java笔记
枚举类型
枚举在定义时,所有的取值都是已知的.枚举是一种特殊的类,其每个值都有一个实例来表示.
枚举在声明时必须首先声明其所有的枚举常量.
枚举的访问修饰符要么是public,要么省略.
enum中可以定义方法.
public class Test {
Direction direction=Direction.down;
public static void main(String[] args) {
Test test=new Test();
System.out.println(test.direction);
System.out.println(test.direction.getSize());
}
}
enum Direction {
left,right,up,down;
int getSize(){
return 4;
}
}
枚举做switch-case语句的条件:
switch(direction){
case left: //不能用Direction.left
...
case right:
...
}
枚举类型可以用来在网络间传输以传递消息.
对象数组排序
根据对象的某个属性对一个对象数组排序
public class SortTest implements Comparable<SortTest>{
int fied;
@Override
public int compareTo(SortTest o) {
return this.fied-o.fied;
}
public static void main(String[] args) {
SortTest sortTest[]= new SortTest[3];
SortTest sortTest2=new SortTest();
sortTest2.fied=3;
sortTest[0]=sortTest2;
sortTest2=new SortTest();
sortTest2.fied=2;
sortTest[1]=sortTest2;
sortTest2=new SortTest();
sortTest2.fied=5;
sortTest[2]=sortTest2;
Arrays.sort(sortTest,0,3);
for(SortTest s:sortTest) {
System.out.println(s.fied);
}
}
}
实现Comparable接口,compareTo方法返回this.fied-o.fied,调用sort(Object[] a, int fromIndex, int toIndex) 方法将升序排序,如果compareTo方法返回o.fied-this.fied将降序排序.
Java内部类
成员内部类
定义在一个类的内部。
成员内部类作为外部类的成员,可以无条件访问外部类的所有成员属性和成员方法(包括private成员和静态成员)。
创建内部类对象要用外部类对象来创建。
可以直接用使用类名,不过需先import。
当然也可以用外部类.内部类的形式。
import test.OutClass.InnerClass;
public class Test {
public static void main(String[] args) {
OutClass out=new OutClass();
InnerClass in=out.new InnerClass();
OutClass.InnerClass in2=out.new InnerClass();
}
}
class OutClass{
class InnerClass{
}
}
当成员内部类拥有和外部类同名的成员变量或者方法时,会发生隐藏现象,即默认情况下访问的是成员内部类的成员。如果要访问外部类的同名成员,需要以下面的形式进行访问:
外部类.this.成员变量
外部类.this.成员方法
外部类要想访问内部类的非静态成员,要先创建内部类对象再访问。
局部内部类
局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
局部内部类只能使用方法中被标记为final或是effectively final的局部变量。也就是说对于方法的非final局部变量只能访问不能修改。
注意,局部内部类就像是方法里面的一个局部变量一样,是不能有public、protected、private以及static修饰符的。
class OutClass{
public inter func() {
int i=0;
class InnerClass implements inter{
int a=i;
}
return new InnerClass();
}
}
interface inter{
}
二维数组排序
对第一维排序:
int[][] points={{10,16}, {2,8}, {1,6}, {7,12}};
Arrays.sort(points, new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
return o1[0] - o2[0];
}
});
for (int i = 0; i < points.length; i++) {
for (int j = 0; j < points[0].length; j++) {
System.out.printf("points[%d][%d]=%d\t",i,j,points[i][j]);
}
System.out.println();
}

集合框架
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
继承关系:
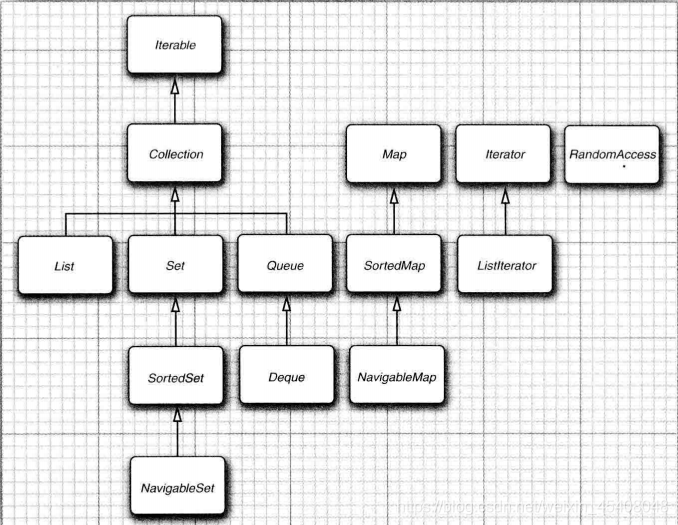
List:有序集合,元素会自动增加到容器中特定位置.java中所有链表都是双向的.
