1、背景
集群有一个
spark sql
的任务,每天需要跑38561秒,噢,来计算一下38561/60/60 这就是10.7个小时呀,就是下面那这种样子:

2、排查过程
2.1 查看任务日志
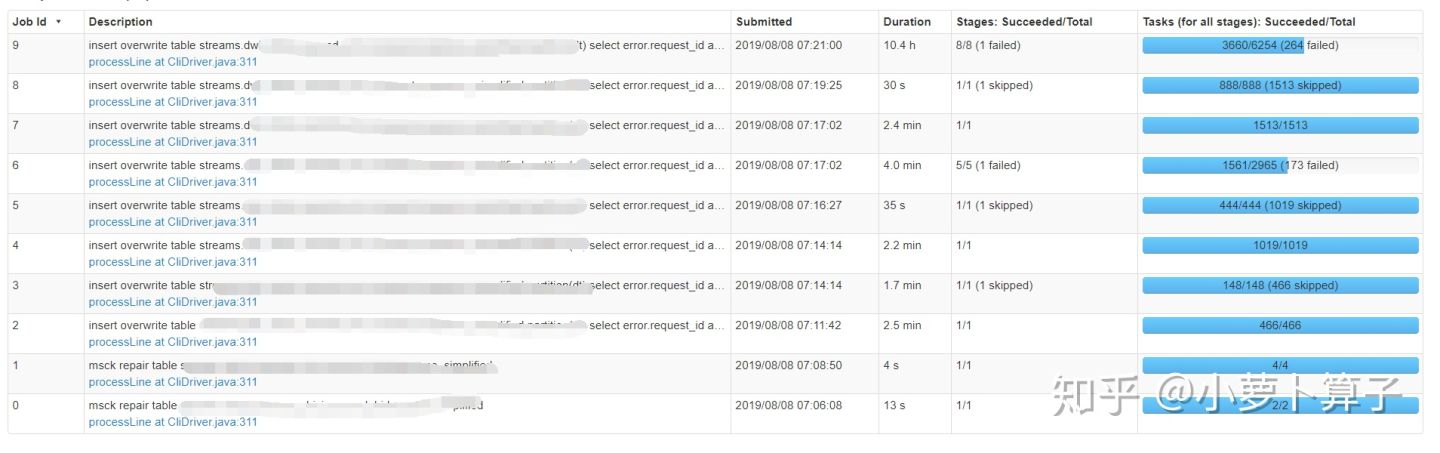
发现第9个job跑了10.4h,那一定就是这个job有问题了,点进去继续看
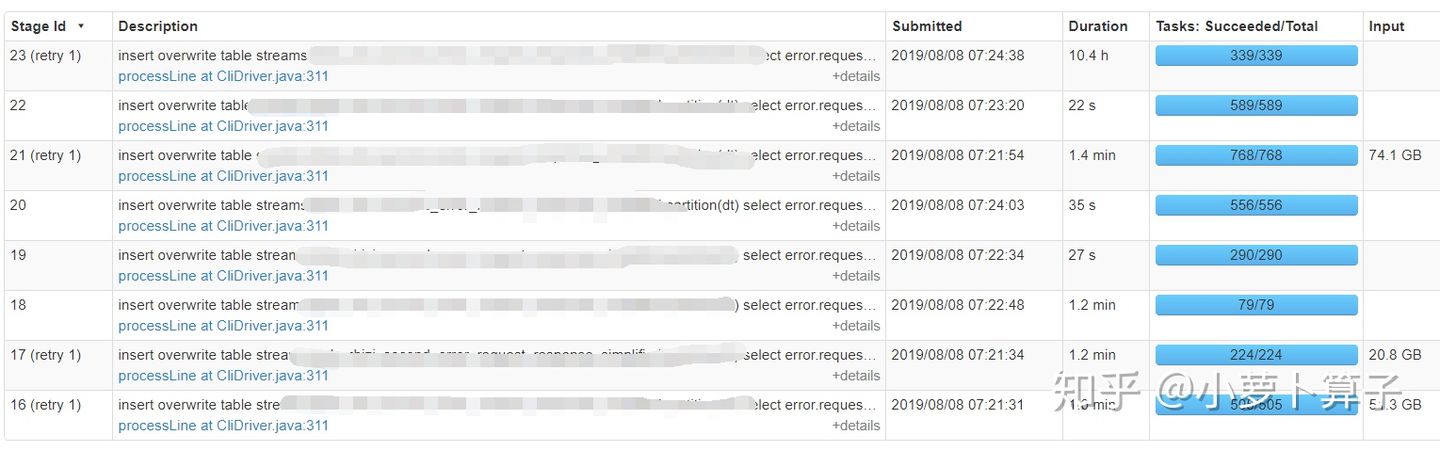
Stage_id
为23的运行了10.4h,其它的只用不到2min,点进去继续看
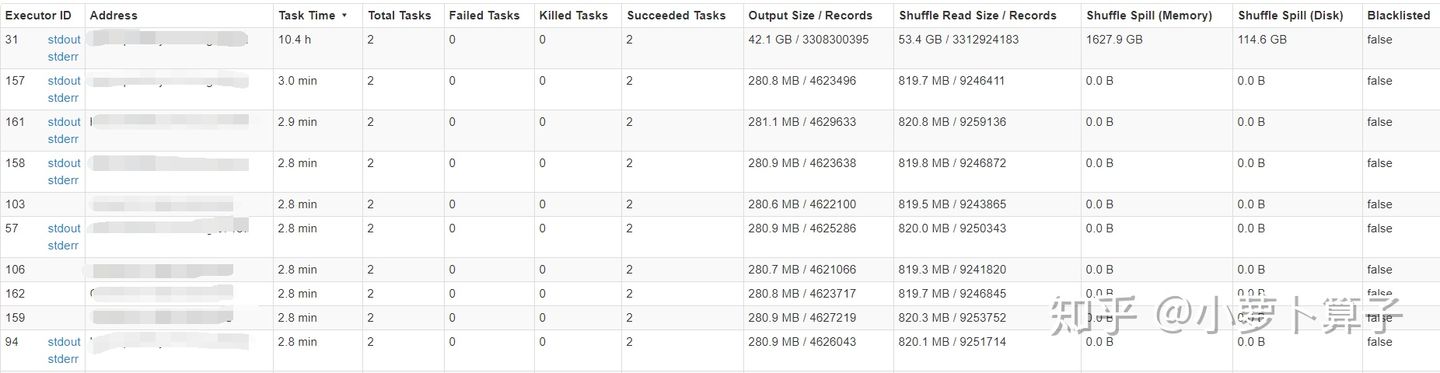
按照
Task Time
倒序排列,发现有个服务器运行了10.4h,并且
shuffle spill
了1T多的数据,没得说,老毛病,肯定是数据倾斜,继续巴拉巴拉日志

发现该服务除了出现少数几次
OutOfDirectMeoryError
外大部分的时间,都在写磁盘,从上午8点多写到下午5点47,这就更确认之前的假设是对的,数据倾斜。
2.2 数据倾斜发生的原因
数据倾斜的原因很简单:在进行
shuffle
的时候,必须将各个节点上相同的
key
拉取到某个节点上的一个
task
来进行处理,比如按照
key
来聚合或者
join
的时候,这时如果某个
key
对应的数据量特别大的话,就会发生数据倾斜。 比如 大部分
key
对应10条数,而某个
key
却对应几百万条数,那么大部分
task
可能就只会分配到10条数据,然后1秒钟就运行完了;但是某个
task
可能分配到了几百万 条数据,要运行好几个小时。
整个Spark作业的运行进度是由运行时间最长的那个task决定的。因此出现数据倾斜的时候,Spark作业看起来会运行的异常缓慢,甚至可能因为某个
task
处理的数据量过大导致内存溢出。
数据倾斜发生在shuffle过程中。常用的并且可能会触发shuffle操作的算子:
distinct
、
groupByKey
、
reduceByKey
、
aggregateByKey
、
join
、
cogroup
、
repartition
等。出现数据倾斜时,可能就是sql中用到这其中某个算子导致的。
2.3 业务背景
大致的业务背景如下:
request
–> 广告竞价发出的request请求相关信息
response
–>广告竞价对request的响应信息
error
–> 错误的request信息
现在需要把这三个信息融合在一起,简化后的原sql如下:
select
error.request_id as error_request_id,
req.request_id,
req.deviceid
from
(
select
didmd5 as deviceid,
request_id
from request where dt = '2019-08-07' and request_id<>'1'
) req full join
(
select
request_id
from error where dt = '2019-08-07' and request_id<>'1'
) error on error.request_id=req.request_id
left outer join
(
select
didmd5 ,
request_id
from response where dt = '2019-08-07' and request_id<>'1' and didmd5 <> '1'
) res on req.deviceid=res.didmd5 and req.request_id = res.request_id
非常简洁的三张表关联,有两个
join
操作,
request
与
error
进行
full join
,再与
response
进行
left join
2.4 确认问题
看一下执行计划:
"== Physical Plan ==
