前言:为实现基于数据湖的流批一体,采用业内主流技术栈hudi、flink、CDH(hive、spark)。flink使用sql client与hive的catalog打通,可以与hive共享元数据,使用sql client可操作hive中的表,实现批流一体;flink与hudi集成可以实现数据实时入湖;hudi与hive集成可以实现湖仓一体,用flink实时入湖,用spark跑批处理。由于方案中中采用的CDH6.3.2是官方最后的开源版本,而flink与hudi是社区近期发布的开源版,网上几乎没有关于它们集成的资料,近期为完成它们集成费了不少神,特写出来分享给大家,有问题可一起交流。
以下为实现hudi、flink、CDH(hive、spark)集成的过程:
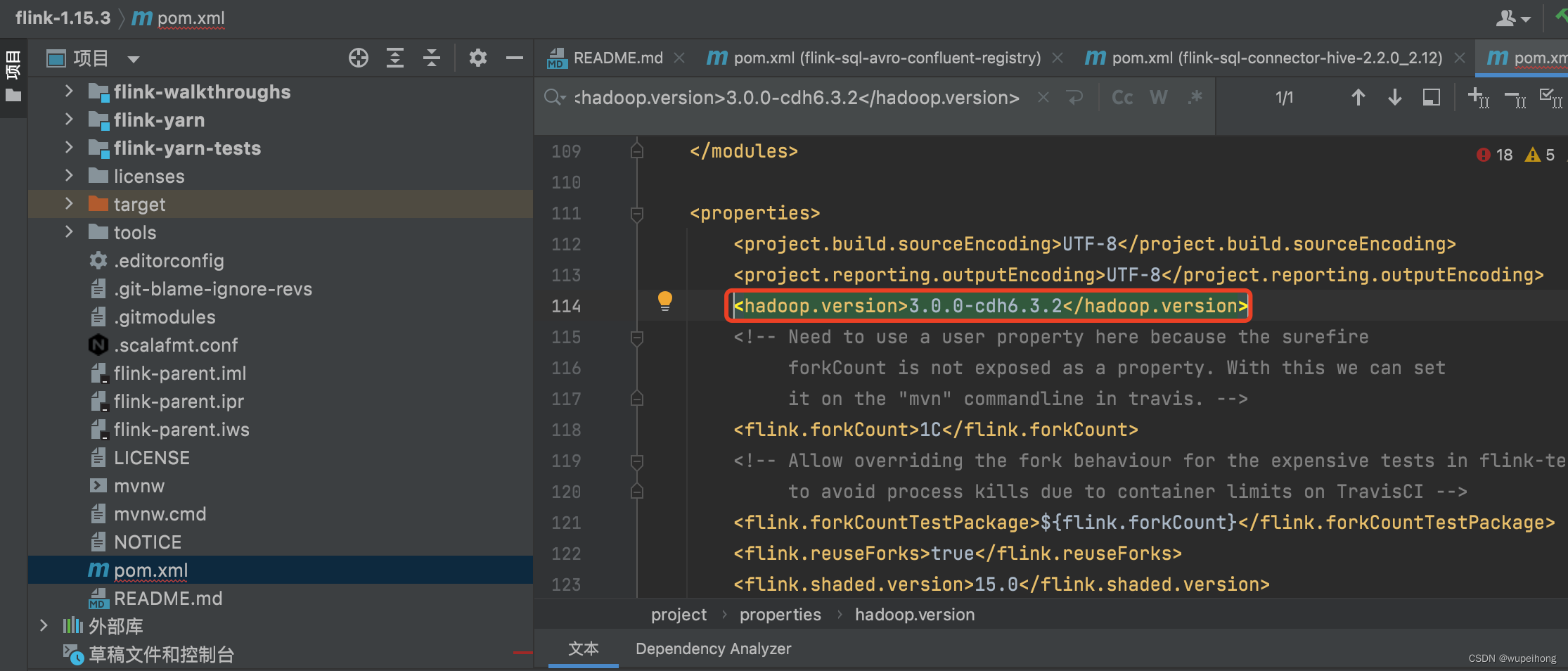
1、由于cdh的Hadoop版本是3.0.0-cdh6.3.2,所以需要重新编译flink-sql-connector-hive-2.2.0,修改内容如下:
1)修改flink-1.15.3/pom.xml的Hadoop.version为3.0.0-cdh6.3.2
2)新增repository
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>

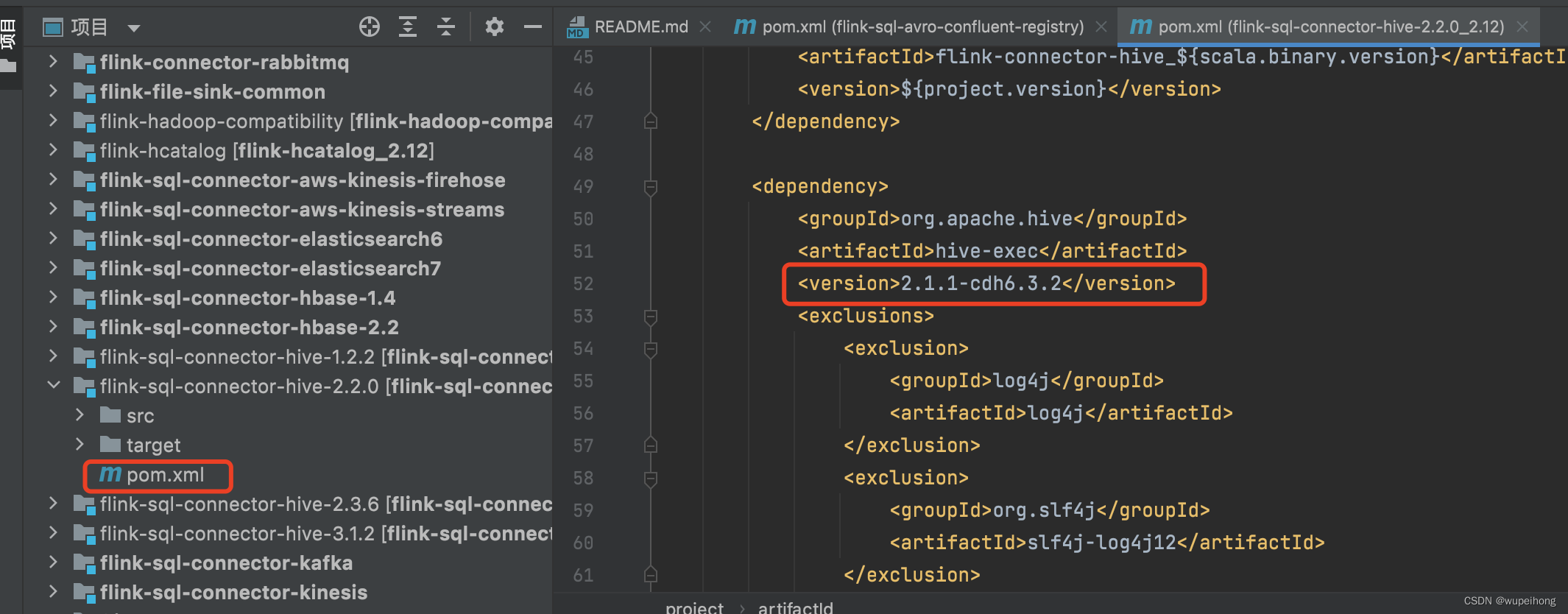
3)修改flink-1.15.3/flink-connectors/flink-sql-connector-hive-2.2.0/pom.xml
2、编译flink-sql-connector-hive-2.2.0,在flink-1.15.3目录执行以下命令:
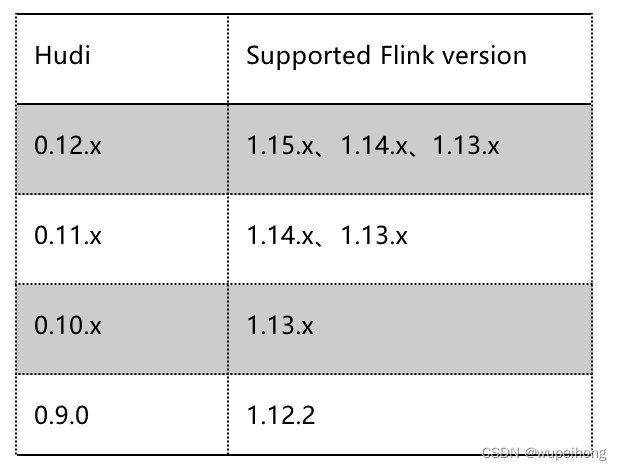
mvn clean install -DskipTests -Dfast -Dhadoop.version=3.0.0-cdh6.3.2 -Dskip.npm idea:idea -pl flink-connectors/flink-sql-connector-hive-2.2.03、部署flink,flink15.3支支持0.12.1版本的hudi
4、flink安装包下载路径
https://dlcdn.apache.org/flink/flink-1.15.3/flink-1.15.3-bin-scala_2.12.tgz
,将下载的安装包,上传到服务目录/opt/modules,执行以下命令:
tar -zcxf flink-1.15.3-bin-scala_2.12.tgz
mv flink-1.15.3-bin-scala_2.1 flink5、上传依赖包到flink的lib中
cp /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/client/guava-11.0.2.jar /opt/modules/flink/lib/
cp /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/lib/libfb303-0.9.3.jar /opt/modules/flink/lib/
cp /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/client/hadoop-mapreduce-client-core-3.0.0-cdh6.3.2.jar /opt/modules/flink/lib/
#上传mysql-connector-java-5.1.47.jar到/opt/modules/flink/lib/中
#上传flink-sql-connector-hive-2.2.0_2.12-1.15.3.jar到/opt/modules/flink/lib/中
#上传hudi-flink1.15-bundle-0.12.1.jar到/opt/modules/flink/lib/中6、配置环境变量
sudo vim /etc/profile
