利用多层神经网络对鸢尾花进行分类。鸢尾花数据集(iris)一共有150个数据,这些数据分为3类(分别为:setosa,versicolor,virginica),每类50个数据,前五十个样本点属于类别1,中间50个数据是类别2,末尾50个数据是类别3。每个数据包含4个属性:萼片(sepal)长度、萼片宽度、花瓣(petal)长度、花瓣宽度。
hidden_layer_sizes = (97,98)表示两层隐含层,第一层97个神经元,第二层98个神经元。
首先加载数据集:
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
import numpy as np
from matplotlib import pyplot as plt
from sklearn.neural_network import MLPClassifier
## 加载数据集
np.random.seed(0)
iris=datasets.load_iris() # 使用 scikit-learn 自带的 iris 数据集
X=iris.data[:,0:2] # 使用前两个特征,方便绘图
Y=iris.target # 标记值
data=np.hstack((X,Y.reshape(Y.size,1)))
np.random.shuffle(data) # 混洗数据。因为默认的iris 数据集:前50个数据是类别0,中间50个数据是类别1,末尾50个数据是类别2.混洗将打乱这个顺序
X=data[:,:-1]
Y=data[:,-1]
train_x=X[:-30]
test_x=X[-30:] # 最后30个样本作为测试集
train_y=Y[:-30]
test_y=Y[-30:]X=iris.data[:,0:2] 表示使用前两个特征(sepal length和sepal width),因为两个特征方便在二维图形上表现出来,横轴为:sepal length,纵轴为:sepal width。对数据进行混洗,最后取出最后的30个数据作为测试集。
def plot_classifier_predict_meshgrid(ax,clf,x_min,x_max,y_min,y_max):
''' 绘制 MLPClassifier 的分类结果 :param ax: Axes 实例,用于绘图:param clf: MLPClassifier 实例
:param x_min: 第一维特征的最小值:param x_max: 第一维特征的最大值:param y_min: 第二维特征的最小值
:param y_max: 第二维特征的最大值:return: None '''
plot_step = 0.02 # 步长
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.Paired) # 绘图
