概述
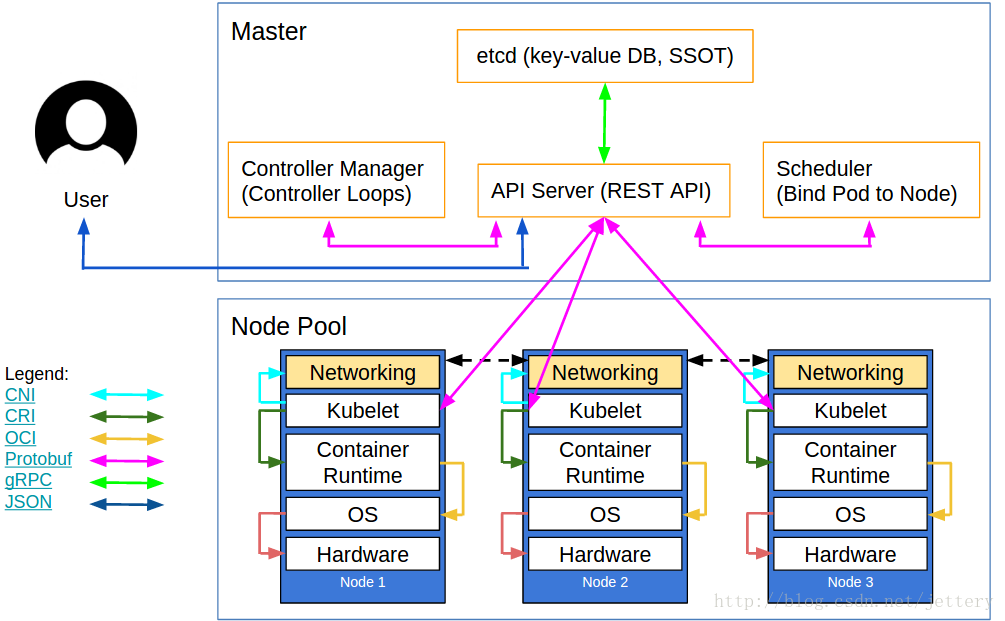
Kubelet组件运行在Node节点上,维持运行中的Pods以及提供kuberntes运行时环境,主要完成以下使命:
1.监视分配给该Node节点的pods
2.挂载pod所需要的volumes
3.下载pod的secret
4.通过docker/rkt来运行pod中的容器
5.周期的执行pod中为容器定义的liveness探针
6.上报pod的状态给系统的其他组件
7.上报Node的状态
整个kubelet可以按照上图所示的模块进行划分,模块之间相互配合完成Kubelet的所有功能.下面对上图中的模块进行简要的介绍.
Kubelet对外暴露的端口,通过该端口可以获取到kubelet的状态
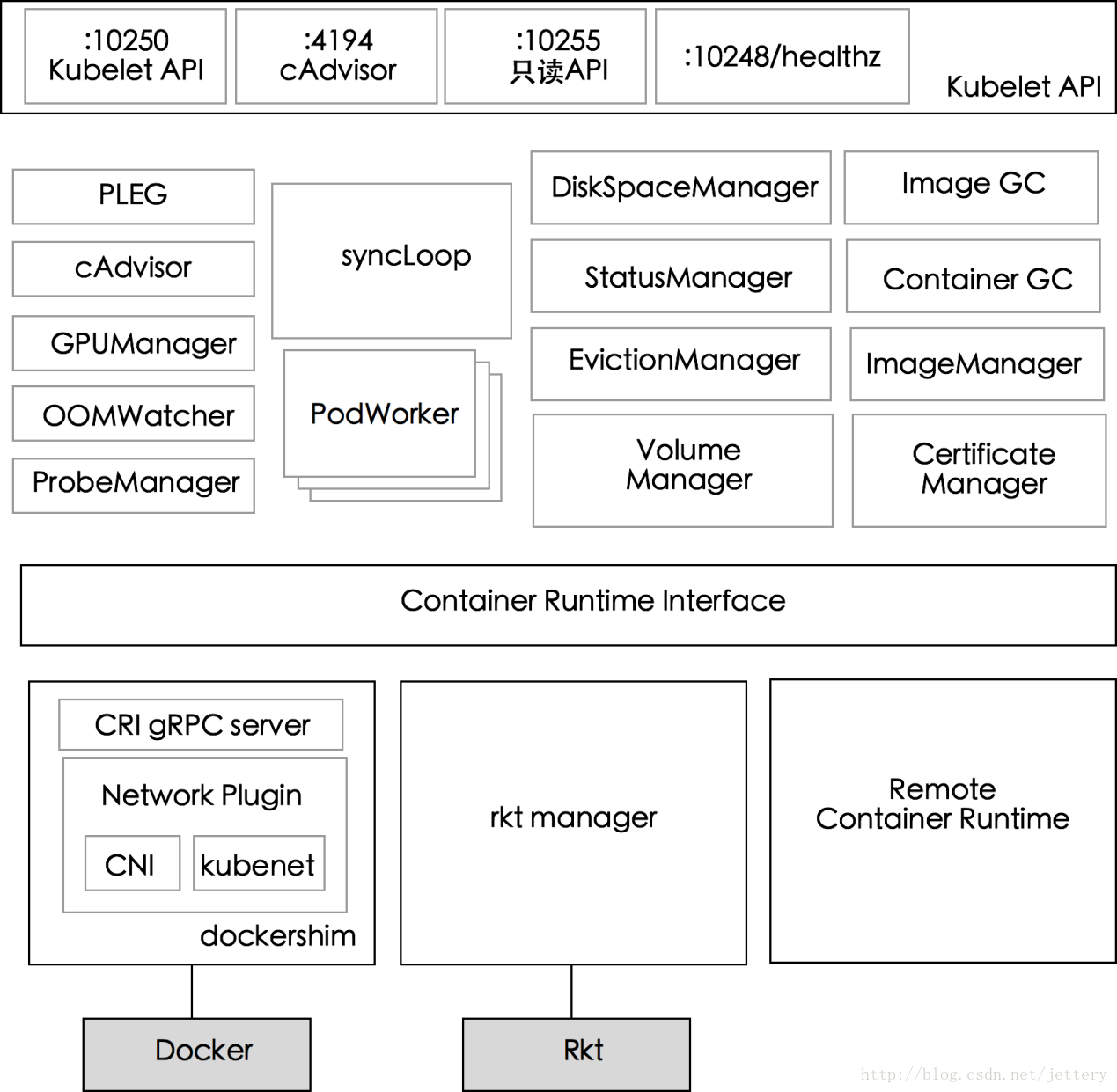
10250 kubelet API –kublet暴露出来的端口,通过该端口可以访问获取node资源以及状态,另外可以配合kubelet的启动参数contention-profiling enable-debugging-handlers来提供了用于调试和profiling的api
4194 cAdvisor –kublet通过该端口可以获取到本node节点的环境信息以及node上运行的容器的状态等内容
10255 readonly API –kubelet暴露出来的只读端口,访问该端口不需要认证和鉴权,该http server提供查询资源以及状态的能力.注册的消息处理函数定义src/k8s.io/kubernetes/pkg/kubelet/server/server.go:149
10248 /healthz –kubelet健康检查,通过访问该url可以判断Kubelet是否正常work, 通过kubelet的启动参数–healthz-port –healthz-bind-address来指定监听的地址和端口.默认值定义在pkg/kubelet/apis/kubeletconfig/v1alpha1/defaults.go

核心功能模块
-
PLEG
PLEG全称为PodLifecycleEvent,PLEG会一直调用container runtime获取本节点的pods,之后比较本模块中之前缓存的pods信息,比较最新的pods中的容器的状态是否发生改变,当状态发生切换的时候,生成一个eventRecord事件,输出到eventChannel中. syncPod模块会接收到eventChannel中的event事件,来触发pod同步处理过程,调用contaiener runtime来重建pod,保证pod工作正常. -
