在上文中,从技术角度分析了激光雷达传感器:熟悉了基本原理,知道了点云是如何生成的。然而,仅基于点云,自动驾驶汽车无法安全导航。为了做出决策,执行路径规划或发出制动动作,自动驾驶汽车需要识别周围的相关物体。这些对象是其他各种类型的车辆(如汽车、卡车、拖车)、骑自行车的人、行人、车道边界、路标和其它。
在计算机视觉中,深度学习方法常用于检测和分类场景中的相关对象。在下面的图像中,人和车被
YOLO检测框架(
YOLO: Real-Time Object Detection
)
检测到并正确分类。

YOLO对象检测
直到最近,二维图像处理仍然是主要的领域,其中基于深度学习的检测和分类。然而,近年来,基于三维点云的深度学习已经引起了学术界和汽车行业的关注。特别是在过去的四五年中,已发布的解决点云处理相关问题的方法数量显著增加。
与图像相比,基于点云的深度学习一直面临着以下几个挑战:
1.点云是一种稀疏和非结构化的性质,作为点在场景中的位置,因此它们的密度和数量随着场景中物体的呈现而变化。另一方面,与相机拍摄的图像有着类似数量的像素,可以输入到神经网络。
2.由于自动驾驶汽车需要快速反应,因此必须实时进行目标检测;这意味着检测网络必须在两次扫描之间的时间间隔内提供结果。
一、最先进的3D物体检测技术
在这一节中,我们将看一看基于点云的物体检测和分类的处理管道。管道结构由三大部分组成,分别是(1)数据表示、(2)特征提取和(3)基于模型的检测。下图是通过管道的数据流,一端是原始点云,另一端是分类后的物体:
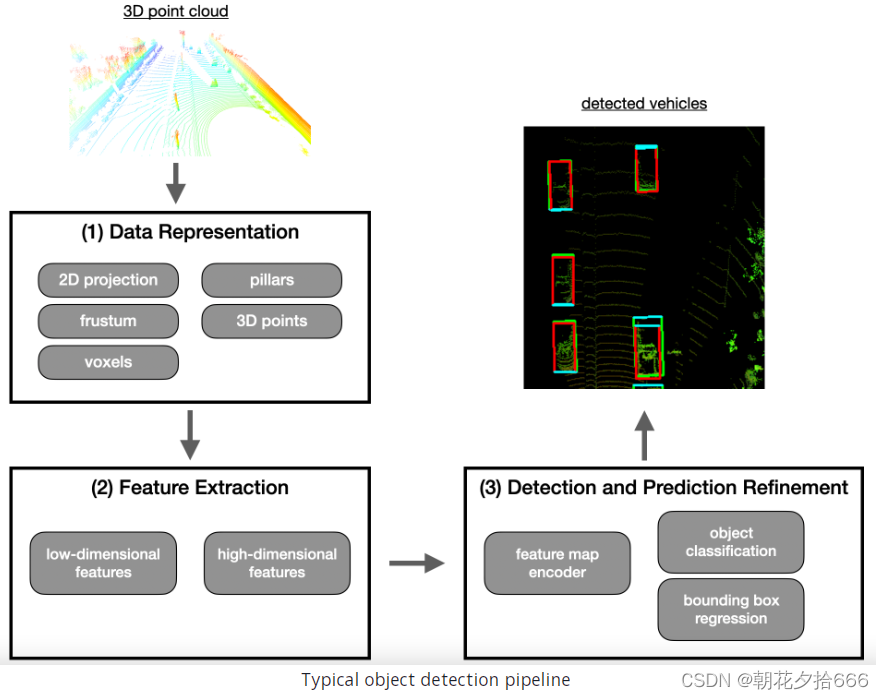
在第一部分中,激光雷达传感器提供的点云被组织成一个结构,适合在后续的管道阶段有效地处理数据。在现有的研究中,存在两种主要的数据表示方法:要么将点云转化为“体素”、“柱子”或“截锥”等结构,要么保留点云并直接处理。这两种方法都有各自的优点和缺点,我们将在本节中讨论这两种方法。
第二部分是特征提取,从变换后的点云中提取不同类型的低维和高维特征,现在可以将其表示为网格中的二维鸟瞰图。一旦一组特征被检测出来,结果就会被转发到实际的检测网络中。
第三部分是实际的检测网络,是进行物体检测的地方。该步骤包括物体类预测、检测物体周围的边界框和物体方向确定等操作。
除了介绍三步法检测管道,本节还对目前可用的基于点云的物体检测深度学习方法进行了全面的概述。请注意,本节更多的是理论性的,不包含任何编码示例。但是,在下一节中将从这一内容中获益良多,并讨论这里介绍的方法之一的实际实现。
步骤1:数据表示
正如我们在上一文中所看到的,激光雷达点云是一种非结构化的数据点分类,这些数据点在测量范围内分布不均匀。随着卷积神经网络(convolutional neural networks, CNN)在物体检测中的普及,要求点云的表示具有适合CNN的结构,这样才能有效的进行卷积运算。现在让我们看看可用的方法:
基于点(Point-based)
的数据表示
基于点的方法将原始的、未经过滤的输入点云转换为稀疏表示,本质上对应于一个聚类操作,根据某种标准(例如空间距离)将点分配到同一个聚类。下一步,该方法通过考虑相邻聚类提取每个点的特征向量。这种方法通常首先为每个单点寻找低维的局部特征,然后将其聚合为更大更复杂的高维特征。这类方法中最突出的代表之一是Qi等人的
PointNet(
https://arxiv.org/abs/1612.00593
)
,它反过来启发了许多其他重要的贡献,如
PointNet++(
https://arxiv.org/abs/1706.02413
)
或
LaserNet(
https://arxiv.org/abs/1903.08701
)
。基于点的方法的一个主要优点是,它们保持点云的结构完整,因此不会因为聚类而丢失信息。然而,基于点的方法的缺点之一是它们对内存资源的需求相对较高,因为必须通过处理管道传输大量的点。
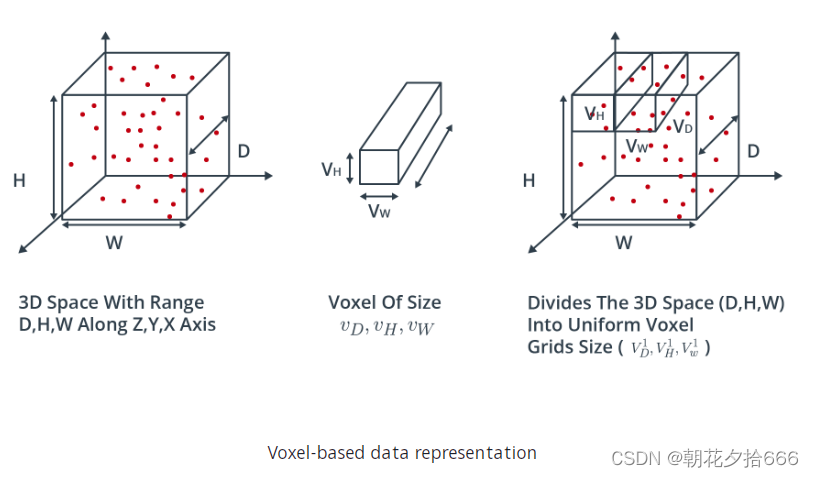
基于体素(Voxel-based
)的数据表示
体素被定义为空间三维网格中的体元素。基于体素的方法将输入点云中的每个点分配给特定的体元素。根据体素网格的粗糙程度,多个点可能位于相同的体素元素中。然后,在下一步中,从每个体素内的点组中提取局部特征。基于体素的方法最显著的优势之一是,它们节省了内存资源,因为它们减少了必须同时保存在内存中的元素数量。因此,特征提取网络将在计算上更有效率,因为特征提取是针对一组体素,而不是针对每个点。这类算法的一个著名代表是
VoxelNet(
https://arxiv.org/abs/1903.08701
)
。下图显示了一个点云,它的各个点是基于它们的空间邻近性聚类并分配给体素的。操作完成后,表示该对象的数据量显著减少。
基于支柱(Pillar-based )的数据表示
一种非常类似于基于体素表示的方法是基于支柱的方法。在这里,点云不是聚集成立方体积的元素,而是聚集成从地面上升起的垂直柱。
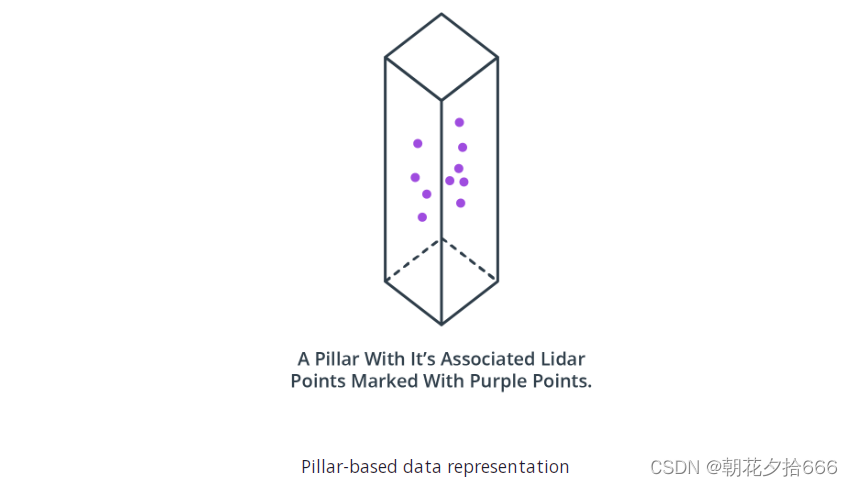
与基于体素的方法一样,将点云分割成离散的体素元素可以节省内存资源——对于柱子更是如此,因为通常柱子比体素要少得多。这类中一个著名的检测算法是
PointPillars(
https://arxiv.org/abs/1812.05784
)
。
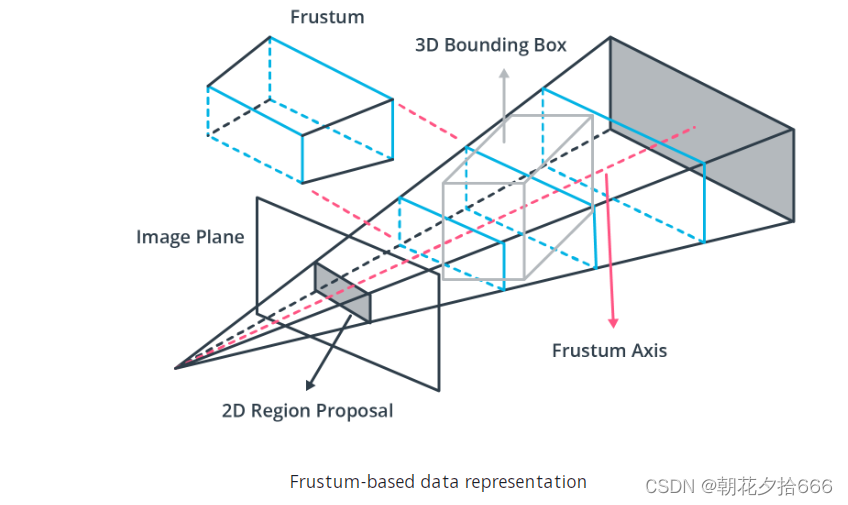
基于截锥
(Frustum-based)的数据表示
当与其他传感器(如相机)结合时,激光雷达点云可以基于预先检测到的2d物体(如车辆或行人)进行聚类。如果已知图像平面上物体投影周围的二维区域,则可以利用摄像机的内部和外部校准将截锥投影到3D空间。属于这个类的一个方法是
Frustum PointNets(
https://arxiv.org/pdf/1711.08488v1.pdf
)
。下图说明了其原理:
与以前的方法相比,这种方法的一个明显缺点是它需要第二个传感器,比如相机。然而,由于这些技术已经用于自动驾驶的物体检测,并保证安装在车辆上,所以这并不是一个显著的缺点。
基于投影(Projection-based)的数据表示
基于体素和基于支柱的算法都是基于空间邻近度来聚类点云的,而基于投影的方法则是沿着指定的维度降低3D点云的维数。在文献中,可以确定三种主要的方法,即前视图(FV),范围视图(RV)和鸟瞰视图(BEV)。在FV逼近时,点云沿前向轴被压缩,而在BEV图像中,点被投影到地平面上。下图说明了这两种方法:
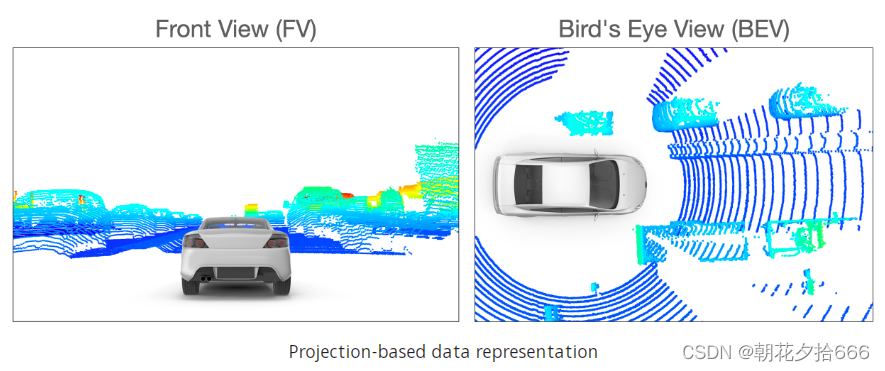
RV方法非常类似于FV方法,除了点云不是投射到平面上,而是投射到全景视图上。这个概念是在
Waymo数据集
(上文有详细介绍)中实现的,其中激光雷达数据存储为范围图像(range image)。
在文献中,BEV是应用最广泛的投影方案。原因有三:(1)感兴趣的物体与装有传感器的车辆位于同一平面上,只有很小的差异。此外,BEV投影保留了物体之间的物理大小和邻近关系,比FV和RV投影更清楚地分离物体。在下一节中,我们将实现BEV投影,作为本文中使用的物体检测方法的基础。
步骤2:特征提取
点云被转换成合适的表示(如BEV投影)后,下一步是识别合适的特征。特征提取是目前最活跃的研究领域之一,近年来取得了显著的进展,特别是在提高物体检测模型的效率方面。最常用的特征类型是(1)局部特征,(2)全局特征和(3)上下文特征:
1.局部特征,通常被称为低级特征,通常在非常早期的处理阶段获得,并包含精确的信息,例如关于数据表示结构的单个元素的本地化。
2.全局特性,也称为高级特性,通常编码数据表示结构中元素的几何结构与其邻接元素的关系。
3.上下文特征在处理管道的最后阶段提取。这些特征的目标是精确定位,并具有丰富的语义信息,如对象类别、边界框形状和大小、对象方向等。
下面,我们将看看在当前的文献中找到的一些特征提取器类:
逐点(Point-wise)特征提取器
术语“逐点”指的是将整个点云用作输入。这种方法显然适用于第一步的基于点的数据表示。点特征提取器对每个点进行单独分析和标记,例如
PointNet(
https://arxiv.org/abs/1612.00593
)
和
pointnet++(
https://arxiv.org/abs/1706.02413
)
,它们是目前最著名的特征提取器之一。为了说明这一原理,让我们简要地看一下PointNet体系结构,如下图所示:
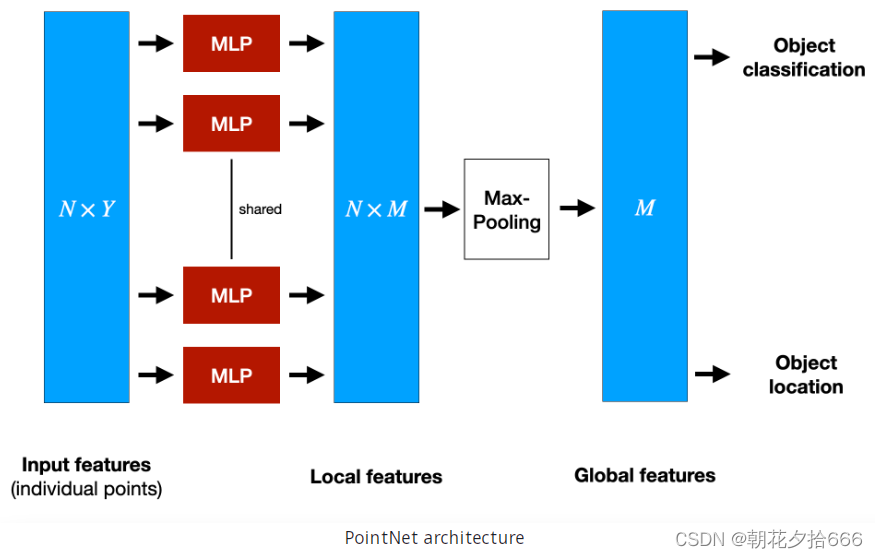
PointNet使用整个点云作为输入。它从欧几里得空间中点子集内每个点的空间特征中提取全局结构。为了实现这一点,PointNet实现了一个由三个主要块组成的非分层神经网络,这三个块是一个最大池层,一个用于组合局部和全局信息的结构,以及两个将输入点与提取的点特征对齐的网络。图中N表示送入PointNet的点的个数,Y表示特征的维数。为了逐点提取特征,我们使用一组多层感知器(MLP)将每个NN点从三个维度(x, y, z)映射到64个维度。然后重复这个过程,将64维的N点映射到M=1024维。完成后,max-pooling被用来在R^1024中创建一个全局特征向量。最后,使用三层全连通网络映射全局特征向量,生成目标分类和目标位置。
PointNet的一个缺点是它不能捕获相邻点之间的局部结构信息,因为每个点的特征都是单独学习的,点之间的关系被忽略了。这已经在PointNet++中得到了改进,但出于简单的原因,我们将不在这里进一步详细说明。尽管点特征提取技术显示出了非常有前景的结果,但由于对内存和计算复杂度的要求,它们还不适合在自动驾驶中使用。
分段(Segment-wise)特征提取器
由于基于点的特征具有较高的计算复杂度,因此需要采用替代方法才能在实时环境中使用激光雷达点云中的目标检测。术语“分段”指的是点云被划分为空间簇(例如体素、柱子或截锥)的方式。一旦完成了这些,分类模型被应用到一个段的每个点,以提取合适的体积特征。这类特征提取器中被引用最多的代表之一是
VoxelNet(
https://arxiv.org/abs/1711.06396
)
。简而言之,VoxelNet的思想是通过一种称为“体素特征提取器(VFE)”的架构对每个体素进行编码,然后使用3D卷积层组合局部体素特征,然后将点云转换为高维体素表示。最后,区域建议网络处理体积表示并输出实际检测结果。
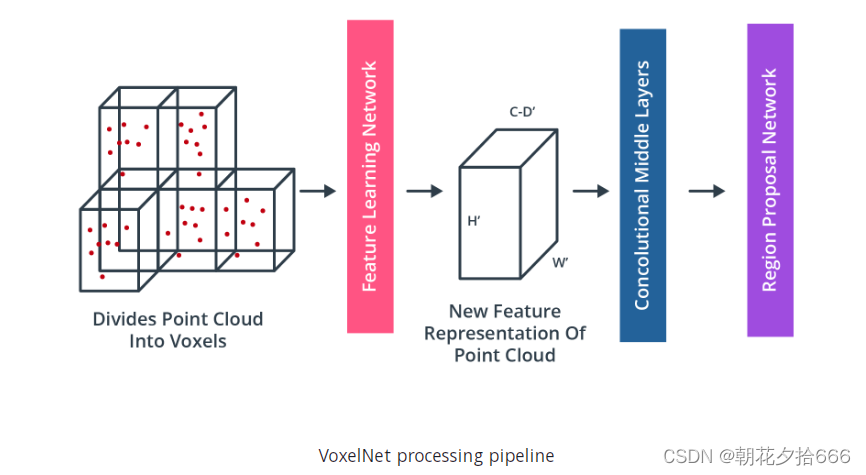
为了说明这一概念,下图展示了
体素(Voxel)特征提取器(
https://arxiv.org/abs/1711.06396
)
在特征学习网络中的架构,如图所示:
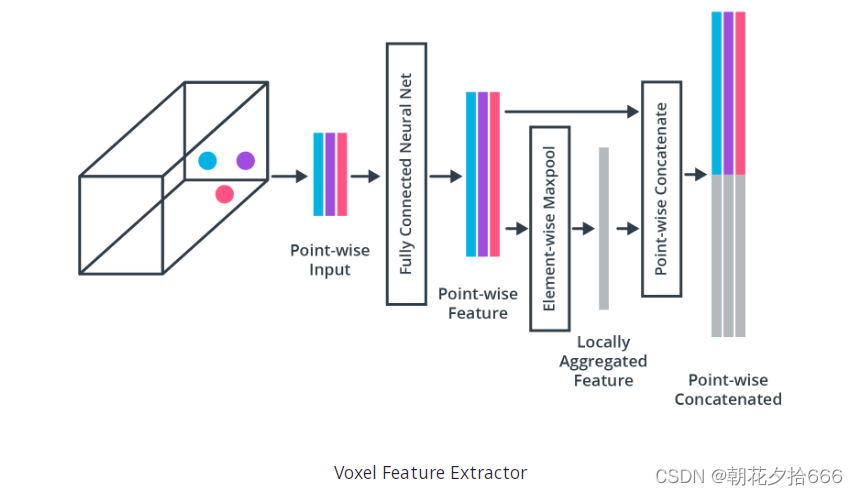
由于本文旨在提供文献的广泛概述,我们将不深入VoxelNet或VFE的细节。如果想看到实际的算法,请参阅这个
非官方的实现(this unofficial implementation):
GitHub – qianguih/voxelnet: This is an unofficial inplementation of VoxelNet in TensorFlow.
。
卷积神经网络(CNN)
多年来,CNN已经成功地用于相机图像中的物体检测和分类。最早的具有里程碑意义的论文之一表明,基于CNN的图像分类优于当时最先进的方法,如支持向量机(SVM),由
Krizhevsky(
ImageNet classification with deep convolutional neural networks | Communications of the ACM
)
等人于2012年发表。近年来,许多基于图像的物体检测方法都成功地转化为点云处理。因此,在本节中,我们将简要地回顾图像中基于CNN的检测原理,然后只做一些调整就转到点云部分。
在基于CNN的对象检测方法中,处理管道严重依赖于“骨干网”的使用,骨干网作为提取特征的基本元素。这种方法允许特性的自适应和自动识别,而不需要像许多经典方法那样投入人工(因此常常是启发式)工程工作。在大多数情况下,用于基于图像的物体检测的骨干网络也可以直接用于点云。为了在检测精度和效率之间取得平衡,主干的类型可以在连接较深且密集的网络或连接较少的轻量级变体之间选择。
尽管当时
AlexNet(
https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
)
等在CNN上取得的结果令人震惊,但这些网络的问题是,随着网络深度的增加,检测的准确性迅速饱和并下降,这是由于一个被称为
“vanishing gradient”(
https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Fthe-vanishing-gradient-problem-69bf08b15484
)
的问题。这个问题通常发生在所有层数多的体系结构中,即在所有“深度”网络中。为了克服这一问题,He等人在
该文(
https://arxiv.org/abs/1512.03385
)
中提出了ResNet架构,该架构使用“跳过连接”(即快捷方式)直接将一层的值传递到下一层,而不使用非线性转换。通过使用这些捷径,梯度可以直接传播,从而显著降低训练难度。这意味着可以在不影响模型训练能力的情况下增加网络深度。
步骤3:检测和预测细化
一旦从输入数据中提取特征,就需要一个检测网络来生成上下文特征(如对象类、边界框),并最终输出模型预测。根据体系结构的不同,检测过程可以执行单遍或双遍。根据探测器网络架构,可用的类型可以大致分为两类,即双级编码器,如
R-CNN(
https://arxiv.org/pdf/1311.2524.pdf
), Faster R-CNN(
https://papers.nips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf
)
或
PointRCNN(
https://arxiv.org/abs/1812.04244
)
,或单级编码器,如
YOLO(
https://arxiv.org/abs/1506.02640
)
或
SSD(
https://arxiv.org/abs/1512.02325
)
。一般来说,单级编码器比双级编码器更快,这使得它们更适合于自动驾驶等实时应用。
基于CNN的对象检测面临的一个问题是,我们不知道在输入数据中有多少特定对象类型的实例。在点云中可能只有一辆车,也可能有10辆车。解决这个问题的一个简单的方法是将CNN应用到多个区域,并分别检查每个区域内的对象是否存在。然而,由于物体会有不同的位置和形状,人们将不得不选择非常多的区域,这很快在计算上变得不可行的。