Set:无序集合,不允许重复元素.
Queue:队列.
ArrayList
一种可以动态增长和缩减的索引序列.封装了动态再分配的数组,可以较高效地对元素进行随机访问.
为了便于插入,ArrayList的listIterator()方法返回ListIterator,ListIterator继承Iterator,其中的add()方法可以添加元素,而set是无序的,所以set的Iterator不提供add()方法.多个迭代器修改list是线程不安全的,如:
ArrayList<Integer> arrayList=new ArrayList<Integer>();
arrayList.add(4);
arrayList.add(3);
arrayList.add(5);
ListIterator<Integer> iterator1=arrayList.listIterator();
ListIterator<Integer> iterator2=arrayList.listIterator();
iterator1.next();
iterator1.remove();
iterator2.next();//发生异常

iterator2能检测到链表被修改了,所以抛出异常.
ArrayList是非线程安全的,不能多线程同时修改ArrayList,Iterator也是非线程安全的,所以虽然Vector是线程安全的,如果用Iterator操作Vector也是非线程安全的.
LinkedList
链表.
为了高效,操作ArrayList可以用get,set;操作LinkedList用迭代器.
Vector
动态数组.
是线程安全的,其所有方法都是同步的,所以只有一个线程时会耗费大量资源,应当用ArrayList代替,多线程操作时才使用Vector.
Stack
栈,Vector的子类.
push():进栈
pop():出栈
peek():查看栈顶元素.
Queue
队列,是一个接口,LinkedList实现了Deque(Deque继承Queue)接口。
Queue<Integer> que=new LinkedList<Integer>();
que.offer(4);//入队,在队尾插入
que.poll();//出队,从队头出队
que.peek();//返回队头元素
Deque
插入元素
addFirst(): 向队头插入元素,如果元素为空,则发生NPE
addLast(): 向队尾插入元素,如果为空,则发生NPE
offerFirst(): 向队头插入元素,如果插入成功返回true,否则返回false
offerLast(): 向队尾插入元素,如果插入成功返回true,否则返回false
移除元素
removeFirst(): 返回并移除队头元素,如果该元素是null,则发生NoSuchElementException
removeLast(): 返回并移除队尾元素,如果该元素是null,则发生NoSuchElementException
pollFirst(): 返回并移除队头元素,如果队列无元素,则返回null
pollLast(): 返回并移除队尾元素,如果队列无元素,则返回null
获取元素
getFirst(): 获取队头元素但不移除,如果队列无元素,则发生NoSuchElementException
getLast(): 获取队尾元素但不移除,如果队列无元素,则发生NoSuchElementException
peekFirst(): 获取队头元素但不移除,如果队列无元素,则返回null
peekLast(): 获取队尾元素但不移除,如果队列无元素,则返回null
栈操作
pop(): 弹出栈中元素,也就是返回并移除队头元素,等价于removeFirst(),如果队列无元素,则发生NoSuchElementException
push(): 向栈中压入元素,也就是向队头增加元素,等价于addFirst(),如果元素为null,则发生NPE,如果栈空间受到限制,则发生IllegalStateExceptio
优先队列
java.util.PriorityQueue.
add(),offer():添加
poll():删除并返回最小值
peek():查看最小值.
java的优先队列是排好序的.
如果要用自定义类作为优先队列的元素,需实现Comparable接口.
PriorityQueue<Test> queue=new PriorityQueue<Test>();
PriorityQueue默认为最小堆,要使用最大堆使用Comparator:
PriorityQueue<Integer> maxHeap = new PriorityQueue<Integer>(11,new Comparator<Integer>(){ //大顶堆,容量11
@Override
public int compare(Integer i1,Integer i2){
return i2-i1;
}
});
散列表
在Java中,散列表用链表数组实现,用拉链法解决冲突。每个列表被称为桶( bucket)。要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。例如,如果某个对象的散列码为76268,并且有128个桶,对象应该保存在第108 号桶中( 76268除以128余108)。如果该桶中已有元素则发生冲突.