#新增以下环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export HADOOP_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_CONF_DIR=/etc/hive/conf
export HIVE_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive
source /etc/profile
7、修改flink-conf.yaml配置
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 4
state.backend: rocksdb
execution.checkpointing.interval: 30000
state.checkpoints.dir: hdfs://hadoop01:8020/ckps
state.backend.incremental: true
#为解决异常:flink you can disable this check with the configuration ‘classloader.check-leaked-classloader‘,增加以下配置
classloader.check-leaked-classloader: false
8、创建sql-client初始化脚本
vim /opt/modules/flink/conf/hive_catalog.sql
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/etc/hive/conf'
);
USE CATALOG hive_catalog;9、启动Flink的sql-client
chmod 777 /opt/modules/flink/log/flink-hive-sql-client-hadoop01.log
chmod 777 /opt/modules/flink/log
/opt/modules/flink/bin/sql-client.sh embedded
/opt/modules/flink/bin/sql-client.sh embedded -i /opt/modules/flink/conf/hive_catalog.sql -s yarn-session10、Flink的sql-clinet的使用
#查看数据库
show databases;
#切换数据库
use hudi;
#查看表
show tables;
#创建mor表并关闭compaction,因为每次compaction需要消耗大量内存,干扰写流程,采用离线compaction任务更稳定
CREATE TABLE ods_hudi_flink (
id int PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
price int,
ts int,
dt VARCHAR(10))
PARTITIONED BY (dt)
WITH ('connector' = 'hudi',
'path' = 'hdfs://hadoop01:8020/user/hive/hudi/ods_hudi_flink',
'table.type' = 'MERGE_ON_READ',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hoodie.parquet.compression.codec'= 'snappy',
'write.operation' = 'upsert',
'compaction.async.enabled' = 'false',
'compaction.schedule.enabled' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hadoop01:9083',
'hive_sync.conf.dir'='/etc/hive/conf',
'hive_sync.db' = 'hudi',
