文章目录
-
励志
-
刷题指南
-
八月刷题录
-
-
1.Java引用传递与值传递
-
2.Java的4类流程控制语句
-
3.Java中的四类八种基本数据类型
-
4.静态变量
-
5.super
-
6. 数据类型取值范围
-
7.Servlet
-
8.JSON数据格式
-
9.垃圾回收
-
10.抽象类与接口
-
11.Sout(balabala相加)
-
12.import包访问
-
13.线程
-
14.运算符与操作符
-
15.内部类
-
16.异常
-
17.设计模式
-
18.IO流
-
19.数据类型转化
-
20.成员变量与局部变量
-
21.包(package)
-
22.类加载器
-
23.char字节溢出
-
24.构造器
-
25.关键字
-
26.正则表达式
-
27.集合
-
28.StringBuffer
-
29.Override(重写)与Overload(重载)
-
30.修饰符
-
31.函数
-
32.反射
-
33.Socket和ServerSocket
-
34.Java命令
-
35.事务隔离级别
-
-
九月刷题录
-
-
1.JDK 和 JRE 有什么区别?
-
2.== 和 equals 的区别是什么?
-
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
-
4.final 在 java 中有什么作用?
-
5.java 中的 Math.round(-1.5) 等于多少?
-
6.java 中操作字符串都有哪些类?它们之间有什么区别?
-
7. final、finally、finalize的区别?
-
8.什么是自动拆装箱?
-
9.为什么会出现4.0-3.6=0.40000001这种现象?
-
10.一个十进制的数在内存中是怎么存的?
-
11.为什么重写equals还要重写hashcode?
-
12.谈一下面向对象的”六原则一法则”。
-
13.面向对象的特征有哪些方面?
-
14.解释一下extends 和super 泛型限定符
-
15.解释一下类加载机制,双亲委派模型,好处是什么?
-
16.为什么集合类没有实现Cloneable和Serializable接口?
-
17.说明一下线程池有什么优势?
-
18.线程,进程,然后线程创建有很大开销,怎么优化?
-
19.介绍一下什么是生产者消费者模式?
-
20.多线程中的i++线程安全吗?请简述一下原因?
-
21.深拷贝 vs 浅拷贝
-
22.谈谈BigDecimal 的用处?
-
励志
日积月累,每天进步一点点!
刷题指南
地址:
链接直达
变强、变秃!
推荐书籍:

在线编译器:
地址:
链接直达
八月刷题录
1.Java引用传递与值传递
指出下列程序运行的结果:
public class Example{
String str=new String("tarena");
char[]ch={'a','b','c'};
public static void main(String args[]){
Example ex=new Example();
ex.change(ex.str,ex.ch);
System.out.print(ex.str+" and ");
System.out.print(ex.ch);
}
public void change(String str,char ch[]){
//引用类型变量,传递的是地址,属于引用传递。
str="test ok";
ch[0]='g';
}
}
解:
tarena and gbc
思:
String,char[] 都是引用类型,传递地址,会影响原变量值,但String是特殊引用类型,其值不可变,所以方法里面的字符串是栈上分配,随方法结束而消失。这里不可变实现原理:Java在内存中专门为String开辟了一个字符串常量池,用来锁定数据不被篡改。
String 与 char[] 的区别:
String内部是用char[]数组实现的,不过结尾不用\0
2.Java的4类流程控制语句
- 循环语句:while,for,do while
- 选择语句(分支语句):if,switch
- 跳转语句:break,continue
- 异常处理语句:try catch finally,throw
小试牛刀:
设m和都是int类型,那么以下for循环语句的执行情况是:
for (m = 0, n = -1; n = 0; m++, n++)
n++;
答案:循环结束判断条件不合法
for 循环的结束判定条件 是
boolean型
n = 0 是 int 类型
会有编译异常
3.Java中的四类八种基本数据类型
- 整数类型 byte short int long
- 浮点型 float double
- 逻辑型 boolean(只有两个值可取true false)
- 字符型 char
java.lang.String类是final类型的,因此不可以继承这个类、不能修改这个类。
String可不是基本数据类型
小试牛刀:
下面的Java赋值语句哪些是有错误的 ()
A.int i =1000;
B.float f = 45.0;
C.char s = ‘\u0639’;
D.Object o = ‘f’;
E.String s = “hello,world\0”;
F.Double d = 100;
答案:BF
解:
a:略
b:
小数如果不加 f 后缀,默认是double类型
。double转成float向下转换,意味着精度丢失,所以要进行强制类型转换。
c:是使用unicode表示的字符。
d:
‘f’ 字符会自动装箱成包装类,就可以向上转型成Object了。
f:整数默认是int类型,int类型不能转型为Double,最多通过自动装箱变为Integer但是 Integer与Double没有继承关系,也没法进行转型。所以
不同的数据类型不能自动装箱拆箱
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| boolean | Boolean |
| short | Short |
| char | Character |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
包装类是针对 基本数据类型 的。
String可不是什么包装类
4.静态变量
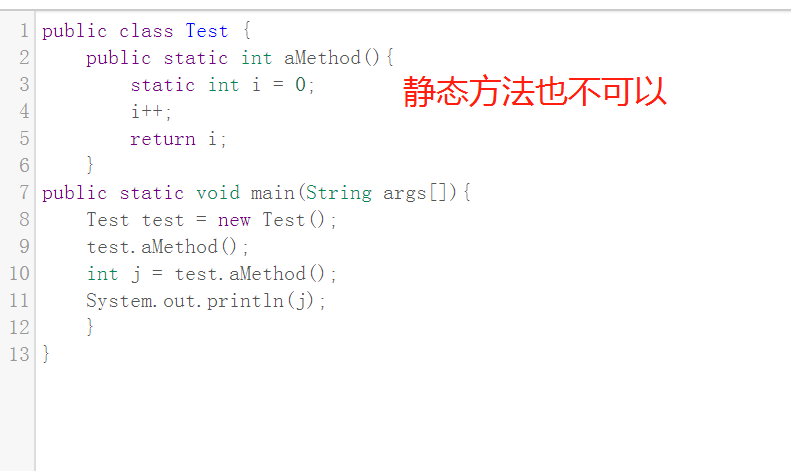
如下代码的输出结果是什么?
public class Test {
public int aMethod(){
static int i = 0;
i++;
return i;
}
public static void main(String args[]){
Test test = new Test();
test.aMethod();
int j = test.aMethod();
System.out.println(j);
}
}
解:
编译失败
思:
静态变量只能在类主体中定义,不能在方法中定义
5.super
【判断题】子类要调用继承自父类的方法,必须使用super关键字。(X)
- 1、子类构造函数调用父类构造函数用super
- 2、子类重写父类方法后,若想调用父类中被重写的方法,用super
- 3、未被重写的方法可以直接调用。
- 4、子类不能访问父类的私有方法
- 1.super可以访问父类中public、default、protected修饰的成员变量,不能直接访问private修饰的成员变量。格式为super.成员名称。
- 2.super可以访问父类中public、default、protected修饰的实例方法,不能访问private修饰的实例方法。格式为super.实例方法。
- 3.super可以访问父类中public、default、protected修饰的构造方法,不能访问private修饰的构造方法,格式为super(参数).
6. 数据类型取值范围
【判断题】字符型类型默认是0,取值范围是-2^15 —2^15-1 (X)
| 默认值 | 存储需求(字节) | 取值范围 | 示例 | |
|---|---|---|---|---|
| byte | 0 | 1 |
-2 7 — 2 7 -1 |
byte b=10; |
| char | ‘\u0000′ | 2 |
0—2 16 -1 |
char c=’c’ ; |
| short | 0 | 2 |
-2 15 —2 15 -1 |
short s=10; |
| int | 0 | 4 |
-2 31 —2 31 -1 |
int i=10; |
| long | 0 | 8 |
-2 63 —2 63 -1 |
long o=10L; |
| float | 0.0f | 4 |
-2 31 —2 31 -1 |
float f=10.0F |
| double | 0.0d | 8 |
-2 63 —2 63 -1 |
double d=10.0; |
| boolean | false | 1 | true\false | boolean flag=true; |
7.Servlet
如何获取ServletContext设置的参数值?
答案:
context.getInitParameter()
知识点:
- getParameter()是获取POST/GET传递的参数值;
- getInitParameter获取Tomcat的server.xml中设置Context的初始化参数
- getAttribute()是获取对象容器中的数据值;
- getRequestDispatcher是请求转发。
Web容器在
启动时
为每个Web应用创建一个ServletContext对象,ServletConfig对象中维护了ServletContext的引用,开发人员在编写servlet时,可以通过ServletConfig.getServletContext方法获得ServletContext对象。由于一个WEB应用中的
所有Servlet共享同一个ServletContext对象
,因此Servlet对象之间可以通过ServletContext对象来实现通讯。ServletContext对象通常也被称之为
context域对象
。
1.多个Servlet通过ServletContext对象实现数据共享。 在InitServlet的Service方法中利用ServletContext对象存入需要共享的数据
ServletContext context = this.getServletContext();
context.setAttribute("name", "haha");
在其它的Servlet中利用ServletContext对象获取共享的数据
ServletContext context = this.getServletContext();
String name = context.getAttribute("name");
2.获取WEB应用的初始化参数。
在DemoServlet的doPost方法中测试获取初始化参数的步骤如下:
ServletContext context = this.getServletContext();
String url = context.getInitParameter("url");
读取 HTTP 头(方法通过 HttpServletRequest 对象)
-
1)Cookie[] getCookies()
返回一个数组,包含客户端发送该请求的所有的 Cookie 对象。
-
2)Object getAttribute(String name)
以对象形式返回已命名属性的值,如果没有给定名称的属性存在,则返回 null。
-
3)String getHeader(String name)
以字符串形式返回指定的请求头的值。
Cookie也是头的一种
; -
4)String getParameter(String name)
以字符串形式返回请求参数的值,或者如果参数不存在则返回 null。
Servlet生命周期:
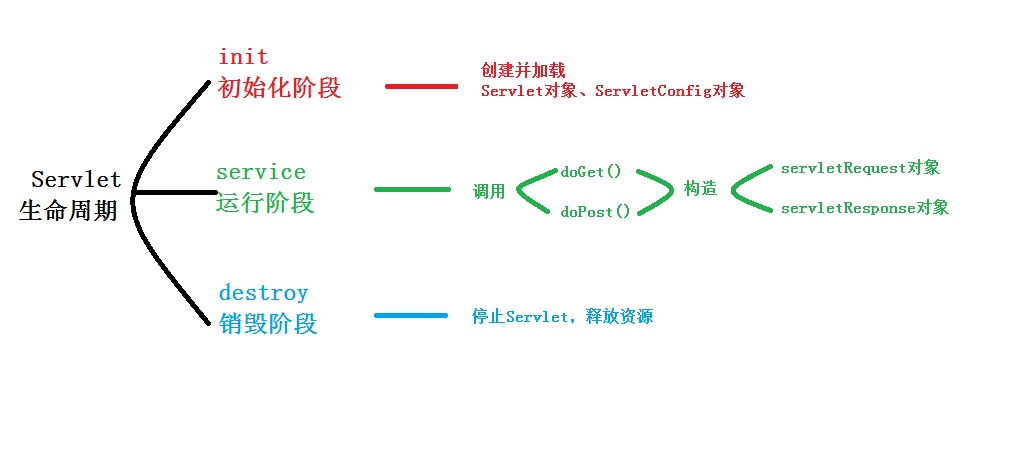
- init():仅执行一次,负责在装载Servlet时初始化Servlet对象
- service():核心方法,一般HttpServlet中会有get,post两种处理方式。在调用doGet和doPost方法时会构造servletRequest和servletResponse请求和响应对象作为参数。
- destory():在停止并且卸载Servlet时执行,负责释放资源
8.JSON数据格式
以下 json 格式数据,错误的是:
A.{company:4399}
B.{“company”:{“name”:[4399,4399,4399]}}
C.{[4399,4399,4399]}
D.{“company”:[4399,4399,4399]}
E.{“company”:{“name”:4399}}
答案:A C
JSON对象表示:
- {key1:value1,key2:value2,…}
- “‘名称/值’对”的无序集合
JSON数组表示:
- 值(value)的有序集合
- [value1,value2,value3,…]
9.垃圾回收
下面哪些描述是正确的:
public class Test {
public static class A {
private B ref;
public void setB(B b) {
ref = b;
}
}
public static Class B {
private A ref;
public void setA(A a) {
ref = a;
}
}
public static void main(String args[]) {
…
start();
….
}
public static void start() {
A a = new A();
B b = new B();
a.setB(b);
b = null;
a = null;
…
}
}
A.b = null执行后b可以被垃圾回收
B.a = null执行后b可以被垃圾回收
C.a = null执行后a可以被垃圾回收
D.a,b必须在整个程序结束后才能被垃圾回收
E.类A和类B在设计上有循环引用,会导致内存泄露
Fa, b 必须在start方法执行完毕才能被垃圾回收
答案:
先分析一下数据区:
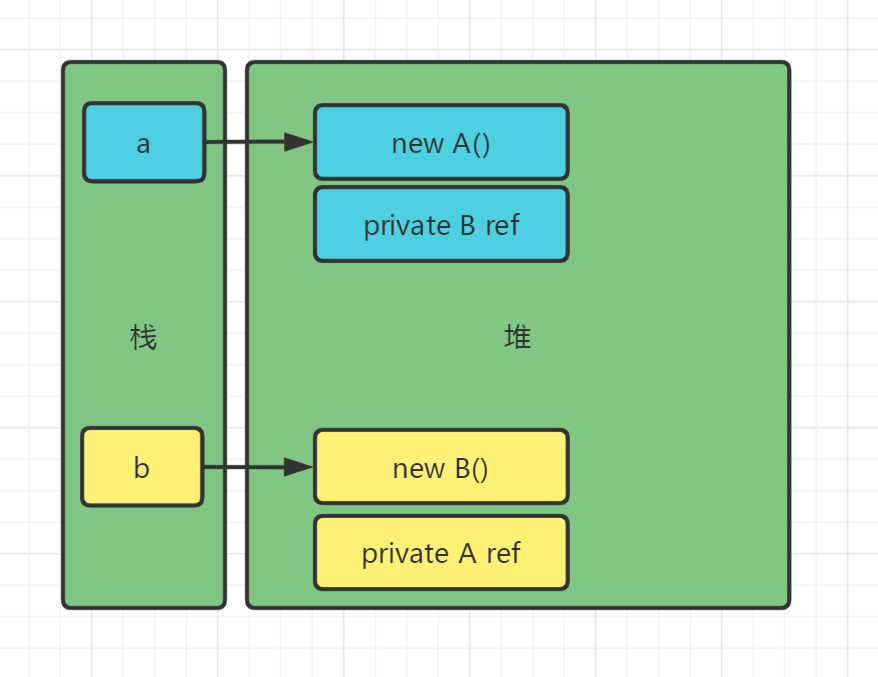
开始执行:

