开发环境:Win10
开发环境:STS
概要:此篇文章主要是传统的Mysql查询和ES查询两种方式的效率比较,以及代码实现,另外使用logstash进行mysql数据的同步也可以直接理解为“数据同步中间件”,还有ik分词器,至于什么是分词器查询,举个例子:假如属于”我是中国人“这几个字,按照我们口语的描述其实可以分为“我”,“是“,”中国人“,”中国“,”人“等待这些吧,但是代码呢只会一个字一个字输出,ik分词器查询就是把冰冷的代码输出更友好的表达。
上一篇已经详细的讲了ElasticSearch + Kibana + logstash安装的方式,这篇主要讲实战,其实博主也就这两天的学习时间,对于ElasticSearch + Kibana + logstash可以说仅仅是很片面的理解,但是博主一直觉得实战验证真理,当然不是说上来就让你来做,基本的学习了解还是必要的,其它可以多看看其它详细的博客,跟着实际项目去理解会更好。
测试方式可以使用postman或者kibana的可视化页面,都可以,新手建议使用kibana,第一了解一下这个怎么使用,不然不白下了,而且kibana会有自动联想提示的功能,用起来更方便。
先说使用kibana进行简单的创建索引、查看索引、更新索引、删除索引。

新建索引,使用PUT的方式,而且不需要前面的http:ip+port,它会自动根据你启动的页面找到你的IP信息

添加索引,看下图中肯定有疑问为什么要有“_doc”,因为在新的版本中一个索引只有一个type,所以都可以称之为_doc,并且官方也是这么建议的。
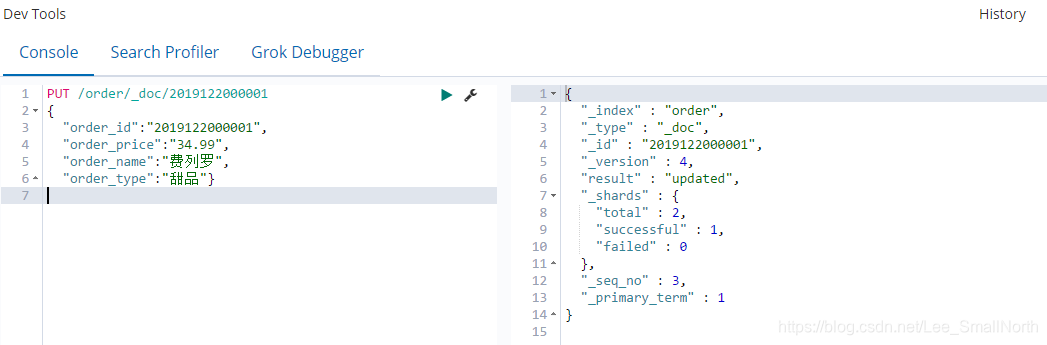
查看索引1,根据id查看单条索引
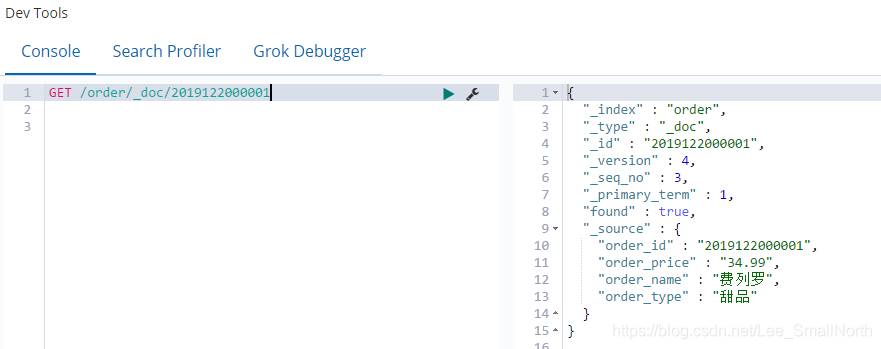