cAdvisor
cAdvisor集成在kubelet中,起到收集本Node的节点和启动的容器的监控的信息,启动一个Http Server服务器,对外接收rest api请求.cAvisor模块对外提供了interface接口,可以通过interface接口获取到node节点信息,本地文件系统的状态等信息,该接口被imageManager,OOMWatcher,containerManager等所使用
cAdvisor相关的内容详细可参考github.com/google/cadvisor -
GPUManager
对于Node上可使用的GPU的管理,当前版本需要在kubelet启动参数中指定feature-gates中添加Accelerators=true,并且需要才用runtime=Docker的情况下才能支持使用GPU,并且当前只支持NvidiaGPU,GPUManager主要需要实现interface定义的Start()/Capacity()/AllocateGPU()三个函数 -
OOMWatcher
系统OOM的监听器,将会与cadvisor模块之间建立SystemOOM,通过Watch方式从cadvisor那里收到的OOM信号,并发生相关事件 -
ProbeManager
探针管理,依赖于statusManager,livenessManager,containerRefManager,实现Pod的健康检查的功能.当前支持两种类型的探针:LivenessProbe和ReadinessProbe,
LivenessProbe:用于判断容器是否存活,如果探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理
ReadinessProbe: 用于判断容器是否启动完成
探针有三种实现方式
execprobe:在容器内部执行一个命令,如果命令返回码为0,则表明容器健康
tcprobe:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康
httprobe:通过容器的IP地址,端口号以及路径调用http Get方法,如果响应status>=200 && status<=400的时候,则认为容器状态健康 -
StatusManager
该模块负责pod里面的容器的状态,接受从其它模块发送过来的pod状态改变的事件,进行处理,并更新到kube-apiserver中. -
Container/RefManager
容器引用的管理,相对简单的Manager,通过定义map来实现了containerID与v1.ObjectReferece容器引用的映射. -