*(8) Project [request_id#139230 AS error_request_id#139207, request_id#139217, deviceid#139206]
+- SortMergeJoin [deviceid#139206, request_id#139217], [didmd5#139263, request_id#139277], LeftOuter
:- *(5) Sort [deviceid#139206 ASC NULLS FIRST, request_id#139217 ASC NULLS FIRST], false, 0
: +- Exchange(coordinator id: 359321552) hashpartitioning(deviceid#139206, request_id#139217, 4096), coordinator[target post-shuffle partition size: 67108864]
: +- SortMergeJoin [request_id#139217], [request_id#139230], FullOuter
: :- *(2) Sort [request_id#139217 ASC NULLS FIRST], false, 0
: : +- Exchange(coordinator id: 1640930436) hashpartitioning(request_id#139217, 4096), coordinator[target post-shuffle partition size: 67108864]
: : +- *(1) Project [didmd5#139216 AS deviceid#139206, request_id#139217]
: : +- *(1) Filter (isnotnull(request_id#139217) && NOT (request_id#139217 = 1))
: : +- *(1) FileScan parquet streams.request[didmd5#139216,request_id#139217,dt#139225,dt_hour#139226]
: +- *(4) Sort [request_id#139230 ASC NULLS FIRST], false, 0
: +- Exchange(coordinator id: 1640930436) hashpartitioning(request_id#139230, 4096), coordinator[target post-shuffle partition size: 67108864]
: +- *(3) Project [request_id#139230]
: +- *(3) Filter (isnotnull(request_id#139230) && NOT (request_id#139230 = 1))
: +- *(3) FileScan parquet streams.error[request_id#139230,dt#139233]
+- *(7) Sort [didmd5#139263 ASC NULLS FIRST, request_id#139277 ASC NULLS FIRST], false, 0
+- Exchange(coordinator id: 359321552) hashpartitioning(didmd5#139263, request_id#139277, 4096), coordinator[target post-shuffle partition size: 67108864]
+- *(6) Project [didmd5#139263, request_id#139277]
+- *(6) Filter (((isnotnull(didmd5#139263) && isnotnull(request_id#139277)) && NOT (request_id#139277 = 1)) && NOT (didmd5#139263 = 1))