查看索引2,根据任意条件查询

查看索引3,查询该索引下所有数据

上述几种方法一学就会,毫无难度的,下面的写法才是刚开始。。

解释一下,每行代表什么意思
query:查询语句
bool:bool类型,查询要么对要么错
should:应该要去做什么事情
match:匹配哪一个字段和值
此处有两个知识点:
- match:可以有多个,可以看到should是一个数组的形式
- should:就相当于sql语句中的OR
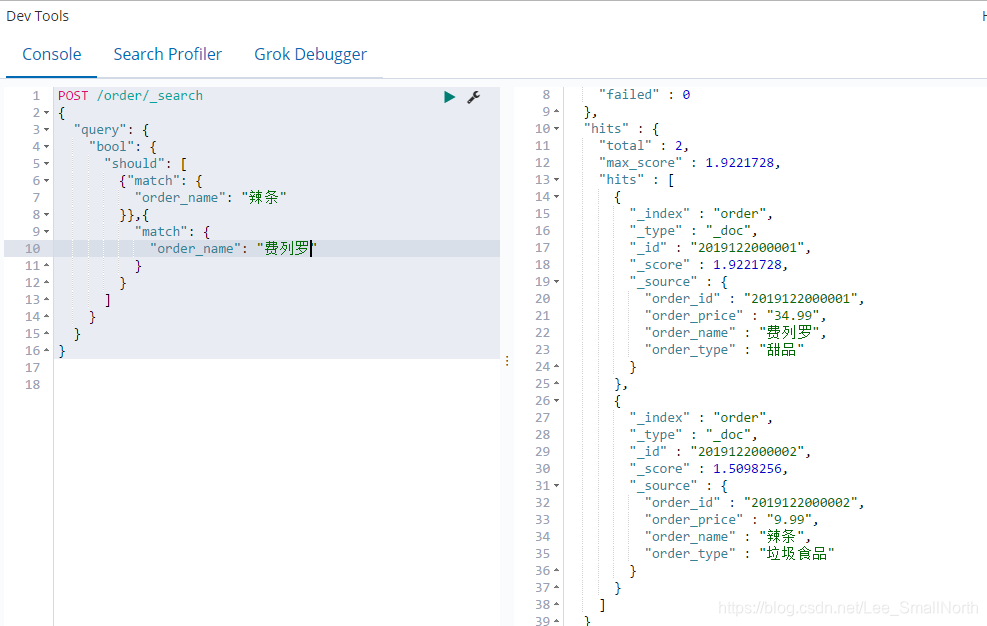
如果想使用类似AND的方法,把should改成must就可以了,可以看到有几个方法,都可以试一试,must_not肯定就是不等于的意思啦

修改和新增数据差不多,都是根据主键来的
删除索引,我这里单独创建了一个索引,演示使用的,不然我还得重新添加数据,见谅~

基础的Dev Tools增删查改就这些例子,还有很多大家可以自己深入研究,因为我也还是个二把手,写博客主要还是给自己当笔记为主,要是还能帮到别人那荣幸之至。
logstash
安装的问题说过了,还是要提一下,版本一定要与es,kibana一致,安装完毕解压~
目录结构一样:
主要说一下,是与mysql进行数据同步的,那么就需要mysql的jar,下载地址:
http://central.maven.org/maven2/mysql/mysql-connector-java/
再次叨叨两句,mysql.jar包的版本一定要高一点,和你的es和logstash版本差不多或者高于,否则会有一些错误,博主之前就是遇到过,版本低导致同步一致出错。
那么有个问题,logstash是怎么实现与mysql的数据进行同步的?