b=null,不能回收b
a=null,可以回收
相互引用并不会导致无法回收
题目:
下面关于垃圾收集的说法正确的是
A.一旦一个对象成为垃圾,就立刻被收集掉。
B.对象空间被收集掉之后,会执行该对象的finalize方法
C.finalize方法和C++的析构函数是完全一回事情
D.一个对象成为垃圾是因为不再有引用指着它,但是线程并非如此
答案:D
-
1、在java中,对象的内存在哪个时刻回收,取决于垃圾回收器何时运行。
-
2、一旦垃圾回收器准备好释放对象占用的存储空间,将
首先调用其finalize()方法
,并且在下一次垃圾回收动作发生时,才会真正的回收对象占用的内存(《java 编程思想》) -
3、在C++中,对象的内存在哪个时刻被回收,是可以确定的,在C++中,析构函数和资源的释放息息相关,能不能正确处理析构函数,关乎能否正确回收对象内存资源。
在java中,所有的对象,包括对象中包含的其他对象,它们所占的内存的回收都依靠垃圾回收器,因此不需要一个函数如C++析构函数那样来做必要的垃圾回收工作。当然存在本地方法时需要finalize()方法来清理本地对象。在《java编程思想》中提及,
finalize()方法的一个作用是用来回收“本地方法”中的本地对象
-
4.线程的释放是在run()方法结束以后,此时线程的引用可能并未释放。
有诗云:
以前我是堆,你是栈
你总是能精准的找到我,给我指明出路
后来有一天我明白了
我变成了栈,你却隐身堆海
我却找不到你了,空指针了
我不愿意如此,在下一轮full gc前
我找到了object家的finalize
又找到了你,这次我不会放手
在世界重启前,一边躲着 full gc 一边老去
10.抽象类与接口
在interface里面的变量都是
public static final (可省略)
,声明的时候要给变量
赋初始值
解释:
首先接口是提供一种统一的’协议’,而接口中的属性也属于’协议’中的成员.它们是公共的,静态的,最终的常量.相当于全局常量.
抽象类是不’完全’的类
,相当于是接口和具体类的一个中间层.即满足接口的抽象,也满足具体的实现.
如果接口可以定义变量,但是接口中的方法又都是抽象的,
在接口中无法通过行为来修改属性
。有的人会说,没有关系,可以通过实现接口的对象的行为来修改接口中的属性。这当然没有问题,但是考虑这样的情况。如果接口A中有一个public访问权限的静态变量a。按照Java的语义,我们可以不通过实现接口的对象来访问变量a,通过A.a = xxx;就可以改变接口中的变量a的值了。正如抽象类中是可以这样做的,那么实现接口A的所有对象也都会自动拥有这一改变后的a的值了,也就是说
一个地方改变了a,所有这些对象中a的值也都跟着变了
。这和抽象类有什么区别呢,怎么体现接口更高的抽象级别呢,怎么体现接口提供的统一的协议呢,那还要接口这种抽象来做什么呢?所以接口中不能出现变量,如果有变量,就和接口提供的统一的抽象这种思想是抵触的。所以接口中的属性必然是常量,
只能读不能改
,这样才能为实现接口的对象提供一个统一的属性。
通俗的讲,你认为是要变化的东西,就放在你自己的实现中,不能放在接口中去,
接口只是对一类事物的属性和行为更高层次的抽象
。对修改关闭,对扩展(不同的实现implements)开放,接口是对开闭原则的一种体现。
题目:抽象类和接口的区别,以下说法错误的是:
A.接口是公开的,里面不能有私有的方法或变量,是用于让别人使用的,而抽象类是可以有私有方法或私有变量的。
B.abstract class 在 Java 语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface,实现多重继承。接口还有标识(里面没有任何方法,如Remote接口)和数据共享(里面的变量全是常量)的作用。
C.在abstract class 中可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是 static final的,不过在 interface中一般不定义数据成员),所有的成员方法默认都是 public abstract 类型的。
D.abstract class和interface所反映出的设计理念不同。其实abstract class表示的是”has-a”关系,interface表示的是”is-a”关系。
答案:ACD
抽象类
:在Java中
被abstract关键字修饰
的类称为抽象类,被abstract关键字修饰的方法称为抽象方法,抽象方法只有方法的声明,没有方法体。
抽象类的特点:
-
a、抽象类不能被实例化
只能被继承
; -
b、包含抽象方法的一定是抽象类,但是
抽象类不一定含有抽象方法
; - c、抽象类中的抽象方法的修饰符只能为public或者protected,默认为public;
-
d、一个子类继承一个抽象类,则
子类必须实现父类抽象方法否则子类也必须定义为抽象类
; -
e、抽象类可以包含属性、方法、构造方法,但是
构造方法不能用于实例化
,主要用途是被
子类调用
。
接口
:Java中接口使用
interface关键字修饰
,特点为:
- a、接口可以包含变量、方法;变量被隐式指定为public static final,方法被隐式指定为public abstract(JDK1.8之前);
-
b、
接口支持多继承
,即一个接口可以extends多个接口,间接的解决了Java中类的单继承问题; -
c、一个类可以
实现多个接口
- d、JDK1.8中对接口增加了新的特性:
(1)默认方法(default method):
JDK1.8允许给接口添加非抽象的方法实现
,但必须使用default关键字修饰;定义了default的方法可以不被实现子类所实现,但只能被实现子类的对象调用;如果子类实现了多个接口,并且这些接口包含一样的默认方法,则子类必须重写默认方法;
(2)静态方法(static method):JDK1.8中允许使用static关键字修饰方法,并提供实现,称为接口静态方法。接口静态方法只能通过接口调用(接口名.静态方法名)。
注意:jdk1.9是允许接口中出现private修饰的默认方法和静态方法。
解析:
A:jdk1.9是允许接口中出现private修饰的默认方法和静态方法,A错误;抽象类可以有私有的变量和方法。
B:正确
C:抽象类可以有抽象和非抽象的方法;jdk1.8接口中可以有默认方法和静态方法,C错误。
D:
强调继承关系,is-a
,如果A is-a B,那么B就是A的父类;
代表组合关系,like-a
,
接口
,如果A like a B,那么B就是A的接口。 ;
强调聚合关系,has-a
,如果A has a B,那么B就是A的组成部分(属性)。
D项错误。
小小坑题:
下面选项中,哪些是interface中合法方法定义?()
A.public void main(String [] args);
B.private int getSum();
C.boolean setFlag(Boolean [] test);
D.public float get(int x);
答案:
ACD
A项没有static修饰符,可以作为普通的方法。
java8中,
1、接口可以有非抽象的静态方法;
2、可以定义默认方法,此方法有方法体,子类可以重写,也可以不。
【判断题】Java中的接口(interface)也继承了Object类(X)
如果interface继承自Object,那么interface必然是一个class。java中接口跟类是两个并行的概念
11.Sout(balabala相加)
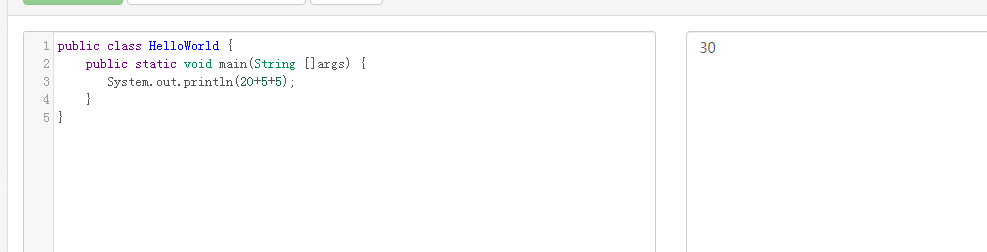
如果int x=20, y=5,则语句System.out.println(x+y +””+(x+y)+y); 的输出结果是:
答案:25255
1.括号优先
2.从左往右
3.字符串 + 数字 与 数字 + 字符串 都按字符串相加

12.import包访问
有一个源代码,只包含import java.util.* ; 这一个import语句,下面叙述正确的是? ( )
A.可以访问java/util目录下及其子目录下的所有类
B.能访问java/util目录下的所有类,不能访问java/util子目录下的所有类
答案:B
思:导入java.util.*不能读取其子目录的类,因为如果
java.util里面有个a类
,
java.util.regex里面也有个a类
,我们若是要调用a类的方法或属性时,应该使用哪个a类呢。
13.线程
假设 a 是一个由线程 1 和线程 2 共享的初始值为 0 的全局变量,则线程 1 和线程 2 同时执行下面的代码,最终 a 的结果:
boolean isOdd = false;
for(int i=1;i<=2;++i){
if(i%2==1)isOdd = true;
else isOdd = false;
a+=i*(isOdd?1:-1);
}
不管怎样线程对a的操作就是+1后-2
1.线程1执行完再线程2执行,1-2+1-2=-2(线程不并发)
2.线程1和2同时+1,再-2不同时,1-2-2=-3(线程部分并发)
3.线程1和2不同时+1,同时-2,1+1-2=0(线程部分并发)
4.线程1和2既同时+1又同时-2,1-2=-1)(线程并发)
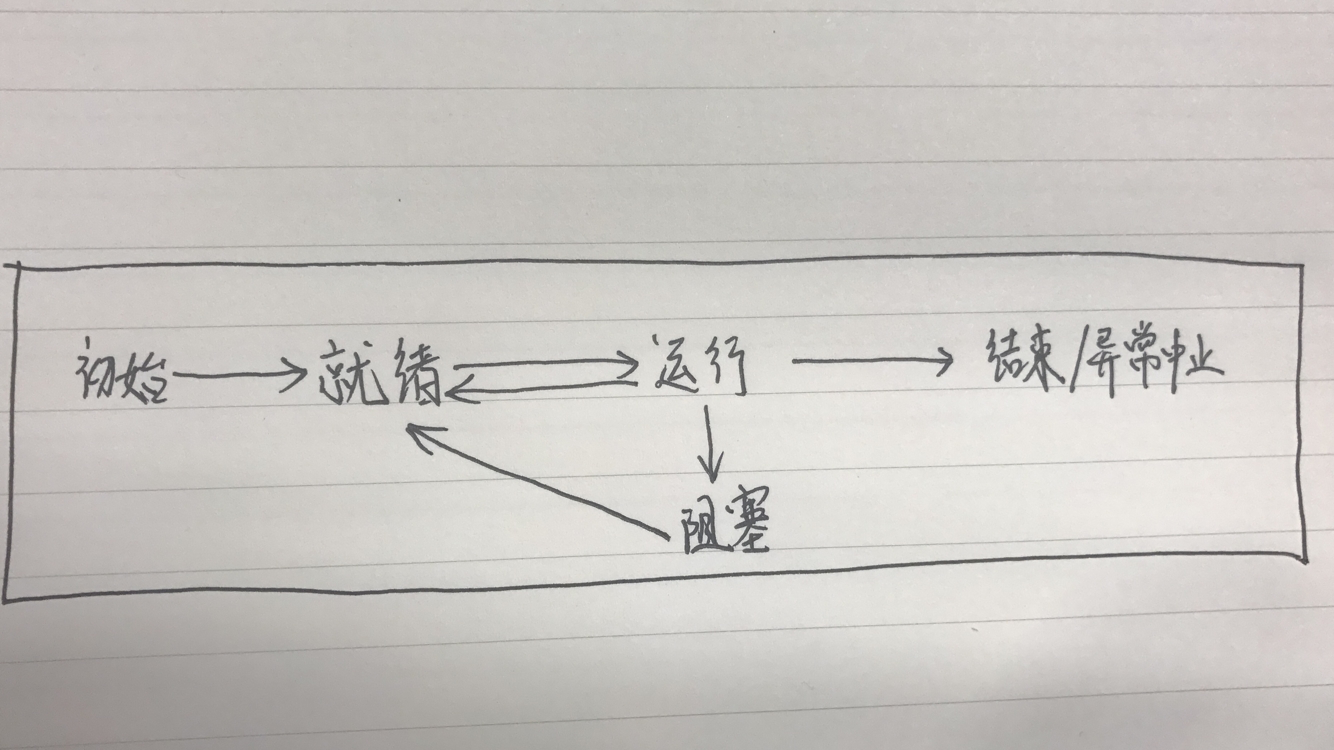
线程状态转化:

简化手写版:
稍微简版:

完整版:
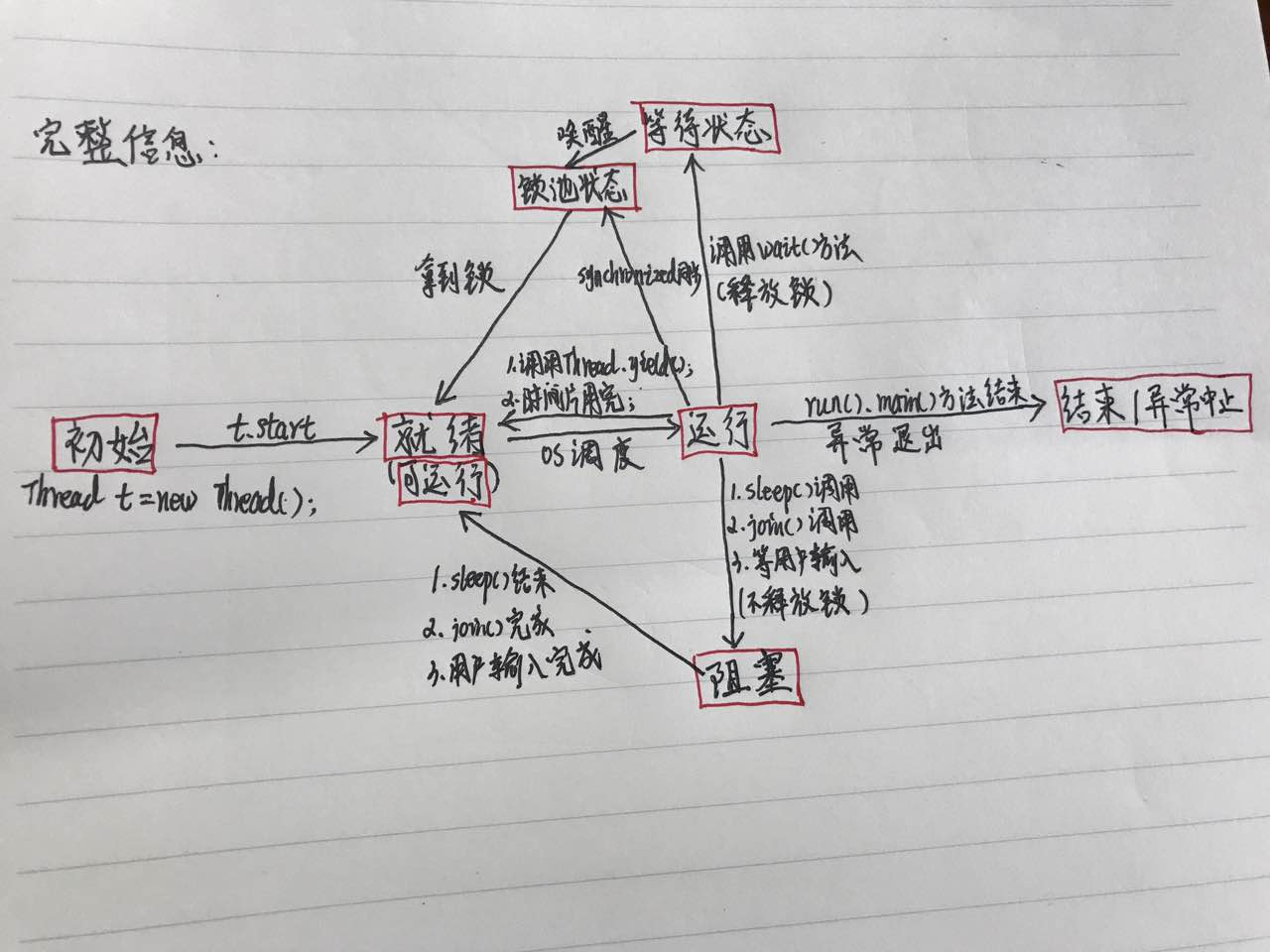
补充:
wait()、sleep()、yield():
1)wait()是Object的
实例
方法,在synchronized同步环境使用,作用当前对象,会释放对象锁,需要被唤醒。
2)sleep()是Thread的
静态
方法,不用在同步环境使用,作用当前线程,不释放锁。
不考虑线程的优先级
。调用后进入
阻塞
状态。
3)yield()是Thread的
静态
方法,作用当前线程,释放当前线程持有的CPU资源,将CPU让给优先级
不低于自己
的线程用,调用后进入
就绪
状态。
sleep()方法比yield()方法(跟操作系统CPU调度相关)具有更好的可移植性。
线程同步synchronized:
执行如下程序,输出结果是
class Test
{
private int data;
int result = 0;
public void m()
{
result += 2;
data += 2;
System.out.print(result + " " + data);
}
}
class ThreadExample extends Thread
{
private Test mv;
public ThreadExample(Test mv)
{
this.mv = mv;
}
public void run()
{
synchronized(mv)
{
mv.m();
}
}
}
class ThreadTest
{
public static void main(String args[])
{
Test mv = new Test();
Thread t1 = new ThreadExample(mv);
Thread t2 = new ThreadExample(mv);
Thread t3 = new ThreadExample(mv);
t1.start();
t2.start();
t3.start();
}
}
答案:2 24 46 6
解:
Test mv =newTest()声明并初始化对data赋默认值
使用synchronized关键字加同步锁线程依次操作m()
t1.start();使得result=2,data=2,输出即为2 2
t2.start();使得result=4,data=4,输出即为4 4
t3.start();使得result=6,data=6,输出即为6 6
System.out.print(result +” “+ data);是
print()方法不会换行
,输出结果为2 24 46 6
问题:
Java的Daemon线程,setDaemon( )设置必须要?
答案:
setDaemon()方法必须在线程
启动之前
调用。
关于Java的daemon线程
1.首先我们必须清楚的认识到java的线程分为两类:
用户线程和daemon线程
-
A.用户线程:用户线程可以简单的理解为用户定义的线程,当然包括main线程(以前我
错误的认为main线程也是一个daemon线程
,但慢慢的发现原来main线程不是,因为如果我再main线程中创建一个用户线程,并且打出日志,我们会发现这样一个问题,main线程运行结束了,但是我们的线程任然在运行). -
B.daemon线程: daemon线程是为我们创建的用户线程提供服务的线程,比如说jvm的GC等等,这样的线程有一个非常明显的特征:
当用户线程运行结束的时候,daemon线程将会自动退出.(由此我们可以推出下面关于daemon线程的几条基本特点)
2. daemon 线程的特点:
-
A.守护线程创建的过程中需要
先调用setDaemon方法
进行设置,然后
再启动线程
.否则会报出IllegalThreadStateException异常. -
B.由于daemon线程的终止条件是当前是否存在用户线程,所以我们不能指派daemon线程来进行一些业务操作,而
只能服务用户线程
. -
C.daemon线程创建的
子线程仍然是daemon线程
.
A特点分析:
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(new Thread2());
thread1.start();
thread1.setDaemon(true);
Thread.sleep(10);
System.out.println("用户线程退出");
}
}
class Thread2 implements Runnable{
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println("1+1="+(1+1));
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行结果:
Exception in thread "main" java.lang.IllegalThreadStateException
at java.lang.Thread.setDaemon(Thread.java:1352)
at ThreadTest.main(ThreadTest.java:5)
1+1=2
通过上面的例子我们可以发现,我们并
不能动态的更改线程为daemon线程
,源码解释如下:
java源码:
public final void setDaemon(boolean on) {
checkAccess();
if (isAlive()) {
throw new IllegalThreadStateException();
}
daemon = on;
}
我们可以发现,在源码中如果我们的线程状态是alive的,我们的程序就会抛出异常.
B特点分析:
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(new Thread2());
thread1.setDaemon(true);
thread1.start();
Thread.sleep(10);
System.out.println("用户线程退出");
}
}
class Thread2 implements Runnable{
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println("1+1="+(1+1));
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
运行结果: 用户线程退出
通过上面的例子我们可以看到,我们在daemon线程中进行相关的计算工作,但是我们并没有获取计算结果,因为用户线程main已经运行结束.
C特点分析:
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Thread2());
thread.setDaemon(true);
thread.start();
System.out.println("Thread是否是daemon线程"+thread.isDaemon());
Thread.sleep(100);
System.out.println("用户线程退出");
}
}
class Thread2 implements Runnable{
@Override
public void run() {
Thread1 thread1 = new Thread1();
thread1.start();
System.out.println("Thread1是否是daemon线程"+thread1.isDaemon());
}
}
class Thread1 extends Thread{
public void run () {
System.out.println("dosomething");
}
}
运行结果:
Thread是否是daemon线程true
Thread1是否是daemon线程true
dosomething
用户线程退出
源码解析:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
......
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
......
}
在进行Thread初始化的时候,会获取父进程的isDaemon来复制子进程的daemon.
线程的私有、共享
-
线程私有区域:程序计数器、虚拟机栈、本地方法栈
-
线程共享区域:堆、方法区
14.运算符与操作符