为了解决这个问题,Ross Girshick等人提出了一种方法(R-CNN),使用选择性搜索提取~2000个区域,他称之为区域建议。这意味着需要分类的区域数量大幅减少。请注意,在原始出版物中,输入数据是相机图像,而不是点云。然后将候选区域输入CNN生成高维特征向量,并使用支持向量机(SVM)推断候选区域内的对象。如下图所示:
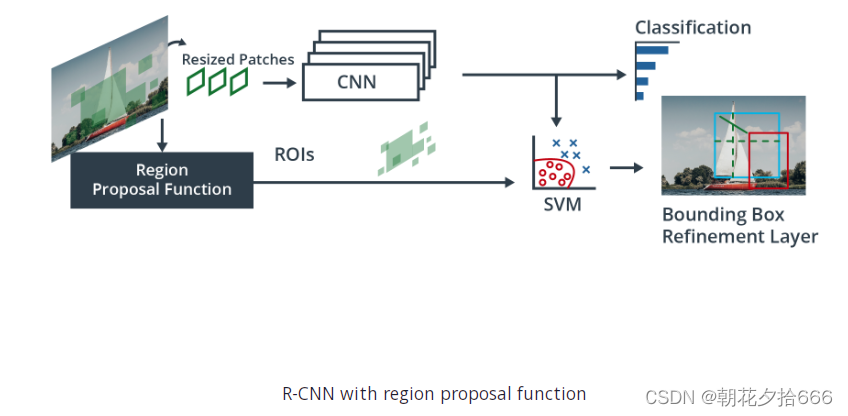
为了细化预测并提高模型输出的准确性,双级编码器将第一阶段的结果输入到一个额外的检测网络,该网络通过结合不同的特征类型产生细化结果来细化预测。
另一方面,单级目标检测器在一个步骤中完成区域建议、分类和边界框回归,这使得它们的速度明显更快,因此更适合实时应用。不过,在许多情况下,两级探测器往往能达到更好的精度。
最著名的单级检测器之一是YOLO (You Only Look Once)。该模型对输入数据运行深度学习CNN,产生网络预测。对象检测器对预测进行解码,生成边框,如下图所示:
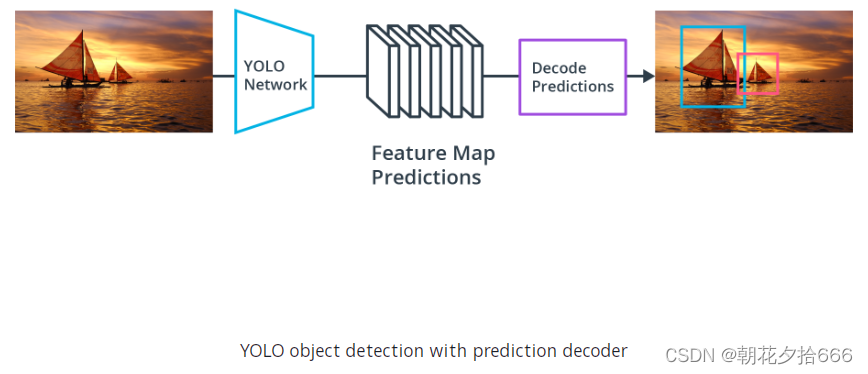
YOLO使用锚框来检测对象的类别,锚框是预定义的具有特定高度和宽度的边界框。这些方框被定义为捕捉特定对象类(例如车辆、行人)的比例和纵横比,通常根据训练数据集中的对象大小进行选择。在检测期间,预定义的锚框被平铺在整个图像。该网络预测概率和其他属性,如背景、联合(IoU)交集和每个平铺锚框的偏移量。这些预测被用来细化每个单独的锚框。
当使用锚框时,可以一次性评估所有对象的预测,而不需要像许多经典应用程序那样使用滑动窗口。使用锚盒的对象检测器可以一次性处理整个输入数据,使实时对象检测系统成为可能。
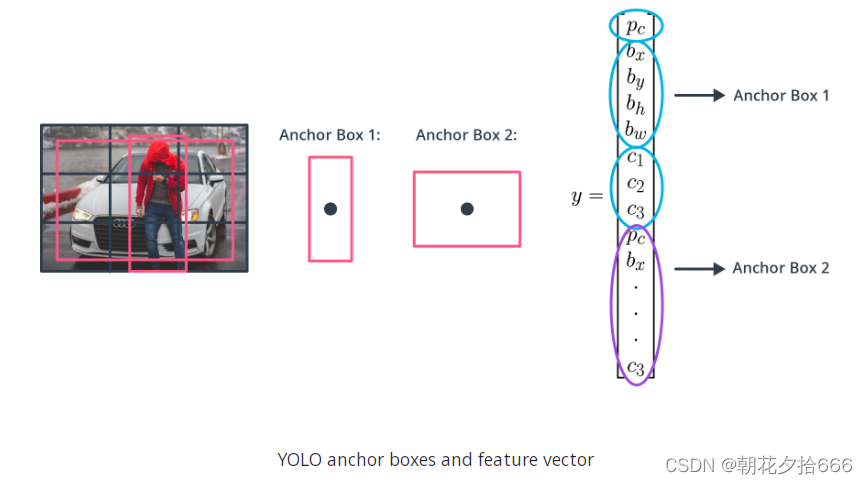
该网络为每个定义的锚框返回一组独特的预测。最后的特征图表示每个类的对象检测。锚盒的使用使网络能够检测多个对象、不同规模的对象和重叠的对象。
如前所述,大多数基于CNN的方法最初来自于计算机视觉领域,并已在基于图像的检测的思想中发展起来。因此,为了将这些方法应用于激光雷达点云,必须将3d点转换为2d域。这正是我们将在下一节点云中的物体检测中所要做的。
二、点云上的实时三维物体检测
Complex-YOLO算法
M. Simon等人在
Complex-YOLO:实时点云三维物体检测(
https://arxiv.org/abs/1803.06199
)
一文中,将著名的二维图像边界盒检测YOLO网络扩展到三维点云。从下图可以看出,Complex YOLO的主线包括三个步骤:
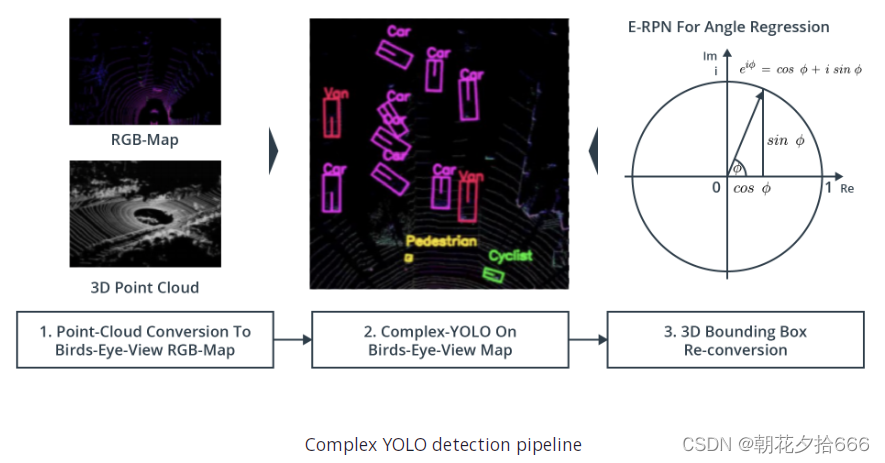
1. 将点云转换为鸟瞰视图 (BEV)
首先,将三维点云转换为鸟瞰视图(BEV),这是通过沿向上轴(Waymo车辆坐标系中的z轴)压缩点云来实现的。BEV被分割成一个由大小相同的单元组成的网格,这使得我们可以将其视为一幅图像,其中每个像素对应于路面上的一个区域。从下图可以看出,几个单独的点经常落入同一个网格元素中,特别是在与路面正交的表面上。下图说明了这个概念:
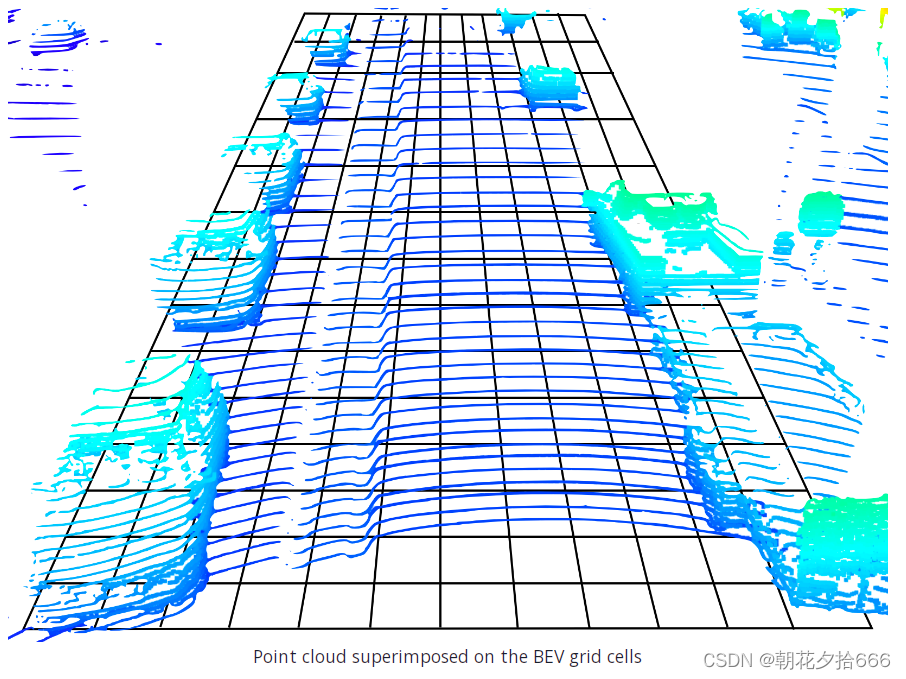
可以看到,点的密度在单元格之间变化很大,这取决于场景中物体的存在。而在路面上,由于垂直方向的角度分辨率(64束激光),点的数量相对较低,而在车辆的前面、后面或侧面的点的数量要高得多,因为相邻的垂直led从相同的距离反射过来。这意味着我们可以为每个BEV单元导出三条信息,即点的强度、高度和密度。因此,得到的BEV地图将有三个通道,从检测网络的角度来看,它是一幅彩色图像。
BEV地图的生成过程如下:
1.首先,我们需要决定我们想要涵盖的区域。对于本课程中的物体检测,我们将纵向范围设置为0…50米,横向距离-25…+25米。选择这组特定参数的部分原因是基于原始论文以及Complex YOLO现有实现中的设计选择。
2.然后,通过指定生成的BEV图像的分辨率或定义单个网格单元的大小,将区域划分为网格。在我们的实现中,我们将BEV图像的大小设置为608 x 608像素,这导致空间分辨率约为≈8cm。
3.现在我们已经将检测区域划分为一个网格,我们需要识别落在每个单元格中的点集Pij,其中i、j是各自的单元格坐标。下面,我们将使用Ni,j表示单元格中的点的数量。按照原论文的建议,我们将以下信息分配给每个单元格的三个通道:
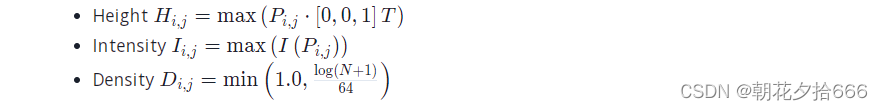
如你所见,Hi,j编码单元格内的最大高度;Ii,j为最大强度和Di,j为映射到单元格中的所有点的标准密度。产生的BEV图像(将在本节的第二部分创建)如下所示:

在左上角,你可以看到所有三个通道叠加的BEV地图。在右上方,你可以看到用绿色标记的高度。可以清楚地看到,车辆的车顶比路面有更高的强度。在左下角,你可以看到蓝色的强度。根据屏幕的对比度,你可能能够分辨出诸如尾灯或车牌之类的物体。如果没有,不要担心,我们将在本文中进一步深入地研究这个问题。最后在右下方,点云密度以红色显示,可以清楚地看到车辆的侧面、正面和后部出现最多。此外,随着距离的增加,路面上的点密度变小,这明显与透视效果和激光雷达的垂直角分辨率有关。
2. BEV地图上的
Complex-
YOLO
现在让我们来看看网络架构,如下图所示:
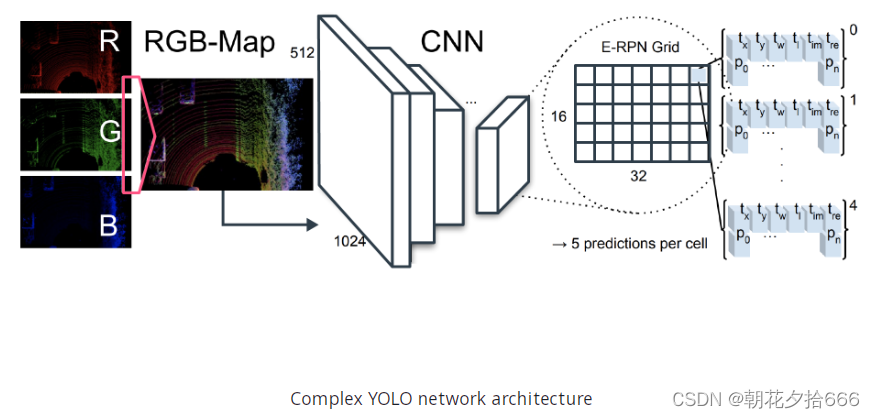
在最初的出版物中,使用了一个简化的YOLOv2 CNN架构。注意,在后续项目的实现中,我们将使用
YOLOv4(
https://arxiv.org/abs/2004.10934
)
替代。对原始YOLO网络的扩展是复杂的角度回归和Euler-Region Proposal network (E-RPN),用于获取被检测物体周围边框盒的方向。
YOLO网络已配置为将图像划分为16 x 32网格并预测75个功能。该模型共有18个卷积层和5个池化层。此外,还有3个中间层,用于特征重组。关于网络布局的更多细节可以从
原始出版物(
https://arxiv.org/pdf/1803.06199.pdf
)
中获得(表1)。
让我们讨论一下每个网格单元的特征是如何得到的:
YOLO网络预测每个单元有一组固定的盒子,在这个例子中是5个。对于每个box,得到6个单独的参数,分别是它在BEV映射中的二维位置,它的宽度和长度,以及方向角的两个分量:[x,y,w,l,αIm,αRe]。
除了box参数之外,还有一个参数用于指示边框盒是否包含实际物体并被准确放置。另外,有三个参数表示一个盒子是否属于“car”、“pedestrian”或“bicycle”类。
最后,区域提议网络(Region Proposal Network)使用5个附加参数来估计精确的物体方向和边界。
3. 3D边框盒重新转换
其中一个方面使Complex YOLO特别之处的是经典Grid RPN方法的拓展,经由一个方向角仅评估边界框的位置和形状,它在欧拉符号中编码作为一个复杂的角(因此得名“E-RPN”)以便方向可重建,即arctan2 (Im, Re)。下图是边界框回归估计的参数:
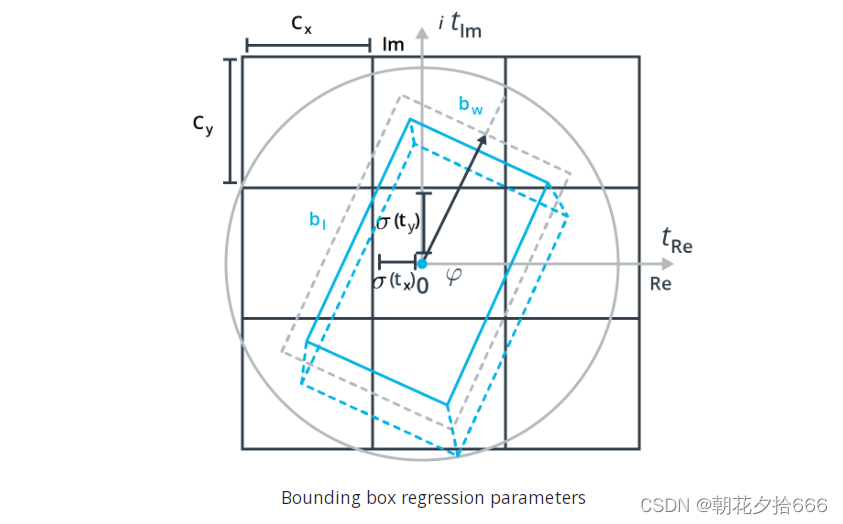
回归值然后直接传递到损失函数的计算,损失函数基于YOLO概念(即误差平方和),使用
multi-part loss
(多部分损失)(
https://arxiv.org/pdf/1912.12355v1.pdf
),但通过欧拉回归部分将其扩展,它是通过计算真实值和预测角之间的差值得到的,预测角总是假设在上面所示的圆内。
为什么使用Complex YOLO(复杂YOLO
)?