EvictionManager
evictManager当node的节点资源不足的时候,达到了配置的evict的策略,将会从node上驱赶pod,来保证node节点的稳定性.可以通过kubelet启动参数来决定evict的策略.另外当node的内存以及disk资源达到evict的策略的时候会生成对应的node状态记录. -
ImageGC
imageGC负责Node节点的镜像回收,当本地的存放镜像的本地磁盘空间达到某阈值的时候,会触发镜像的回收,删除掉不被pod所使用的镜像.回收镜像的阈值可以通过kubelet的启动参数来设置. -
ContainerGC
containerGC负责NOde节点上的dead状态的container,自动清理掉node上残留的容器.具体的GC操作由runtime来实现. -
ImageManager
调用kubecontainer.ImageService提供的PullImage/GetImageRef/ListImages/RemoveImage/ImageStates的方法来保证pod运行所需要的镜像,主要是为了kubelet支持cni. -
VolumeManager
负责node节点上pod所使用的volume的管理.主要涉及如下功能
Volume状态的同步,模块中会启动gorountine去获取当前node上volume的状态信息以及期望的volume的状态信息,会去周期性的sync volume的状态,另外volume与pod的生命周期关联,pod的创建删除过程中volume的attach/detach流程.更重要的是kubernetes支持多种存储的插件,kubelet如何调用这些存储插件提供的interface.涉及的内容较多,更加详细的信息可以看kubernetes中volume相关的代码和文档. -
containerManager
负责node节点上运行的容器的cgroup配置信息,kubelet启动参数如果指定–cgroupPerQos的时候,kubelet会启动gorountie来周期性的更新pod的cgroup信息,维持其正确.实现了pod的Guaranteed/BestEffort/Burstable三种级别的Qos,通过配置kubelet可以有效的保证了当有大量pod在node上运行时,保证node节点的稳定性.该模块中涉及的struct主要包括
-
runtimeManager
containerRuntime负责kubelet与不同的runtime实现进行对接,实现对于底层container的操作,初始化之后得到的runtime实例将会被之前描述的组件所使用.