def plot_samples(ax,x,y):
''' 绘制二维数据集:param ax: Axes 实例,用于绘图:param x: 第一维特征
:param y: 第二维特征 :return: None'''
n_classes = 3
plot_colors = "bry" # 颜色数组。每个类别的样本使用一种颜色
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
ax.scatter(x[idx, 0], x[idx, 1], c=color,
label=iris.target_names[i], cmap=plt.cm.Paired) # 绘图def mlpclassifier_iris():
'''
使用 MLPClassifier 预测调整后的 iris 数据集
:return: None
'''
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
classifier=MLPClassifier(activation='logistic',max_iter=10000,
hidden_layer_sizes=(30,))
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
print("Training accuracy:%f;Testing accuracy:%f"%(train_score,test_score))
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("train score:%f;test score:%f"%(train_score,test_score))
plt.show()
其中使用到了两个绘图函数 :
plot_samples(ax,x,y):用于绘制样本点。
plot_classifier_predict_meshgrid(ax,clf,x_min,x_max,y_min,y_max):用于绘制分类器对平面上每个点进行分类预测的分布图。
![]()
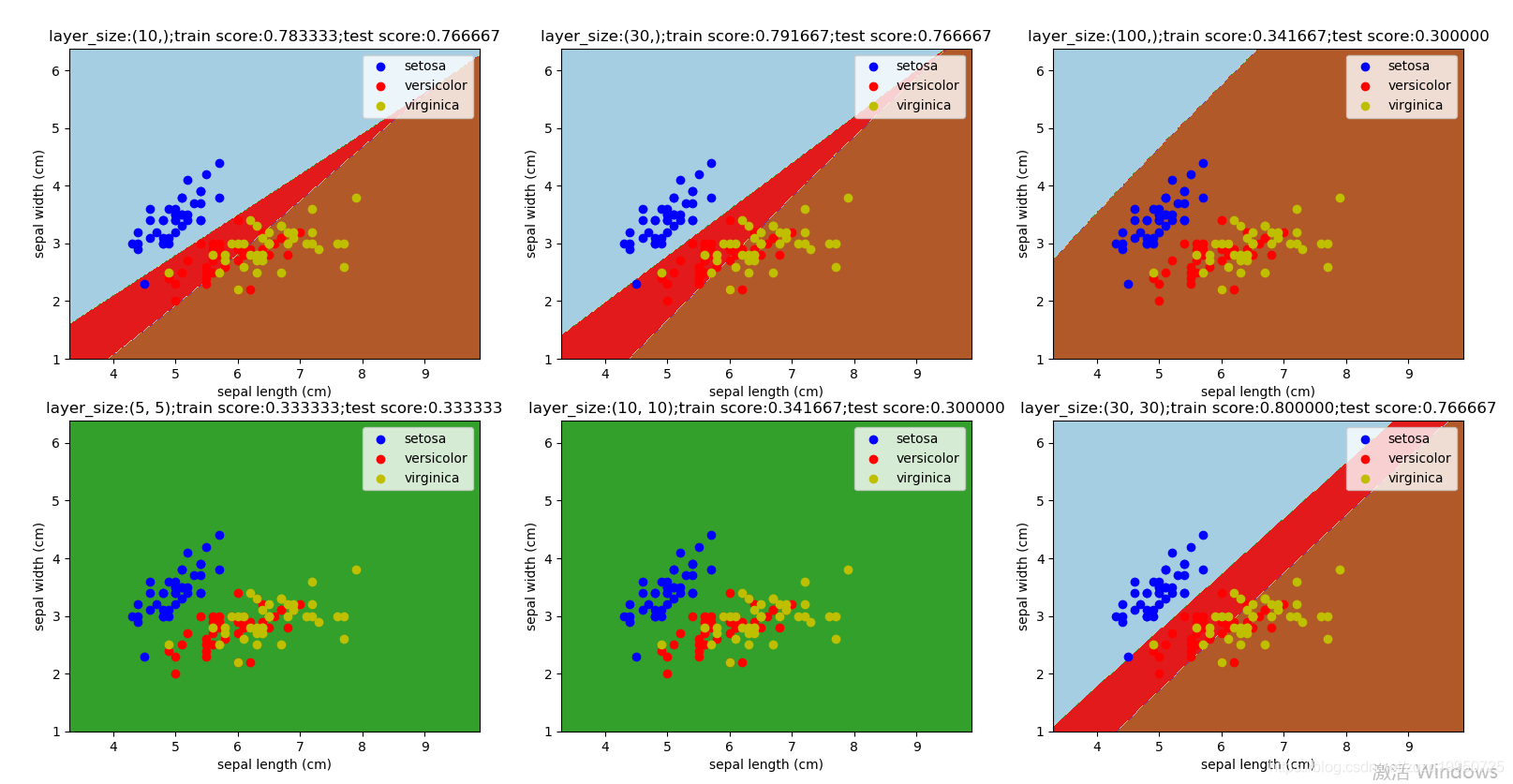
观察不同的隐藏层对多层神经网络分类器的影响:调用函数:mlpclassifier_iris_hidden_layer_sizes(),得到输出结果图,我们可以看到:样本数据150个,因此单层神经元(比如100)过多时,训练精度和预测精度下降。此外,神经网络隐藏层为(5,5)时,训练精度和预测精度也比较差。
def mlpclassifier_iris_hidden_layer_sizes():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 hidden_layer_sizes 的影响