Complex
YOLO网络的主要优势之一是它与目前其他可用方法相比的速度。从下图可以看出,在达到类似检测性能的情况下,Complex YOLO的可实现帧率明显高于PointNet或VoxelNet。这使得它非常适合自动驾驶汽车等实时应用。请注意,图中使用的术语“平均精度(mean Average Precision, mAP)”将在下一节详细解释。

Source: https://arxiv.org/pdf/1803.06199.pdf
然而,Complex YOLO当前实现的一个缺点是缺乏边框高度和垂直位置。假设所有边界框都位于路面上,高度设置为基于检测类的预定义常数。在跟踪阶段,这可能会导致不同海拔的驾驶场景的不准确性。
该文(
https://arxiv.org/pdf/1808.02350v1.pdf
)
描述了Complex YOLO的一个改进版本,它将概念扩展到全3D。
三、将点云转换为鸟瞰视图
为Complex YOLO创建BEV地图
在本节中,我们将从激光雷达点云创建实际的鸟瞰图。正如本章前面所述,这个过程遵循一系列步骤,它们是
1.过滤一个定义区域之外的所有点
2.通过将定义区域划分为单元格并将每个点的度量坐标转换为网格坐标来创建实际的BEV MAP
3.计算每个单元格的高度、强度和密度,并将结果值转换为8位整数。
从第一步开始,从激光雷达点云中移除不满足以下条件的所有点:

如前所述,参数的选择基于原始发布和算法的现有实现。
在代码中,定义这些限制如下所示:
lim_x = [0,50]
lim_y = [-25,25]
lim_z = [-1, 3]接下来,可以用np.where检索坐标在这些限制范围内的点:
mask = np.where((lidar_pcl[:, 0] >= lim_x[0]) & (lidar_pcl[:, 0] <= lim_x[1]) &
(lidar_pcl[:, 1] >= lim_y[0]) & (lidar_pcl[:, 1] <= lim_y[1]) &
(lidar_pcl[:, 2] >= lim_z[0]) & (lidar_pcl[:, 2] <= lim_z[1]))
lidar_pcl = lidar_pcl[mask]
例C2-3-1:剪裁点云
通过从basic_loop.py调用函数crop_pcl来试验object-detection/examples/l2_examples.py中的代码。注意有两行需要取消注释,因为lidar_pcl输出从第一行转换到第二行。如果想查看点云,将range_image_to_point_cloud结尾的False设置为True(但请确保在继续之前将其设置为False,否则后面的行将强制首先重新查看这些可视化)。
注意,在这个例子中开始使用
Open3D库(
Open3D – A Modern Library for 3D Data Processing
)
,并在本文练习和项目中使用它。这是一个非常棒的用于处理3D数据(如激光雷达)的开源库,可以在Python或C++中使用。
由于预定义的限制,得到的点云如下所示:
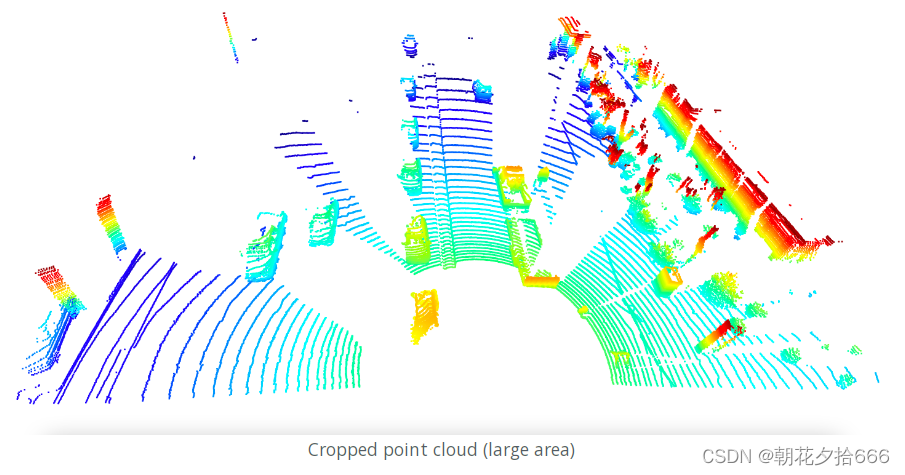
将限制改为更严格的设置会对剩余点数产生直接影响,如下图所示:
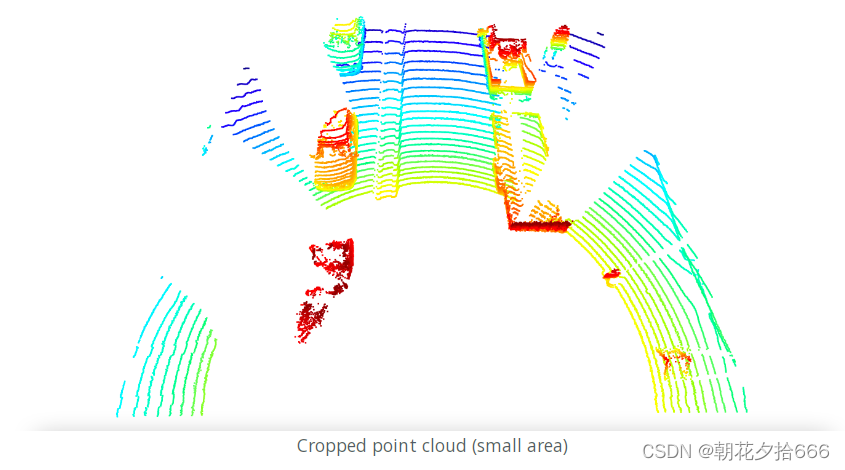
下一步,通过对单元格进行离散化,然后将点坐标从车辆空间转换为BEV空间来创建BEV地图。下面的代码给出了单个BEV单元的尺寸,单位是米/像素:
bev_width = 608
bev_height = 608
bev_discret = (lim_x[1] - lim_x[0]) / bev_height接下来,要执行实际的坐标转换,这是在下面的练习中要做的工作。
四、练习C2-3-2:将点云转换成鸟瞰图
起始代码
本节练习的起始代码与上节一样在
同一个存储库(repository )(
https://github.com/udacity/nd013-c2-fusion-exercises
)
中。
工作文件:
basic_loop.py
lesson-2-object-detection/exercises/starter/l2_exercises.py
Sequence 3, frame 0
完成之后,请执行代码并打开可视化,得到的高度图应该如下所示:

可以预期的是,车辆顶部、树和左边的墙明显比路面亮。
参考代码:
def pcl_to_bev(lidar_pcl, configs, vis=True):
# compute bev-map discretization by dividing x-range by the bev-image height
bev_discret = (configs.lim_x[1] - configs.lim_x[0]) / configs.bev_height
# create a copy of the lidar pcl and transform all metrix x-coordinates into bev-image coordinates
lidar_pcl_cpy = np.copy(lidar_pcl)
lidar_pcl_cpy[:, 0] = np.int_(np.floor(lidar_pcl_cpy[:, 0] / bev_discret))
# transform all metrix y-coordinates as well but center the foward-facing x-axis on the middle of the image
lidar_pcl_cpy[:, 1] = np.int_(np.floor(lidar_pcl_cpy[:, 1] / bev_discret) + (configs.bev_width + 1) / 2)
# shift level of ground plane to avoid flipping from 0 to 255 for neighboring pixels
lidar_pcl_cpy[:, 2] = lidar_pcl_cpy[:, 2] - configs.lim_z[0]
# re-arrange elements in lidar_pcl_cpy by sorting first by x, then y, then by decreasing height
idx_height = np.lexsort((-lidar_pcl_cpy[:, 2], lidar_pcl_cpy[:, 1], lidar_pcl_cpy[:, 0]))
lidar_pcl_hei = lidar_pcl_cpy[idx_height]
# extract all points with identical x and y such that only the top-most z-coordinate is kept (use numpy.unique)
_, idx_height_unique = np.unique(lidar_pcl_hei[:, 0:2], axis=0, return_index=True)
lidar_pcl_hei = lidar_pcl_hei[idx_height_unique]
# assign the height value of each unique entry in lidar_top_pcl to the height map and
# make sure that each entry is normalized on the difference between the upper and lower height defined in the config file
height_map = np.zeros((configs.bev_height + 1, configs.bev_width + 1))
height_map[np.int_(lidar_pcl_hei[:, 0]), np.int_(lidar_pcl_hei[:, 1])] = lidar_pcl_hei[:, 2] / float(np.abs(configs.lim_z[1] - configs.lim_z[0]))
# sort points such that in case of identical BEV grid coordinates, the points in each grid cell are arranged based on their intensity
lidar_pcl_cpy[lidar_pcl_cpy[:,3]>1.0,3] = 1.0
idx_intensity = np.lexsort((-lidar_pcl_cpy[:, 3], lidar_pcl_cpy[:, 1], lidar_pcl_cpy[:, 0]))
lidar_pcl_cpy = lidar_pcl_cpy[idx_intensity]
# only keep one point per grid cell
_, indices = np.unique(lidar_pcl_cpy[:, 0:2], axis=0, return_index=True)
lidar_pcl_int = lidar_pcl_cpy[indices]
# create the intensity map
intensity_map = np.zeros((configs.bev_height + 1, configs.bev_width + 1))
intensity_map[np.int_(lidar_pcl_int[:, 0]), np.int_(lidar_pcl_int[:, 1])] = lidar_pcl_int[:, 3] / (np.amax(lidar_pcl_int[:, 3])-np.amin(lidar_pcl_int[:, 3]))
# visualize intensity map
if vis:
img_intensity = intensity_map * 256
img_intensity = img_intensity.astype(np.uint8)
while (1):
cv2.imshow('img_intensity', img_intensity)
if cv2.waitKey(10) & 0xFF == 27:
break
cv2.destroyAllWindows()
五、强度通道
强度通道
现在已经创建了鸟瞰图的第一层,让我们看看下面的强度通道。与高度一样,其思想是在每个单元中存储强度最大的值。请注意,使用我们之前基于最大高度选择的点的强度值将不起作用,因为在大多数情况下,单元格的最高点不会同时具有最高强度。相反,我们需要再次执行排序过程,这一次是基于强度而不是高度。
在处理激光雷达传感器时,在实践中遇到的一个问题是,反射强度在传感器模型之间有显著差异。将KITTI数据集中使用的Velodyne LiDAR与Waymo LiDAR进行比较时,您会注意到,在大多数情况下,使用Waymo传感器时,场景中出现的最大强度值要高得多。
示例C2-3-3:最小和最大强度
作为一个小实验,让我们提取每一帧的最小和最大强度,这样就可以对Waymo激光雷达传感器产生的值的范围有一个感觉。请注意,对于其他激光雷达传感器,强度值和范围将有所不同。
要运行这个实验,需要在文件l2_examples.py中执行min_max_intensity函数。这个小函数将简单地将给定帧的所有点的最小和最大强度打印到终端。
例如,当处理sequence 3(序列3)的前5帧时,输出将如下所示:
processing frame #0
min. intensity = 0.0002117156982421875, max. intensity = 91648.0
------------------------------
processing frame #1
min. intensity = 0.000316619873046875, max. intensity = 86528.0
------------------------------
processing frame #2
min. intensity = 0.0003261566162109375, max. intensity = 80384.0
------------------------------
processing frame #3
min. intensity = 0.000209808349609375, max. intensity = 75776.0
------------------------------
processing frame #4
min. intensity = 0.00019168853759765625, max. intensity = 70656.0
------------------------------
processing frame #5
min. intensity = 0.00023746490478515625, max. intensity = 66048.0
如你所见,强度最小值和最大值之间的差异总共是十的8次方。让我们更仔细地研究一下这个观察结果。我们可以复制和调整用于创建高度图的代码,以创建强度图。
现在请看看下面给出的强度图。

BEV图:强度通道(全比例)-几乎看不见!