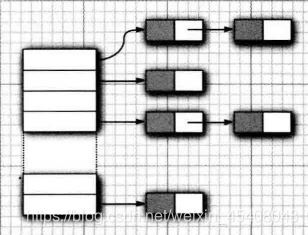
如果大致知道最终会有多少个元素要插人到散列表中,就可以设置桶数。通常,将桶数设置为预计元素个数的75% ~ 150%。 有些研究人员认为:尽管还没有确凿的证据,但最好
将桶数设置为一一个素数,以防键的集聚。标准类库使用的桶数是2的幂,默认值为16 (为表大小提供的任何值都将被自动地转换为2的下一个幂)。当然,并不是总能够知道需要存储多少个元素的,也有可能最初的估计过低。
如果散列表太满,就需要再散列(rehashed)。如果要对散列表再散列,就需要创建一个桶数更多的表,并将所有元素插入到这个新表中,然后丢弃原来的表。装填因子( load factor)决定何时对散列表进行再散列。例如,如果装填因子为0.75 (默认值),而表中超过75%的位置已经填入元素,这个表就会用双倍的桶数自动地进行再散列。对于大多数应用程序来说,装填因子为0.75是比较合理的。
散列表可以用于实现几个重要的数据结构。其中最简单的是set类型。set 是没有重复元
素的元素集合。set 的add方法首先在集中查找要添加的对象,如果不存在,就将这个对象添加进去。
Java集合类库提供了一个HashSet类,它实现了基于散列表的集。可以用add方法添加
元素,contains()判断一个元素是否在集合中。
HashMap
如果用自定义类来做key,需要重写equels()和hashCode()方法.
HashMap的数据结构为 数组+(链表或红黑树)
为什么采用这种结构来存储元素呢?
数组的特点:查询效率高,插入,删除效率低。
链表的特点:查询效率低,插入删除效率高。
在HashMap底层使用数组加(链表或红黑树)的结构完美的解决了数组和链表的问题,使得查询和插入,删除的效率都很高。
链表中元素太多的时候会影响查找效率,所以当链表的元素个数达到8的时候使用链表存储就转变成了使用红黑树存储,原因就是红黑树是平衡二叉树,在查找性能方面比链表要高.
HashMap中的两个重要的参数:HashMap中有两个重要的参数:初始容量大小和加载因子,初始容量大小是创建时给数组分配的容量大小,默认值为16,用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用rehash方法将数组容量增加到原来的两倍,专业术语叫做扩容.
在做扩容的时候会生成一个新的数组,原来的所有数据需要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能.
创建HashMap时我们可以通过合理的设置初始容量大小来达到尽量少的扩容的目的。加载因子也可以设置,但是除非特殊情况不建议设置.
遍历
HashMa<String,String> map;
//方式一
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//方式二
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//方式三,只遍历值
for (String v : map.values()) {
System.out.println("value= " + v);
}
HashSet
如果HashSet中存的是自定义类,为了保证插入的元素不同,需要重写equels()方法和hashCode()方法
HashSet是基于HashSet实现的,其包含HashMap属性,使用HashMap来保存所有元素,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成.
class Point{
int x;
int y;
public Point(int x,int y) {
this.x=x;
this.y=y;
}
@Override
public boolean equals(Object obj) {
Point point=(Point) obj;
if (x==point.x&&y==point.y) {
return true;
} else {
return false;
}
}
@Override
public int hashCode() {
return x*y;
}
public static void main(String[] args) {
Set<Point> set=new HashSet<Point>();
set.add(new Point(1, 2));
set.add(new Point(1, 2));//无法插入
System.out.println(set.size());
}
}
重写equals方法是为了能对自定义的类进行比较是否相等,为什么还要重写hashCode?因为HashSet存储时用到了hashCode,如果不重写,point1=new Point(1, 2)和point2=new Point(1, 2)后,因为是两个不同对象所以hashCode不相同,而我们认为这两个对象相等,所以重写让他们生成相同的hashCode,这样HashSet存储时就会把他们映射到相同的地址再判断他们相等后就不会再重复插入了.
