一、read_table/read_csv常用函数参数
1、path:表明文件系统位置的字符串、url或文件型对象

2、sep或delimiter:用于分隔每行字段的字符序列或正则表达式

3、header:用作列名的行号,默认是0(第一行),如果没有列名的话,应该指定为None

4、names:结果的列名列表,和header=None一起用。
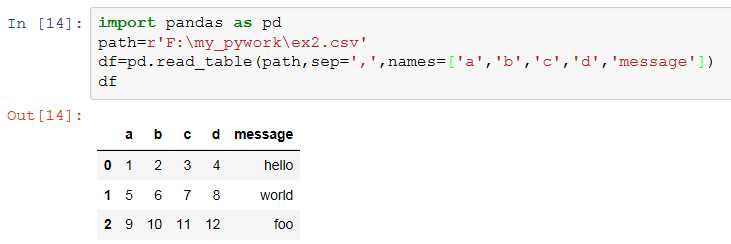
5、index_col: 用作结果中行索引的列号或列名,可以是一个单一的名称/数字,也可以是一个分层索引。


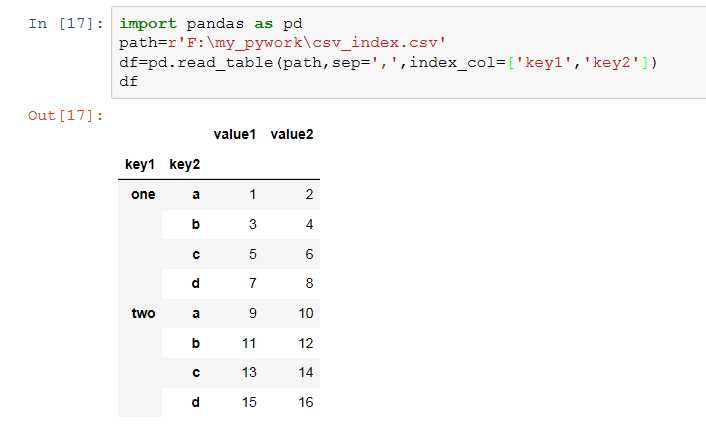
6、skiprows:从文件开头处起,需要跳过的行数或行号列表。

7、na_values:需要用NA替换的值序列。

缺失值默认显示为NULL(用NAN表示)
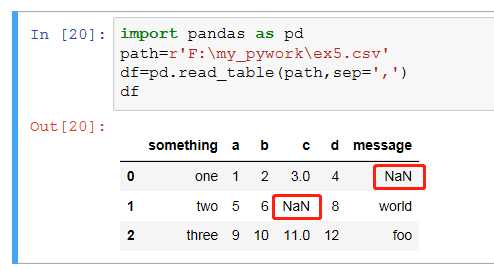
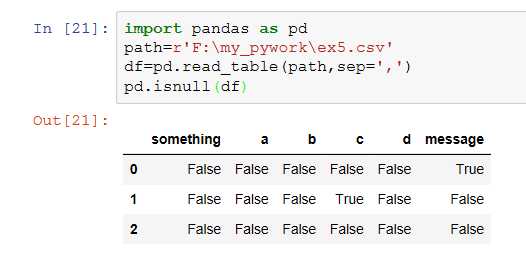
na_nalues指定缺失值显示为NULL(用NAN表示)

通过字典形式,na_values可指定不同列缺失值显示为不同的值

8、nrows:分块读入文件
max_rows:在尝试大文件之前,我们可以先对pandas的显示设置进行调整,使之更为紧凑
如果指向读取一小部分行,可以指明nrows:



原文:https://www.cnblogs.com/dlp-527/p/11824875.html