'hive_sync.table' = 'ods_hudi_flink',
'hive_sync.partition_fields' = 'dt',
'hive_sync.assume_date_partitioning' = 'false',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor',
'hive_sync.support_timestamp'= 'true'
);
#插入数据
insert into ods_hudi_flink values (1,'hudi1',5,10,'2023-1-31'),(2,'hudi2',10,10,'2023-1-31');
#在flink中查询
set sql-client.execution.result-mode=tableau;
select * from ods_hudi_flink;
#在hive中查询,由于该表配置了离线compaction,所以需要做compaction以后才能查询
/opt/modules/flink/bin/flink run -c org.apache.hudi.sink.compact.HoodieFlinkCompactor /opt/modules/flink/lib/hudi-flink1.15-bundle-0.12.1.jar --path hdfs://hadoop01:8020/user/hive/hudi/ods_hudi_flink
#注意:接入无界流可以在表中配置自动compaction
#在hive中生产两个表ods_hudi_flink_ro,ods_hudi_flink_rt,增量数据写入ods_hudi_flink_rt,执行compaction后数据会写入ods_hudi_flink_ro,执行compaction前数据记录在log中,执行compaction后记录写到parquet文件
#cow模式建表示例
CREATE TABLE test_user2 (
id int PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
city varchar(100),
dt VARCHAR(10))
PARTITIONED BY (dt)
WITH ('connector' = 'hudi',
'path' = 'hdfs://hadoop01:8020/user/hive/hudi/test_user2',
'table.type' = 'COPY_ON_WRITE',
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.ComplexAvroKeyGenerator',
'hoodie.datasource.write.recordkey.field' = 'id',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'hoodie.parquet.compression.codec'= 'snappy',
'write.operation' = 'upsert',
'hive_sync.enable' = 'true',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hadoop01:9083',
'hive_sync.conf.dir'='/etc/hive/conf',
'hive_sync.db' = 'hudi',
'hive_sync.table' = 'test_user2',
'hive_sync.partition_fields' = 'dt',
'hive_sync.assume_date_partitioning' = 'false',
'hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.HiveStylePartitionValueExtractor',
'hive_sync.support_timestamp'= 'true'
);