:return: None
'''
fig=plt.figure()
hidden_layer_sizes=[(10,),(30,),(100,),(5,5),(10,10),(30,30)] # 候选的 hidden_layer_sizes 参数值组成的数组
for itx,size in enumerate(hidden_layer_sizes):
ax=fig.add_subplot(2,3,itx+1)
classifier=MLPClassifier(activation='logistic',max_iter=10000
,hidden_layer_sizes=size)
classifier.fit(train_x,train_y)
train_score=classifier.score(train_x,train_y)
test_score=classifier.score(test_x,test_y)
x_min, x_max = train_x[:, 0].min() - 1, train_x[:, 0].max() + 2
y_min, y_max = train_x[:, 1].min() - 1, train_x[:, 1].max() + 2
plot_classifier_predict_meshgrid(ax,classifier,x_min,x_max,y_min,y_max)
plot_samples(ax,train_x,train_y)
ax.legend(loc='best')
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[1])
ax.set_title("layer_size:%s;train score:%f;test score:%f"
%(size,train_score,test_score))
plt.show()
由图可以发现:隐藏层(30,)时精度最高。
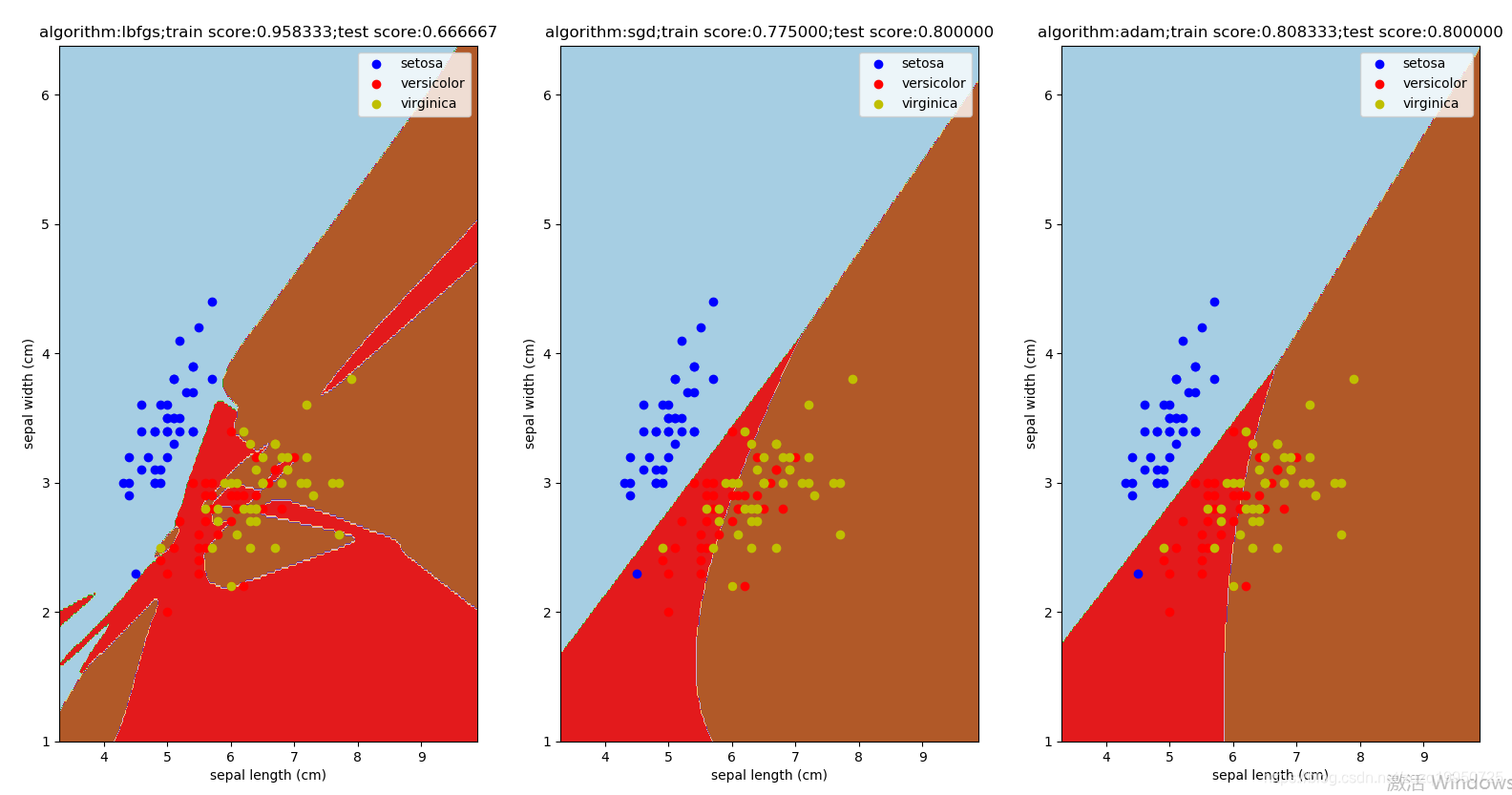
下面观察激活函数对多层神经网络分类器的影响:调用函数mlpclassifier_iris_ativations(),可以看到不同激活函数对性能有影响,但相互之间无显著差别。
def mlpclassifier_iris_ativations():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 activation 的影响
:return: None
'''
fig=plt.figure()
ativations=["logistic","tanh","relu"] # 候选的激活函数字符串组成的列表