问题:下面代码输出结果是?
int i = 5;
int j = 10;
System.out.println(i + ~j);
答案:
-6
计算机本身储存的就是补码。所以我们都换成补码进行计算
10的补码就是10的原码:0000 0000 0000 1010
~10的补码就是:1111 1111 1111 0101
~10的反码就是:1111 1111 1111 0100——补码减1
~10的原码就是:1000 0000 0000 1011——反码取反:这个才是正常二进制数,换算为整数为-11
原码才可以对应为正常的整数,补码只有转换为原码才能被正常人类识别。
三元操作符的坑:
题目:
以下JAVA程序的运行结果是什么( )
public static void main(String[] args) {
Object o1 = true ? new Integer(1) : new Double(2.0);
Object o2;
if (true) {
o2 = new Integer(1);
} else {
o2 = new Double(2.0);
}
System.out.print(o1);
System.out.print(" ");
System.out.print(o2);
}
错解:1 1
正解:1.0 1
三元操作符类型的转换规则:
1.若两个操作数不可转换,则不做转换,返回值为Object类型
2.若两个操作数是明确类型的表达式(比如变量),则按照正常的二进制数字来转换,int类型转换为long类型,long类型转换为float类型等。
3.若两个操作数中有一个是数字S,另外一个是表达式,且其类型标示为T,那么,若数字S在T的范围内,则转换为T类型;若S超出了T类型的范围,则T转换为S类型。
4.若两个操作数都是直接量数字,则返回值类型为范围较大者
小小坑题:
count = 0;
count = count++
正解:count = 0
错解:count = 1
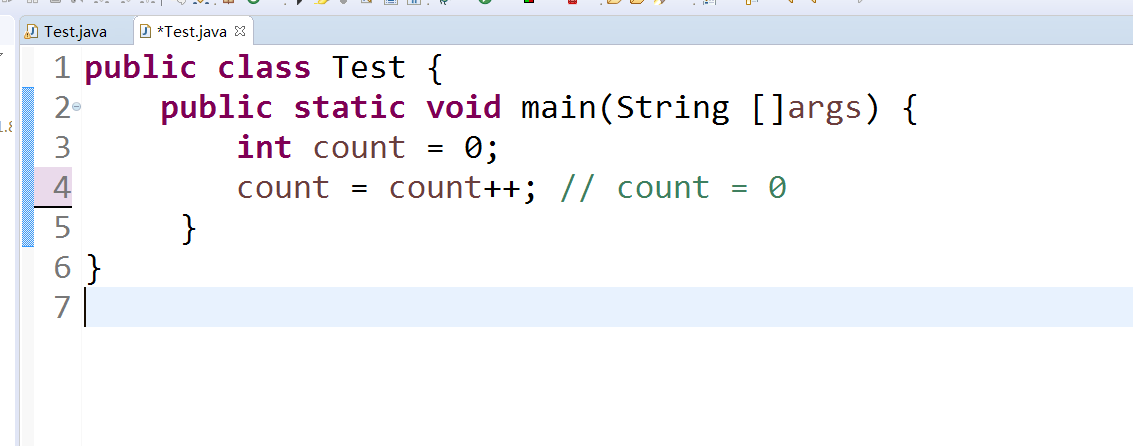
编译后的字节码如下:

- 0: iconst_0 将int型0推送至栈顶
- 1: istore_1 将栈顶int型数值存入第二个本地变量,count为0
- 2: iload_1 将第二个int型本地变量推送至栈顶,栈顶为0,本地变量count为0
- 3: iinc 1, 1 将指定int型变量增加指定值(如i++,i–、i+=2等),本地变量自增count变为1,栈顶为0
- 6: istore_1 将栈顶int型数值存入第二个本地变量 ,栈顶0出栈被本地变量储存,本地变量变为0.
- 7: return
首先0和1是int count=0;这句代码的指令 将0入栈然后出栈存入本地变量中。return是main方法返回void的指令。
所以真正需要关注的是iload_1、iinc 1 1、istore_1 这三条指令。而iinc指令的自增操作是在本地变量中增加,而不是在操作数栈中增加,所以导致了最终结果是0。
15.内部类
import EnclosingOne.InsideOne
class Enclosingone{
public class InsideOne {}
}
public class inertest{
public static void main(string[]args){
EnclosingOne eo = new EnclosingOne();
//insert code here
}
}
Which statement at line 8 constructs an instance of the inner class?
A.InsideOne ei=eo.new InsideOne();
B.eo.InsideOne ei=eo.new InsideOne();
C.InsideOne ei=EnclosingOne.new InsideOne();
D.EnclosingOne.InsideOne ei=eo.new InsideOne();
答案:AD
思:
public class Enclosingone {
//非静态内部类
public class InsideOne {}
//静态内部类
public static class InsideTwo{}
}
class Mytest02{
public static void main(String args []){
//非静态内部类对象
Enclosingone.InsideOne obj1 = new Enclosingone().new InsideOne();
//静态内部类对象
Enclosingone.InsideTwo obj2 = new Enclosingone.InsideTwo();
}
}
内部类小结:
内部类一般来说共分为4种:常规内部类、静态内部类、局部内部类、匿名内部类
-
常规内部类:
常规内部类
没有用static修饰
且定义在
在外部类类体中
。1.常规内部类中的方法可以直接使用外部类的实例变量和实例方法。
2.在常规内部类中可以直接用内部类创建对象 -
静态内部类:
与类的其他成员相似,可以用static修饰内部类,这样的类称为静态内部类。静态内部类与静态内部方法相似,
只能访问外部类的static成员
,不能直接访问外部类的实例变量,与实例方法,只有通过对象引用才能访问。由于
static内部类不具有任何对外部类实例的引用
,因此static内部类中不能使用this关键字来访问外部类中的实例成员,但是可以访问外部类中的static成员。 -
局部内部类:
在方法体或语句块(包括方法、构造方法、局部块或静态初始化块)内部定义的类成为局部内部类。
局部内部类
不能加任何访问修饰符
,因为它只对局部块有效。
1).局部内部类只在方法体中有效,就想定义的局部变量一样,在定义的方法体外不能创建局部内部类的对象
2).在方法内部定义类时,应注意以下问题:
①.方法定义局部内部类同方法定义局部变量一样,
不能使用private、protected、public等访问修饰说明符修饰,也不能使用static修饰
,但可以使用final和 abstract修饰
②.方法中的内部类可以访问外部类成员。对于方法的参数和局部变量,必须有final修饰才可以访问。
③.static方法中定义的内部类可以访问外部类定义的static成员 -
匿名内部类:
定义类的最终目的是创建一个类的实例,但是如果某个类的实例只是用一次,则可以将类的定义与类的创建,放到与一起完成,或者说在
定义类的同时就创建一个类
,以这种方法定义的没有名字的类成为匿名内部类。
声明和构造匿名内部类的一般格式如下:new ClassOrInterfaceName(){ /*类体*/ }1.匿名内部类可以继承一个类
或
实现一个接口,这里的ClassOrInterfaceName是匿名内部类所继承的类名或实现的接口名。但匿名内部类不能同时实现一个接口和继承一个类,也不能实现多个接口。如果实现了一个接口,该类是Object类的直接子类,匿名类继承一个类或实现一个接口,
不需要extends和implements关键字
。
2.由于匿名内部类没有名称,所以类体中
不能定义构造方法
,由于不知道类名也不能使用关键字来创建该类的实例。实际上匿名内部类的定义、构造、和第一次使用都发生在同样一个地方。此外,上式是一个表达式,返回的是一个对象的引用,所以可以直接使用或将其复制给一个对象变量。例:TypeName obj=new Name(){ /*此处为类体*/ };同样,也可以将构造的对象作为调用的参数。例:
someMethod(new Name(){ /*此处为类体*/ });
图总结:

简要版:

16.异常
Java异常都继承Throwable,Throwable子类有Error和Exception,其中Exception又分为
运行时异常和编译时异常
。编译时异常是
未雨绸缪
性质的异常,是防范,
需要显示处理(我们应该捕获或者抛出,不是由由java虚拟机自动进行处理)
。运行时异常是程序员问题造成(往往编译正常,逻辑异常),并不强制进行显示处理。

