
前几天学习了怎么使用HDFS,今天稍微深入一下,HDFS是怎么工作的;
HDFS读取数据的方式:
以下是极简的读取数据:
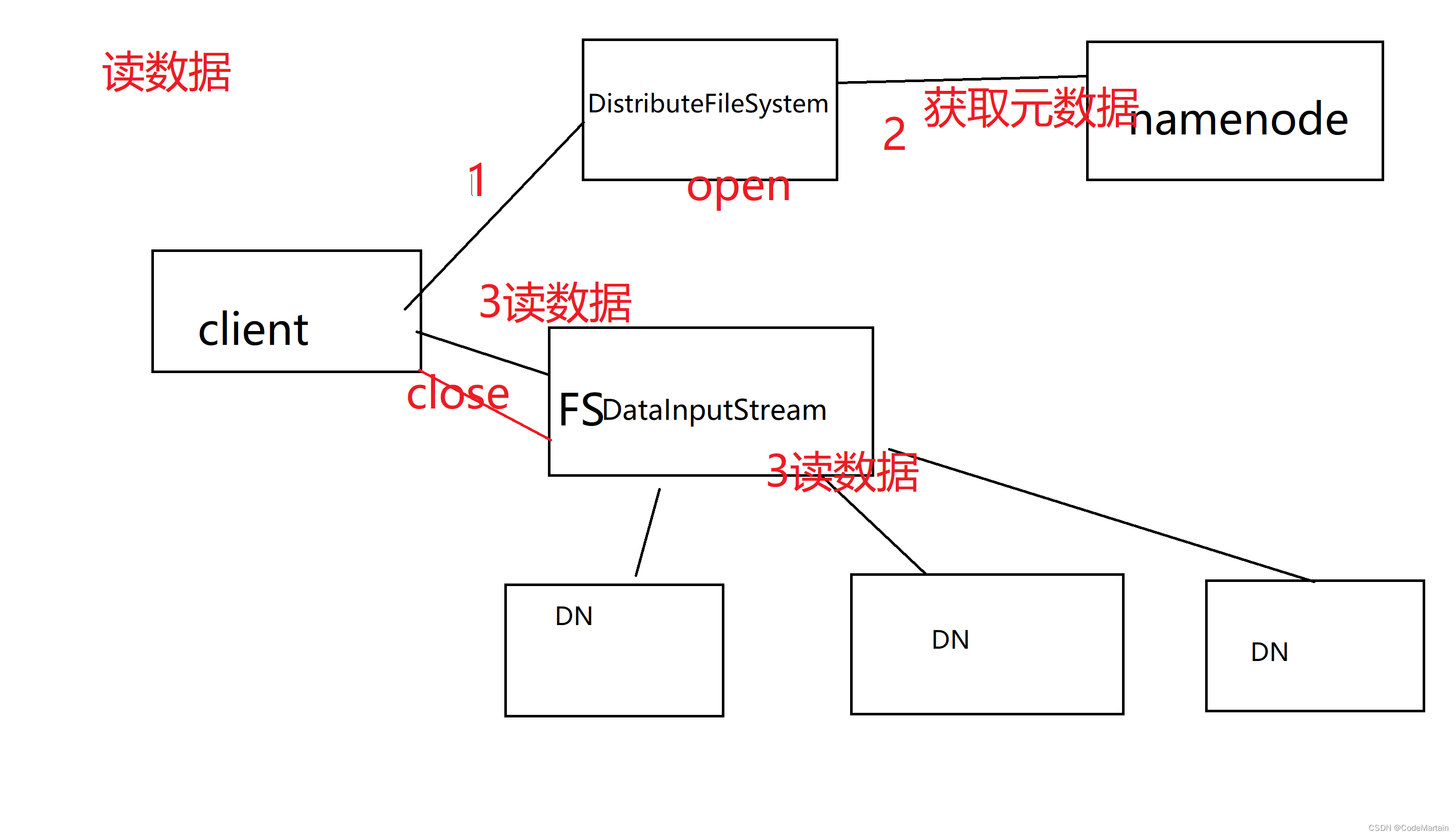
客户端读取数据,首先通过DistributefileSystem 获取数据的元数据(即元数据存在哪里)
为了加快读取速度,首先考虑读取位置离客户端最近的 数据,那怎么判断呢?
通过一个关于位置的API来获取数据存储的位置(机架号) ,通过对比客户端所在机架号跟数据所在机架号,如果一致则优先读取,否则就会随机读取;
其中我们编写代码时是通过FsDatainputStream,其实现了hadoop中的dfsDataInputStream
HDFS写入数据
那怎么写入数据呢?