for itx,act in enumerate(ativations):
ax=fig.add_subplot(1,3,itx+1)
classifier=MLPClassifier(activation=act,max_iter=10000,
hidden_layer_sizes=(30,))
classifier.fit(train_x,train_y)
#后买你与前面代码相同,不详述。下面观察优化算法对多层神经网络分类器的影响:调用函数mlpclassifier_iris_algorithms(),可以看到不同优化算法对性能有影响,但相互之间无显著差别。
def mlpclassifier_iris_algorithms():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的 algorithm 的影响
:return: None
'''
fig=plt.figure()
algorithms=["l-bfgs","sgd","adam"] # 候选的算法字符串组成的列表
for itx,algo in enumerate(algorithms):
ax=fig.add_subplot(1,3,itx+1)
classifier=MLPClassifier(activation="tanh",max_iter=10000,
hidden_layer_sizes=(30,),solver=algo)
classifier.fit(train_x,train_y)
#下面代码与上相同,不详述。
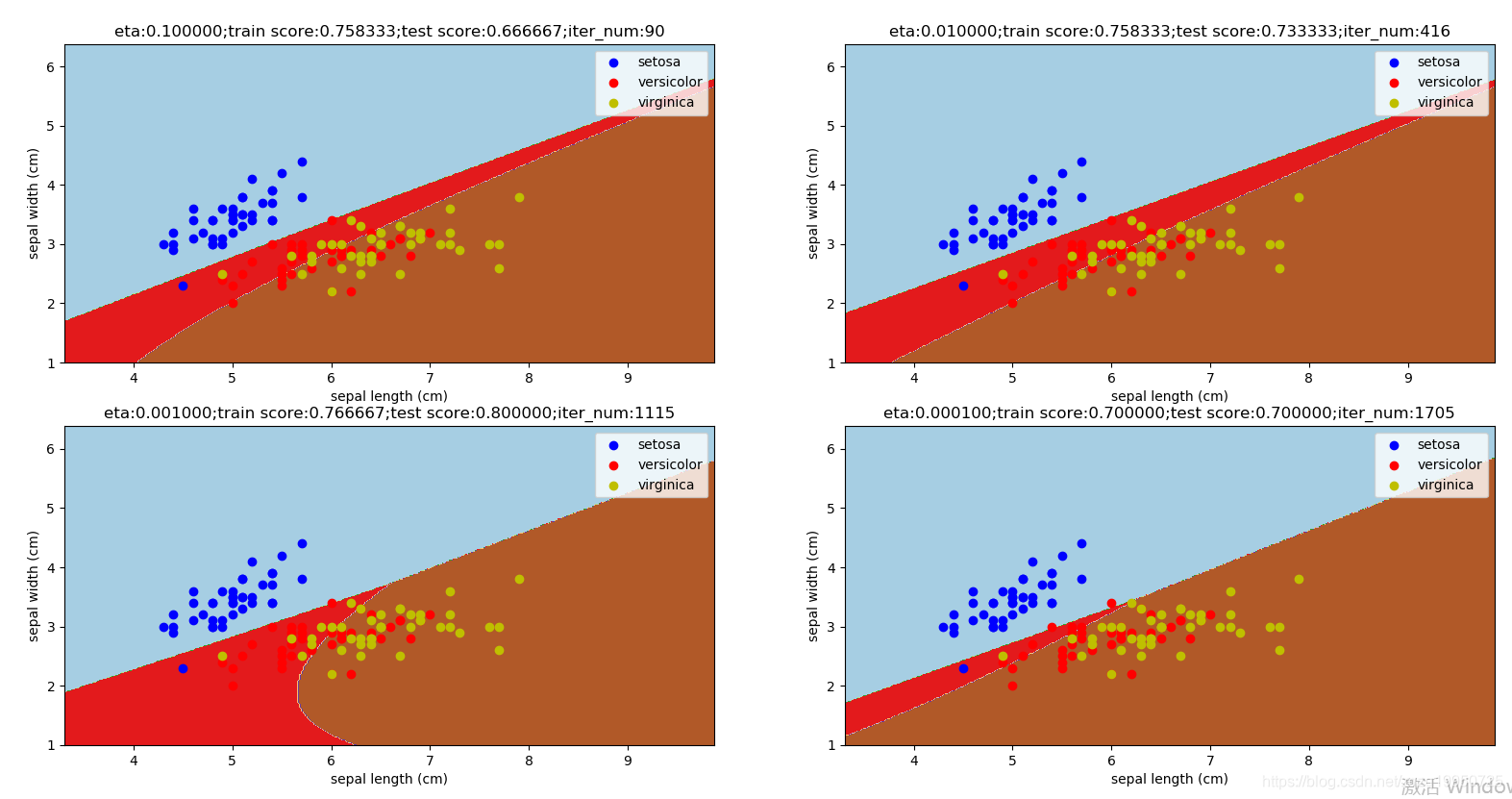
最后观察学习率对多层神经网络分类器的影响:调用函数mlpclassifier_iris_eta(),可以看到:如果采用随机梯度下降法,则随着学习率的减小,总体迭代次数(iter_num)会增加;但是并不是学习率越小,预测性能越好。在学习率过小时,预测精度反而下降。
def mlpclassifier_iris_eta():
'''
使用 MLPClassifier 预测调整后的 iris 数据集。考察不同的学习率的影响
:return: None
'''
fig=plt.figure()
etas=[0.1,0.01,0.001,0.0001] # 候选的学习率值组成的列表
for itx,eta in enumerate(etas):
ax=fig.add_subplot(2,2,itx+1)
classifier=MLPClassifier(activation="tanh",max_iter=1000000,
hidden_layer_sizes=(30,),solver='sgd',learning_rate_init=eta)
classifier.fit(train_x,train_y)
#后面代码一样