- 引言
很多人对spark初步理解为是基于内存的,但这种说法不够准确,其实应该称spark是充分利用了内存而已,在给定资源规模情况下,通过对内存更细致的划分、动态的调整,来达到更快的运行效率;
在编排作业时,你要清楚最多能给你多少内存空间让你缓存数据以及能缓存多少数据,本文主要对spark2.x进行内存分析;
JVM内存管理
既然spark是充分利用内存,那么我们先要理解内存划分,

在spark的角度来说数据的处理、代码的运行主要是对Java堆(Heap)空间的运用
- Java 堆 (Heap):存的是 Object 对象实例,对象实例中一般都包含了其数据成员以及与该对象对应类的信息,它会指向类的引用一个,不同线程肯定要操作这个对象;一个 JVM 实例在运行的时候只有一个 Heap 区域,而且该区域被所有的线程共享;补充说明:垃圾回收是回收堆 (heap) 中内容,堆上才有我们的对象
整体结构与代码剖析
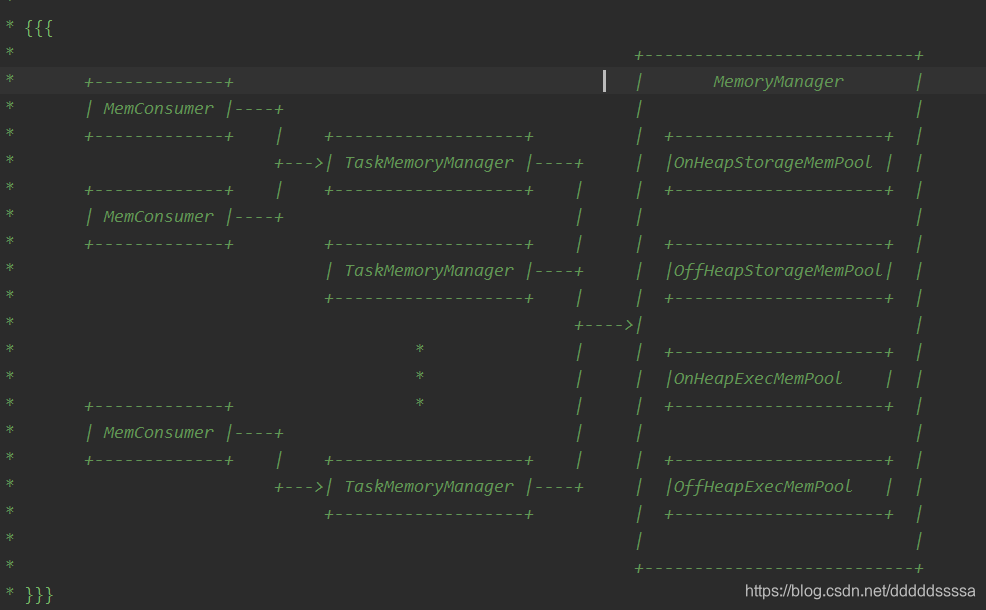
图片源于3.1.0-SNAPSHOT,与spark2.x的区别在与StorageMemPool的划分
其中:
- MemConsumer是TaskMemoryManager的客户端,对应于任务中的单个操作符和数据结构
- TaskMemoryManager是接收来自内存使用者的内存分配请求,并向使用者发出回调,以便在内存不足时触发溢出
-
MemoryPool用于跟踪存储和执行之间的内存划分并记账,
spark代码中创建对象占用内存的申请和释放都有jvm来完成,在申请后和释放前记录这些内存
StorageMemoryPool
/**
* Performs bookkeeping for managing an adjustable-size pool of memory that is used for storage
* (caching).
*
* @param lock a [[MemoryManager]] instance to synchronize on
* @param memoryMode the type of memory tracked by this pool (on- or off-heap)
*/
private[memory] class StorageMemoryPool(
lock: Object,
memoryMode: MemoryMode
) extends MemoryPool(lock) with Logging {...}
——-该类主要是用来给内存记账
其中几个重要方法:
① def acquireMemory(blockId: BlockId, numBytes: Long) = 主要是给Block获取内存
/**
* Acquire N bytes of memory to cache the given block, evicting existing ones if necessary.
*
* @return whether all N bytes were successfully granted.
