昨天想了一天这个问题
首先我们先粗略的说一说:
加入有一个查询语句要查询性别为男生的数据,因为这样的数据很多,我们要扫描很多次索引,然后再去取这个性别为男的数据。
那么分为两部分,先扫描索引,然后去取这个符合要求的数据
如果我们不建立索引,那么去扫描整个表。
不建立索引需要的时间=T扫描整个表 建立索引需要的时间= T去索引中取+T取相应的数据条件
我们去考虑一种极限,如果性别全为男,那么我们建立索引去查找的时间就是T扫描整个索引表+T扫描整个表。那么耗时肯定过大了。所以得出我们的结论
我们在通过innodb和MyISAM来细说
MyISAm中:就是类似于上面的描述,需要先去扫描索引树,再去扫描表。
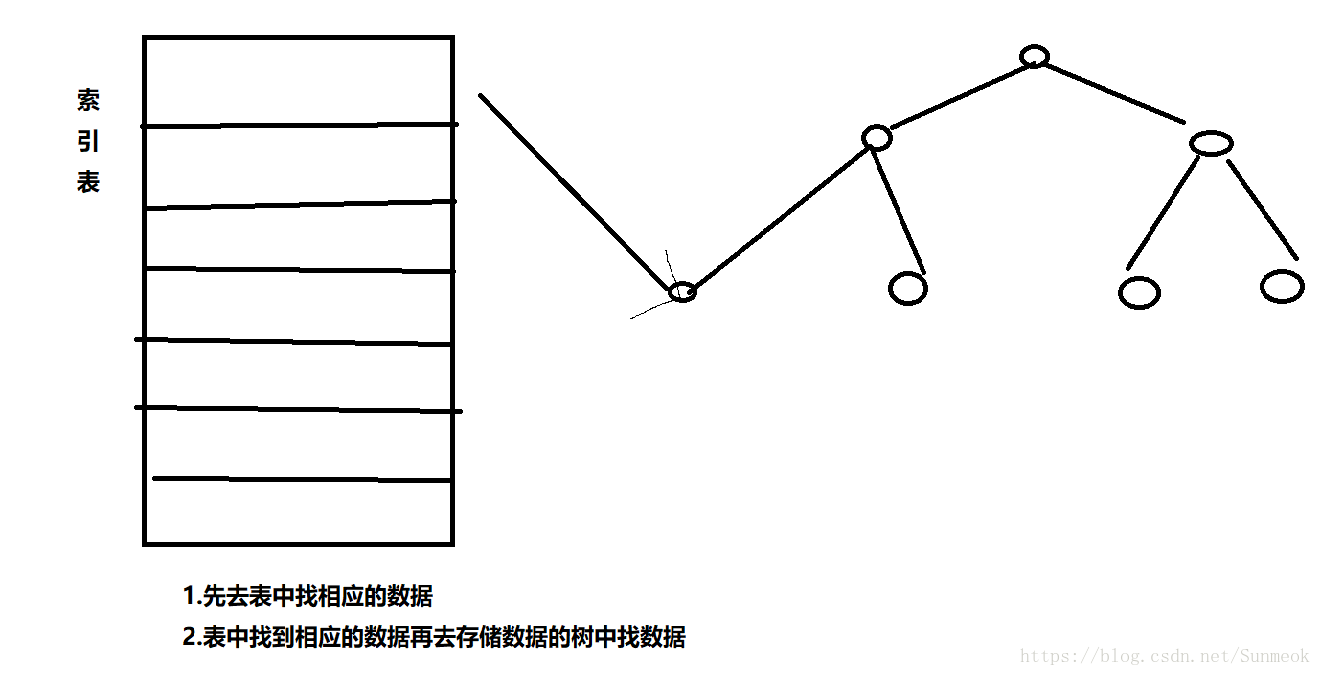