题目:在有除法存在的代码处,为了防止分母为零,必须抛出并捕获异常(X)
分母为0是运行时异常,jvm帮我们捕获,代码无需显示捕获。
异常处理:
Java语言中的异常处理包括
声明异常、抛出异常、捕获异常和处理异常
四个环节。
throw用于抛出异常。
throws关键字可以在方法上声明该方法要抛出的异常,然后在方法内部通过throw抛出异常对象。
try是用于检测被包住的语句块是否出现异常,如果有异常,则抛出异常,并执行catch语句。
cacth用于捕获从try中抛出的异常并作出处理。
finally语句块是不管有没有出现异常都要执行的内容。
try return finally:
题目:
在try的括号里面有return一个值,那在哪里执行finally里的代码?
A.不执行finally代码
B.return前执行
C.return后执行
答案:B
解释:
下面的关键内容来自:
https://www.ibm.com/developerworks/cn/java/j-lo-finally/
我们先来分析一波这两个例子
清单 5.
public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
try {
return 0;
} finally {
return 1;
}
}
}
清单 5 的执行结果:
return value of getValue(): 1
清单 6.
public class Test {
public static void main(String[] args) {
System.out.println("return value of getValue(): " + getValue());
}
public static int getValue() {
int i = 1;
try {
return i;
} finally {
i++;
}
}
}
清单 6 的执行结果:
return value of getValue(): 1
利用我们上面分析得出的结论:
finally 语句块是在 try 或者 catch 中的 return 语句之前执行的。
由此,可以轻松的理解清单 5 的执行结果是 1。因为 finally 中的 return 1;语句要在 try 中的 return 0;语句之前执行,那么 finally 中的 return 1;语句执行后,把程序的控制权转交给了它的调用者 main()函数,并且返回值为 1。
那为什么清单 6 的返回值不是 2,而是 1 呢?按照清单 5 的分析逻辑,finally 中的 i++;语句应该在 try 中的 return i;之前执行啊? i 的初始值为 1,那么执行 i++;之后为 2,再执行 return i;那不就应该是 2 吗?怎么变成 1 了呢?
关于 Java 虚拟机是如何编译 finally 语句块的问题,参考《 The JavaTM Virtual Machine Specification, Second Edition 》中 7.13 节 Compiling finally,那里详细介绍了 Java 虚拟机是如何编译 finally 语句块。实际上,Java 虚拟机会
把 finally 语句块作为 subroutine
(对于这个 subroutine 不知该如何翻译为好,干脆就不翻译了,免得产生歧义和误解。)直接插入到 try 语句块或者 catch 语句块的控制转移语句之前。但是,还有另外一个不可忽视的因素,那就是
在执行 subroutine(也就是 finally 语句块)之前,try 或者 catch 语句块会保留其返回值到本地变量表(Local Variable Table)中
。待 subroutine 执行完毕之后,再恢复保留的返回值到操作数栈中,然后通过 return 或者 throw 语句将其返回给该方法的调用者(invoker)。请注意,前文中我们曾经提到过 return、throw 和 break、continue 的区别,对于这条规则(保留返回值),只适用于 return 和 throw 语句,不适用于 break 和 continue 语句,因为它们根本就没有返回值。
我们来分析一下清单 6 的字节码(byte-code):
Compiled from "Test.java"
public class Test extends java.lang.Object{
public Test();
Code:
0: aload_0
1:invokespecial#1; //Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
Code:
0: getstatic #2; //Field java/lang/System.out:Ljava/io/PrintStream;
3: new #3; //class java/lang/StringBuilder
6: dup
7: invokespecial #4; //Method java/lang/StringBuilder."<init>":()V
10: ldc #5; //String return value of getValue():
12: invokevirtual
#6; //Method java/lang/StringBuilder.append:(
Ljava/lang/String;)Ljava/lang/StringBuilder;
15: invokestatic #7; //Method getValue:()I
18: invokevirtual
#8; //Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;
21: invokevirtual
#9; //Method java/lang/StringBuilder.toString:()Ljava/lang/String;
24: invokevirtual #10; //Method java/io/PrintStream.println:(Ljava/lang/String;)V
27: return
public static int getValue();
Code:
0: iconst_1
1: istore_0
2: iload_0
3: istore_1
4: iinc 0, 1
7: iload_1
8: ireturn
9: astore_2
10: iinc 0, 1
13: aload_2
14: athrow
Exception table:
from to target type
2 4 9 any
9 10 9 any
}
对于 Test()构造方法与 main()方法,在这里,我们不做过多解释。让我们来分析一下 getValue()方法的执行。在这之前,先让我把 getValue()中用到的虚拟机指令解释一下.
1. iconst_
Description: Push the int constant (-1, 0, 1, 2, 3, 4 or 5) onto the operand stack.
Forms: iconst_m1 = 2 (0x2) iconst_0 = 3 (0x3) iconst_1 = 4 (0x4)
iconst_2 = 5 (0x5) iconst_3 = 6 (0x6) iconst_4 = 7 (0x7) iconst_5 = 8 (0x8)
2. istore_
Description: Store int into local variable. The must be an index into the
local variable array of the current frame.
Forms: istore_0 = 59 (0x3b) istore_1 = 60 (0x3c) istore_2 = 61 (0x3d)
istore_3 = 62 (0x3e)
3. iload_
Description: Load int from local variable. The must be an index into the
local variable array of the current frame.
Forms: iload_0 = 26 (0x1a) iload_1 = 27 (0x1b) iload_2 = 28 (0x1c) iload_3 = 29 (0x1d)
4. iinc index, const
Description: Increment local variable by constant. The index is an unsigned byte that
must be an index into the local variable array of the current frame. The const is an
immediate signed byte. The local variable at index must contain an int. The value
const is first sign-extended to an int, and then the local variable at index is
incremented by that amount.
Forms: iinc = 132 (0x84)
Format:
iinc
index
const
- ireturn
Description: Return int from method.
Forms: ireturn = 172 (0xac)
- astore_
Description: Store reference into local variable. The must be an index into the
local variable array of the current frame.
Forms: astore_0 = 75 (0x4b) astore_1 = 76 (0x4c) astore_2 =77 (0x4d) astore_3 =78 (0x4e)
- aload_
Description: Load reference from local variable. The must be an index into the
local variable array of the current frame.
Forms: aload_0 = 42 (0x2a) aload_1 = 43 (0x2b) aload_2 = 44 (0x2c) aload_3 = 45 (0x2d)
- athrow
Description: Throw exception or error.
Forms: athrow = 191 (0xbf)
有了以上的 Java 虚拟机指令,我们来分析一下其执行顺序:分为
正常执行(没有 exception)和异常执行(有 exception)
两种情况。
-
正常执行
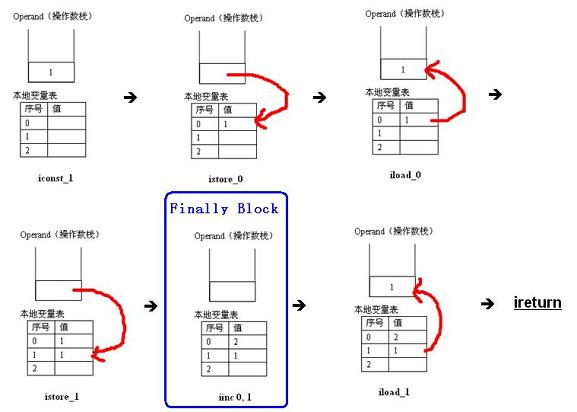
由上图,我们可以清晰的看出,在 finally 语句块(iinc 0, 1)执行之前,getValue()方法保存了其返回值(1)到本地表量表中 1 的位置,完成这个任务的指令是 istore_1;然后执行 finally 语句块(iinc 0, 1),finally 语句块把位于 0 这个位置的本地变量表中的值加 1,变成 2;待 finally 语句块执行完毕之后,把本地表量表中 1 的位置上值恢复到操作数栈(iload_1),最后执行 ireturn 指令把当前操作数栈中的值(1)返回给其调用者(main)。这就是为什么清单 6 的执行结果是 1,而不是 2 的原因。再让我们来看看异常执行的情况。是不是有人会问,你的清单 6 中都没有 catch 语句,哪来的异常处理呢?我觉得这是一个好问题,其实,即使没有 catch 语句,Java 编译器编译出的字节码中还是有默认的异常处理的,别忘了,除了需要捕获的异常,还可能有不需捕获的异常(如RunTimeException 和 Error)。
从 getValue()方法的字节码中,我们可以看到它的异常处理表(exception table), 如下:
Exception table:
from to target type
2 4 9 any
它的意思是说:如果从 2 到 4 这段指令出现异常,则由从 9 开始的指令来处理。
-
异常执行
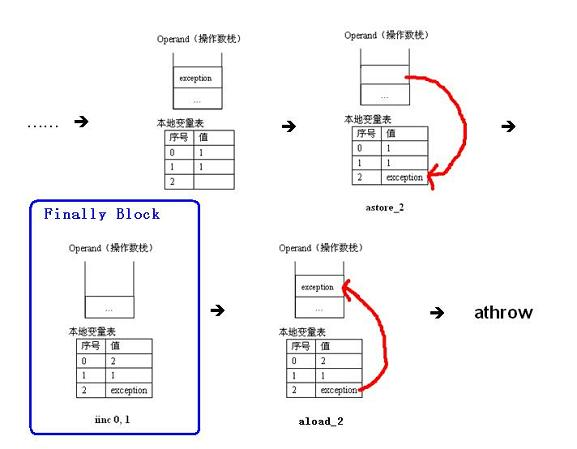
先说明一点,上图中的 exception 其实应该是 exception 对象的引用,为了方便说明,我直接把它写成 exception 了。由上图(图 2)可知,当从 2 到 4 这段指令出现异常时,将会产生一个 exception 对象,并且把它压入当前操作数栈的栈顶。接下来是 astore_2 这条指令,它负责把 exception 对象保存到本地变量表中 2 的位置,然后执行 finally 语句块,待 finally 语句块执行完毕后,再由 aload_2 这条指令把预先存储的 exception 对象恢复到操作数栈中,最后由 athrow 指令将其返回给该方法的调用者(main)。
17.设计模式
分为三大类:
-
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
-
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
-
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
题目:Java数据库连接库JDBC用到哪种设计模式?
答案:
桥接模式
桥接模式:
-
定义 :
将抽象部分与它的实现部分分离
,使它们都可以独立地变化。 -
意图 :将
抽象与实现解耦
。
桥接模式所涉及的角色
- Abstraction :定义抽象接口,拥有一个Implementor类型的对象引用
- RefinedAbstraction :扩展Abstraction中的接口定义
- Implementor :是具体实现的接口,Implementor和RefinedAbstraction接口并不一定完全一致,实际上这两个接口可以完全不一样Implementor提供具体操作方法,而Abstraction提供更高层次的调用
- ConcreteImplementor :实现Implementor接口,给出具体实现
Jdk中的桥接模式:JDBC
JDBC连接 数据库 的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不动,原因就是JDBC提供了
统一接口
,每个数据库提供各自的实现,用一个叫做数据库
驱动
的程序来桥接就行了
18.IO流
下面的类哪些可以处理Unicode字符?
A.InputStreamReader
B.BufferedReader
C.Writer
D.PipedInputStream
答案: A B C
首先unicode编码方案是为解决传统“字符”编码方案局限性而生的,简单地说,字符流是字节流根据字节流所要求的编码集解析获得的,可以理解为
字符流=字节流+编码集
,
stream结尾都是字节流,reader和writer结尾都是字符流
,两者的区别就是读写的时候一个是按字节读写,一个是按字符。
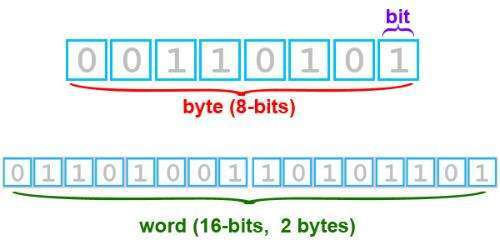
字节流与字符流的区别:
-
字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。字符流一般用于处理纯文本类型的文件,如TXT文件等,但不能处理图像视频等非文本文件。用一句话说就是:
字节流可以处理一切文件,而字符流只能处理纯文本文件。
-== 字节流本身没有缓冲区==,缓冲字节流相对于字节流,效率提升非常高。而
字符流本身就带有缓冲区
,缓冲字符流相对于字符流效率提升就不是那么大了。
流的特性:
- 先进先出:最先写入输出流的数据最先被输入流读取到。
- 顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile除外)
-
只读或只写:
每个流只能是输入流或输出流的一种
,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
IO流的分类:
- 按数据流的方向:输入流、输出流
- 按处理数据单位:字节流、字符流
- 按功能:节点流、处理流
节点流和处理流:
-
节点流:直接操作数据读写的流类,比如FileInputStream
(开头是名词)
(基本流) -
处理流:对一个已存在的流的链接和封装,通过对数据进行处理为程序提供功能强大、灵活的读写功能,例如BufferedInputStream(缓冲字节流)
(开头是动词)
处理流和节点流应用了Java的
装饰者设计模式。
下图就很形象地描绘了节点流和处理流,处理流是对节点流的封装,最终的数据处理还是由节点流完成的。

值得一提的是:在诸多处理流中,有一个非常重要,那就是
缓冲流
。
我们知道,程序与磁盘的交互相对于内存运算是很慢的,容易成为程序的性能瓶颈。减少程序与磁盘的交互,是提升程序效率一种有效手段。缓冲流,就应用这种思路:普通流每次读写一个字节,而缓冲流在内存中设置一个缓存区,缓冲区先存储足够的待操作数据后,再与内存或磁盘进行交互。这样,在总数据量不变的情况下,通过
提高每次交互的数据量,减少了交互次数。
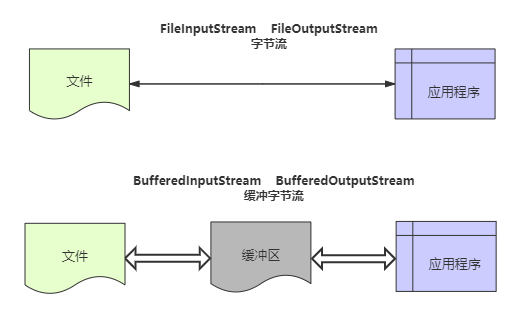
联想一下生活中的例子,我们搬砖的时候,一块一块地往车上装肯定是很低效的。我们可以使用一个小推车,先把砖装到小推车上,再把这小推车推到车前,把砖装到车上。这个例子中,小推车可以视为缓冲区,小推车的存在,减少了我们装车次数,从而提高了效率。