*/
def acquireMemory(blockId: BlockId, numBytes: Long): Boolean = lock.synchronized {
val numBytesToFree = math.max(0, numBytes - memoryFree)
acquireMemory(blockId, numBytes, numBytesToFree)
}
/**
* Acquire N bytes of storage memory for the given block, evicting existing ones if necessary.
*
* @param blockId the ID of the block we are acquiring storage memory for
* @param numBytesToAcquire the size of this block
* @param numBytesToFree the amount of space to be freed through evicting blocks
* @return whether all N bytes were successfully granted.
*/
def acquireMemory(
blockId: BlockId,
numBytesToAcquire: Long,
numBytesToFree: Long): Boolean = lock.synchronized {
assert(numBytesToAcquire >= 0)
assert(numBytesToFree >= 0)
assert(memoryUsed <= poolSize)
if (numBytesToFree > 0) {
memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, memoryMode)
}
// NOTE: If the memory store evicts blocks, then those evictions will synchronously call
// back into this StorageMemoryPool in order to free memory. Therefore, these variables
// should have been updated.
val enoughMemory = numBytesToAcquire <= memoryFree
if (enoughMemory) {
_memoryUsed += numBytesToAcquire
}
enoughMemory
}
② def releaseMemory(size: Long):释放内存
def releaseMemory(size: Long): Unit = lock.synchronized {
if (size > _memoryUsed) {
logWarning(s"Attempted to release $size bytes of storage " +
s"memory when we only have ${_memoryUsed} bytes")
_memoryUsed = 0
} else {
_memoryUsed -= size
}
}
def releaseAllMemory(): Unit = lock.synchronized {
_memoryUsed = 0
}
当要释放的内存大于正在使用的,则把使用中的释放掉,_memoryUsed 置0,反之在正在使用的上面减去要释放的大小,简而言之就是_memoryUsed 做减法;
③ def freeSpaceToShrinkPool(spaceToFree: Long):按“spaceToFree”字节压缩存储内存池的大小,这个方法返回的是要收缩的数值,即得出该方法是在收缩存储池之前调用;
这里有个新词汇:
执行内存池 ---> 指的是执行数据的内存;
存储内存池 --- > 指的是存储数据的内存;
这两个池子大小可动态调整,这里先作为了解,下文会详细说道;
/**
* Free space to shrink the size of this storage memory pool by `spaceToFree` bytes.
* Note: this method doesn't actually reduce the pool size but relies on the caller to do so.
*
* @return number of bytes to be removed from the pool's capacity.
*/
def freeSpaceToShrinkPool(spaceToFree: Long): Long = lock.synchronized {
val spaceFreedByReleasingUnusedMemory = math.min(spaceToFree, memoryFree)
val remainingSpaceToFree = spaceToFree - spaceFreedByReleasingUnusedMemory
if (remainingSpaceToFree > 0) {
// If reclaiming free memory did not adequately shrink the pool, begin evicting blocks:
val spaceFreedByEviction =
memoryStore.evictBlocksToFreeSpace(None, remainingSpaceToFree, memoryMode)
// When a block is released, BlockManager.dropFromMemory() calls releaseMemory(), so we do
// not need to decrement _memoryUsed here. However, we do need to decrement the pool size.
spaceFreedByReleasingUnusedMemory + spaceFreedByEviction
} else {
spaceFreedByReleasingUnusedMemory
}
}
ExecutionMemoryPool
源码描述
/**
* Implements policies and bookkeeping for sharing an adjustable-sized pool of memory between tasks.
*
* Tries to ensure that each task gets a reasonable share of memory, instead of some task ramping up
* to a large amount first and then causing others to spill to disk repeatedly.
*
* If there are N tasks, it ensures that each task can acquire at least 1 / 2N of the memory
* before it has to spill, and at most 1 / N. Because N varies dynamically, we keep track of the
* set of active tasks and redo the calculations of 1 / 2N and 1 / N in waiting tasks whenever this
* set changes. This is all done by synchronizing access to mutable state and using wait() and
* notifyAll() to signal changes to callers. Prior to Spark 1.6, this arbitration of memory across
* tasks was performed by the ShuffleMemoryManager.