当前可以通过kubelet的启动参数–container-runtime来定义是使用docker还是rkt.runtime需要实现的接口定义在src/k8s.io/kubernetes/pkg/kubelet/apis/cri/services.go文件里面 -
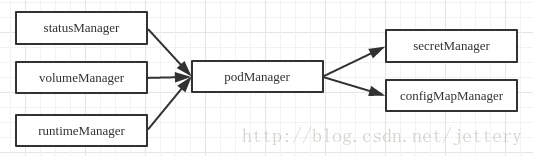
podManager
podManager提供了接口来存储和访问pod的信息,维持static pod和mirror pods的关系,提供的接口如下所示
跟其他Manager之间的关系,podManager会被statusManager/volumeManager/runtimeManager所调用,并且podManager的接口处理流程里面同样会调用secretManager以及configMapManager.
上面所说的模块可能只是kubelet所有模块中的一部分,更多的需要大家一起看探索.
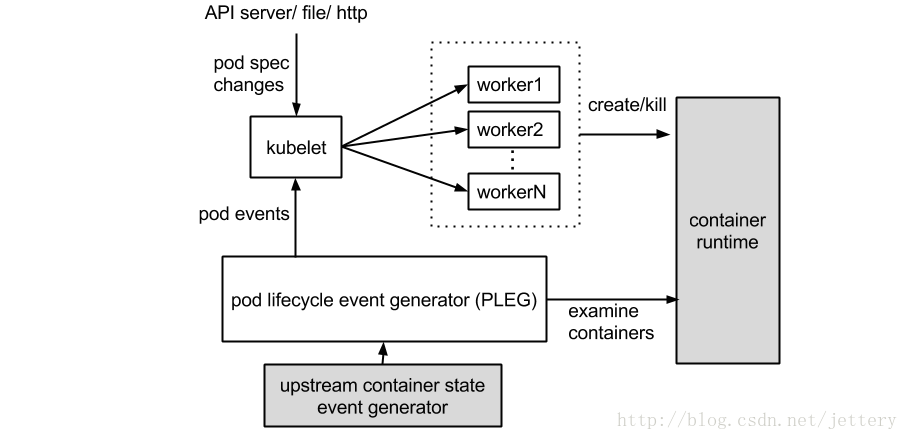


深入分析
下面进一步的深入分析kubelet的代码
Kubelet负责pod的创建,pod的来源kubelet当前支持三种类型的podSource
– FileSource: 通过kubelet的启动参数–pod-manifest-path来指定pod manifest文件所在的路径或者文件都可以.Kubelet会读取文件里面定义的pod进行创建.常常我们使用来定义kubelet管理的static pod
– HTTPSource: 通过kubelet的启动参数–manifest-url –manifest-url-header来定义manifest url. 通过http Get该manifest url获取到pod的定义
– ApiserverSource: 通过定义跟kube-apiserver进行通过的kubeclient, 从kube-apiserver中获取需要本节点创建的pod的信息.
Kubelet如何同时处理这三种podSource里面定义的pod进行处理的.在src/k8s.io/kubernetes/pkg/kubelet/kubelet.go:254的makePodSourceConfig中分别是处理三种podSource的启动参数.
三种source的实现类似,分别启动goroutinue,周期性的查看是否有新的数据来源,如果发现获取到新的数据,生成PodUpdate对象,输出到对应的channel里面.