我们可以看到,只有非常少量的像素是可见的,而绝大多数投影3d点的亮度值为零。根据我们通过打印强度最小值和最大值暴露的范围,强度通道明显由少数高强度点主导。让我们进一步研究这个观察结果,并计算强度值的直方图:
b = np.array([0, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1, 1e+1, 1e+3, 1e+3, 1e+4, 1e+5, 1e+6, 1e+7])
hist,bins = np.histogram(lidar_pcl[:,3], bins=b)
print(hist)
请注意,这些箱体(bins)不是等距的,而是代表对数刻度。这将帮助我们找到包含大部分强度值的十进位(decade)。代码的输出如下所示:
hist = [0, 0, 40, 5722, 15258, 9886, 49, 70, 0, 62, 70, 0, 0]
根据这些数字,我们可以清楚地看到,绝大多数强度值都在0.001到1.0之间。由于强度较高的点的数量少于数据的1%,我们可以安全地执行过滤操作,使强度高于1.0的每个点被剪切到1.0:
idx_limit = lidar_pcl[:,3]>1.0
lidar_pcl[idx_limit,3] = 1.0
现在,强度过大的主导影响已被消除。当我们再次计算强度映射时,结果如下所示:

BEV图:强度通道(裁剪在1.0)
虽然BEV地图的对比度有所提高,让你可以看到更多的细节,但可以清楚地看到可见点的数量相当高,这将使目标检测网络更容易根据反射激光雷达脉冲的强度来定位车辆。
高度、强度和密度的组合将组成BEV图,我们可以使用它来执行目标检测。
关于模型训练的说明
此时您可能会问自己——如何训练模型呢?我们已经介绍了从3D激光雷达点云数据转换成这些BEV地图的过程,接下来将考虑在给定数据上评估预训练模型的性能,但模型的训练可能不清楚。这是因为在这种情况下,我们现在能够使用2D对象检测模型(正如您将在项目中)!BEV地图与你通常在2D物体检测中使用的RGB图像非常相似——高度、强度和密度都是BEV“图像”的有效通道,就像红色、绿色和蓝色是RGB图像的通道一样。在这种情况下,每个物体都是从上方(带有相关的2D边界框)检测到的,而不是从侧面,就像你可能从同一辆车的摄像机图像中检测到的那样。
所有同样的原则都适用,所以我们不会在本文中直接涵盖这些模型的训练。
六、评估目标检测的性能
在许多论文中,诸如
Waymo Open Challenge(
https://waymo.com/open/challenges/3d-detection/#
)
或
KITTI 3D目标检测基准(KITTI 3D Object Detection Benchmark)(
The KITTI Vision Benchmark Suite
)
等排名和挑战,“平均精度”(Average Precision, AP)和“中值平均精度”(mean Average Precision, mAP)等指标经常被用作有意义地比较检测算法的事实标准。下图为Waymo公开赛的积分排行榜:
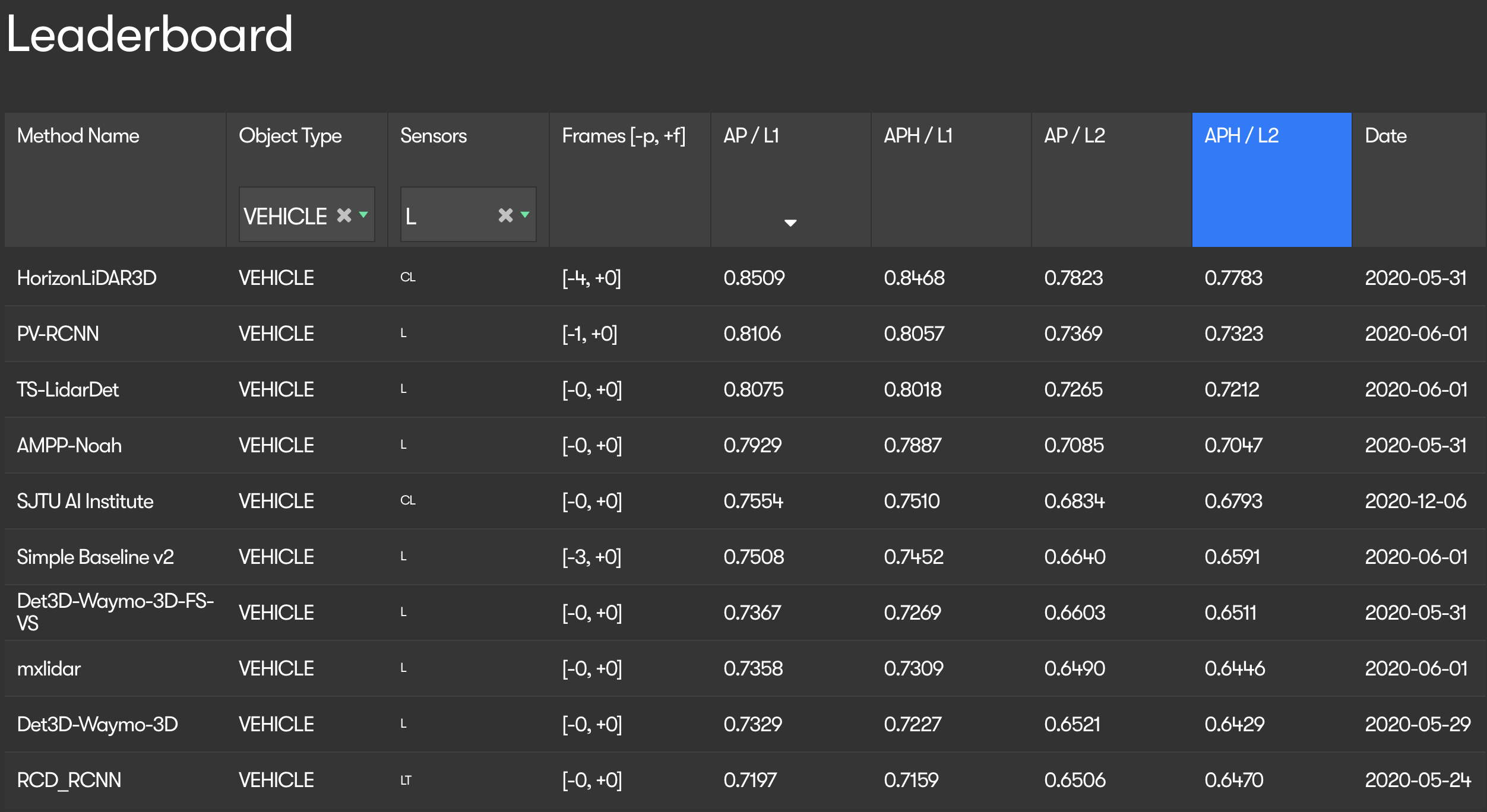
Waymo挑战排行榜
排行榜在AP/L1列之后排序,该列使用0.0到1.0之间的单个数字对各种算法进行排名。本节将详细解释AP和mAP度量及其与目标检测的相关性。
评估目标探测器
考虑以下点云:

两辆车在点云里
从图中可以看出,场景中有两辆车。目标检测算法需要完成两个主要任务,分别是
1.判断物体是否存在于场景中
2.确定目标的位置、方向和形状
第一个任务被称为“分类”,而第二个任务通常被称为“定位”。在真实的场景中,一个场景将包含几个对象类(例如车辆、行人、骑自行车的人、交通标志),这导致有必要为每个检测到的对象分配一个置信度评分,通常在0.0到1.0之间。根据这个分数,检测算法可以在不同的置信水平下进行评估,这意味着接受或拒绝一个对象的阈值是系统地变化的。
为了解决这些问题,提出了一种适用于目标检测的平均精度(AP)指标。要理解AP背后的概念,首先需要理解术语“精确度”和“召回率”以及四个特征“真阳性”(TP)、“真阴性”(TN)、“假阳性”(FP)和“假阴性”(FN)。
TP, TN, FP和FN
再次考虑上一个例子中的点云,现在通过一个目标检测算法添加了一组边界框:
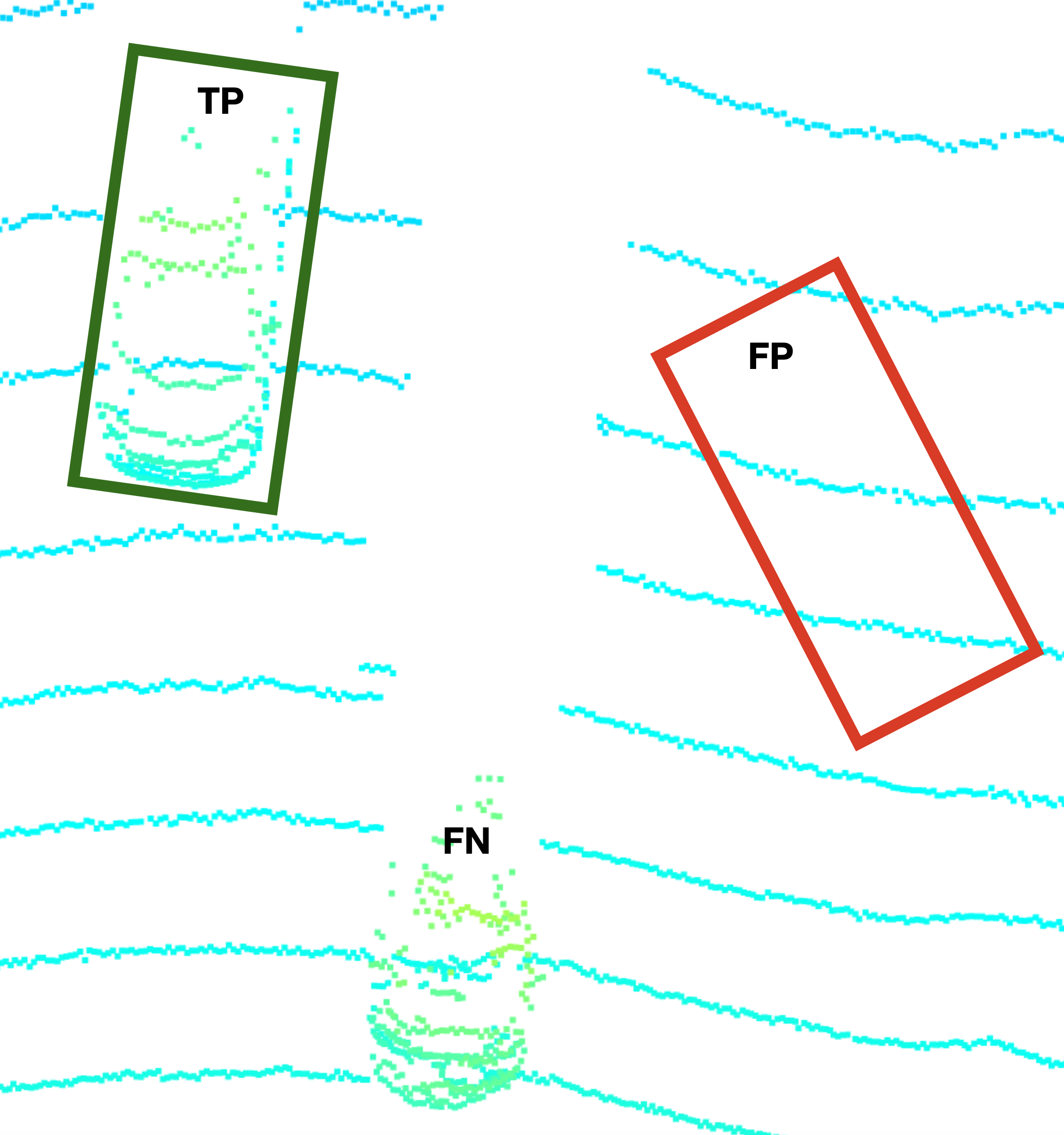
真阳性(TP),假阳性(FP),假阴性(FN)
标记为“TP”的边界框显示了正确的检测:它包含了一个实际的对象,形状和标题都是准确的。这被称为“真阳性”,其中“阳性”表示检测器看到的物体的存在。在右侧,有一个标记为“FP”的红色边框,它不包含任何对象,因此是一个错误的检测。这种错误的物体被称为“假阳性”,因为探测器错误地相信一个实际物体的存在。此外,在图像的底部,在点云中有一个清晰可见的物体,但探测器没有找到它。这种漏检被称为“假阴性”,其中的“阴性”意味着探测器相信某个物体不存在。在药物试验中,对患者进行某种特定疾病的检测,应遵循以下原则:
TP:病人确实患病了,检测结果是阳性的
FP:病人没有患病,但测试结果却呈阳性
FN:病人有这种病,但检查结果错误地呈阴性
最后,还有一种情况是,患者没有患病,但测试正确地返回阴性结果。这被称为“真正阴性”(TN)。在对象检测中,这意味着在一个场景中没有对象,检测器没有正确地返回一个检测结果。这四种状态可以排列成一个矩阵,在机器学习中称为“混淆矩阵” :
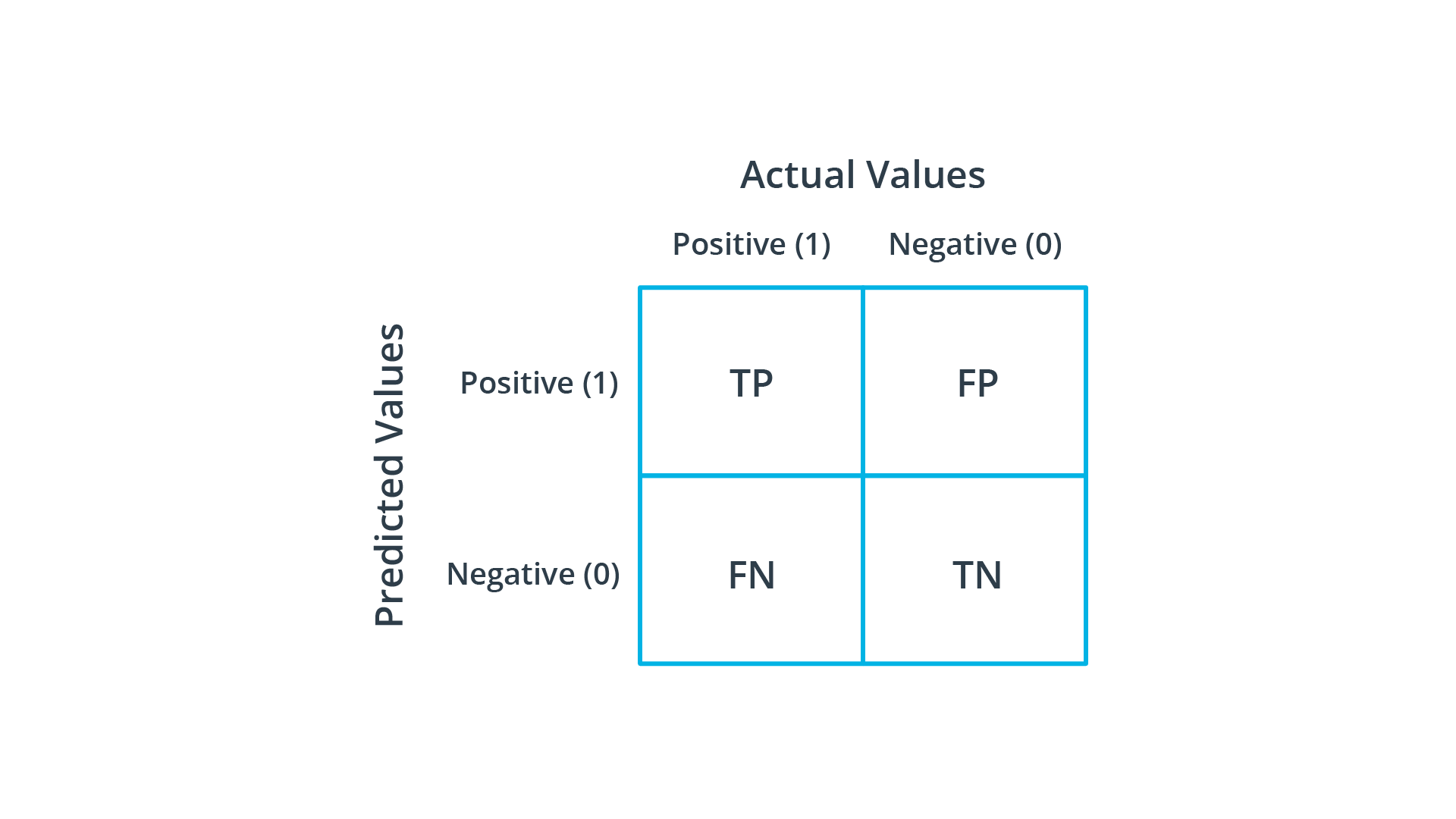
混淆矩阵(Confusion matrix)
注意,在这种情况下,预测值与实际值一致时,位于矩阵的主对角线上。
精确率
和召回率
假设我们想以一种有意义的方式评估上面示例中使用的检测算法。我们可能会问两个问题:
1.算法找到的物体与真实物体对应的概率是多少?
2.一个真实的物体被探测器发现的概率是多少?