其实,我们都知道mysql有一种日志叫做binlog,简单理解二进制日志记录文件,logstash也就是基于binlog去进行数据同步的,说到binlog第一想到的就是主从复制,logstash也就是把自己伪装成一个slave节点(从节点)来同步数据。
既然是同步,就会有两个常见的名词,全量和增量:
全量很好理解,一次性把所有数据打包,同步到es
增量就是新插入数据和以前的老数据得到了修改或删除,那么就可以通过id或者时间标识字段来进行数据增量
下载完成将mysql.jar包放置bin同级,在config包下新建mysql.conf文件,文件内容:
input{
jdbc{
type => "jdbc"
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/localbase?serverTimezone=UTC&characterEncoding=UTF-8&autoReconnect=true"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "G:\\ES\\logstash-6.7.2\\mysql-connector-java-8.0.12.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
connection_retry_attempts => "3"
jdbc_validate_connection => "true"
jdbc_validation_timeout => "3600"
clean_run => true
schedule => "* * * * *"
statement => "select * FROM t_blog WHERE update_time > :sql_last_value AND update_time < NOW() ORDER BY update_time desc"
}
}
output{
elasticsearch{
hosts =>["127.0.0.1:9200"]
index => "blog"
document_id => "%{id}"
}
}上述常用的都能看懂,主要的几个说一下:
1.clean_run:清除上一次sql_last_value的数据,sql_last_value也就相当于一个游标,记录上一次同步的数据位置
2.schedule => "* * * * *":定时任务,多久一次查询,默认是一分钟,* * * * *表示实时
3.index => "blog" :索引,我们上述创建了order这个索引,这里操作方式一样,在此就使用它为例子
4.document_id => "%{id}":document_id 是es中的id,意思就是把mysql的id值当作document_id 配置完毕,开始启动logstash,说一下,logstash启动方式和es/kibana不一样的哦,要指定配置文件路径
先cmd切到logstash/bin路径下,命令:
logstash -f ../config/mysql.conf当控制台看到执行了配置文件中的sql 就表示已经启动成功了。

再到kibana的控制台看一下是否成功了,看到下图表示已经成功了。