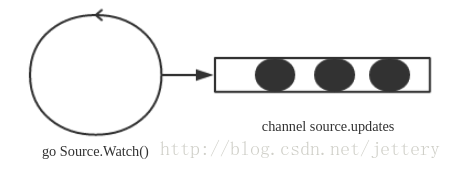
会针对每种类型创建对应的Channel.
cfg.Channel(kubetypes.FileSource)
cfg.Channel(kubetypes.HTTPSource)
cfg.Channel(kubetypes.ApiserverSource)
Channel存储在PodConfig.mux.sources里面
其中channel中传递的对象定义如下
type PodUpdate struct {
Pods []*v1.Pod
Op PodOperation
Source string
}
Op为kubetypes.SET Source表示pod的来源,可能的值为HTTPSource|FileSource|ApiserverSource,
进一步的分析代码,发现定义chanel的时候,同时也定义gorountine用来watch该channel的变化
go wait.Until(func() { m.listen(source, newChannel) }, 0, wait.NeverStop)
func (m *Mux) listen(source string, listenChannel <-chan interface{}) {
for update := range listenChannel {
m.merger.Merge(source, update)
}
}
原来是将3个channel的对象merge到podConfig.updates中.这个地方merge会对podUpdate进行预处理,处理流程可以仔细看podStorage.merge().会将事件中包含的pods与本地内存中存储pods信息进行分析,将podUpdate分成adds.updates,deletes,removes,reconsiles五类,并分别更新kubetypes.PodUpdate.Op的操作.
对于podSource中生成的podUpdate,如果初次进入该流程,一开始podUpdate.Op=kubetypes.SET, 将会podSource中定义的pod将会addPods里面,podUpdate.Op=kubetype.ADD.
定义的podConfig保存在kubeDeps.PodConfig中.
进一步跟进kubelet源码,自然想到的是谁会从channel中获取PodUpdate进行处理,进行pod同步.
Kubelet的主流程里面会启动gorountiue执行如下代码
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
glog.Info("Starting kubelet main sync loop.")
// The resyncTicker wakes up kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
for {
if rs := kl.runtimeState.runtimeErrors(); len(rs) != 0 {
glog.Infof("skipping pod synchronization - %v", rs)
time.Sleep(5 * time.Second)
continue
}
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
其中updates就是podConfig.updates中定义的channel. 同时kl.pleg.Watch()是pleg模块定义的事件channel,
SyncHandler定义
type SyncHandler interface {
HandlePodAdditions(pods []*v1.Pod)
HandlePodUpdates(pods []*v1.Pod)
HandlePodRemoves(pods []*v1.Pod)
HandlePodReconcile(pods []*v1.Pod)
HandlePodSyncs(pods []*v1.Pod)
HandlePodCleanups() error
}
syncLoopIteration方法是一个channel中事件处理中心,处理从跟pod生命周期创建相关的channel中获取事件,之后进行转发到对应的处理函数中.这个对于理解kubelet对于pod的管理至关重要.
触发同步的事件channel主要包括
1.configCh pod的配置改变
2.PLEG模块中状态更新事件
3.1s为周期的同步时钟 syncPod
4.2s为周期的执行全局清理任务的始终 CleanupPod
启动了goroutinue循环调用PodCfg.Updates()中的Channel中获取PodUpdate.进入消息中专分支流程.
1.<-configCh && u.Op=kubetype.ADD
a)执行handler.HandlePodAdditions, handler.HandlePodAdditions()的实现在kubelt.HandlePodAdditions(pods []*v1.Pod)
在Kubelt.HandlePodAdditions中再一次分发podUpdate并将kl.probeManager(AddPod(pod)),执行dispatchWork. 之后将updatePodOption初始化,添加到podWorkers.podUpdates的channel中.
dispatchWork中将updatePodOptions定义成如下结构体
type UpdatePodOptions struct {
// pod to update
Pod *v1.Pod
// the mirror pod for the pod to update, if it is a static pod
MirrorPod *v1.Pod
// the type of update (create, update, sync, kill)
UpdateType kubetypes.SyncPodType
// optional callback function when operation completes
// this callback is not guaranteed to be completed since a pod worker may
// drop update requests if it was fulfilling a previous request. this is
// only guaranteed to be invoked in response to a kill pod request which is
// always delivered.
