在写爬虫的时候解析网页,使用最多的解析方式就是xpath解析,但是在使用在使用xpath解析的时候,明明自己写的xpath语句正确,但是返回值还是为空
原因通常是前端做的一些反爬措施,在编写网页的时候通常省略一层标签,但是被省略的标签浏览器会自动补充,修改成正确的结构。。
我们通过浏览器进行检查的时候,看到的代码结构是已经被浏览器修改后的,而爬虫获取到的是源代码
所以根据修改后的xpath解析源代码会找不到相应的元素,返回值自然为空
举例
浏览器修改后的代码
xpath语句
'/html/body/div[5]/div[3]/div[2]/table/tbody/tr[1]/td[2]/a/@href'
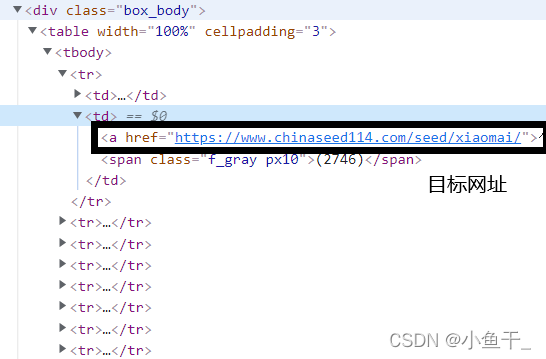
源码
缺少一个tbody标签,
xpath
/html/body/div[5]/div[3]/div[2]/table/tr[1]/td[2]/a/@href
将tbody删除

总结 当使用xpath获取不到向相应的元素的时候,观察一下源码结构,根据源码进行解析
版权声明:本文为qq_52007481原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。