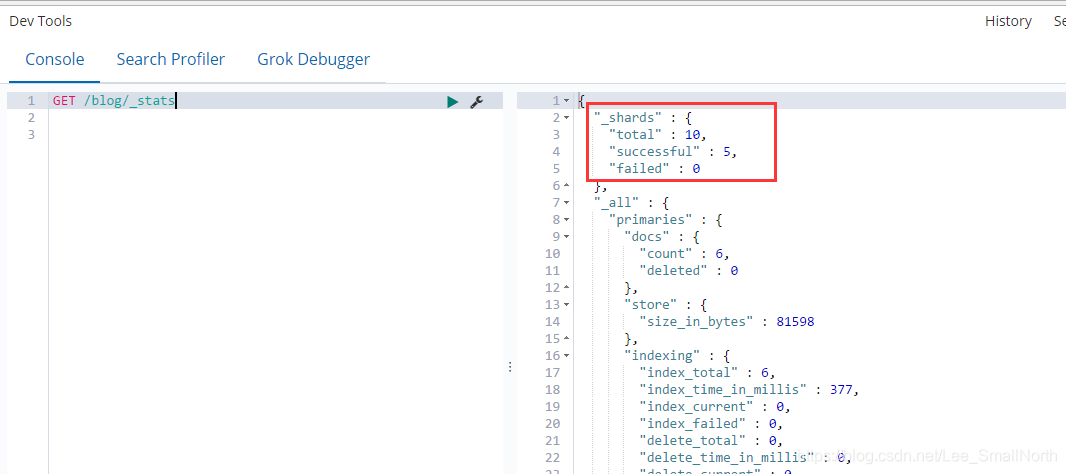
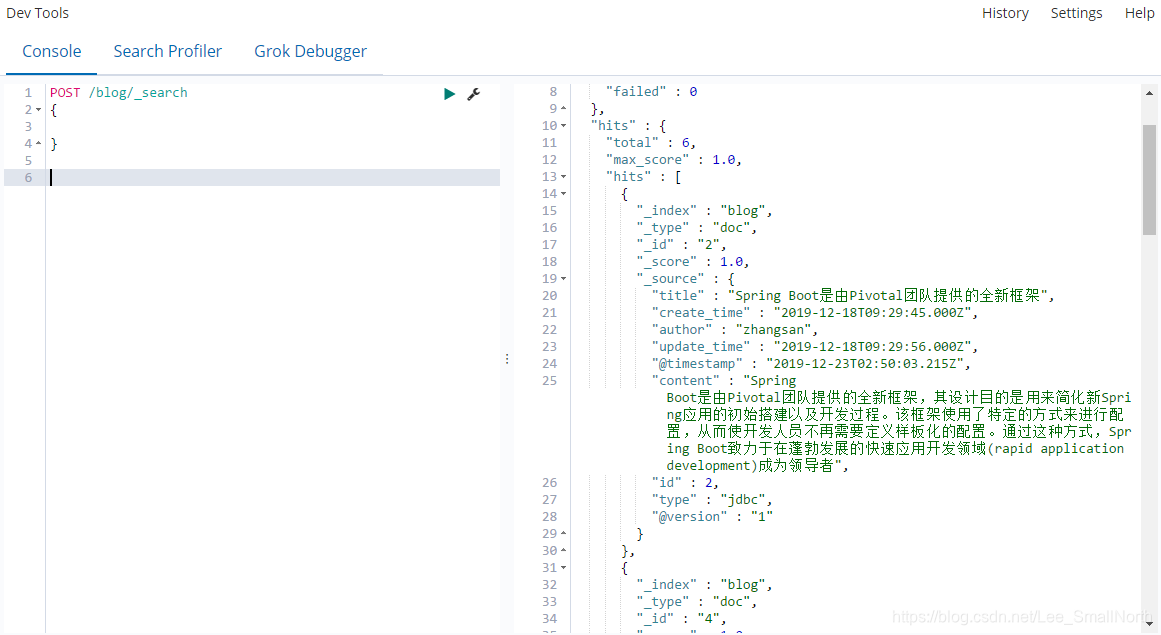
那再来看一下数据,确定是否真的成功了。
ik分词器
概念:至于什么是分词器查询,举个例子:假如属于”我是中国人“这几个字,按照我们口语的描述其实可以分为“我”,“是“,”中国人“,”中国“,”人“等待这些吧,但是代码呢只会一个字一个字输出,ik分词器查询就是把冰冷的代码输出更友好的表达。
先看一下,这冰冷智障的原始分词查询处理的结构
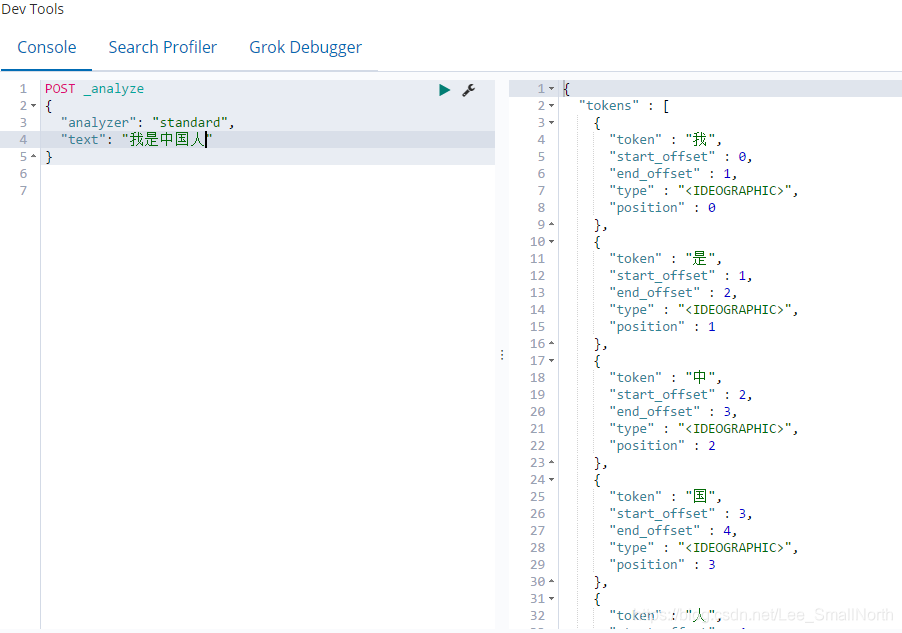
下载ik
gihub地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases
已经有很多个版本了,下载和es保持版本一致的即可。下载完成,解压把所有的文件拷贝到
G:\ES\elasticsearch-6.7.2\plugins ES安装路径的plugins下,可以新建一个文件夹专门存放。然后重启es
好了,我们再次使用kibana来看一下分词效果,ik中提供了两种分词方法:
第一种:ik_smart

第二种:ik_max_word 更智能
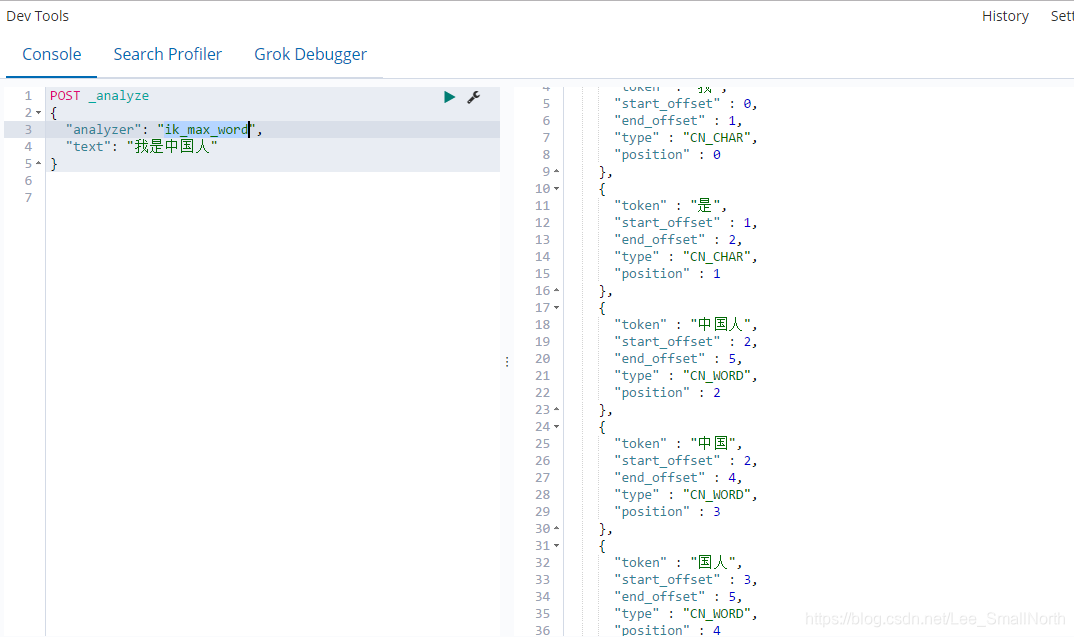
这些东西怎么说的,实现的方式确实让知道真相的我眼泪留下来,就是在config下,有很多txt文件,打开后你会惊喜的发现,都是在文档中整理好了,如果你不信,你可以随便写一句话,并且在main.txt最下面手动配置你的内容,一样可以实现分词效果。
惊不惊喜?意不意外?