OnCompleteFunc OnCompleteFunc
// if update type is kill, use the specified options to kill the pod.
KillPodOptions *KillPodOptions
}同时启动goroutinue用于处理managePodLoop,在managePodLoop将会依次处理channel中的podUpdate.最终将会调用kubelet中定义的func (kl *Kubelet) syncPod(o syncPodOptions).在kubelet的syncPod中实现了调用底层其他模块来完成pod状态的同步.
1.kubelet.syncPod记录podWorkerStartLatency监控指标,该指标用来统计pod被node所创建延迟的时间
2.执行kubelet中定义的podSyncHandler.ShouldEvict(),当前podSyncHandler定义有activeDeadlineHandler,该handler对应pod的spec.activeDeadlineSeconds定义进行处理,如果pod中定义该字段,则要求pod在该字段定义的时间内完成创建过程.
3.generateAPIPodStatus根据pod的信息来生成PodStatus结构体
4.kubelet.canRunPod检查是否本节点可以运行该pod,检查通过softAdmitHandler进行定义,另外对于pod是否具有allowPrivileged的权限.其中softAdmitHandler的定义在kubelet的启动流程中,分别为
lifecycle.NewPredicateAdmitHandler
lifecycle.NewAppArmorAdmitHandler
lifecycle.NewNoNewPrivsAdmitHandler
5.statusManager.SetPodStatus更新缓存pod的状态信息,触发状态更新
6.触发kl.containerManager.updateQOSCgroups()更新pod的cgroup设置.其中kl.containerManager的定义为cm.NewContainerManager()中创建的type containerManagerImpl struct实现的interface. 继续分析代码最终调用的函数是qosContainerManagerImpl.UpdateCgroups(),配置顶层的QosCgroup的相关内容.
7.调用kl.containerManager.NewPodContainerManager().EnsureExists(),配置pod的cgroup的信息. 只有在kubelet的启动参数–cgroups-per-qos为true的时候,会执行podContainerManagerImpl.EnsureExists()来创建将pod中设置对于资源的限制去对应的cgroup.详细的创建是由cgroupManager来完成.
8.创建pod所使用的podDir,podVolumesDir以及podPluginDir目录
9.volumeManager.WaitForAttachAndMount(pod) volumeManager将会把volume挂载到pod运行的宿主机上面.
10.调用kl.getPullSecretsForPod(),如果pod中定义了spec.ImagePullSecrets,则获取资源对象中定义的内容.
11.最后调用kl.containerRuntime.SyncPod(),kl.containerRuntime的定义可以参考kubelet的启动流程.如果runtime是docker,那么SyncPod()的定义为kubeGenericRuntimeManager, src/k8s.io/kubernetes/pkg/kubelet/kuberuntime/kuberuntime_manager.go:568,在该流程中分别是创建sandbox,之后创建create init/containers.
Node资源管理
Node节点运行运用的pod以及系统基础组件,这里的资源主要指的是node节点上的cpu,memory,storage. 用户的pod存在资源使用随着时间变大的情况,可能会影响到其他正常工作的pod以及node节点上的其他系统组件等,如何在该场景下提高node节点的稳定性是一个需要探索的问题.
首先,先Kubernetes中相关的概念
Cgroups
Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。
跟容器相关的功能主要涉及以下
· 限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
· 进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
· 记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间。
· 进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
Limits/request
Request: 容器使用的最小资源需求,作为容器调度时资源分配的判断依赖。只有当节点上可分配资源量>=容器资源请求数时才允许将容器调度到该节点。但Request参数不限制容器的最大可使用资源。
Limit: 容器能使用资源的资源的最大值,设置为0表示使用资源无上限。
当前可以设置的有memory/cpu, kubernetes版本增加了localStorage在1.8版本中的策略.