让我们试着根据阳性和阴性来回答第一个问题:为了得到这个概率,我们需要用真阳性除以所有检测的数量,也就是真阳性和假阳性的总和。这个比例被称为“精确率”PP:
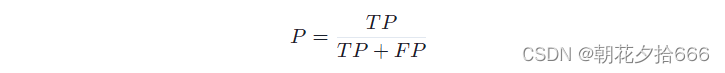
在实践中,精确率有时也被称为“阳性预测值”(PPV)。
对于我们假设的探测器,其精确率为P= 1/(1+1)=0.5。基于这一具有两次检测的单帧,检测到对应于真实物体的概率将为50%。
第二个问题可以用类似的方式回答:为了计算探测到实际物体的概率,我们需要用实际探测到的次数除以实际探测到的次数和未探测到的次数之和。这一措施被称为“召回率”RR:
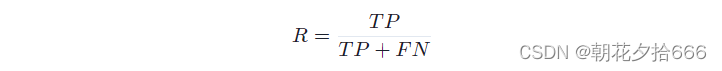
在实践中,召回率也经常被称为“真阳性率”(TPR)或“敏感性”。
对于我们假设的检测器,召回率是R= 1/(1+1)=0.5。显然,对于一个带有如此少量测量值的单帧计算这个度量没有多大意义。因此,在实践中,精确率和召回率是在整个数据集上计算的,应该包含来自每个类(TP、TN、FN)的一些代表,这样的结果在统计上是相关的。 为了有意义地评估检测器的性能,我们必须同时检查精确率和召回率。一个完美的检测器应该同时拥有1.0的召回率和1.0的精确率。然而,在实践中,这两种措施往往是紧相关的,这意味着提高精确率,例如通过调整一些检测器参数,将有可能减少召回率,反之亦然。假设我们有一个检测器,它返回以下结果:TP=80, FP=2, FN=6。根据这些数字,我们可以得到:
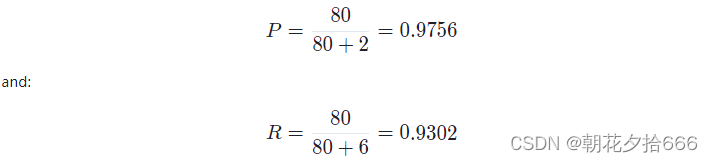
如果我们降低分类阈值,将置信度得分较低的对象作为检测,则FN的数量将减少,而FP的数量将增加,即TP=80, FP=6, FN=2。对于性能测量,这意味着P= 80
/(80+6)=0.9302, R= 80/(80+2)=0.9756。
如你所见,精确率降低了,而召回率增加了。在增加分类阈值的情况下,这种效果将会逆转。一般来说,一个检测算法在精确率和召回率上都优于另一个算法,这很可能是更好的。
另一种同样基于预测类型的度量方法叫做“准确度”A,它是正确预测次数与总预测次数的比率。准确度可表示为:
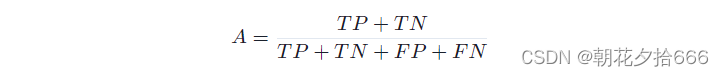
然而,在物体检测中,准确度并不被使用,因为真实阴性的数量并不对应一个有意义的检测器行为。“没有物体,探测器也没有探测到”的状态适用于没有探测到和没有物体的场景的所有区域。在实践中,我们需要一个对象的存在,无论是来自检测器还是来自可靠的来源(如人类观察者),以获得状态TP、FP和FN。
Intersection-over-Union (IoU)
在前面的例子中,我们想当然地认为某些实体会为我们提供检测是TP、FP还是FN的信息。然而,在实践中,事情并没有那么容易。为了将检测归入某些类别,需要采取以下几个步骤:
1.提供一个人为生成的检测列表,作为事实真相。这种检测通常被称为“标签”。
2.将我们想要评估的算法提供的检测列表与事实真相标签列表进行匹配。
3.根据检测和事实真相标签(ground-truth label)的重叠程度判断某一检测是TP、FP还是FN。
看看上一个示例中的点云,它现在包含检测器生成的边界框(红色)和事实真相标签(绿色)。
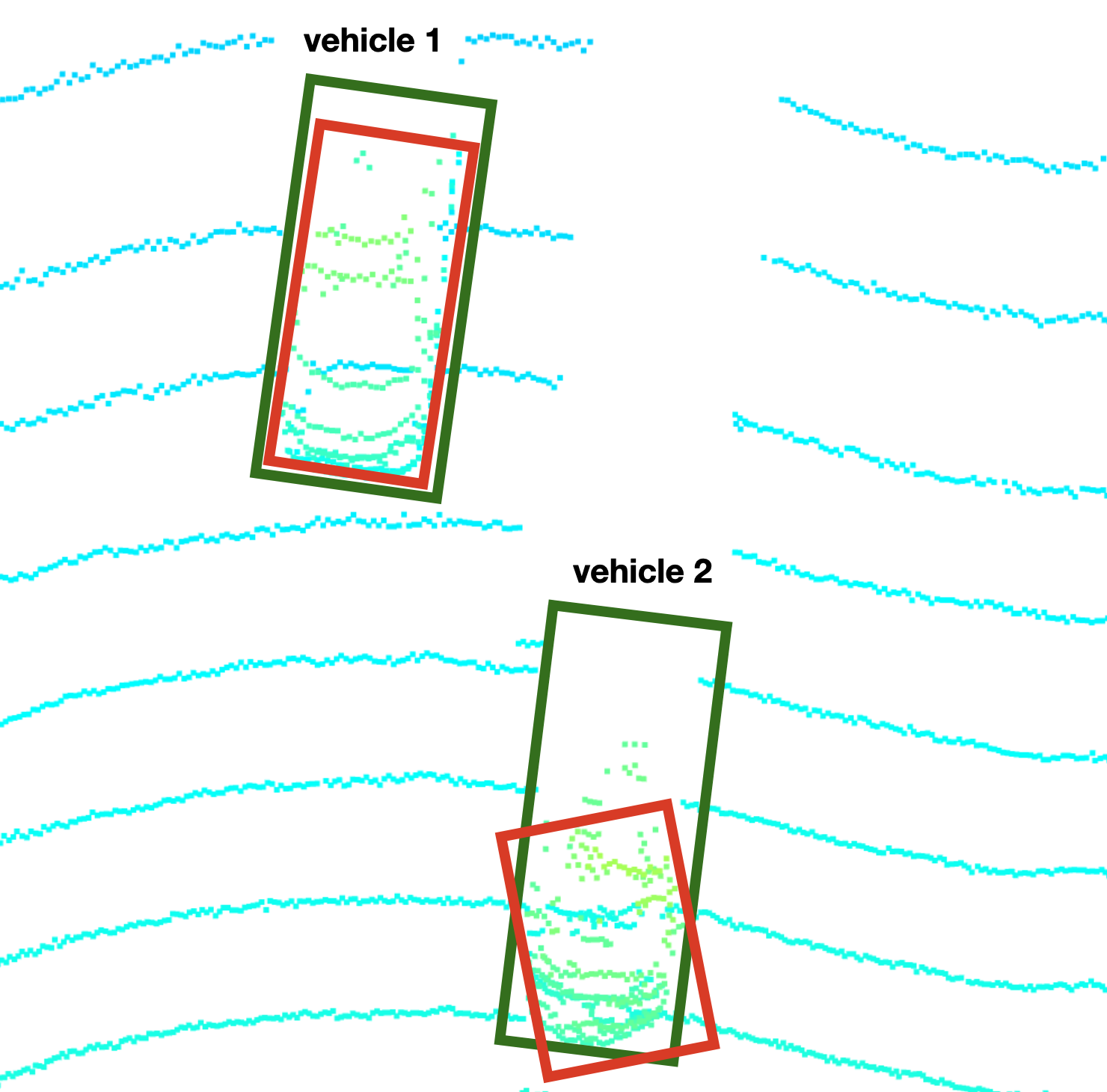
标签(绿色)vs检测(红色)
可以看到,车辆1的边界框在形状和大小上都非常相似,基于检测的边界框略小于人类标记的边界框。而对于车辆2来说,由于形状、比例和角度的不同,两个盒子之间的重叠明显要小得多。
为了以一种有意义的方式评估检测器,我们需要决定真实标签和检测结果是否被视为匹配。在实践中,我们使用一种称为“交集-并集”(IoU)的度量来决定是否分配两个边界框。其思想是测量检测器返回的每个边界框与所有真实边界框之间的重叠程度,从而计算出两个矩形的交集面积和并集面积。下图说明了这个概念:
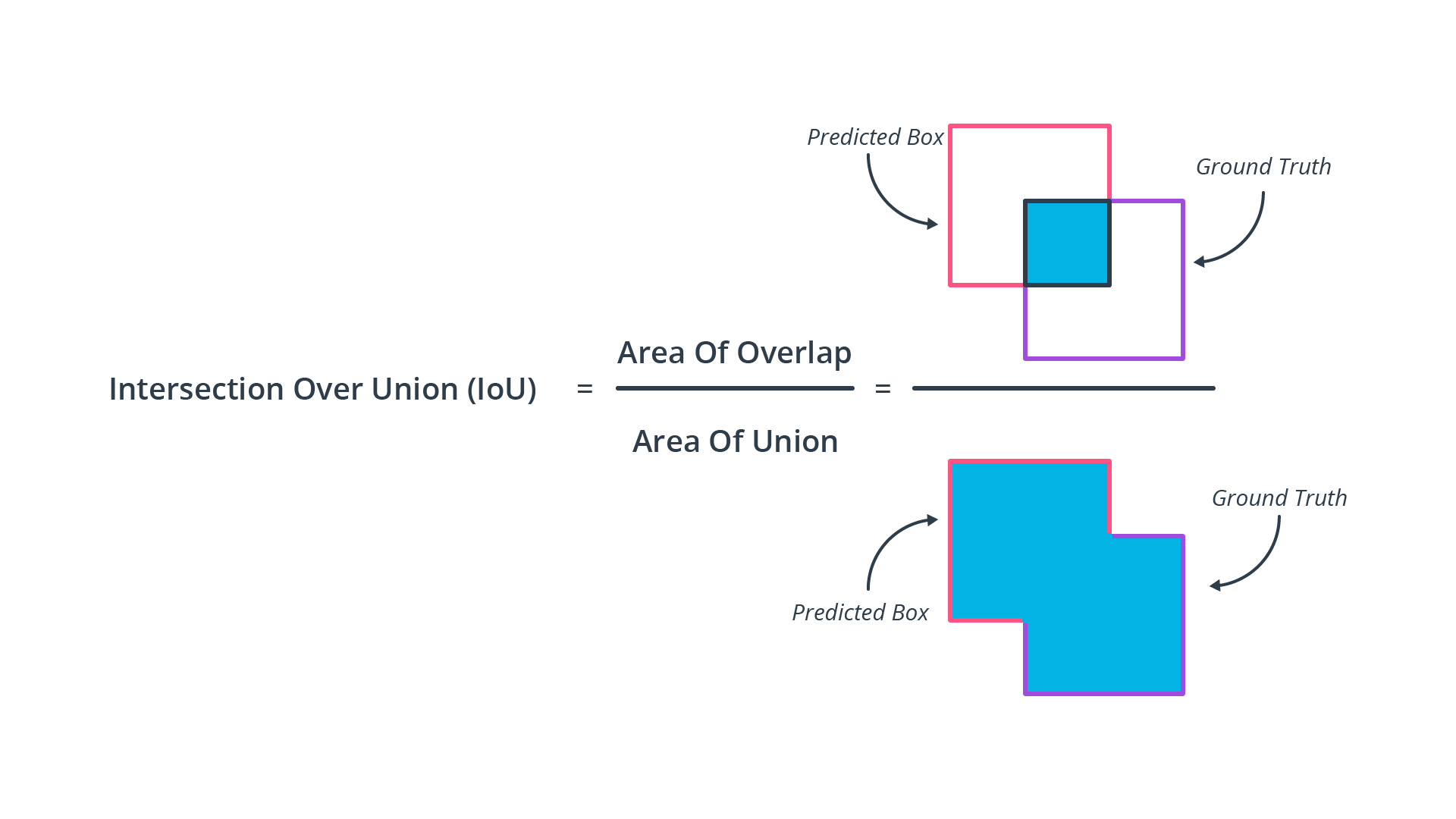
Intersection-over-Union (IoU)
正如你所看到的,检测和真实值之间的重叠越小,交集-并集值就越小。在完全没有重叠的情况下,IoU将是0.0,而对于完美匹配,IoU将是1.0。在实践中,当匹配检测和真实值标签时,我们需要为IoU决定一个“适当的”阈值。例如,如果IoU阈值为0.5,而某个标签检测匹配的IoU值为0.7,那么我们将其归类为TP。另一方面,当IoU低于阈值时,例如0.3,我们将相应的检测分类为FP。如果存在根本没有检测到的真实标签,这些就被归类为FN。
基于IoU阈值,precision和recall的值将会改变,因为在较低的阈值时,预计许多检测将与标签匹配,从而导致较高的TP数。在大多数基准(如KITTI、Waymo)中,车辆所需的最低IoU为70%。但是,在我们进一步研究改变IoU的想法之前,让我们先来看看precision-recall曲线的概念,这是我们计算检测器“平均精度”的下一步。
精确率 -召回率
(Precision-Recall)曲线
如前所述,精确率和召回率之间存在反比关系,这取决于我们选择的目标检测阈值。我们来看下图,这是各种对象检测算法的precision-recall曲线(每种颜色代表不同的算法):
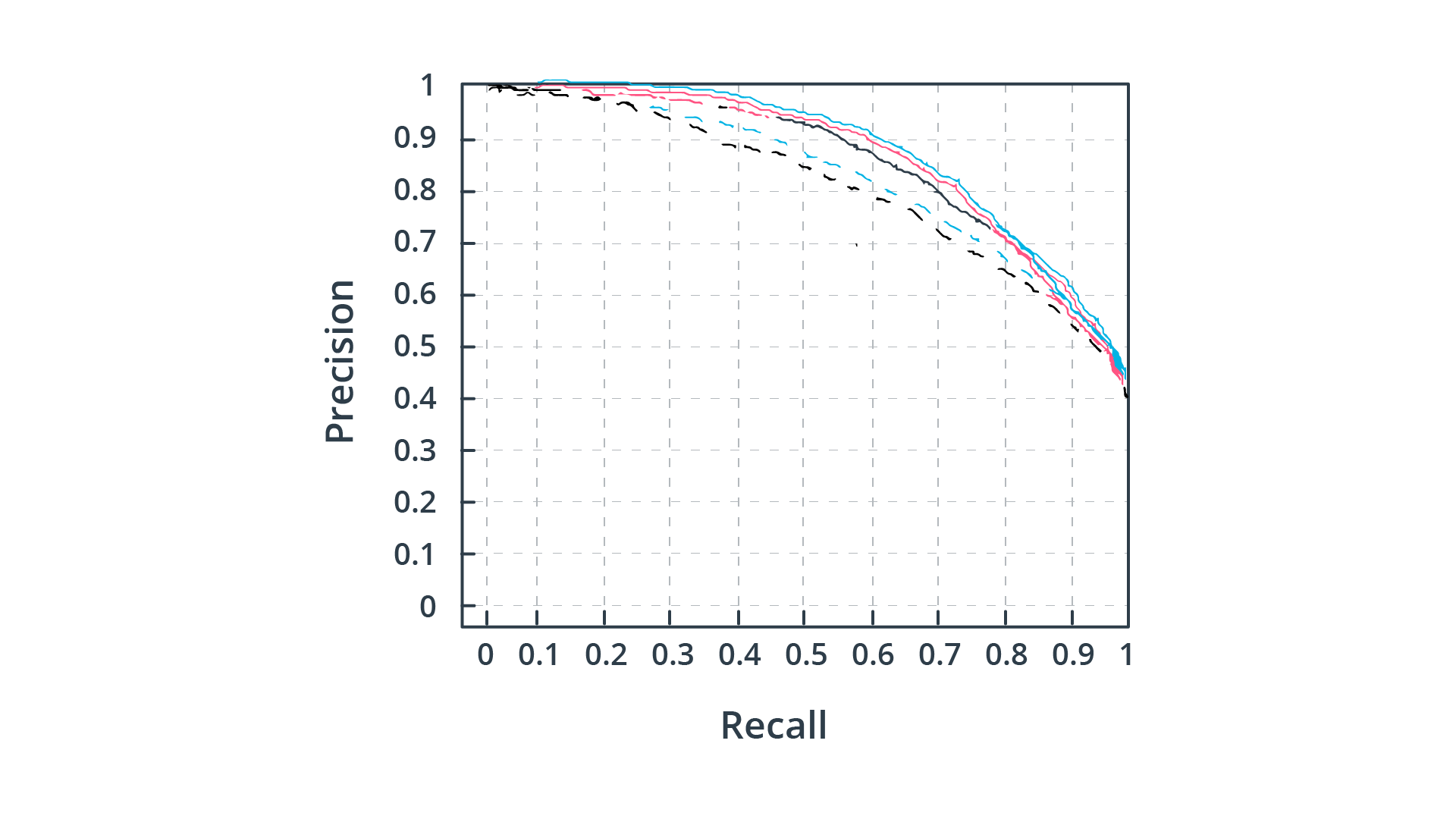
5个检测器的
精确率 -召回率
曲线
通过将检测阈值从0.0变化到1.0,并计算每个设置的 precision 和recall,可以生成这些曲线。基于这个指标,蓝色实曲线显示了最好的性能,因为随着recall值的增加,precision(即检测实际上对应于真实对象的可能性)下降的最小。理想情况下,precision应该保持在1.0,直至recall值达到1.0。因此,观察这些曲线的另一种方法用于比较检测器,是基于曲线下面的区域:这样,precision-recall 曲线的积分越大,检测器的性能就越高。根据precision-recall 曲线,工程师们可以考量在precision和recall方面应用的需求,对自己想要的检测器阈值的选择设置,而做出明智的决定。
平均精确率
平均精确率(AP)指标的思想是将precision-recall 曲线内的信息压缩成一个数字,可以用来方便地比较不同算法。这个目标是通过针对不同(=11)间距的recall值的precision值进行求和来实现的:

下图进一步说明了这个概念:
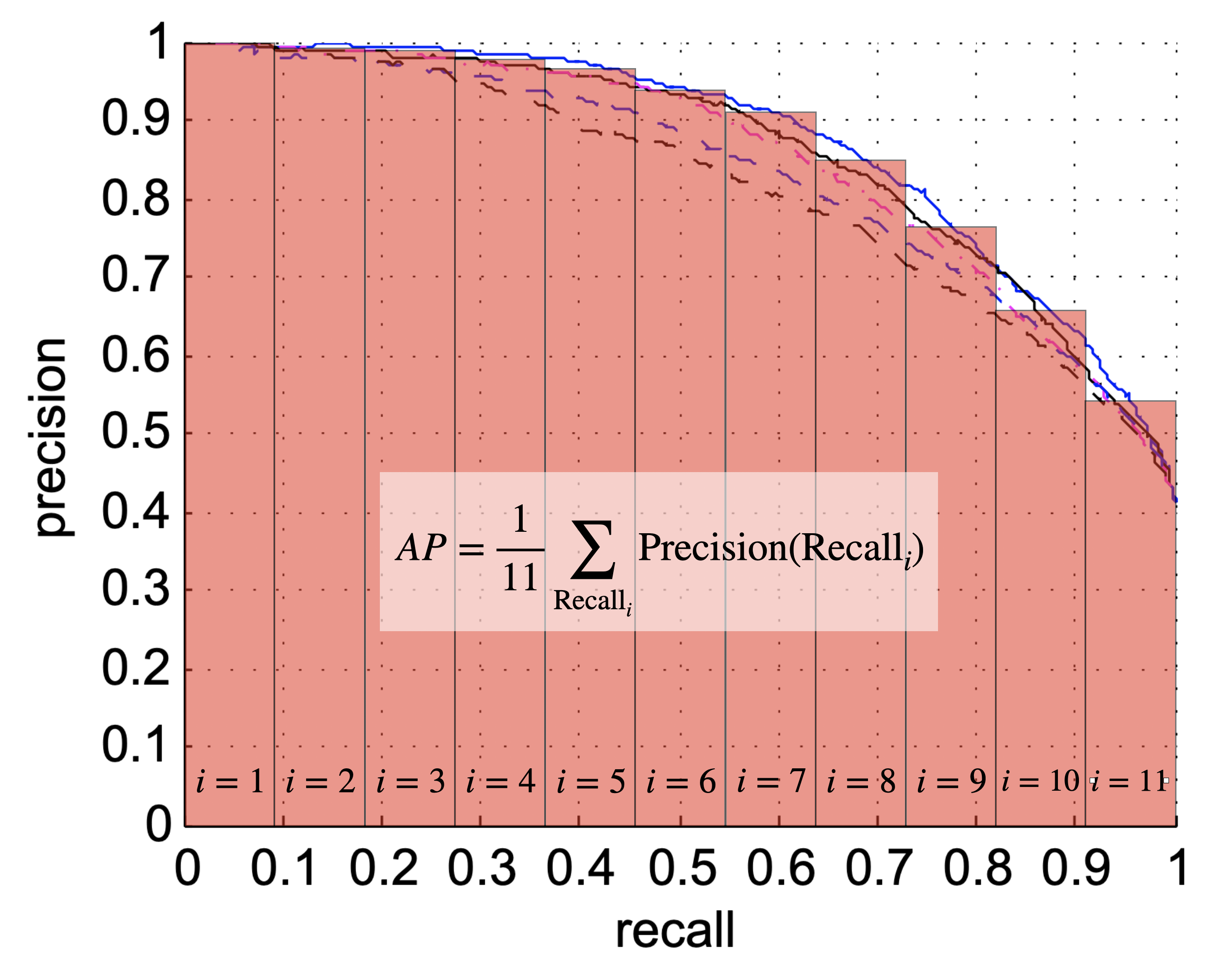
平均精确率
请注意,在实践中,以等间距增量改变阈值水平并不对应于等间距的recall增加。算法的AP得分在0.0到1.0之间,后者是一个完美的结果。
中值平均精度(mAP)
现在你已经了解如何将precision-recall曲线整合成一个简单的数字,以便于比较,我们可以进行最后一步,增加复杂性的一层:基于改变IoU阈值会影响precision和recall的观察,中值平均精度(mAP)度量的思想是计算各种IoU阈值的AP得分,然后从这些值计算平均值。 下图显示了几种IoU阈值设置的precision-recall曲线:
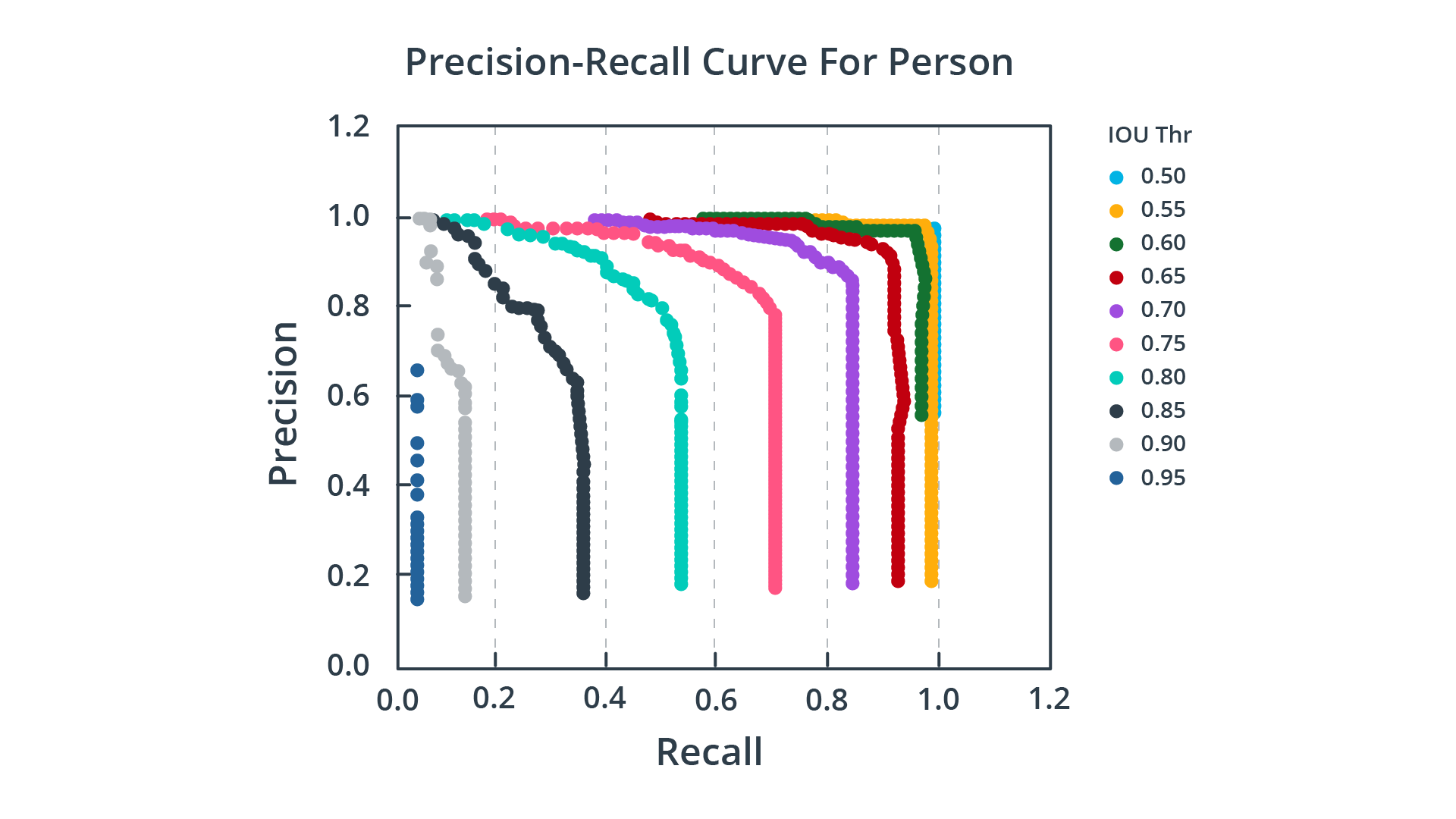