TreeSet
非线程安全的二叉树排序树,插入的元素将会排好序,如果保存的是自定义类型,需要实现Comparable接口.
并发编程
线程可以调用interrupt方法请求终止进程,但线程被阻塞(如sleep)时不可终止,否则抛出java.lang.InterruptedException.
在Java程序设计语言中,每一个线程有一个优先级。默认情况下,一个线程继承它的父
线程的优先级。可以用setPriority方法提高或降低任何一个线程的优先级。可以将优先级设置为在MIN_ PRIORITY (在Thread类中定义为1)与MAX_ PRIORITY (定义为10)之间的
任何值。NORM_ _PRIORITY 被定义为5。
守护线程(daemon)
java线程分为用户线程和守护线程,守护线程是为其他线程提供服务的线程,比如jvm的GC.
只要当前JVM实例中尚存在任何一个非守护线程没有结束,守护线程就全部工作;只有当最后一个非守护线程结束时,守护线程随着JVM一同结束工作。
用户可以自己设置守护线程:
thread.setDaemon(true);
但必须要在线程start()之前调用setDaemon(),否则抛出异常.
守护线程产生的新线程也是守护线程.
守护线程应该永远不去访问固有资源,如文件、数据库,因为它会在任何时候甚至在一个操作的中间发生中断。
ThreadLocal
在Thread中有一个成员变量ThreadLocals,该变量的类型是ThreadLocalMap,也就是一个Map,它的键是threadLocal,值为就是变量的副本。通过ThreadLocal的get()方法可以获取该线程变量的本地副本,在get方法之前要先set,否则就要重写initialValue()方法。
ThreadLocal是一个线程局部变量.
threadlocal是一个线程内部的存储类,可以在指定线程内存储数据,数据存储以后,只有指定线程可以得到存储数据.
ThreadLocal提供了线程内存储变量的能力,这些变量不同之处在于每一个线程读取的变量是对应的互相独立的。通过get和set方法就可以得到当前线程对应的值。
每个线程持有一个ThreadLocalMap对象。
ThreadLocal是采用哈希表的方式来为每个线程都提供一个变量的副本,单它
采用开发地址法来解决哈希冲突.
ThreadLocal保证各个线程间数据安全,每个线程的数据不会被另外线程访问和破坏
线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收
对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式
线程池
构建一个新的线程是有一定代价的,因为涉及与操作系统的交互。如果程序中创建了大量的生命期很短的线程,应该使用
线程池
( thread pool)。一个线程池中包含许多准备运行的
空闲线程。将Runnable对象交给线程池,就会有一一个线程调用run方法。当run方法退出
时,线程不会死亡,而是在池中准备为下一个请求提供服务。
另一个使用线程池的理由是减少并发线程的数目。创建大量线程会大大降低性能甚至使虚拟机崩溃。如果有一个会创建许多线程的算法,应该使用一个线程数“固定的”线程池以限制并发线程的总数。
执行器( Executors)类有许多静态工厂方法用来构建线程池:

以上方法将返回ExecutorService对象,该对象有:
1、execute(Runnable),执行一个任务,没有返回值。
2、submit(Runnable),提交一个线程任务,有返回值。
Callable接口
继承Thread和实现Runnable在执行完任务之后无法获取执行结果。
自从Java 1.5开始,就提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果。
Future类方法:
cancel方法用来取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。参数mayInterruptIfRunning表示是否允许取消正在执行却没有执行完毕的任务,如果设置true,则表示可以取消正在执行过程中的任务。
isCancelled方法表示任务是否被取消成功
isDone方法表示任务是否已经完成
get()方法用来获取执行结果,这个方法会产生阻塞,会一直等到任务执行完毕才返回.如果任务被取消了将抛出异常.