以上说完了,实战代码要来了,做一个博客的查询
建表:直接sql脚本
/*
Navicat MySQL Data Transfer
Source Server : localhost_3306
Source Server Version : 80013
Source Host : localhost:3306
Source Database : localbase
Target Server Type : MYSQL
Target Server Version : 80013
File Encoding : 65001
Date: 2019-12-23 11:46:56
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for t_blog
-- ----------------------------
DROP TABLE IF EXISTS `t_blog`;
CREATE TABLE `t_blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(60) DEFAULT NULL COMMENT '博客标题',
`author` varchar(60) DEFAULT NULL COMMENT '作者',
`content` mediumtext COMMENT '内容',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_blog
-- ----------------------------
INSERT INTO `t_blog` VALUES ('1', 'springboot入门', 'lixiaobei', 'springboot是Java的微服务', '2019-12-17 15:38:53', '2019-12-17 15:38:56');
INSERT INTO `t_blog` VALUES ('2', 'Spring Boot是由Pivotal团队提供的全新框架', 'zhangsan', 'Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者', '2019-12-18 09:29:45', '2019-12-18 09:29:56');
INSERT INTO `t_blog` VALUES ('3', 'Spring框架', 'baidu', 'Spring框架是Java平台上的一种开源应用框架,提供具有控制反转特性的容器', '2019-12-18 09:30:24', '2019-12-18 09:30:27');
INSERT INTO `t_blog` VALUES ('4', 'SpringBoot简介', 'baidubaike', 'SpringBoot是由Pivotal团队在2013年开始研发、2014年4月发布第一个版本的全新开源的轻量级框架。它基于Spring4.0设计,不仅继承了Spring框架原有的优秀特性,而且还通过简化配置来进一步简化了Spring应用的整个搭建和开发过程。另外SpringBoot通过集成大量的框架使得依赖包的版本冲突,以及引用的不稳定性等问题得到了很好的解决', '2019-12-17 09:30:59', '2019-12-18 09:31:03');
INSERT INTO `t_blog` VALUES ('5', 'SpringBoot所具备的特征有:', 'airuike', '(1)可以创建独立的Spring应用程序,并且基于其Maven或Gradle插件,可以创建可执行的JARs和WARs;\r\n(2)内嵌Tomcat或Jetty等Servlet容器;\r\n(3)提供自动配置的“starter”项目对象模型(POMS)以简化Maven配置;\r\n(4)尽可能自动配置Spring容器;\r\n(5)提供准备好的特性,如指标、健康检查和外部化配置;\r\n(6)绝对没有代码生成,不需要XML配置', '2019-12-18 14:12:17', '2019-12-27 14:12:12');
INSERT INTO `t_blog` VALUES ('6', 'SpringBoot框架中还有两个非常重要的策略', 'jiutong', 'SpringBoot框架中还有两个非常重要的策略:开箱即用和约定优于配置。开箱即用,Outofbox,是指在开发过程中,通过在MAVEN项目的pom文件中添加相关依赖包,然后使用对应注解来代替繁琐的XML配置文件以管理对象的生命周期。这个特点使得开发人员摆脱了复杂的配置工作以及依赖的管理工作,更加专注于业务逻辑。约定优于配置,Convention over configuration,是一种由SpringBoot本身来配置目标结构,由开发者在结构中添加信息的软件设计范式。这一特点虽降低了部分灵活性,增加了BUG定位的复杂性,但减少了开发人员需要做出决定的数量,同时减少了大量的XML配置,并且可以将代码编译、测试和打包等工作自动化。', '2019-12-18 17:50:11', '2019-12-21 14:12:08');
INSERT INTO `t_blog` VALUES ('7', '优雅的SpringBoot框架', 'java', 'Spring Boot是一个简化Spring开发的框架。用来监护spring应用开发,约定大于配置,去繁就简,just run 就能创建一个独立的,产品级的应用。\r\n我们在使用Spring Boot时只需要配置相应的Spring Boot就可以用所有的Spring组件,简单的说,spring boot就是整合了很多优秀的框架,不用我们自己手动的去写一堆xml配置然后进行配置。从本质上来说,Spring Boot就是Spring,它做了那些没有它你也会去做的Spring Bean配置。', '2019-12-18 14:12:02', '2019-12-18 14:12:05');
新建一个springboot项目
pom依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- JPA支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- druid 阿里巴巴开源平台上一个数据库连接池实现 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.18</version>
</dependency>
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.4</version>
</dependency>
<!-- mybatis-plus依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>MysqlBlog.java
package com.portal.entity.mysql;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.Data;
@Data
@Entity
@Table(name = "t_blog")