19.数据类型转化
Java类Demo中存在方法func1、func2、func3和func4,请问该方法中,哪些是
不合法
的定义?( )
public class Demo{
float func1()
{
int i=1;
return;
}
float func2()
{
short i=2;
return i;
}
float func3()
{
long i=3;
return i;
}
float func4()
{
double i=4;
return i;
}
}
A.func1
B.func2
C.func3
D.func4
答案:AD
首先数据类型转换:
由大到小强制转换(会丢失精度)
,由小到大自动转化。
long → float 无须强制转换
float占4个字节为什么比long占8个字节大呢,因为底层的实现方式不同。
浮点数的32位并不是简单直接表示大小,而是按照一定标准分配的。
第1位,符号位,即S
接下来8位,指数域,即E。
剩下23位,小数域,即M,取值范围为[1 ,2 ) 或[0 , 1)
然后按照公式: V=(-1)
s
* 2
E
* M
也就是说浮点数在内存中的32位不是简单地转换为十进制,而是通过公式来计算而来,通过这个公式虽然,只有4个字节,但浮点数最大值要比长整型的范围要大。(注意还有指数呢!)
题目:
表达式(short)10/10.2*2运算后结果是什么类型?
答案:double
首先,要注意是(short)10/
10.2
* 2,而不是(short) (10/10.2*2),前者只是把10强转为short,又由于式子中存在
浮点数
,所以会对结果值进行一个自动类型的提升,浮点数默认为double,所以答案是double;后者是把计算完之后值强转short。
拆箱与装箱:
- parseInt得到的是基础数据类型int
- valueof得到的是装箱数据类型Integer
- valueInt得到的是基础数据类型int
20.成员变量与局部变量
成员变量和局部变量的区别:
1、成员变量是独立于方法外的变量,局部变量是类的方法中的变量
-
成员变量:包括
实例变量和类变量
,用static修饰的是类变量,不用static修饰的是实例变量,所有类的成员变量可以通过this来引用。 - 局部变量:包括形参,方法局部变量,代码块局部变量,存在于方法的参数列表和方法定义中以及代码块中。
2、成员变量可以被public,protect,private,static等修饰符修饰,而
局部变量不能被控制修饰符及 static修饰
;两者
都可以定义成final型
。
3、成员变量存储在堆,
局部变量存储在栈
。局部变量的作用域仅限于定义它的方法,在该方法的外部无法访问它。成员变量的作用域在整个类内部都是可见的,所有成员方法都可以使用它。如果访问权限允许,还可以在类的外部使用成员变量。
4、局部变量的生存周期与方法的执行期相同。当方法执行到定义局部变量的语句时,局部变量被创建;执行到它所在的作用域的最后一条语句时,局部变量被销毁。类的成员变量,如果是实例成员变量,它和对象的生存期相同。而
静态成员变量的生存期是整个程序运行期
。
5、成员变量在类加载或实例被创建时,系统自动分配内存空间,并在分配空间后自动为成员变量指定初始化值,初始化值为默认值,基本类型的默认值为0,复合类型的默认值为null。(被final修饰且没有static的必须显式赋值),
局部变量在定义后必须经过显式初始化后才能使用,系统不会为局部变量执行初始化
。
6、
局部变量可以和成员变量 同名
,且在使用时,局部变量具有更高的优先级,直接使用同名访问,访问的是局部变量,如需要访问成员变量可以用this.变量名访问
小试牛刀:
下面代码的运行结果是
public static void main(String[] args){
String s;
System.out.println("s="+s);
}
答案:由于String s没有初始化,代码不能编译通过。
解:
局部变量没有默认值
21.包(package)
下列关于包(package)的描述,正确的是()
A.包(package)是Java中描述操作系统对多个源代码文件组织的一种方式。
B.import语句将所对应的Java源文件拷贝到此处执行。
C.包(package)是Eclipse组织Java项目特有的一种方式。
D.定义在同一个包(package)内的类可以不经过import而直接相互使用。
答案:D
1、为了更好地组织类,Java提供了包机制。包是类的容器,用于分隔类名空间。如果没有指定包名,所有的示例都属于一个默认的无名包。Java中的包一般均包含相关的类,java是跨平台的,所以java中的包和操作系统没有任何关系,
java的包是用来组织文件的一种虚拟文件系统
。A错
2、import语句并没有将对应的java源文件拷贝到此处仅仅是
引入
,告诉编译器有使用外部文件,编译的时候要去读取这个外部文件。B错
3、Java提供的包机制与IDE没有关系。C错
4、定义在同一个包(package)内的类可以不经过import而直接相互使用。
22.类加载器
Java 中的类加载器大致可以分成两类,一类是
系统提供
的,另外一类则是由
Java 应用开发人员编写
的。
系统提供的类加载器主要有下面三个:
引导类加载器(bootstrap class loader):
它用来加载 Java 的核心库,是用原生代码来实现的,并不继承自 java.lang.ClassLoader。主要负责jdk_home/lib目录下的核心api 或 -Xbootclasspath 选项指定的jar包装入工作(其中的jdk_home是指配置jdk环境变量是java_home的配置路径,一般是jdk/jre所在目录)。
扩展类加载器(extensions class loader):
它用来加载 Java 的扩展库。Java虚拟机的实现会提供一个扩展库目录,扩展类加载器在此目录里面查找并加载 Java 类,主要负责jdk_home/lib/ext目录下的jar包或 -Djava.ext.dirs 指定目录下的jar包装入工作。
系统类加载器(system class loader):
它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过 ClassLoader.getSystemClassLoader()来获取它。主要负责CLASSPATH/-Djava.class.path所指的目录下的类与jar包装入工作.
除了系统提供的类加载器以外,开发人员可以通过
继承java.lang.ClassLoader类
的方式实现自己的类加载器,从而进行动态加载class文件,以满足一些特殊的需求,这体现java动态实时类装入特性。
除了引导类加载器之外,所有的类加载器都有一个父类加载器
,通过getParent()方法可以得到。对于系统提供的类加载器来说,系统类加载器的父类加载器是扩展类加载器,而扩展类加载器的父类加载器是引导类加载器;对于开发人员编写的类加载器来说,其父类加载器是加载此类加载器 Java 类的类加载器。因为类加载器 Java 类如同其它的 Java 类一样,也是要由类加载器来加载的。一般来说,开发人员编写的类加载器的父类加载器是系统类加载器。类加载器通过这种方式组织起来,形成树状结构。树的根节点就是引导类加载器。
下图中给出了一个典型的类加载器树状组织结构示意图,其中的箭头指向的是父类加载器。
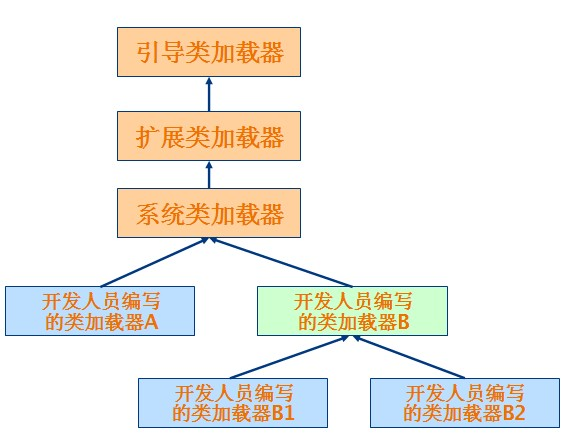
类的加载顺序:
(1) 父类静态对象和静态代码块
(2) 子类静态对象和静态代码块
(3) 父类非静态对象和非静态代码块
(4) 父类构造函数
(5) 子类 非静态对象和非静态代码块
(6) 子类构造函数
以下代码执行后输出结果为:
public class Test
{
public static Test t1 = new Test(); // 静态变量
// 构造块
{
System.out.println("blockA");
}
// 静态块
static
{
System.out.println("blockB");
}
public static void main(String[] args)
{
// 空参构造函数
Test t2 = new Test();
}
}
答案:
block
A
block
B
block
A
静态域:用staitc声明,jvm加载类时执行,仅执行一次
构造代码块:类中直接用{}定义,每一次创建对象时执行。
执行顺序优先级:静态域,main(),构造代码块,构造方法。
1 静态域 :首先执行,
第一个静态域是一个静态变量
public static Test t1 = new Test(); 创建了Test 对象,会执行构造块代码,所以输出blockA。然后执行==第二个静态域(即静态代码块)==输出blockB。
2 main():Test t2 = new Test()执行,创建Test类对象,
只会执行构造代码块(创建对象时执行)
,输出blockA。
3 构造代码块只会在创建对象时执行,没创建任何对象了,所以没输出
4 构造函数:
使用默认构造函数
,没任何输出
题目:关于Java中的ClassLoader下面的哪些描述是错误的:( )
A.默认情况下,Java应用启动过程涉及三个ClassLoader: Boostrap, Extension, System
B.一般的情况不同ClassLoader装载的类是不相同的,但接口类例外,对于同一接口所有类装载器装载所获得的类是相同的
C.类装载器需要保证类装载过程的线程安全
D.ClassLoader的loadClass在装载一个类时,如果该类不存在它将返回null
E.ClassLoader的父子结构中,默认装载采用了父优先
F.所有ClassLoader装载的类都来自CLASSPATH环境指定的路径
答案:BDF
A、java中类的加载有5个过程,
加载、验证、准备、解析、初始化
;这便是类加载的5个过程,而类加载器的任务是根据一个类的全限定名来读取此类的二进制字节流到JVM中,然后转换为一个与目标类对应的java.lang.Class对象实例,在虚拟机提供了3种类加载器,引导(Bootstrap)类加载器、扩展(Extension)类加载器、系统(System)类加载器(也称应用类加载器)。A正确
B、一个类,由不同的类加载器实例加载的话,会在方法区产生两个不同的类,彼此不可见,并且在堆中生成不同Class实例。所以B前面部分是正确的,后面接口的部分真的没有尝试过,等一个大佬的讲解吧;
C、类加载器是肯定要保证
线程安全
的;C正确
D、装载一个不存在的类的时候,因为采用的
双亲加载模式
,所以强制加载会直接报错,
java.lang.SecurityException: Prohibited package name: java.lang,D错误
E、双亲委派模式是在Java 1.2后引入的,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己想办法去完成,所以默认是父装载,E正确
F、自定义类加载器实现 继承ClassLoader后
重写了findClass方法加载指定路径上的class
,F错误
23.char字节溢出
执行如下程序代码
char chr = 127;
int sum = 200;
chr += 1;
sum += chr;
sum的值是( )
备注:同时考虑c/c++和Java的情况的话
答案:72、328
Java中,char两个字节,不会溢出,chr=128
C/C++中,char一个字节,对127+1后,01111111→10000000, chr=-128
24.构造器
一个类的构造器不能调用这个类中的其他构造器。(X)
this()和super()都是构造器,this()调用本类构造器,super()调用父类构造器
小小坑题,
构造器没有void
尝试编译以下程序会产生怎么样的结果?
public class MyClass {
long var;
public void MyClass(long param) { var = param; }//(1)
public static void main(String[] args) {
MyClass a, b;
a =new MyClass();//(2)
b =new MyClass(5);//(3)
}
}
答案:编译错误将在(3)处发生,因为该类没有构造函数,该构造函数接受一个int类型的参数
题目:对文件名为Test.java的java代码描述:
class Person {
String name = "No name";
public Person(String nm) {
name = nm;
}
}
class Employee extends Person {
String empID = "0000";
public Employee(String id) {
empID = id;
}
}
public class Test {
public static void main(String args[]) {
Employee e = new Employee("123");
System.out.println(e.empID);
}
}
答案:
编译报错
如果子类构造器没有显示地调用超类的构造器,则将自动地调用超类默认(没有参数)的构造器。如果超类没有不带参数的构造器,并且在子类的构造器中有没有显示地调用超类的其他构造器,则Java编译器将报告错误。使用super调用构造器的语句必须是子类构造器的第一条语句。
——p153《Java核心技术卷I》
25.关键字
下面哪个不是Java的关键字?
A.null
B.true
C.sizeof
D.implements
E.instanceof
答案:D E
-
关键字列表 (依字母排序 共50组):
abstract, assert, boolean, break, byte, case, catch, char, class,
const(保留关键字)
, continue, default, do, double, else, enum, extends, final, finally, float, for,
goto(保留关键字)
, if, implements, import, instanceof, int, interface, long, native, new, package, private, protected, public, return, short, static, strictfp, super, switch, synchronized, this, throw, throws, transient, try, void, volatile, while -
保留字列表 (依字母排序 共14组),Java保留字是指现有Java版本尚未使用,但
以后版本可能会作为关键字使用
:byValue, cast,
false
, future, generic, inner, operator, outer, rest,
true
, var, goto (保留关键字) , const (保留关键字) ,
null
26.正则表达式
要求匹配以下16进制颜色值,正则表达式可以为:
示例:
#ffbbad #Fc01DF #FFF #ffE
答案: /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g
正则表达式:用来描述或者匹配一系列符合某个语句规则的字符串
符号:
-
单个符号:
1、英文句点
.
符号:匹配
单个任意
字符。表达式t.o 可以匹配:tno,t#o,teo等等。不可以匹配:tnno,to,Tno,t正o等。
2、中括号
[]
:只有方括号里面
指定
的字符才参与匹配,也只能匹配单个字符。表达式:t[abcd]n 只可以匹配:tan,tbn,tcn,tdn。不可以匹配:thn,tabn,tn等。
3、
|
符号。相当与
“或”
,可以匹配指定的字符,但是也只能选择其中一项进行匹配。表达式:t(a|b|c|dd)n 只可以匹配:tan,tbn,tcn,tddn。不可以匹配taan,tn,tabcn等。
4、表示匹配次数的符号
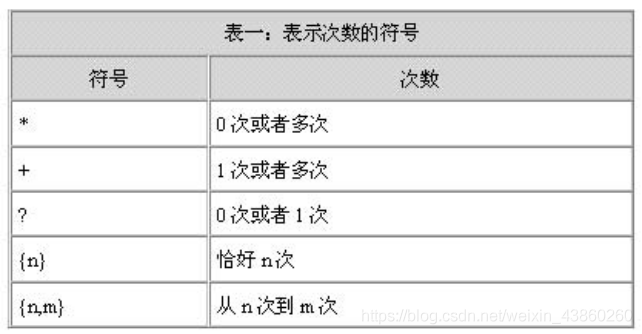
表达式:[0—9]{ 3 } \— [0-9]{ 2 } \— [0-9]{ 3 } 的匹配格式为:999—99—999
因为—符号在正则表达式中有特殊的含义,它表示一个范围,所以在前面加转义字符\。5、
^
符号:表示否,如果用在方括号内,^表示不想匹配的字符。表达式:[^x] 第一个字符不能是x
6、
\S
符号:
非空
字符7、
\s
符号:
空
字符,只可以匹配一个空格、制表符、回车符、换页符,不可以匹配自己输入的多个空格。8、
\r
符号:
空格
符,与\n、\tab相同 -
快捷符号
1、
\d
表示
[0—9]
2、
\D
表示
[^0—9]
3、
\w
表示
[0—9A—Z_a—z]
4、
\W
表示
[^0—9A—Z_a—z]
5、
\s
表示
[\t\n\r\f]
6、
\S
表示
[^\t\n\r\f]
小写=XX 大写=非XX
常用方法:
- 1、判断功能
public boolean matches(String regex)
- 2、分割功能
public String[] split(String regex)
- 3、替换功能
public String replaceAll(String regex,String replacement)
27.集合
对于 Collection 接口的实现,其实是由 AbstractCollection 类完成的.此类提供了 Collection 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。
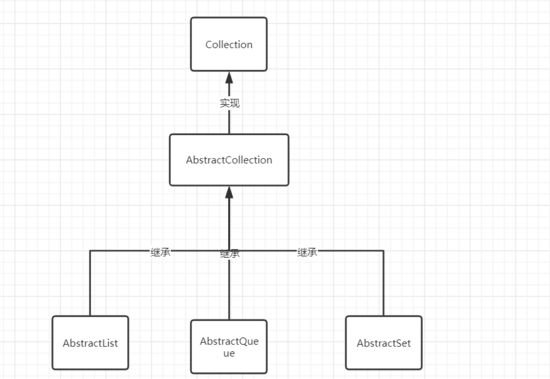
所有的集合都是依靠这种方式构建的,
用一个抽象类实现接口,然后再用集合类去实现这些抽象类,来完成构建集合的目的.
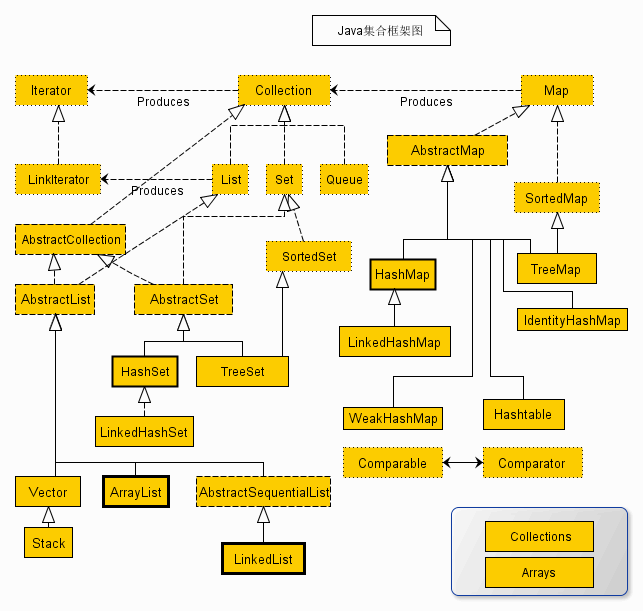
Iterator接口–迭代器:
{
boolean hasNext() 如果仍有元素可以迭代,则返回 true。
E next() 返回迭代的下一个元素。
void remove() 删除
default void forEach 实现了迭代器接口的类才可以使用forEach
}
这几个方法有着很重要的意义:
- 所有实现 Collection 接口(也就是大部分集合)都可以使用forEach功能.
- 通过反复调用 next() 方法可以访问集合内的每一个元素.
- java迭代器查找的唯一操作就是依靠调用next,而在执行查找任务的同时,迭代器的位置也在改变.
-
Iterator迭代器remove方法会删除上次调用next方法返回的元素.这也意味之remove方法和next有着很强的依赖性.如果在
调用remove之前没有调用next是不合法的 .
这个接口衍生出了,java集合的迭代器.
java集合的迭代器使用:
class test {
public static void run() {
List<Integer> list = new LinkedList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
Iterator<Integer> iterator = list.iterator();//依靠这个方法生成一个java集合迭代器<--在Colletion接口中的方法,被所有集合实现.
// iterator.remove();报错java.lang.IllegalStateException
iterator.next();
iterator.remove();//不报错,删掉了1
System.out.println(list);//AbstractCollection类中实现的toString让list可以直接被打印出来
while (iterator.hasNext()) {//迭代器,hasNext()集合是否为空
Integer a = iterator.next();//可以用next访问每一个元素
System.out.println(a);//2,3 ,3
}
for (int a : list) {//也可以使用foreach
System.out.println(a);//2,3,3
}
}
public static void main(String[] args) {
run();
}
}
解释:为什么 remove 方法前面必须跟着一个next方法?
图解:
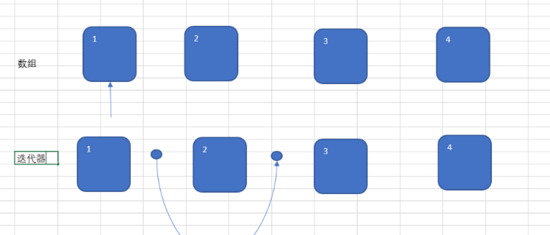
迭代器的next方法的运行方式并不是类似于数组的运行方式.
数组的指针指向要操作的元素上面,而迭代器却是将要操作的元素放在运动轨迹中间.
本质来讲,
迭代器的指针并不是指在元素上,而是指在元素和元素中间.
假设现在调用remove().被删除的就是2号元素.(被迭代器那个圆弧笼盖在其中的那个元素).如果
再次调用,就会报错,因为圆弧之中的2号元素已经消失
,那里是空的,无法删除.
Collection接口:
这个对象是一个被 List , Set , Queue 的超类, 这个接口中的方法,构成了集合中主要的方法和内容.剩下的集合往往都是对这个接口的扩充.
boolean add(E o)
确保此 collection 包含指定的元素(可选操作)。
boolean addAll(Collection<? extends E> c)
将指定 collection 中的所有元素添加到此 collection 中(可选操作)。
void clear()
从此 collection 中移除所有元素(可选操作)。
boolean contains(Object o)
如果此 collection 包含指定的元素,则返回 true。
boolean containsAll(Collection<?> c)
如果此 collection 包含指定 collection 中的所有元素,则返回 true。
boolean isEmpty()
如果此 collection 不包含元素,则返回 true。
abstract Iterator<E> iterator()
返回在此 collection 中的元素上进行迭代的迭代器。
boolean remove(Object o)
从此 collection 中移除指定元素的单个实例(如果存在)(可选操作)。
boolean removeAll(Collection<?> c)
从此 collection 中移除包含在指定 collection 中的所有元素(可选操作)。
boolean retainAll(Collection<?> c)
仅在此 collection 中保留指定 collection 中所包含的元素(可选操作)。
abstract int size()
返回此 collection 中的元素数。
Object[] toArray()
返回包含此 collection 中所有元素的数组。
<T> T[] toArray(T[] a)
返回包含此 collection 中所有元素的数组;返回数组的运行时类型是指定数组的类型。
String toString() <--很重要
java集合中使用泛型的好处
除了为了
防止输入错误的数据
,更重要的是如果用了泛型也会让操作更加的方便,
省去了强制转化的过程
.
另: @SuppressWarnings(“unchecked”)这个只能抑制警告信息,用它就不会有警告
List:
List是一个
有序集合
,元素会增加到容器中特定的位置,可以采用两种方式访问元素:使用
迭代器访问
或者
随机访问(使用一个整数索引访问)
.
void add(int index,E element);//这个和上面不同,带了index.
void remove(int index);
E get(int index);
E set(int index,E element);
List主要有两种类.一个是LinkedList一个是ArrayList.
LinkedList:
/**
* LinkedLIST也像ArrayList一扬实现了基本的List接口,但是他执行一些操作效率更高,比如插入.
* LIST为空就会抛出NoSuchElement-Exception
*/
public class LinkedListFeatures {
public static void main(String[] args) {
LinkedList<Pet> pets=new LinkedList<Pet>(Pets.arrayList(5));//后面括号中的意思是生成五个Pets对象
System.out.println("pets = [" + pets + "]");
System.out.println("pets.getFirst() "+pets.getFirst());//取第一个
System.out.println("pets.element "+pets.element());//也是取第一个,跟first完全相同.
//如果列表为空如上两个内容返回NoSuchElement-Exception
System.out.println("pets.peek()"+pets.peek());//peek跟上面两个一扬,只是在列表为空的时候返回null
System.out.println(pets.removeFirst());
System.out.println(pets.remove());//这两个完全一样,都是移除并返回列表头,列表空的时候返回NoSuchElement-Exception
System.out.println(pets.poll());//稍有差异,列表为空的时候返回null
pets.addFirst(new Rat());//addFirst将一个元素插入头部,addLast是插到尾部
System.out.println(pets);
pets.add(new Rat());//将一个元素插入尾部
System.out.println(pets);
pets.offer(new Rat());//与上面一样,将一个元素插入尾部
System.out.println(pets);
pets.set(2,new Rat());//将替换为指定的元素
System.out.println(pets);
}
}
小归纳:(刷力扣必会)
栈相关的操作方法:
E push()
找到并移除此列表的头(第一个元素)。
peek()
找到但不移除此列表的头(第一个元素)。
void addFirst(E o) 加入开头可以当作add用
void push(E o)
队列相关的操作方法:
E element() 首元素
boolean offer(E o)将指定队列插入桶
E peek() 检索,但是不移除队列的头
E poll()检索并移除此队列的头,为空返回null.
E remove()检索并移除此队列的头
ArrayList:
public class ListFeatures {
public static void main(String[] args) {
Random rand=new Random(47);//相同的种子会产生相同的随机序列。
List<String> list=new ArrayList<>();
list.add("demo3");
list.add("demo2");
list.add("demo1");//加入方法
System.out.println("插入元素前list集合"+list);//可以直接输出
/**
* /void add(int index, E element)在指定位置插入元素,后面的元素都往后移一个元素
*/
list.add(2,"demo5");
System.out.println("插入元素前list集合"+list);
List<String> listtotal=new ArrayList<>();
List<String> list1=new ArrayList<>();
List<String> list2=new ArrayList<>();
list1.add("newdemo1");
list1.add("newdemo2");
list1.add("newdemo2");
/**
* boolean addAll(int index, Collection<? extends E> c)
* 在指定的位置中插入c集合全部的元素,如果集合发生改变,则返回true,否则返回false。
* 意思就是当插入的集合c没有元素,那么就返回false,如果集合c有元素,插入成功,那么就返回true。
*/
boolean b=listtotal.addAll(list1);
boolean c=listtotal.addAll(2,list2);
System.out.println(b);
System.out.println(c);//插入2号位置,list2是空的
System.out.println(list1);
/**
* E get(int index)
* 返回list集合中指定索引位置的元素
*/
System.out.println(list1.get(1));//list的下标是从0开始的
/**
* int indexOf(Object o)
* 返回list集合中第一次出现o对象的索引位置,如果list集合中没有o对象,那么就返回-1
*/
System.out.println(list1.indexOf("demo"));
System.out.println(list1.indexOf("newdemo2"));
//如果在list中有相同的数,也没有问题.
//但是如果是对象,因为每个对象都是独一无二的.所以说如果传入一个新的对象,indexof和remove都是无法完成任务的
//要是删除,可以先找到其位置,然后在进行删除.
//Pet p=pets.get(2);
//pets.remove(p);
/**
* 查看contains查看参数是否在list中
*/
System.out.println(list1.contains("newdemo2"));//true
/**
* remove移除一个对象
* 返回true和false
*/
//只删除其中的一个
System.out.println(list1.remove("newdemo2"));//[newdemo1, newdemo2]
System.out.println(list1);
List<String> pets=list1.subList(0,1);//让你从较大的一个list中创建一个片段
//containsall一个list在不在另一个list中
System.out.println(pets+"在list中嘛"+list1.containsAll(pets));//[newdemo1]在list中嘛true
//因为sublist的背后就是初始化列表,所以对于sublist的修改会直接反映到原数组上面
pets.add("new add demo");
System.out.println(list1);//[newdemo1, new add demo, newdemo2]
Collections.sort(pets);
System.out.println(
pets
);//new add demo, newdemo1
System.out.println(list1.containsAll(pets));//true-----变换位置不会影响是否在list1中被找到.
list1.removeAll(pets);//移除在参数list中的全部数据
/**
* list1[newdemo1, new add demo, newdemo2]
* pets[new add demo, newdemo1]
*/
System.out.println(list1);//[newdemo2]
System.out.println(list1.isEmpty());//是否为空
System.out.println(list1.toArray());//将list变为数组
//list的addAll方法有一个重载的.可以让他在中间加入
}
}
Set:
-
Set
不
保存
重复
的元素.(在调用equal时,如果两个Set中的元素都相等,无论两者的顺序如何,这两个Set都会相等.) - Set就是Collection,只是行为不同.
-
HashSet
使用了
散列
,它打印的时候,输出的元素不会正常排列 -
TreeSet
使用了储存在
红黑树
结构中,所以输出的元素会正常排列
Set最主要的工作就是
判断存在性
,目的是看一个元素到底存不存在这个集合之中.(想想力扣中刷到的一些题目)
SortedSet(TreeSet)
public class SortedSetOfInteger {
public static void main(String[] args) {
Random random=new Random(47);
SortedSet<Integer> intset=new TreeSet<>();
for (int i = 0; i <100 ; i++) {
intset.add(random.nextInt(30));
}
System.out.println(intset);//set特性只能输入相同的数,别看输入了100个数,但是实际上只有30个进去了.
//这个有序了.这就是treeset的功劳,因为内部的实现时红黑树,所以来说.这就简单了一些
}
}
HashSet
public class SetOfInteger {
public static void main(String[] args) {
Random rand=new Random(47);
Set<Integer> intset=new HashSet<>();//创建一个HashSet
for (int i = 0; i <100 ; i++) {
intset.add(rand.nextInt(30));
}
System.out.println(intset);//set特性只能输入相同的数,别看输入了100个数,但是实际上只有30个进去了.
}
}
来复习一下HashSet:
HashSet
无序
,根据属性可以快速的访问所需要的对象。
散列表
为每个对象
计算
一个整数,成为散列码,
散列码是实例产生的一个整数。
散列表用链表数组实现。每个
列表称为通
。想要查找表中对象的位置就计算它的散列码。然后与通的总数取余,得到的数就是保存这个元素的通的索引。
但是桶总有被沾满的一刻。
为了应对这种情况,需要用新对象与桶中所有对象比较,看是否存在。
为了控制性能就要能
定义初始桶数
,设置为要
插入元素的75%-150%
,最好为
素数
。
这个时候就要执行再散列,让这个散列表获得更多的内容。
再散列
:
需要创建一个桶数更多的表,并将全部元素插入这个新表中。装填因子绝对什么时候在执行,如果装填因子为0.75那么就是在表中75%的位置被沾满时,表会给如双倍的桶数自动散列。
Queue:
在集合中的Queue并没有单独的实现类,而是
用LinkedList实现的
。
add()尾部添加
removeFirst()删除头部元素
peek()查看头部元素
Queue主要有两种不同的类型:
分别是PriorityQueue优先级队列和Deque双端队列
PriorityQueue:
remove
移除
的都是
当前最小
的元素 .
优先级使用了一种堆,一个可以自我调节的二叉树,对树进行执行添加和删除。它可以让最小的元素移动到跟,而不必花时间对其排序。
Deque:
线性集合,支持两端的元素插入和移除。Deque是 double ended queue 的简称,习惯上称之为
双端队列
。大多数Deque 实现对它们可能包含的元素的数量没有固定的限制,但是该接口支持容量限制的deques以及没有固定大小限制的deque。
public class Main {
public static void main(String[] args) {
Deque<String> deque = new LinkedList<>();
deque.offerLast("A"); // A
deque.offerLast("B"); // B -> A
deque.offerFirst("C"); // B -> A -> C
System.out.println(deque.pollFirst()); // C, 剩下B -> A
System.out.println(deque.pollLast()); // B
System.out.println(deque.pollFirst()); // A
System.out.println(deque.pollFirst()); // null
}
}
Stack:
拿LinkedList实现就完事了
public class Stack<T> {
private LinkedList<T> storage=new LinkedList<>();//用LinkedList作为栈的核心
public void push(T v){ storage.addFirst(v);}//
public T peek(){ return storage.getFirst();}
public T pop(){return storage.removeFirst();}
public boolean empty(){return storage.isEmpty();}
public String toString(){return storage.toString();}
}
小结小结一下:
Map:
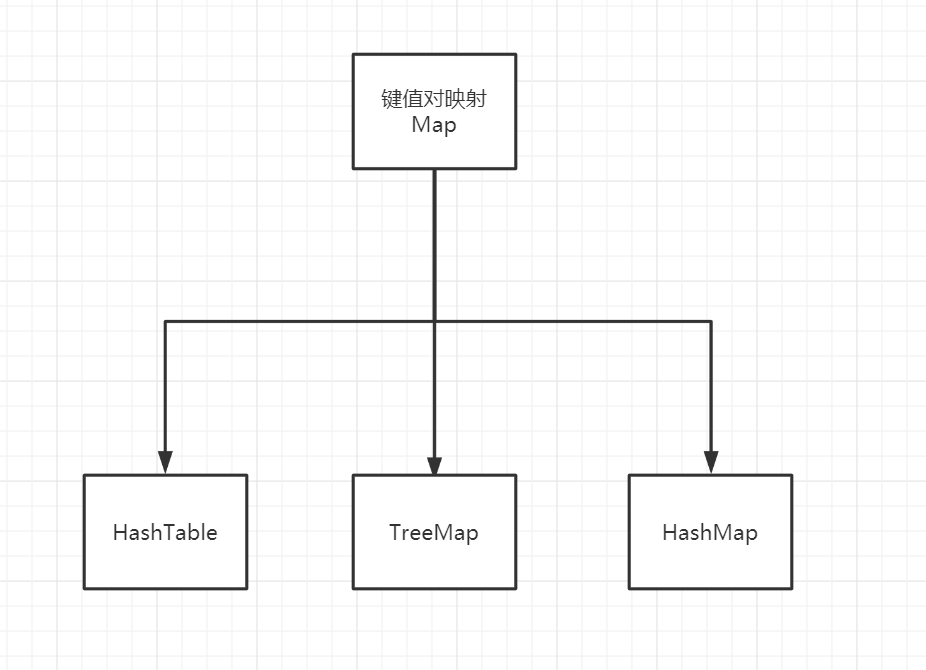
和Set一样,
HashMap要比TreeMap要快上一些
,但是
TreeMap有序
.这与Set很相似,毕竟
Set其实也是映射结构
.
键是唯一的
,不能对同一个键放两个值.如果对同一个键调用
两次put方法,第二次调用会取代第一个
.
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。
public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。
public V get(Object key) 根据指定的键,在Map集合中获取对应的值。
boolean containsKey(Object key) 判断集合中是否包含指定的键。
public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
Map集合遍历键找值方式:keyset()
public class MapDemo01 {
public static void main(String[] args) {
//创建Map集合对象
HashMap<String, String> map = new HashMap<String,String>();
//添加元素到集合
map.put("胡歌", "霍建华");
map.put("郭德纲", "于谦");
map.put("薛之谦", "大张伟");
//获取所有的键 获取键集
Set<String> keys = map.keySet();
// 遍历键集 得到 每一个键
for (String key : keys) {
//key 就是键
//获取对应值
String value = map.get(key);
System.out.println(key+"的CP是:"+value);
}
}
}
Map集合遍历键值对方式
public class MapDemo02 {
public static void main(String[] args) {
// 创建Map集合对象
HashMap<String, String> map = new HashMap<String,String>();
// 添加元素到集合
map.put("胡歌", "霍建华");
map.put("郭德纲", "于谦");
map.put("薛之谦", "大张伟");
// 获取 所有的 entry对象 entrySet
Set<Entry<String,String>> entrySet = map.entrySet();
// 遍历得到每一个entry对象
for (Entry<String, String> entry : entrySet) {
// 解析
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"的CP是:"+value);
}
}
}
Map接口有两个经典的实现分别是 Hashtable 和 Hashmap
-
Hashtable
线程安全,不支持key和value为空
,key不能重复,但
value可以重复
,
不支持key和value为null
。 - Hashmap 非线程安全,支持key和value为空,key不能重复,但value可以重复,支持key和value为null。
一般认为Hashtable是一个遗留的类。
Vector & ArrayList 的主要区别
- 1) 同步性:Vector是线程安全的,也就是说是同步的 ,而ArrayList 是线程序不安全的,不是同步的
-
2)数据增长:当需要增长时,==Vector默认增长为原来一倍
,而
ArrayList却是原来的50% ==,这样,ArrayList就有利于节约内存空间。如果涉及到堆栈,队列等操作,应该考虑用Vector,如果需要快速随机访问元素,应该使用ArrayList。
ArrayList & LinkedList的主要区别
ArrayList的内部实现是基于内部数组Object[],所以从概念上讲,它更像数组,但LinkedList的内部实现是基于一组连接的记录,所以,它更象一个链表结构,所以,它们在性能上有很大的差别:
从上面的分析可知,在ArrayList的前面或中间插入数据时,你必须将其后的所有数据相应的后移,这样必然要花费较多时间,所以,当你的操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能; 而访问链表中的某个元素时,就必须从链表的一端开始沿着连接方向一个一个元素地去查找,直到找到所需的元素为止,所以,当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
28.StringBuffer
StringBuffer s = new StringBuffer(x); x为初始化容量长度
s.append(“Y”); “Y”表示长度为y的字符串
length始终返回当前长度即y;
对于s.capacity():
1.当y<x时,值为x
以下情况,容器容量需要扩展
2.当x<y<2
x+2时,值为 2
x+2
3.当y>2*x+2时,值为y
29.Override(重写)与Overload(重载)
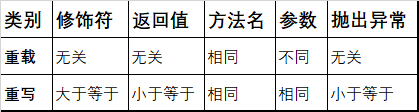
Override:
两同两小一大
方法名、参数列表相同
返回类型、抛出异常 《 重写前
访问权限 》 重写前
[注意:这里的返回类型必须要在有继承关系的前提下比较]
Overload:
同一个类,
方法名必须相同,参数类型必须不同
,包括但不限于一项,参数数目,参数类型,参数顺序 ,
与修饰符和返回值类型以及抛出异常类型无关
重载:在一个类中为一种行为提供多种实现方式并提高可读性,(编译时多态)
重写:父类方法无法满足子类的要求,子类通过方法重写满足需求(运行时多态)