Pod Qos
Qos服务质量分成三个级别
BestEffort:POD中的所有容器都没有指定CPU和内存的requests和limits,默认为0,不限制资源的使用量,那么这个POD的QoS就是BestEffort级别
Burstable:POD中只要有一个容器,这个容器requests和limits的设置同其他容器设置的不一致,requests < limits, 那么这个POD的QoS就是Burstable级别
Guaranteed:POD中所有容器都必须统一设置了limits,并且设置参数都一致,如果有一个容器要设置requests,那么所有容器都要设置,并设置参数同limits一致,requests = limits. 那么这个POD的QoS就是Guaranteed级别.
Kuberntes管理的node资源中cpu为可压缩资源,当node上运行的pod cpu负载较高的时候,出现资源抢占,会根据设置的limit值来分配时间片.
Kubernetes管理的node资源memory/disk是不可压缩资源,当出现资源抢占的时候,会killer方式来释放pod所占用的内存以及disk资源.
当非可压缩资源出现不足的时候,kill掉pods的Qos优先级比较低的pods.通过OOM score来实现,Guaranteed pod,OOM_ADJ设置为-998, BestEffort 设置的OOM_ADJ为1000, Burstable级别的POD设置为2-999.
Evict策略
当系统资源不足的时候,kubelet会通过evict策略来驱逐本节点的pod来使得node节点的负载不是很高, 保证系统组件的稳定性.
当前支持的驱逐信号Eviction Signal为
memory.available
nodefs.available
nodefs.inodesFree
imagefs.available
imagefs.inodesFree
kubelet将支持软硬驱逐门槛, 操作管理员通过设置Kubelet的启动参数–eviction-soft –eviction-hard 来指定, 硬驱逐阈值没有宽限期,如果观察到,kubelet将立即采取行动来回收相关的饥饿资源。 如果满足硬驱逐阈值,那么kubelet会立即杀死pods,没有优雅的终止。软驱逐阈值将驱逐阈值与所需的管理员指定的宽限期配对。kubelet不采取任何措施来回收与驱逐信号相关的资源,直到超过宽限期。
以内存导致驱逐的场景来详细说明
让我们假设操作员使用以下命令启动kubelet:
–eviction-hard=”memory.available<100Mi”
–eviction-soft=”memory.available<300Mi”
–eviction-soft-grace-period=”memory.available=30s”
kubelet将运行一个同步循环,通过计算(capacity-workingSet)从cAdvisor报告,查看节点上的可用内存。 如果观察到可用内存降至100Mi以下,那么kubelet将立即启动驱逐。 如果观察到可用内存低于300Mi,则会在高速缓存中内部观察到该信号时记录。 如果在下一次同步时,该条件不再满足,则该信号将清除缓存。 如果该信号被视为满足长于指定时间段,则kubelet将启动驱逐以尝试回收已满足其逐出阈值的资源。
Pods的驱逐策略
如果已经达到逐出阈值,那么kubelet将启动逐出pods的过程,直到观察到信号已经低于其定义的阈值。
驱逐顺序如下:
1. 对于每个监测间隔,如果已经达到逐出阈值
2. 找候选pod
3. 失败pod
4. 阻止直到pod在节点上终止
kubelet将实施围绕pod质量服务类定义的默认驱逐策略。