不同IoU阈值的Precision-Recall曲线
可以看到,随着IoU阈值的减小,曲线的形状接近一个矩形。 此外,一些排名网站不仅考虑IoU阈值,还考虑各种对象类。例如,在PASCAL VOC 2007挑战中,只考虑了一个IoU设置(0.5)和20个对象类。另一方面,在COCO 2017挑战中,mAP平均超过10个IoU设置和80个对象类。
七、实现精确率
和召回率
从Waymo Open数据集中提取标签
在本节中,将展示如何从Waymo帧加载特定传感器的真实标签。下面的列表显示了标签的布局:
`-- Label
|-- Box
| |-- center_x
| |-- center_y
| |-- center_z
| |-- length
| |-- width
| |-- height
| `-- heading
|-- Metadata
| |-- speed_x
| |-- speed_y
| |-- accel_x
| `-- accel_y
|-- type
|-- id
|-- detection_difficulty_level
`-- tracking_difficulty_level
如您所见,每个标签包括一个包含7个参数的边界框,用于描述相关对象的位置、形状和朝向。此外,还提供了关于Metadata(元数据)子分支中的速度和加速的信息。最后,每个标签都与一个类型(例如TYPE_VEHICLE)相关联,具有唯一的标识符以及关于检测和跟踪难度级别的信息。这两者在性能评估中很重要,因为有些物体可能对传感器来说是不可见的(例如,停在墙后的车辆),因此不应被计入传感器性能的负面影响。
例C2-4-2:遍历所有标签并计算类型和难度级别
注意:你可以在basic_loop.py文件中执行l2_examples.count_vehicles(…)函数来运行这个演示。
下面的代码循环遍历一个帧中的所有标签,并计算车辆的总数以及被标记为难以检测的车辆的数量:
for label in frame.laser_labels:
if label.type == label_pb2.Label.Type.TYPE_VEHICLE:
count_vehicles.cnt_vehicles += 1
if label.detection_difficulty_level > 0:
count_vehicles.cnt_difficult_vehicles += 1
当执行sequence 3和~200帧的完整范围的代码时,将得到以下输出:
no. of labelled vehicles = 11339, no. of vehicles difficult to detect = 47
正如你所看到的,与场景中出现的大量实际对象相比,标记为“困难”的对象数量非常少。然而,在评估一个数据集以评估检测器性能时,排除此类标签仍然是一个明智的步骤,以避免对评估结果引入偏见。
示例C2-4-3:在BEV地图顶部显示标签边界框
注意:可以通过在上面工作区的basic_loop.py文件中执行函数l2_examples.render_bb_over_bev(…)来运行这个演示。
在下一步中,我们将把标签边界框显示为BEV地图的覆盖层。使用以下代码,可以从文件中加载一个预先计算的映射:
lidar_bev = load_object_from_file(results_fullpath, data_filename, 'lidar_bev', cnt_frame)
然后,需要将BEV地图从张量格式转换为8位数据结构,这样就可以使用OpenCV来显示它:
bev_map = (bev_map.squeeze().permute(1, 2, 0).numpy() * 255).astype(np.uint8)
bev_map = cv2.resize(bev_map, (configs.bev_width, configs.bev_height))
bev_map = cv2.rotate(bev_map, cv2.ROTATE_180)
cv2.imshow("BEV map", bev_map)
当这段代码执行时,得到的图像如下所示:

所有三种颜色通道的BEV地图
这里显示的BEV地图将单个的高度、强度和密度地图统一为一个彩色图像。在后续项目中,将编写生成该图像的实际代码。现在,使用这个预先计算的结果进行可视化。
例C2-4-4:在BEV映射顶部显示检测到的对象
注意:可以通过在上面工作区的basic_loop.py文件中执行函数l2_examples.render_obj_over_bev(…)来运行这个演示。
接下来,我们需要从所有标签中提取实际的边界框,并将其覆盖到BEV图像上。要做到这一点,可以使用两个helper函数,它们执行从Waymo边框格式到检测和跟踪模块中使用的格式转换,然后执行实际的投影:
label_objects = tools.convert_labels_into_objects(labels, configs)
tools.project_detections_into_bev(bev_map, label_objects, configs, [0,255,0])
这两个函数都位于misc.objdet_tools.py中。当执行时,结果如下所示:

带有真实标签的BEV地图(绿色)
正如预期的那样,绿色的边界框被放置在相应的车辆点云周围。注意,在BEV地图顶部部分可见的车辆没有被标记,对于每个标签,至少50%的区域必须位于BEV地图内-否则将被丢弃。
加载预先计算的检测
在下一步中,将从文件加载预先计算的对象检测,并以与标签相同的方式将其分层到BEV地图上。为此,首先需要发出以下命令:
detections = load_object_from_file(results_fullpath, data_filename, 'detections', cnt_frame)
tools.project_detections_into_bev(bev_map, detections, configs, [0,0,255])
注意,在即将到来的项目中,将实现计算二进制和被检测对象的实际代码。但是现在,由于我们关注的是评估过程,所以在这一点上,只要简单地按原样使用两者就足够了,而不必关心关于它们实现的太多细节。

带有标签(绿色)和检测到的对象(红色)的BEV地图
正如从图像中看到的,两辆车都已被检测算法成功检测,因此是真阳性(TP)。由于没有遗漏检测(FN)或幻像物体(FP),检测器对这一帧的得分非常完美。但如果是另一个sequence(序列),情况看起来就不一样了:
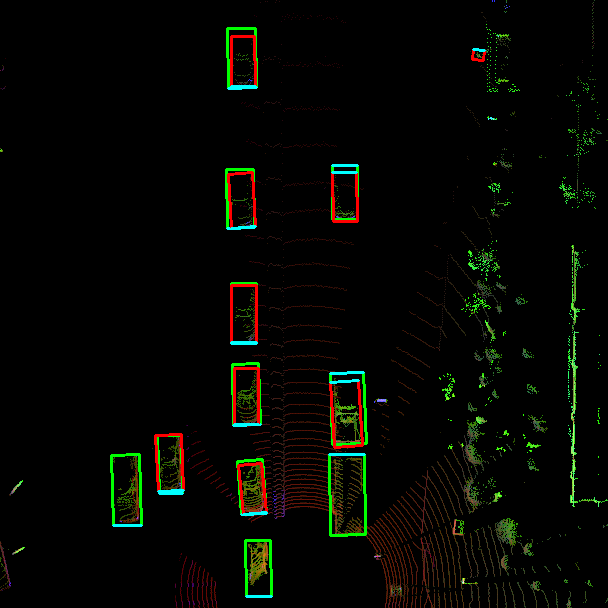
带有标签(绿色)和被检测对象(红色)的复杂交通场景的BEV地图
计算召回率和精确率
显然,单个帧不足以计算精确率和召回率的可靠估计。所以为了得到更有意义的结果,需要分析更多的帧。由于手动处理(如前面练习中的单幅图像)不适用于大型数据集,因而评估需要自动化。为了做到这一点,需要将标签框与检测框进行配对,对每个框,保留重叠最大的匹配(=IoU)。为此,创建了大量预先计算的文件,其中包含 sequence1大约200帧的TP、FP和FN,置信度阈值水平的几个设置,用于对象检测中决定何时保留候选对象。注意,执行匹配的实际代码是后期项目的一部分。
为了加载单个帧的结果,需要对每一帧执行以下代码:
conf_thresh = 0.5
det_performance = load_object_from_file(results_fullpath, data_filename, 'det_performance_' + str(conf_thresh), cnt_frame)
det_performance_all.append(det_performance)
注意,在第二行中,附加了一个包含当前置信阈值(用于对象检测)的变量。这使得可以加载TP, FP和FN的各种置信水平,这样我们就可以得到平均精确率(AP)的估计。目前,我们只使用单一设置。第三行将当前帧的性能结果附加到包含所有之前结果的列表中,这样在所有帧的循环结束时,det_performance_all包含整个序列的所有TP、TN和FN。
八、练习:评估目标检测的性能
工作文件:
-
basic_loop.py
-
lesson-2-object-detection/exercises/starter/l2_exercises.py
首先,请将上面列出的代码添加到basic_loop.py的主循环中,切换到sequence1,帧设置为[0,200]并执行循环。当累积完成后,打开l2_exercises.py中的compute_precision_recall函数,并添加计算精确率和召回率所需的代码。同时,打印TP, FP和FN的数量以及精确率和召回率的结果到终端。结果应该如下所示:
TP = 552, FP = 50, FN = 188
precision = 0.9169435215946844, recall = 0.745945945945946, conf_thres = 0.5
基于这些结果,可以评估检测器的性能:虽然总共成功检测了552辆汽车,但发生了50次幻影检测,遗漏了188次。虽然这听起来可能很多,但我们不知道这些错误发生的位置:它们是在驾驶过程中发生的吗?幻影物体出现了多久?实际车辆消失了多少帧?在实践中,工程团队需要调查每个案例来分析这些错误的情况。此外,由于遗漏的检测和短暂的幻影对象等问题,可以通过跟踪阶段消除或至少减轻,因此不关注帧对帧的检测,而是关注对象随时间的跟踪是有意义的。
根据精确率结果,可以说,探测到实际车辆的概率为~92%。召回率结果为我们提供了车辆被检测到的概率为~75%的信息。注意,这两个值仅适用于置信阈值为0.5的情况。
参考代码:
def compute_precision_recall(det_performance_all, conf_thresh=0.5):
if len(det_performance_all)==0 :
print("no detections for conf_thresh = " + str(conf_thresh))
return
# extract the total number of positives, true positives, false negatives and false positives
# format of det_performance_all is [ious, center_devs, pos_negs]
pos_negs = []
for item in det_performance_all:
pos_negs.append(item[2])
pos_negs_arr = np.asarray(pos_negs)
positives = sum(pos_negs_arr[:,0])
true_positives = sum(pos_negs_arr[:,1])
false_negatives = sum(pos_negs_arr[:,2])
false_positives = sum(pos_negs_arr[:,3])
print("TP = " + str(true_positives) + ", FP = " + str(false_positives) + ", FN = " + str(false_negatives))
# compute precision
precision = true_positives / (true_positives + false_positives) # When an object is detected, what are the chances of it being real?
# compute recall
recall = true_positives / (true_positives + false_negatives) # What are the chances of a real object being detected?
print("precision = " + str(precision) + ", recall = " + str(recall) + ", conf_thres = " + str(conf_thresh) + "\n")
九、练习:绘制精确率和召回率曲线
工作文件:
-
basic_loop.py
-
lesson-2-object-detection/exercises/starter/l2_exercises.py
一旦完成,请通过创建一个散点图来可视化结果,就像这样:
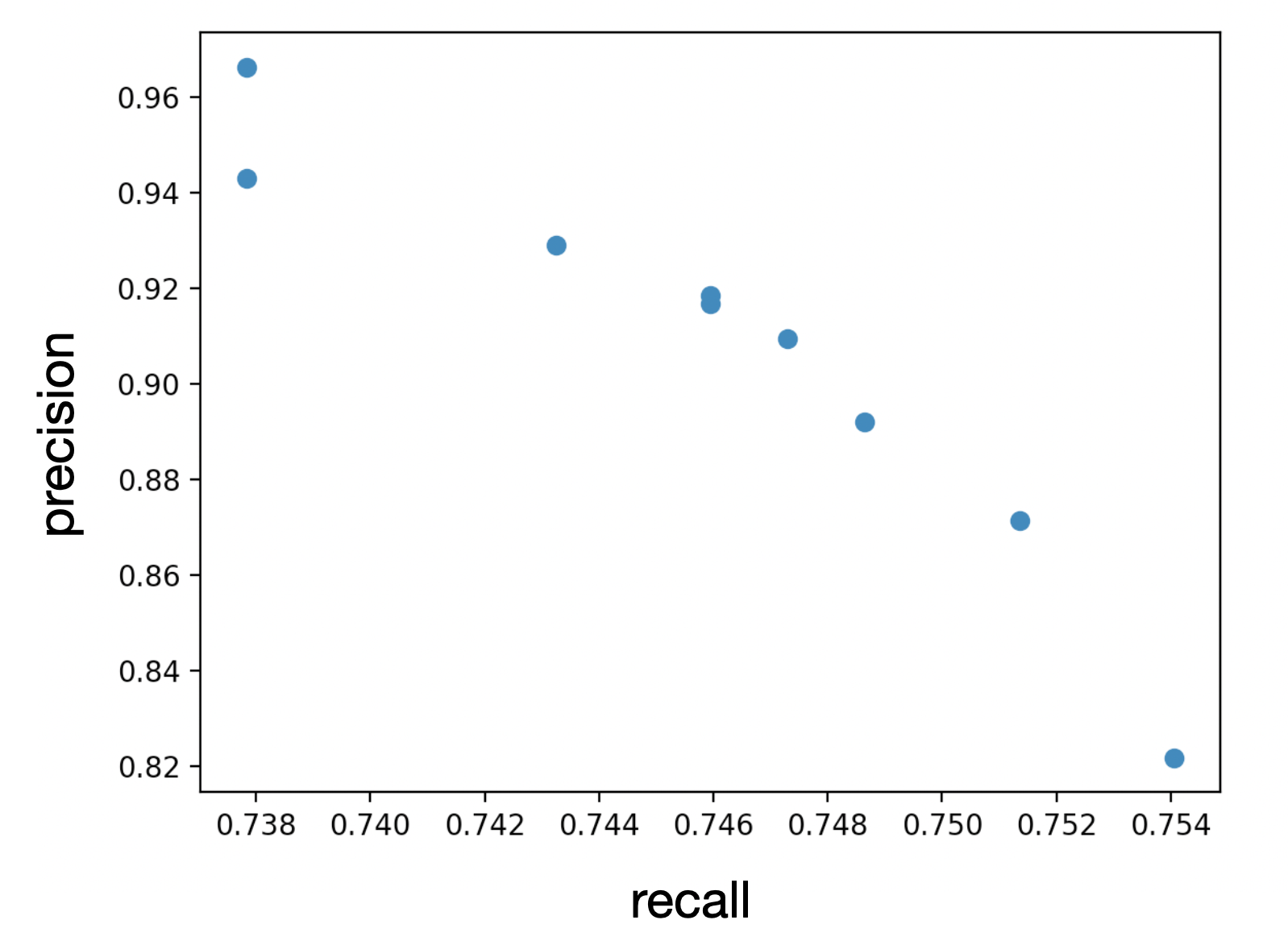
sequence1的精确率和召回率曲线
当一切正常工作时,对于降低精确率,召回率增加,反之亦然。基于从0到1.0的全召回尺度,就有可能计算出如上所述的平均精确率(AP)。注意,在实际操作中,需要评估的序列数量和置信阈值要大得多。然而,为限制本文的范围,仅满足于创建精确率和召回率曲线的一部分,并理解其背后的基本概念。
参考代码:
def plot_precision_recall():
# Please note: this function assumes that you have pre-computed the precions/recall value pairs from the test sequence
# by subsequently setting the variable configs.conf_thresh to the values 0.1 ... 0.9 and noted down the results.
# Please create a 2d scatter plot of all precision/recall pairs
import matplotlib.pyplot as plt
P = [0.97, 0.94, 0.93, 0.92, 0.915, 0.91, 0.89, 0.87, 0.82]
R = [0.738, 0.738, 0.743, 0.746, 0.746, 0.747, 0.748, 0.752, 0.754]
plt.scatter(R, P)
plt.show()
十、总结
现在,已经对基于点云的物体检测的最相关类别有了一个总览。它们在各自的数据表示、特征提取和检测网络的体系结构方面有所不同。
此外,了解了一种可用的探测器是如何工作的,它是通过将激光雷达点云转换为鸟瞰视角,然后将强度、高度和点密度输入卷积神经网络来寻找车辆。
最后,是如何使用召回率和精度来评估目标检测器的性能。