题目:
对于如下代码段
class A{
public A foo() {
return this;
}
}
class B extends A {
public A foo(){
return this;
}
}
class C extends B {
_______
}
可以放入到横线位置,使程序正确编译运行,而且不产生错误的选项是( )
A.public void foo(){}
B.public int foo(){return 1;}
C.public A foo(B b){return b;}
D.public A foo(){return A;}
答案:C
这道题 A B 都是方法名和参数相同,是重写,但是返回类型没与父类返回类型有继承关系,错误
D 返回一个类错误 c的参数类型与父类不同,所以不是重写,可以理解为广义上的重载访问权限小于父类,都会显示错误
虽然题目没点明一定要重载或者重写,但是当你的方法名与参数类型与父类相同时,已经是重写了,这时候如果返回类型或者异常类型比父类大,或者访问权限比父类小都会编译错误
30.修饰符
Java提供了很多的修饰符,主要分为
控制访问的修饰符和非控制访问的修饰符。
-
控制访问的修饰符:对类、成员变量和方法访问的保护
public:
修饰类,成员变量和方法
。对所有的类都开放,可以被所有的类访问,如果被访问的public类与使用类
不在一个包下
,就需要先
导包
。Java 程序的
main() 方法必须设置成public
,否则,JVM将不能运行该类。
protected:修饰成员变量、方法和
内部类
,它不能用来修饰类,它也
不能用来修饰接口
、接口的成员变量和接口的方法。
default:相当于不添加
private:
不允许用来修饰类(但是可以修饰内部类)
,它能够修饰成员变量和方法。被private修饰的
只能被本类所访问。
-
非控制访问的修饰符:实现其他的一些功能。
static:修饰
变量和方法
。不需要实例化类,就能被使用。静态变量也称作类变量。局部变量
不能声明为static变量。
静态方法中不能使用非静态
的成员变量和非静态方法。
final:修饰
类、成员变量和方法
。final类表示最终的类,该类
不允许被继承
。final变量表示最终的变量,该变量一经赋值,就
不能被修改
。当final修饰的成员变量为
引用数据类型时
,在赋值后其指向
地址无法改变
,但是
对象内容还是可以改变的
。 final修饰的成员变量在赋值时可以有三种方式。
1、在声明时直接赋值。2、在构造器中赋值。3、在初始代码块中进行赋值
。final方法表示最终的方法,它能被子类所继承,但是该方法
不能被子类所重写
。
abstract:修饰
类和方法
。
一个类不能被abstract和final同时修饰
,抽象方法不包含方法体,
没有{}
,它的声明
以;结尾
,
抽象方法不能用final和static修饰
synchronized:修饰
方法、代码块
(不是变量),在同一时间内只能被一个线程所访问。
transient(短暂的):修饰
成员变量
,用来
预处理
类和变量的数据类型,序列化的对象包含被transient修饰的实例变量时,JVM会跳过该特定的变量。
volatile(不稳定的):修饰
成员变量
,修饰的成员变量在每次被线程访问时,都强制从共享内存中
重新读取
该成员变量的值。当成员变量发生变化时,会强制线程将变化值
回写到共享内存中
。这样在任何时候,
两个不同的线程总是看到某个成员变量的同一个值
。
题目:关于volatile关键字,下列描述不正确的是?
A.用volatile修饰的变量,每次更新对其他线程都是立即可见的。
B.对volatile变量的操作是原子性的。
C.对volatile变量的操作不会造成阻塞。
D.不依赖其他锁机制,多线程环境下的计数器可用volatile实现。
答案:B、D
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是
立即可见
的。
2)
禁止进行指令重排序
。
volatile只提供了保证访问该变量时,每次都是从内存中读取最新值,并不会使用寄存器缓存该值——每次都会从内存中读取。
而对该变量的修改,volatile并不提供原子性的保证。
由于及时更新,很可能导致另一线程访问最新变量值,无法跳出循环的情况
多线程下计数器必须使用锁保护。
关于原子性的理解:
- 原子性就是不可分割,比如赋值操作 i = 0;这就是一个原子性的代码,但是i++;这种就是i=i+1;是两个操作,先加一后赋值,所以不是原子性,volatile关键字只保证了线程可见性,但是线程操作上没有规定必须原子性。
- synchronized方法保证了原子性,但是可能会造成线程阻塞,而volatile虽然能实现了同样的锁的机制,但性能没有其好,不过优势在于他不会造成阻塞,开销要小得多。
补充:
| 修饰符 | 同类 | 同包 | 子类 | 不同包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
-
1.final static abstract均不可以修饰构造方法
-
2.一些修饰符不可联用:
abstract 与 private
abstract 与 static
abstract 与 final
-
3.关于抽象类
JDK 1.8以前,抽象类的方法默认访问权限为protected
JDK 1.8时,抽象类的方法默认访问权限变为default(包访问权限) -
4.关于接口
JDK 1.8以前,接口中的方法必须是public的
JDK 1.8时,接口中的方法可以是public的,也可以是default的
JDK 1.9时,接口中的方法可以是private的
31.函数
Math:
public static double abs(double num);获取绝对值。有多种重载,absolutely绝对地
public static double ceil(double num);向上取整,ceil是天花板
public static double floor(double num);向下取整,floor是地板
public static long round(double num);四舍六入五成双
Math.P I= 3.14159265358979323846
Math.round:
设一个数为x, 则其Math.round(x)的输出结果为y=
向下取整
(
x+0.5
)。
例如:
(1)x=-11.5; 其输出结果Math.round(-11.5) = -11;
(2)x=11.5;其输出结果Math.round(11.5) = 12;
String:
题目:
以下代码将打印出
public static void main (String[] args) {
String classFile = "com.jd.". replaceAll(".", "/") + "MyClass.class";
System.out.println(classFile);
}
错解:com/jd/MyClass.class
正解:///MyClass.class
-
public String replace(char oldChar, char newChar)
在字符串中用newChar字符替代oldChar字符,返回一个新的字符串 -
public String replaceAll(String regex,String replacement)使用给定的
replacement 字符串替换此字符串匹配给定的
正则表达式
的每个子字符串。
“.“在正则表达式中表示任何字符,所以会把前面字符串的所有字符都替换成”/”,如果想替换的只是”.”,那么就要写成”\.”
32.反射
反射就是把java类中的各种成分映射成一个个的Java对象。Class对象的由来是将class文件读入内存,并为之创建一个Class对象。
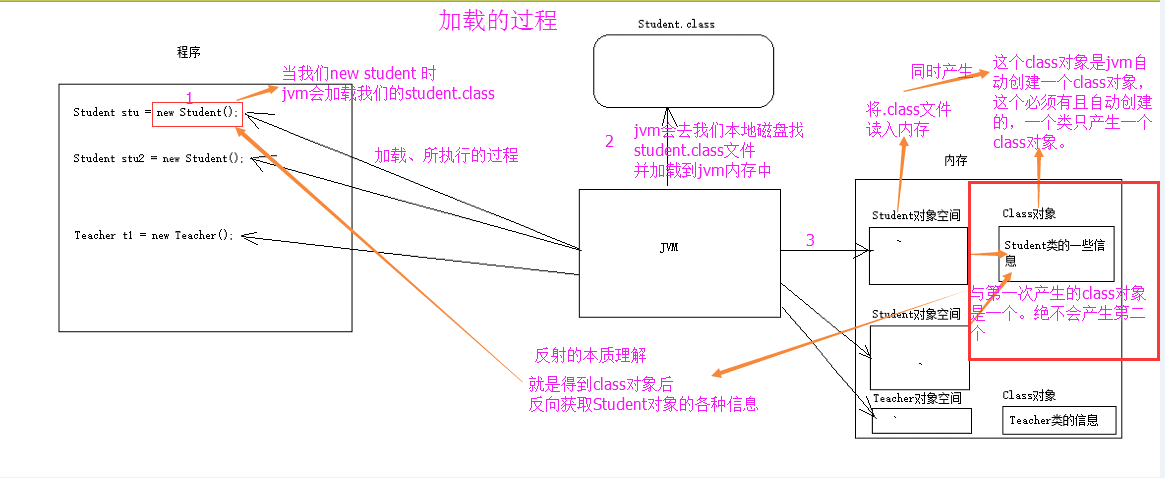
获取功能:
- 获取Class对象的三种方式:
【Source源代码阶段】 Class.forName(“全类名”):将字节码文件加载进内存,返回Class对象;
多用于配置文件,将类名定义在配置文件中,通过读取配置文件加载类。
【Class类对象阶段】 类名.class:通过类名的属性class获取;
多用于参数的传递
【Runtime运行时阶段】对象.getClass():此方法是定义在Objec类中的方法,因此所有的类都会继承此方法。
多用于对象获取字节码的方式
//方式一:Class.forName("全类名");
Class class1 = Class.forName("com.Person");// Person自定义实体类
//方式二:类名.class
Class class2 = Person.class;
//方式三:对象.getClass();
Person person = new Person();
Class class3 = person.getClass();
同一个字节码文件(*.class)在一次程序运行过程中,只会被
加载一次
,无论通过哪一种方式获取的Class对象都是同一个。
//比较三个对象
System.out.println(class1 == class2); //true
System.out.println(class1 == class3); //true
- 获取成员变量
Field[] getFields() //获取所有public修饰的成员变量
Field getField(String name) //获取指定名称的public修饰的成员变量
Field[] getDeclaredFields() //获取所有的成员变量,不考虑修饰符
Field getDeclaredField(String name) //获取指定的成员变量,不考虑修饰符
Field:成员变量
(1)设置值 void set(Object obj, Object value)
(2)获取值 get(Object obj)
(3)忽略访问权限修饰符的安全检查 setAccessible(true):暴力反射
测试的实体类:
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
@Data
public class Person {
public String a; //最大范围public
protected String b; //受保护类型
String c; //默认的访问权限
private String d; //私有类型
}
//获取Person的Class对象
Class personClass = Person.class;
//1、Field[] getFields()获取所有public修饰的成员变量
Field[] fields = personClass.getFields();
for(Field field : fields){
System.out.println(field);
}
//2.Field getField(String name) 获取指定名称的public修饰的成员变量
Field a = personClass.getField("a");
//获取成员变量a的值 [也只能获取公有的,获取私有的或者不存在的字符会抛出异常]
Person p = new Person();
Object value = a.get(p);
System.out.println("value = " + value);//因为在Person类中a没有赋值,所以为null
//设置成员变量a的属性值
a.set(p,"张三");
System.out.println(p);
//Field getDeclaredField(String name) //获取指定的成员变量,不考虑修饰符
Field d = personClass.getDeclaredField("d"); //private String d;
Person p = new Person();
//Object value1 = d.get(p); //如果直接获取会抛出异常,因为对于私有变量虽然能会获取到,但不能直接set和get,必须忽略访问权限修饰符的安全检查后才可以
//System.out.println("value1 = " + value1);
//忽略访问权限修饰符的安全检查,又称为暴力反射
d.setAccessible(true);
Object value2 = d.get(p);
System.out.println("value2 = " + value2);