public class MysqlBlog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String title;
private String author;
@Column(columnDefinition = "mediumtext")
private String content;
private Date createTime;
private Date updateTime;
}
MysqlBlogRepositroy.java 持久层是基于Jpa的
package com.portal.repository.mysql;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import com.portal.entity.mysql.MysqlBlog;
public interface MysqlBlogRepositroy extends JpaRepository<MysqlBlog, Integer>{
@Query("select e from MysqlBlog e order by e.createTime desc")
List<MysqlBlog> queryAll();
@Query("select e from MysqlBlog e where e.title like concat('%',:keyword,'%') or e.content like concat('%',:keyword,'%')")
List<MysqlBlog> queryBlog(@Param("keyword") String keyword);
}
EsBlogRepositroy.java
package com.portal.repository.es;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import com.portal.entity.es.EsBlog;
public interface EsBlogRepositroy extends ElasticsearchRepository<EsBlog, Integer>{
}
DataController.java
package com.portal.controller;
import java.util.HashMap;
import java.util.List;
import java.util.Optional;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.util.StopWatch;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import com.portal.entity.es.EsBlog;
import com.portal.entity.mysql.MysqlBlog;
import com.portal.repository.es.EsBlogRepositroy;
import com.portal.repository.mysql.MysqlBlogRepositroy;
@RestController
public class DataController {
@Autowired
private MysqlBlogRepositroy mysqlBlogRepositroy;
@Autowired
private EsBlogRepositroy esBlogRepositroy;
/**
* 查询全部列表数据
* @return
*/
@GetMapping("/blogs")
public Object blog() {
List<MysqlBlog> mysqlBlogs = mysqlBlogRepositroy.queryAll();
return mysqlBlogs;
}
/**
* 根据不同类型,使用不同方式
* @param type
* @param keyword
* @return
*/
@GetMapping("/search")
public Object search(@RequestParam("type") String type,@RequestParam("keyword") String keyword)
{
HashMap<String, Object> map = new HashMap<>(16);
//计算执行时间
StopWatch watch = new StopWatch();
watch.start();
if (type.equalsIgnoreCase("mysql")) {
List<MysqlBlog> mysqlBlogs = mysqlBlogRepositroy.queryBlog(keyword);
map.put("list", mysqlBlogs);
}else if (type.equalsIgnoreCase("es")) {
//kibana中的写法,参考与打印处理的相比较
// POST /blog/_search
// {
// "query": {
// "bool": {
// "should": [
// {
// "match_phrase": {
// "title": "Spring"
// }
// },
// {
// "match_phrase": {
// "content": "Spring"
// }
// }
// ]
// }
// }
// }
//
BoolQueryBuilder builder = QueryBuilders.boolQuery();
builder.should(QueryBuilders.matchPhraseQuery("title", keyword));
builder.should(QueryBuilders.matchPhraseQuery("content", keyword));
System.out.println(builder.toString());
Page<EsBlog> search = (Page<EsBlog>)esBlogRepositroy.search(builder);
List<EsBlog> list = search.getContent();
map.put("list", list);
}else {
return "i don`t understand";
}
watch.stop();
long totaltime = watch.getTotalTimeMillis();
map.put("duration", totaltime);
return map;
}
/**
* 根据id查询单条信息
* @param id
* @return
*/
@GetMapping("/blogById/{id}")
public Object blogById(@PathVariable("id") Integer id) {
Optional<MysqlBlog> op= mysqlBlogRepositroy.findById(id);
return op.get();
}
}
Postman打开测试一下。。。