Innodb中:它的索引和数据在一起,它的非聚簇索引中保留了当前列和主键列的索引,每次查还要去主键索引查找整个信心,因为主键的索引是包含所有节点信息的,那么非聚簇索引向聚簇索引转换时就会出现问题时间消耗,如同上面的情况。
有人可能会问,如果放在聚簇索引上查找重复多个列,那不就没关系了,问题是聚集索引是唯一的,不能重复
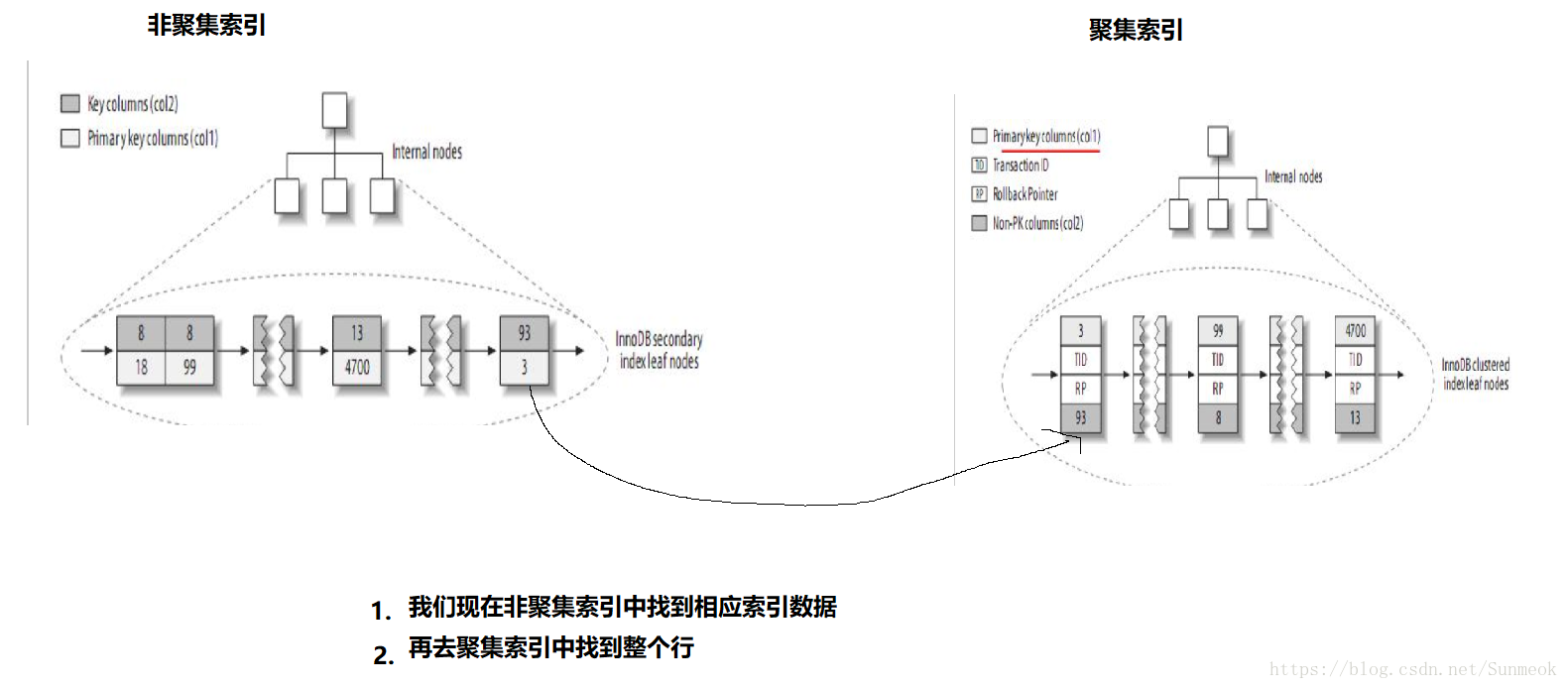
关于索引的存储结构:
https://www.cnblogs.com/zlcxbb/p/5757245.html
https://www.cnblogs.com/weizhixiang/p/5914120.html
这两篇文章都不错,不过我觉得第一篇写的更好。