顺便复习一下Lombok常用注解:
@Data :相当于@Setter + Getter + @ToString + @EqualsAndHashCode
@Setter @Getter:作用于属性上,自动生成getter和setter方法
@NonNull:判断是否为空,如果为空,则抛出java.lang.NullPointerException
@Synchronized:作用在方法上,自动添加到同步机制,生成的代码并不是直接锁方法而是锁代码块
@ToString:生成toString()方法,该注解有以下多个属性可以进一步设置:
-
callSuper:是否输出父类的toString方法,默认为false
-
includeFieldNames:是否包含字段名称,默认为true
-
exclude:排除生成tostring的字段
@EqualsAndHashCode
@Cleanup:用于确保已分配的资源被释放,自动帮我们调用close()方法。比如IO的连接关闭。
@SneakyThrows
@NoArgsConstructor:自动生成无参数构造函数。
@AllArgsConstructor:自动生成全参数构造函数。
@Builder
@SuperBuilder
- 获取构造方法
Constructor<?>[] getConstructors() //获取所有public修饰的构造函数
Constructor<T> getConstructor(类<?>... parameterTypes) //获取指定的public修饰的构造函数
Constructor<?>[] getDeclaredConstructors() //获取所有的构造函数,不考虑修饰符
Constructor<T> getDeclaredConstructor(类<?>... parameterTypes) //获取指定的构造函数,不考虑修饰符
测试的实体类:
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
private String name;
private Integer age;
//单个参数的构造函数,且为私有构造方法
private Person(String name){
}
}
//获取Person的Class对象
Class personClass = Person.class;
//Constructor<?>[] getConstructors() //获取所有public修饰的构造函数
Constructor[] constructors = personClass.getConstructors();
for(Constructor constructor : constructors){
System.out.println(constructor);
}
//获取无参构造函数 注意:Person类中必须要有无参的构造函数,不然抛出异常
Constructor constructor1 = personClass.getConstructor();
//使用获取到的无参构造函数创建对象
Object person1 = constructor1.newInstance();
//获取有参的构造函数 //public Person(String name, Integer age) 参数类型顺序要与构造函数内一致,且参数类型为字节码文件类型
Constructor constructor2 = personClass.getConstructor(String.class,Integer.class);
//使用获取到的有参构造函数创建对象
Object person2 = constructor2.newInstance("zhangsan", 22); //获取的是有参的构造方法,就必须要指定参数
//对于一般的无参构造函数,我们都不会先获取无参构造器之后在进行初始化,而是直接调用Class类内的newInstance()方法
Object person3 = personClass.newInstance();
- 获取成员方法
Method[] getMethods() //获取所有public修饰的成员方法
Method getMethod(String name, 类<?>... parameterTypes) //获取指定名称的public修饰的成员方法
Method[] getDeclaredMethods() //获取所有的成员方法,不考虑修饰符
Method getDeclaredMethod(String name, 类<?>... parameterTypes) //获取指定名称的成员方法,不考虑修饰符
测试的实体类:
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
private String name;
private Integer age;
//无参方法
public void eat(){
System.out.println("eat...");
}
//重载有参方法
public void eat(String food){
System.out.println("eat..."+food);
}
}
//获取Person的Class对象
Class personClass = Person.class;
//获取指定名称的方法
Method eat_method1 = personClass.getMethod("eat");
//执行方法
Person person = new Person();
Object rtValue = eat_method1.invoke(person);//如果方法有返回值类型可以获取到,没有就为null
//获取有参的函数,有两个参数:第一个参数为方法名,第二个参数是获取方法的参数类型的字节码文件
Method eat_method2 = personClass.getMethod("eat", String.class);
//执行方法
eat_method2.invoke(person,"苹果");
//获取方法列表
Method[] methods = personClass.getMethods();
for(Method method : methods){ //注意:获取到的方法不仅仅是Person类内自己的方法
System.out.println(method); //继承Object中的方法也会被获取到(当然前提是public修饰的)
}