还是这些组件,只不过在写入的时候是串联的方式,
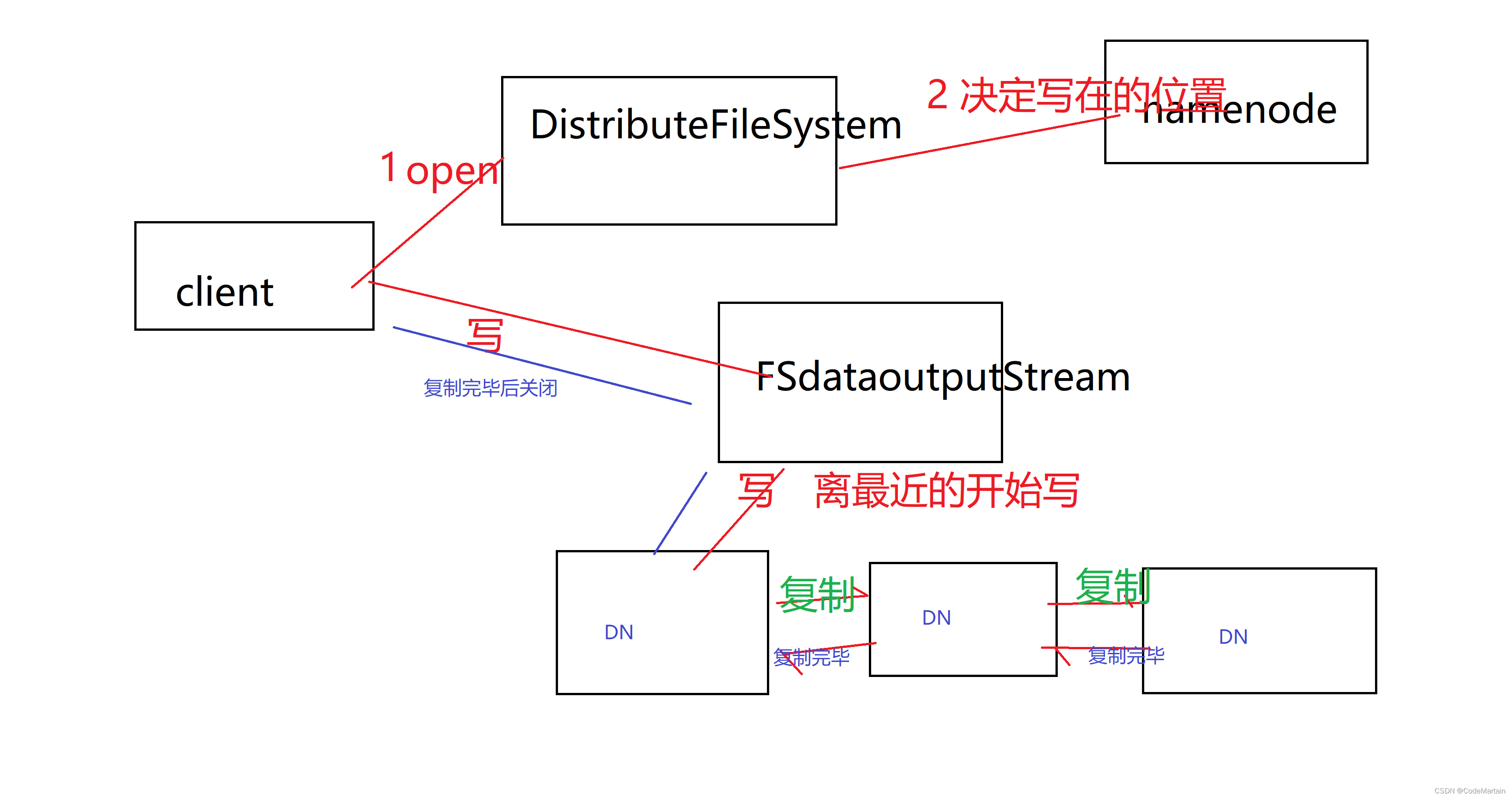
写的时候先检查有没有写的权限,有权限之后检查是不是已经写了(重名的),然后开始写,首先是写入离自己近的机架,写入第一个后返回写入成功,然后由第一个赋值给第二个,完成后第二个发送通知给第一个,以此类推,直到所有的节点都写完了;
如果集群出现问题怎么办?
<
版权声明:本文为weixin_54061333原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。