1 本地模式
本地模式是最简单的模式,所有模块都运行在一个
JVM
进程中,使用本地文件系统而不是
HDFS
。
本地模式主要是用于本地开发过程中的运行调试用,下载后的
Hadoop
不需要设置默认就是本地模式。
2 准备工作
笔者喜欢把
JDK
放在
/usr/local
下,运行前请确保设置了
JAVA_HOME
,注意是在
etc/hadoop/hadoop-env.sh
中设置:
tar -zxvf openjdk-11+28_linux-x64_bin.tar.gz
sudo mv openjdk-11+28_linux-x64_bin /usr/local/java
sudo vim HADOOP/etc/hadoop/hadoop-env.sh # HADOOP为Hadoop安装目录
# 输入
export JAVA_HOME=/usr/local/java
3 使用
官网关于该模式没有太多的描述,只有一个使用默认配置文件作为输入,然后匹配正则表达式作为输出的简单例子:
# HADOOP表示Hadoop安装目录
mkdir input
cp HADOOP/etc/hadoop/*.xml input
HADOOP/bin/hadoop jar HADOOP/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+'
cat output/*
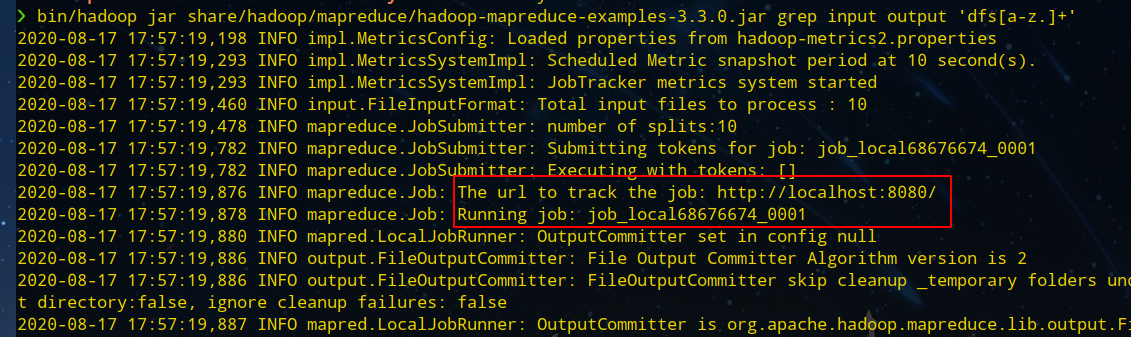
从下图的
id
可以看出是以本地模式工作的:
4 输出
输出文件夹
output
有两个文件:

-
_SUCCESS
:是个空文件,表示运行成功 -
part-r-00000
:输出结果文件,词数统计
part-r-00000
结果如上图所示。
实际上本地模式不需要特别的处理,因为默认就是本地模式。
5 参考
版权声明:本文为qq_27525611原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。