在反射面前没有公有私有,都可以通过暴力反射解决。
- 获取全类名
String getName()
33.Socket和ServerSocket
异常类型(IOException):
- UnkownHostException: 主机名字或IP错误
- ConnectException:服务器拒绝连接、服务器没有启动、(超出队列数,拒绝连接)
- SocketTimeoutException: 连接超时
- BindException: Socket对象无法与制定的本地IP地址或端口绑定
交互过程:
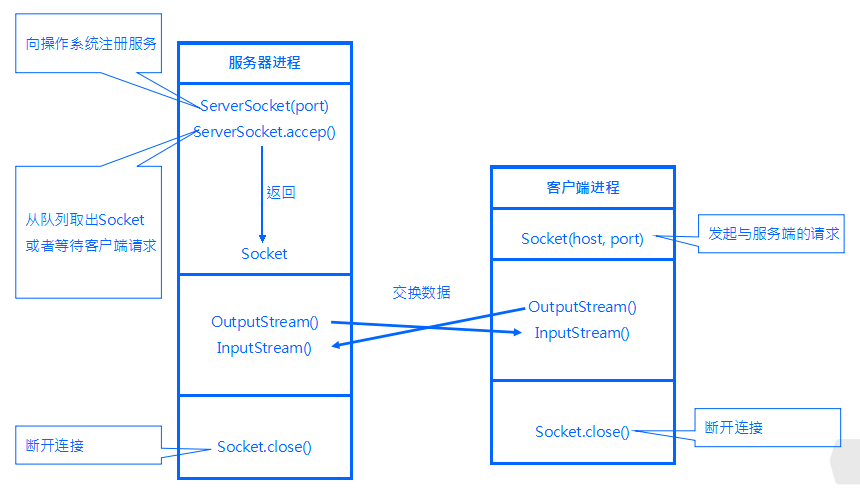
Socket:
构造函数
Socket()
Socket(InetAddress address, int port)throws UnknownHostException, IOException
Socket(InetAddress address, int port, InetAddress localAddress, int localPort)throws IOException
Socket(String host, int port)throws UnknownHostException, IOException
Socket(String host, int port, InetAddress localAddress, int localPort)throws IOException
除去第一种不带参数的之外,其它构造函数会尝试建立与服务器的连接。如果失败会抛出IOException错误。如果成功,则返回Socket对象。
InetAddress是一个用于记录主机的类
,其静态getHostByName(String msg)可以返回一个实例,其静态方法getLocalHost()也可以获得当前主机的IP地址,并返回一个实例。Socket(String host, int port, InetAddress localAddress, int localPort)构造函数的参数分别为目标IP、目标端口、绑定本地IP、绑定本地端口。
Socket方法:
getInetAddress(); 远程服务端的IP地址
getPort(); 远程服务端的端口
getLocalAddress() 本地客户端的IP地址
getLocalPort() 本地客户端的端口
getInputStream(); 获得输入流
getOutStream(); 获得输出流
getInputStream()和getOutputStream()
is improtant!
Socket状态:
isClosed();//连接是否已关闭,若关闭,返回true;否则返回false
isConnect();//如果曾经连接过,返回true;否则返回false
isBound();//如果Socket已经与本地一个端口绑定,返回true;否则返回false
判断Socket的状态是否处于连接中:
boolean isConnection=socket.isConnected() && !socket.isClosed();
半关闭Socket:
很多时候,我们并不知道在获得的输入流里面到底读多长才结束。下面是一些比较普遍的方法:
- 自定义标识符(譬如下面的例子,当受到“bye”字符串的时候,关闭Socket)
- 告知读取长度(有些自定义协议的,固定前几个字节表示读取的长度的)
- 读完所有数据
- 当Socket调用close的时候关闭的时候,关闭其输入输出流
ServerSocket:
构造函数
ServerSocket()throws IOException
ServerSocket(int port)throws IOException
ServerSocket(int port, int backlog)throws IOException
ServerSocket(int port, int backlog, InetAddress bindAddr)throws IOException
注意点:
- port服务端要监听的端口;backlog客户端连接请求的队列长度;bindAddr服务端绑定IP
- 如果端口被占用或者没有权限使用某些端口会抛出BindException错误。譬如1~1023的端口需要管理员才拥有权限绑定。
-
如果设置
端口为0
,则系统会
自动为其分配
一个端口; - bindAddr用于绑定服务器IP,为什么会有这样的设置呢,譬如有些机器有多个网卡。
-
ServerSocket一旦绑定了监听端口,就
无法更改
。ServerSocket()可以实现在绑定端口前设置其他的参数。
单线程的ServerSocket例子:
public void service(){
while(true){
Socket socket=null;
try{
socket=serverSocket.accept();//从连接队列中取出一个连接,如果没有则等待
System.out.println("新增连接:"+socket.getInetAddress()+":"+socket.getPort());
...//接收和发送数据
}catch(IOException e){e.printStackTrace();}finally{
try{
if(socket!=null) socket.close();//与一个客户端通信结束后,要关闭Socket
}catch(IOException e){e.printStackTrace();}
}
}
}
多线程的ServerSocket:
多线程的好处不用多说,而且大多数的场景都是多线程的,无论是我们的即时类游戏还是IM,多线程的需求都是必须的。下面说说实现方式:
- 主线程会循环执行ServerSocket.accept();
- 当拿到客户端连接请求的时候,就会将Socket对象传递给多线程,让多线程去执行具体的操作;
- 实现多线程的方法要么继承Thread类,要么实现Runnable接口。当然也可以使用线程池,但实现的本质都是差不多的。
下面代码为服务器的主线程。为每个客户分配一个工作线程:
public void service(){
while(true){
Socket socket=null;
try{
socket=serverSocket.accept(); //主线程获取客户端连接
Thread workThread=new Thread(new Handler(socket)); //创建线程
workThread.start(); //启动线程
}catch(Exception e){
e.printStackTrace();
}
}
}
当然这里的重点在于如何实现Handler这个类。Handler需要实现Runnable接口:
class Handler implements Runnable{
private Socket socket;
public Handler(Socket socket){
this.socket=socket;
}
public void run(){
try{
System.out.println("新连接:"+socket.getInetAddress()+":"+socket.getPort());
Thread.sleep(10000);
}catch(Exception e){
e.printStackTrace();
}finally{
try{
System.out.println("关闭连接:"+socket.getInetAddress()+":"+socket.getPort());
if(socket!=null)socket.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
}
34.Java命令
- javac.exe是编译.java文件
- java.exe是执行编译好的.class文件
- javadoc.exe是生成Java说明文档
- jdb.exe是Java调试器
- javaprof.exe是剖析工具
35.事务隔离级别
在数据库操作中,为了有效
保证并发读取数据的正确性
,提出的事务隔离级别;为了解决更新丢失,脏读,不可重读(包括虚读和幻读)等问题在标准SQL规范中,定义了4个事务隔离级别,分别为未授权读取,也称为读未提交(read uncommitted);授权读取,也称为读提交(read committed);可重复读取(repeatable read);序列化(serializable).
√: 可能出现 ×: 不会出现
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
问题:事务隔离级别是由谁实现的?
A.Java应用程序
B.Hibernate
C.数据库系统
D.JDBC驱动程序
答案:C
A,我们写java程序的时候只是设定事物的隔离级别,而不是去实现它
B,Hibernate是一个java的数据持久化框架,方便数据库的访问
C,事物隔离级别由数据库系统实现,是数据库系统本身的一个功能
D,JDBC是java database connector,也就是java访问数据库的驱动
九月刷题录
刷面经系列:

1.JDK 和 JRE 有什么区别?
- JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境。
- JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需环境。
具体来说
JDK 其实包含了 JRE
,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
2.== 和 equals 的区别是什么?
== 对于基本类型来说是值比较,对于引用类型来说是比较的是引用;而 equals 默认情况下是引用比较,只是很多类重写了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等。
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
因为在散列表中,hashCode()相等即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等。
4.final 在 java 中有什么作用?
- final 修饰的类叫最终类,该类不能被继承。
-
final 修饰的方法不能被重写,但
能够重载
。 - final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
5.java 中的 Math.round(-1.5) 等于多少?
等于 -1。
6.java 中操作字符串都有哪些类?它们之间有什么区别?
操作字符串的类有:String、StringBuffer、StringBuilder。
String 和 StringBuffer、StringBuilder 的区别在于 String 声明的是不可变的对象,每次操作都会生成新的 String 对象,然后将指针指向新的 String 对象,而 StringBuffer、StringBuilder 可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
StringBuffer 和 StringBuilder 最大的区别在于,StringBuffer 是线程安全的,而 StringBuilder 是非线程安全的,但 StringBuilder 的性能却高于 StringBuffer,所以在单线程环境下推荐使用 StringBuilder,多线程环境下推荐使用 StringBuffer。底层实现上的话,StringBuffer其实就是比StringBuilder多了Synchronized修饰符。
7. final、finally、finalize的区别?
- final修饰符(关键字)如果一个类被声明为final,意味着它不能再派生出新的子类,不能作为父类被继承例如:String类、Math类等。将变量或方法声明为final,可以保证它们在使用中不被改变。被声明为final的变量必须在声明时给定初值,而在以后的引用中只能读取,不可修改。被声明为final的方法也同样只能使用,不能重写,但是能够重载。使用final修饰的对象,对象的引用地址不能变,但是对象的值可以变!
- finally在异常处理时提供 finally块来执行任何清除操作。如果有finally的话,则不管是否发生异常,finally语句都会被执行。一般情况下,都把关闭物理连接(IO流、数据库连接、Socket连接)等相关操作,放入到此代码块中.。
- finalize方法名。Java 技术允许使用 finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要清理工作。finalize() 方法是在垃圾收集器删除对象之前被调用的。它是在Object 类中定义的,因此所有的类都继承了它。子类覆盖 finalize() 方法以整理系统资源或者执行其他清理工作。一般情况下,此方法由JVM调用,程序员不要去调用!
8.什么是自动拆装箱?
自动装箱是Java编译器在基本数据类型和对应的对象包装类型之间做的一个转化。比如:把int转化成Integer,double转化成Double,等等。反之就是自动拆箱。
9.为什么会出现4.0-3.6=0.40000001这种现象?
简单来说:2进制的小数无法精确的表达10进制小数,计算机在计算10进制小数的过程中要先转换为
2进制进行计算
,这个过程中出现了误差。
10.一个十进制的数在内存中是怎么存的?
补码的形式。
负数:补码-1=反码,反码取反等于原码
正数:补码=原码
11.为什么重写equals还要重写hashcode?
HashMap中,如果要比较key是否相等,要同时使用这两个函数!因为自定义的类的hashcode()方法继承于Object类,其hashcode码为默认的内存地址,这样即便有相同含义的两个对象,比较也是不相等的。HashMap中的比较key是这样的,先求出key的hashcode(),比较其值是否相等,若相等再比较equals(),若相等则认为他们是相等的。若equals()不相等则认为他们不相等。如果只重写hashcode()不重写equals()方法,当比较equals()时只是看他们是否为同一对象(即进行内存地址的比较),所以必定要两个方法一起重写。HashMap用来判断key是否相等的方法,其实是调用了HashSet判断加入元素 是否相等。重载hashCode()是为了对同一个key,能得到相同的Hash Code,这样HashMap就可以定位到我们指定的key上。重载equals()是为了向HashMap表明当前对象和key上所保存的对象是相等的,这样我们才真正地获得了这个key所对应的这个键值对。
12.谈一下面向对象的”六原则一法则”。
-
单一职责原则:
一个类只做它该做的事情。
(单一职责原则想表达的就是”
高内聚
“,写代码最终极的原则只有六个字”高内聚、低耦合”,所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。另一个是
模块化
,好的自行车是组装车,从减震叉、刹车到变速器,所有的部件都是可以拆卸和重新组装的,好的乒乓球拍也不是成品拍,一定是底板和胶皮可以拆分和自行组装的,一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现
软件复用
的目标。) -
开闭原则:软件实体应当
对扩展开放,对修改关闭
。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。
要做到开闭有两个要点:
①抽象是关键
,一个系统中如果没有抽象类或接口系统就没有扩展点;
②封装可变性
,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱,如果不清楚如何封装可变性,可以参考《设计模式精解》一书中对桥梁模式的讲解的章节。) -
依赖倒转原则:
面向接口编程
。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。) -
里氏替换原则:任何时候都可以用
子类型替换掉父类型
。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:
子类一定是增加父类的能力而不是减少父类的能力
,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。) -
接口隔离原则:
接口要小而专
,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,
毕竟琴棋书画四样都精通的人还是少数
,而如果设计成四个接口,会几项就实现几个接口,这样的话每个
接口被复用
的可能性是很高的。Java中的接口代表能力、代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。) -
合成聚合复用原则:
优先使用聚合或合成关系复用代码
。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,
工具是可以拥有并可以使用的,而不是拿来继承的
。) -
迪米特法则:迪米特法则又叫最少知识原则,
一个对象应当对其他对象有尽可能少的了解
。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度。
13.面向对象的特征有哪些方面?
(1)封装:
封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面。面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封装的对象,这些对象通过一个受保护的接口访问其他对象。
(2)继承:
继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表述共性的方法。对象的一个新类可以从现有的类中派生,这个过程称为类继承。新类继承了原始类的特性,新类称为原始类的派生类(子类),而原始类称为新类的基类(父类)。派生类可以从它的基类那里继承方法和实例变量,并且类可以修改或增加新的方法使之更适合特殊的需要。
(3) 多态:
多态性是指允许不同类的对象对同一消息作出响应。多态性包括参数化多态性和包含多态性。多态性语言具有灵活、抽象、行为共享、代码共享的优势,很好的解决了应用程序函数同名问题。
14.解释一下extends 和super 泛型限定符
15.解释一下类加载机制,双亲委派模型,好处是什么?
某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
使用双亲委派模型的好处在于Java类随着它的类加载器一起具备了一种带有
优先级的层次关系
。例如类java.lang.Object,它存在在rt.jar中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的Bootstrap ClassLoader进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,那系统中将会出现多个不同的Object类,程序将混乱。因此,如果开发者尝试编写一个与rt.jar类库中重名的Java类,可以正常编译,但是永远无法被加载运行。
16.为什么集合类没有实现Cloneable和Serializable接口?
克隆(cloning)或者是序列化(serialization)的语义和含义是
跟具体的实现相关
的。因此,应该由集合类的具体实现来决定如何被克隆或者是序列化。
Cloneable接口
clone:它允许在堆中克隆出一块和原对象一样的对象,并将这个对象的地址赋予
新的引用
。
Java 中 一个类要实现clone功能 必须实现 Cloneable接口,否则在调用 clone() 时会报
CloneNotSupportedException 异常
。
clone()方法在
java.lang.Object类
中,返回Object对象的一个拷贝。
注意:
-
拷贝对象返回的是一个
新对象
,而不是一个引用; -
拷贝对象与用 new操作符返回的新对象的区别就是这个拷贝
已经包含了一些原来对象的信息
,而不是对象的初始信息。
示例:
class CloneClass implements Cloneable{
public int aInt;
public Object clone(){
CloneClass o = null;
try{
o = (CloneClass)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return o;
}
}
Object类的clone()方法是一个native方法,一个protected属性的方法(意味着如果要应用clone()方法,必须继承Object类)。
Serializable接口:
序列化:对象的寿命通常随着生成该对象的程序的终止而终止,而有时候需要把在内存中的各种对象的状态(也就是实例变量,不是方法)
保存
下来,并且可以在需要时再将对象
恢复
。 Java提供了一种保存对象状态的机制,那就是序列化。
Java 序列化技术可以
将一个对象的状态写入一个Byte 流里(序列化),并且可以从其它地方把该Byte 流里的数据读出来(反序列化)
。
什么时候需要序列化
- 想把内存中的对象状态保存到一个文件中或者数据库中时候;
- 想把对象通过网络进行传播的时候
17.说明一下线程池有什么优势?
- 第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能执行。
- 第三:提高线程的可管理性,线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
18.线程,进程,然后线程创建有很大开销,怎么优化?
使用线程池。
19.介绍一下什么是生产者消费者模式?

生产者和消费者在
同一时间段
内共用
同一存储空间
,生产者向空间里生产数据,而消费者取走数据。
优点:
1、解耦
假设生产者和消费者分别是两个类。
如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。
将来如果消费者的代码发生变化, 可能会影响到生产者。而如果
两者都依赖于某个缓冲区
,
两者之间不直接依赖
,耦合也就相应降低了。
2、支持并发
由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者只需要往缓冲区里丢数据,
就可以继续生产下一个数据,而消费者只需要从缓冲区了拿数据即可,这样就
不会因为彼此的处理速度而发生阻塞
。
3、支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。
当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。 等生产者的制造速度慢下来,消费者再慢慢处理掉。
20.多线程中的i++线程安全吗?请简述一下原因?
不安全。i++不是原子性操作。i++分为读取i值,对i值加一,再赋值给i++,执行期中任何一步都是有可能被其他线程抢占的。
21.深拷贝 vs 浅拷贝
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
-
深拷贝:对基本数据类型进行值传递,对引用数据类型,
创建一个新的对象
,并复制其内容,此为深拷贝。
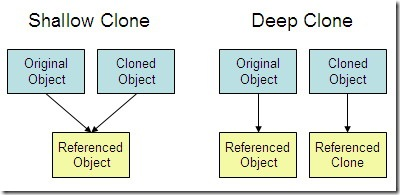
22.谈谈BigDecimal 的用处?
《阿里巴巴Java开发手册》中提到:
浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用 equals 来判断
。 具体原理和浮点数的编码方式有关