*
* @param lock a [[MemoryManager]] instance to synchronize on
* @param memoryMode the type of memory tracked by this pool (on- or off-heap)
*/
—— 该类简说就是在“控制”任务内存
其中有几个重要方法:
- memoryForTask:为了更好的使用内存与记录,spark内存维持着一个HashMap,taskId为key,内存使用为value;
/**
* Map from taskAttemptId -> memory consumption in bytes
*/
@GuardedBy("lock")
private val memoryForTask = new mutable.HashMap[Long, Long]()
override def memoryUsed: Long = lock.synchronized {
memoryForTask.values.sum
}
- private[memory] def acquireMemory(…):给任务分配内存
private[memory] def acquireMemory(
numBytes: Long, //表示申请内存的大小
taskAttemptId: Long, //taskId
maybeGrowPool: Long => Unit = (additionalSpaceNeeded: Long) => (),// 扩展此池所需的内存量
computeMaxPoolSize: () => Long = () => poolSize): Long = lock.synchronized {
assert(numBytes > 0, s"invalid number of bytes requested: $numBytes")
// TODO: clean up this clunky method signature
// Add this task to the taskMemory map just so we can keep an accurate count of the number
// of active tasks, to let other tasks ramp down their memory in calls to `acquireMemory`
if (!memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) = 0L
// This will later cause waiting tasks to wake up and check numTasks again
lock.notifyAll()
}
// Keep looping until we're either sure that we don't want to grant this request (because this
// task would have more than 1 / numActiveTasks of the memory) or we have enough free
// memory to give it (we always let each task get at least 1 / (2 * numActiveTasks)).
// TODO: simplify this to limit each task to its own slot
while (true) {
val numActiveTasks = memoryForTask.keys.size
val curMem = memoryForTask(taskAttemptId)
// In every iteration of this loop, we should first try to reclaim any borrowed execution
// space from storage. This is necessary because of the potential race condition where new
// storage blocks may steal the free execution memory that this task was waiting for.
maybeGrowPool(numBytes - memoryFree)
// Maximum size the pool would have after potentially growing the pool.
// This is used to compute the upper bound of how much memory each task can occupy. This
// must take into account potential free memory as well as the amount this pool currently
// occupies. Otherwise, we may run into SPARK-12155 where, in unified memory management,
// we did not take into account space that could have been freed by evicting cached blocks.
val maxPoolSize = computeMaxPoolSize()
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
// How much we can grant this task; keep its share within 0 <= X <= 1 / numActiveTasks
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
// Only give it as much memory as is free, which might be none if it reached 1 / numTasks
val toGrant = math.min(maxToGrant, memoryFree)
// We want to let each task get at least 1 / (2 * numActiveTasks) before blocking;
// if we can't give it this much now, wait for other tasks to free up memory
// (this happens if older tasks allocated lots of memory before N grew)
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free")
lock.wait()
} else {
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
}
0L // Never reached
}
代码语义:
①. 当task需要在Execution内存区域申请numBytes大小内存时,首先判断spark维护的HashMap中是否维护着该任务内存,如果没有,则以taskId作为key,内存使用置为0 作为value,添加到map中
②. 调用maybeGrowPool(numBytes – memoryFree),需要内存大小 – 空闲的内存 来判断 是否需要扩池
③. computeMaxPoolSize()计算该池最大内存,根据最大内存计算出每个任务可分配最大和最小内存,每个task任务可使用的内存应在1 / 2N ~ 1 / N 之间,N为task数量,并计算出该任务最大可分配内存(maxToGrant)和实际分配的内存(toGrant)
④. 如果 toGrant < numBytes && curMem + toGrant < minMemoryPerTask 则当前任务进行阻塞,直到其它任务释放内存,反之 则在 HashMap 里面将当前 Task 使用的内存加上 numBytes,然后返回;curMem 表示当前任务占用内存
- def releaseMemory(numBytes: Long, taskAttemptId: Long) 释放内存
def releaseMemory(numBytes: Long, taskAttemptId: Long): Unit = lock.synchronized {
val curMem = memoryForTask.getOrElse(taskAttemptId, 0L)
val memoryToFree = if (curMem < numBytes) {
logWarning(
s"Internal error: release called on $numBytes bytes but task only has $curMem bytes " +
s"of memory from the $poolName pool")
curMem
} else {
numBytes
}
if (memoryForTask.contains(taskAttemptId)) {
memoryForTask(taskAttemptId) -= memoryToFree
if (memoryForTask(taskAttemptId) <= 0) {
memoryForTask.remove(taskAttemptId)
}
}
lock.notifyAll() // Notify waiters in acquireMemory() that memory has been freed
}
/**
* Release all memory for the given task and mark it as inactive (e.g. when a task ends).
