mono3D
的方式采用了[0, 70m]范围内的3D anchor的布置方式,(0.25m间隔),角度为0/90度.每个类都有对应的anchor,尺寸为各自类的平均尺寸.最后,3D 候选区域被映射到2D以此得到RoI,经过RoIpooled的特征被用于回归位置和尺寸偏差.
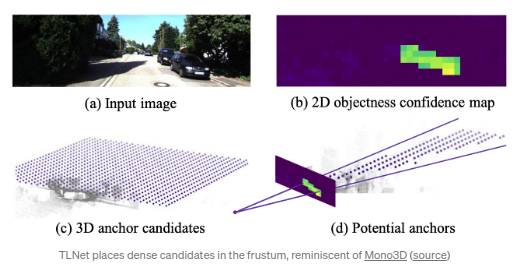
总的来说,在3D空间内布置3D anchors还是比较困难的,原因在于存在大量的可布置的位置.Anchor本质是滑动窗口,而穷尽3D空间位置还是比较棘手的.因此,通常会使用启发式或者基于2D物体检测生成3D检测框,例如:车都是布置在地平面上的,并且车的3D检测框都是在对应2D检测框所面对的视锥内等.
关键总结
- 单目3D物体检测本身为一个病态的问题.然而,我们可以通过2D图片中局部旋转角度,关键点信息以及2D检测框结合几何学关系进行3d或者BEV空间内的位置预测.其中关键点,除了包含一些真实的关键点,如车灯,挡风玻璃边缘,还包括一些人为添加由3D检测框生成的关键点,如3D检测框的中心点或者上下底面点.
- 2D/3D点之间的一致性可以用于规范2D/3D点的联合训练,在获得现有几何关系后,可以将3D检测框的预测问题作为已有2D预测框后的后处理问题.
- 单目深度估计近几年来获得了长足的进步.稠密的深度估计可以使得RGB图像转化为伪雷达点云数据(pseudo-lidar point cloud),从而可以适用于更多基于点云数据的SOTA算法.
- 前视视角下进行3d物体检测通常是比较困难的.而将前视视角转换为BEV视角通常会让检测任务变得更简单,因为在BEV视角下,机动车的可视尺寸不会随着距离的远近发生变化.
- 上述所有算法的先验都是相机的内参是已知的.如果相机的内参未知,大部分算法依然是可行的,只是需要在其结果基础上乘以一个尺寸因子.