它将针对相对于其调度请求的饥饿计算资源的最大消费者的pod。它按照以下顺序对服务质量等级进行排序。
- 消费最多的饥饿资源的BestEffort pods首先失败。
- 消耗最大数量的饥饿资源相对于他们对该资源的请求的Burstable pod首先被杀死。如果没有pod超出其要求,该策略将针对饥饿资源的最大消费者。
- 相对于他们的请求消费最多的饥饿资源的Guaranteed pod首先被杀死。如果没有pod超出其要求,该策略将针对饥饿资源的最大消费者。
关于imagefs/nodefs导致的资源的驱逐详细参考
https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-eviction.md#enforce-node-allocatable
实践经验
-
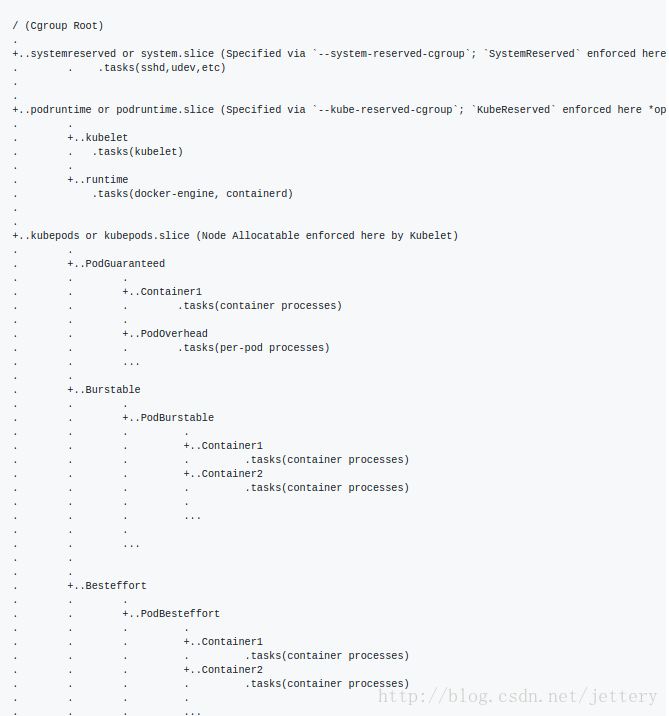
将系统资源进行划分, 预留资源
Node Capacity – 已经作为NodeStatus.Capacity提供,这是从节点实例读取的总容量,并假定为常量。
System-Reserved(提议) – 为未由Kubernetes管理的流程预留计算资源。目前,这涵盖了/系统原始容器中集中的所有进程。
Kubelet Allocatable – 计算可用于调度的资源(包括计划和非计划资源)。这个价值是这个提案的重点。请参阅下面的更多细节。
Kube-Reserved(提出) – 为诸如docker守护进程,kubelet,kube代理等的Kubernetes组件预留的计算资源。
可分配的资源数据将由Kubelet计算并报告给API服务器。它被定义为:[Allocatable] = [Node Capacity] – [Kube-Reserved] – [System-Reserved] – [Hard-Eviction-Threshold]
调度pod时,调度程序将使用Allocatable代替Capacity,Kubelet将在执行准入检查Admission checks时使用它。 -
一个kubelet从来不希望驱逐从DaemonSet导出的pod,因为pod将立即重新创建并重新安排回到同一个节点。此时,kubelet无法区分从DaemonSet创建的pod与任何其他对象。 如果/当该信息可用时,kubelet可以主动地从提供给驱逐策略的候选pod集合中过滤这些pod。一般来说,强烈建议DaemonSet不要创建BestEffort pod,以避免被识别为候选pods被驱逐。 相反,DaemonSet应该理想地包括仅Guaranteed pod。
-
静态static pod
静态POD直接由某个节点上的kubelet程序进行管理,不需要api server介入,静态POD也不需要关联任何RC,完全是由kubelet程序来监控,当kubelet发现静态POD停止掉的时候,重新启动静态POD。
EvictManager模块在系统资源紧张的时候, 根据pod的Qos以及pod使用的资源会选择本节点的pod killer,来释放资源, 但是静态pod被killer之后,并不会发生重启的现象, 设置pod的yaml中定义加入如下内容,并且kubelet的启动参数打开feature gateway(–feature-gates=ExperimentalCriticalPodAnnotation=true).annotations: scheduler.alpha.kubernetes.io/critical-pod: ''
参考
https://speakerdeck.com/luxas/kubernetes-architecture-fundamentals
https://kubernetes.io/docs