* @return the number of bytes freed.
*/
def releaseAllMemoryForTask(taskAttemptId: Long): Long = lock.synchronized {
val numBytesToFree = getMemoryUsageForTask(taskAttemptId)
releaseMemory(numBytesToFree, taskAttemptId)
numBytesToFree
}
这里没什么好说的,一个是释放某个任务的内存,一个是释放所有内存,释放所有内存会调用释放单个的
内存角度看划分
spark内存申请和释放是由jvm来完成,Executor的内存管理建立在JVM的内存管理之上,在堆内存使用上spark进行了更为详细的划分,引入堆外(Off-heap)内存,存在worker节点系统内存中

堆内内存
内存的大小由启动参数指定:–executor-memory / spark.executor.memory
spark对jvmHeap划分成如下四个部分:
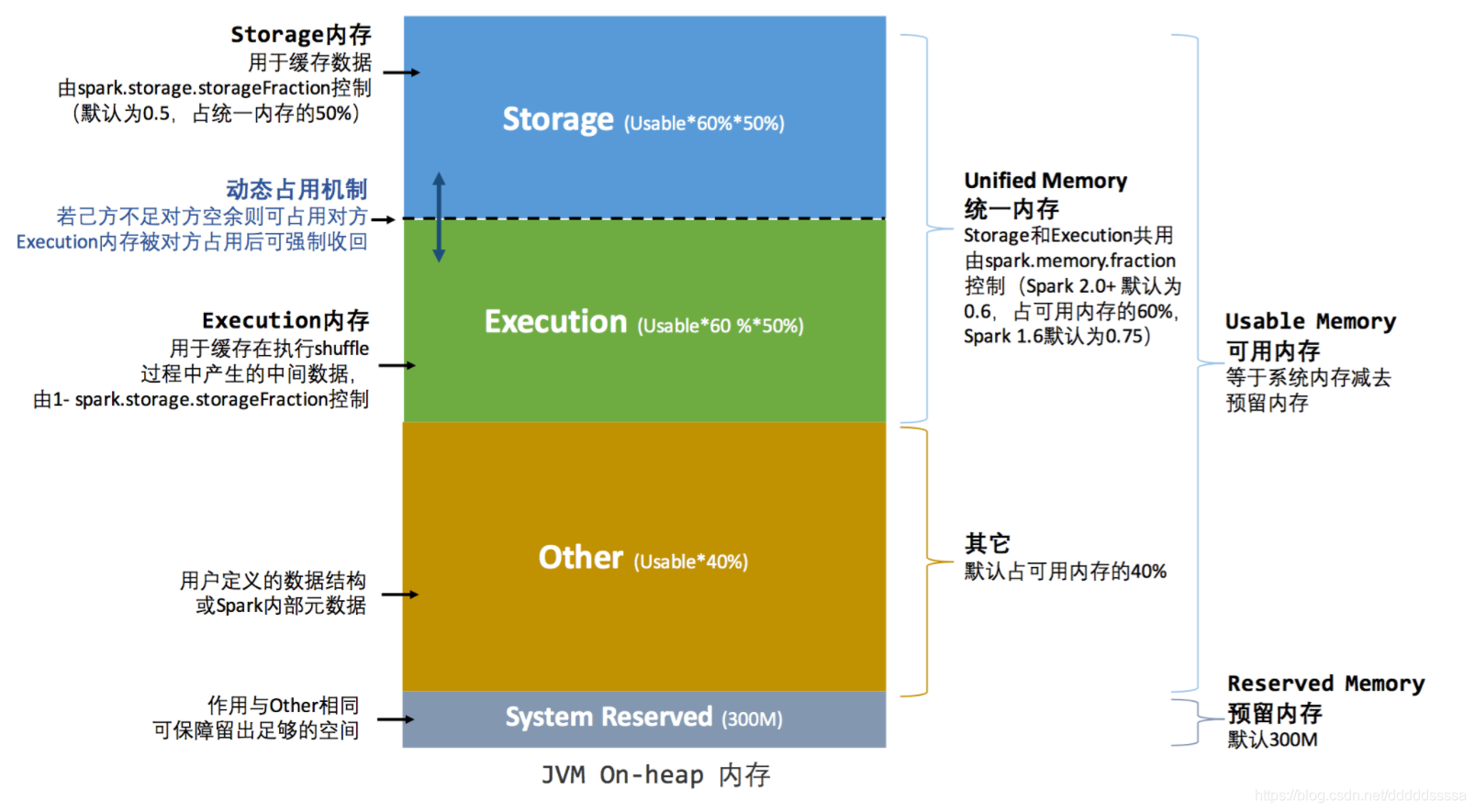
| 内存模块 | 说明 |
|---|---|
| Storage | 是要是用来储存,例如广播(Broadcast)、rdd缓存等caceh数据 |
| Execution | 主要用于存放 Shuffle、Join等 |
| other | 用户操作空间 |
| Reserved | 系统预留空间 |
- Reserved Memory 系统预留空间,默认为300M,这个数据一般是默认不变的;在系统运行时Java Heap空间至少为 reservedMemory * 1.5,也就是450M
private val RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 1024
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or ${config.DRIVER_MEMORY.key} in Spark configuration.")
}