+- *(6) FileScan parquet streams.response[didmd5#139263,request_id#139277,dt#139284,dt_hour#139285]
三次
join
执行的顺序:
request
与
error
进行
full join
生成中间数据,中间数据再与再与
response
进行
left join
。
由于三张表的数据量巨大,都在20亿以上,其中
error
表超过了30亿条数据,对于大表关联,spark选择
SortMergeJoin
实际上,从服务器的日志就可以知道是最后一个
stage
出了问题,基本就可以推测是最后的
left join
有问题。
不放心,我们再确认一下这三张表 key值的分布,发现,三张表的关联键
request_id
都是唯一的,说明这三张表单表关联都是没问题的。
那就是说
request
和
error
进行
full join
之后出现了key值分布不均匀的问题,用
request
和
error
两表
join
发现这两个真正关联上的数很少,只有1000多万,这就导致了两表
full join
之后,
request.request_id
的值有将近30亿的
null
,最后又用
request.request_id
与
response.request_id
关联,那30多亿的
null
值就发生了倾斜,如果下图:
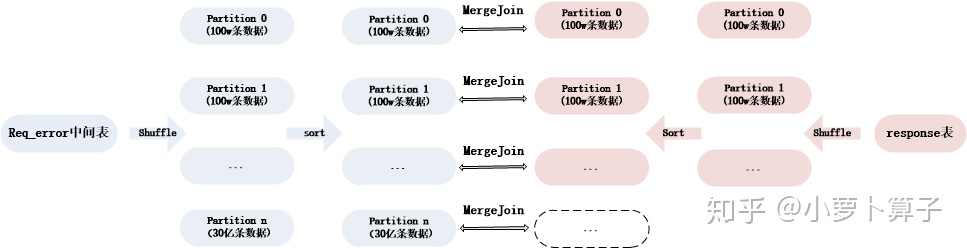
SortMergeJoin
整个过程分为三个步骤:
-
shuffle阶段:将两张大表根据
request_id
进行分区,两张表数据会分布到整个集群,以便分布式并行处理 - sort阶段:对单个分区节点的两表数据,分别进行排序
-
merge阶段:对排好序的两张分区表数据执行
join
操作。
join
操作很简单,分别遍历两个有序序列,碰到相同
join key
就
merge
输出,否则取更小一边
3、解决方案
- 方案一:修改sql的关联顺序
select
error.request_id as error_request_id,
req.request_id,
req.deviceid
from
(
select
didmd5 as deviceid,
request_id
from request where dt = '2019-08-07' and request_id<>'1'
) req left outer join
(
select
didmd5 ,
request_id
from response where dt = '2019-08-07' and request_id<>'1' and didmd5 <> '1'
) res on req.deviceid=res.didmd5 and req.request_id = res.request_id
full join
(
select
request_id
from error where dt = '2019-08-07' and request_id<>'1'
) error on error.request_id=req.request_id
在考察数据时发现,
request
与
error
大部分数据关联不上,但是与
response
有98%以上的数据能关联上,那就先
left join
,再
full join
。这样以来,
request.request_id
做为左表的字段,都不会为
null
并且还唯一,最重要的是,在再行
full join
的时候,数据不会膨胀。
- 方案二:不改变原来的sql顺序,left join 的key值如果为null,用随机数来代替
这种方式虽然能解决数据倾斜问题,但在这次优化中不算最优方案,先
full join
数据会膨胀至50亿,这样是不明智的选择