- other:用户空间,spark程序中产生的临时数据与用户维护的一些数据结构所占的空间,空间大小为(Heap – Reserved Memory) * 40%,这样设计上的好处是用于操作等所需的空间与系统空间分开;假设 Executor 有 4G 的大小,那么在默认情况下 User Memory 大小是:(4G – 300MB) x 40% = 1518MB,也就是说一个 Stage 内部展开后 并行所有的Task 的算子在运行时最大的大小不能够超过 1518MB。例如使用 mapPartition 等,一个Executor并行 Task 内部所有算子使用的数据空间的大小如果大于 1518MB 的话,那么就会出现 OOM。
注意
:
spark-submit 提交任务时指定 –executor-memory 10g,systemMemory = Runtime.getRuntime.maxMemory 实际得到的内存大小要小于10g,因为内存分配池的堆部分分为 Eden,Survivor 和 Tenured 三部分空间,而这里面 Survivor 区域有两个,而这两个 Survivor 区域在任何时候我们只能用到其中一个,
ExecutorMemory = Eden + 2 * Survivor + Tenured
Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured
堆外内存
默认是不启用的,可通过如下参数:
- spark.memory.offHeap.enabled 启动
- spark.memory.offHeap.enabled 设置堆外内存大小,单位字节
引入目的:
为了提高Shuffle时排序的效率及优化内存空间,直接开辟在工作节点,存储经过序列化的二进制文件,堆外内存只分为Storage和Execution两个区域,

由于这种方式不经过 JVM 内存管理,所以可以避免频繁的 GC,这种内存申请的缺点是必须自己编写内存申请和释放的逻辑。
动态占用机制
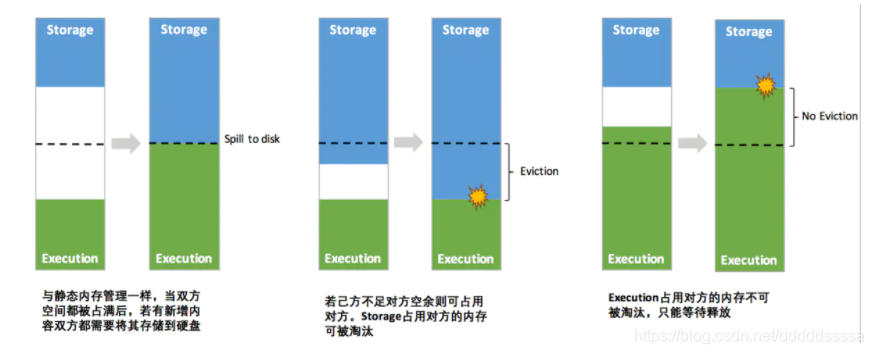
特别注意点:
spark释放内存时通过jvm来完成,当spark通知jvm要进行对象回收时,GC不一定就回立马回收,而spark内存维护任务与内存的hashmap则记录该空间已经释放,会导致实际可用内存 < spark内部维持的内存大小!!!