public class CallableTest {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executor=Executors.newCachedThreadPool();
Future<Integer> result = executor.submit(new MyThread());
System.out.println(result.isDone());
System.out.println(result.get());
}
}
class MyThread implements Callable<Integer>{
@Override
public Integer call() throws Exception {
int result=0;
System.out.println("execute thread...");
return result;
}
}
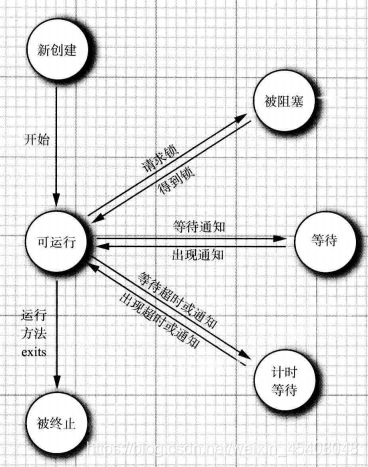
线程的状态
新建状态
当用new操作符创建-一个新线程时, 如new Thread®,该线程还没有开始运行。这意味
着它的状态是new。当-一个线程处于新创建状态时,程序还没有开始运行线程中的代码。在线程运行之前还有一些基础工作要做。
可运行
一旦调用start 方法,线程处于runnable状态。一个可运行的线程可能正在运行也叮能没
有运行,这取决于操作系统给线程提供运行的时间。(Java的规范说明没有将它作为-一个单独状态。一个正在运行中的线程仍然处于可运行状态。)
一旦一个线程开始运行,它不必始终保持运行。事实上,运行中的线程被中断,目的是
为了让其他线程获得运行机会。线程调度的细节依赖于操作系统提供的服务。抢占式调度系统给每一个可运行线程一个时间片来执行任务。当时间片用完,操作系统剥夺该线程的运行权,并给另一个线程运行机会。
被阻塞和等待
当一个线程试图获取-一个内部的对象锁( 而不是java.util.concurrent库中的锁),而该
锁被其他线程持有,则该线程进人阻塞状态。当所有其他线程释放该锁,并且线程调度器允许本线程持有它的时候,该线程将变成非阻塞状态。
当线程等待另一个线程通知调度器一个 条件时,它自己进入等待状态。我们在第。在调用Object.wait方法或Thread.join方法,或者是等待java.util.concurrent库中的Lock或Condition时,就会出现这种情况。实际上,被阻塞状态与等待状态是有很大不同的。
有几个方法有一个超时参数。调用它们导致线程进人计时等待( timed waiting) 状态。这一状态将一直保持到超时期满或者接收到适当的通知。
被终止
线程因如下两个原因之一而被终止:
●因为run方法正常退出而自然死亡。
●因为一个没有捕获的异常终止了run方法而意外死亡。
我们可以调用线程的stop方法杀死一个线程。但该方法不安全,已过时,可以调用thread.interrupt()终止线程,或thread.exit = true设置标志为结束线程.
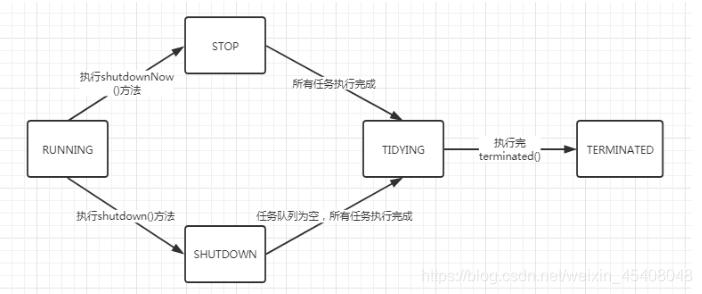
线程池的状态
-
RUNNING:线程池一旦被创建,就处于 RUNNING 状态,任务数为 0,能够接收新任务,对已排队的任务进行处理。
-
SHUTDOWN:不接收新任务,但能处理已排队的任务。调用线程池的 shutdown() 方法,线程池由 RUNNING 转变为 SHUTDOWN 状态。
-
STOP:不接收新任务,不处理已排队的任务,并且会中断正在处理的任务。调用线程池的 shutdownNow() 方法,线程池由(RUNNING 或 SHUTDOWN ) 转变为 STOP 状态。
-
TIDYING:
SHUTDOWN 状态下,任务数为 0, 其他所有任务已终止,线程池会变为 TIDYING 状态,会执行 terminated() 方法。线程池中的 terminated() 方法是空实现,可以重写该方法进行相应的处理。
线程池在 SHUTDOWN 状态,任务队列为空且执行中任务为空,线程池就会由 SHUTDOWN 转变为 TIDYING 状态。
线程池在 STOP 状态,线程池中执行中任务为空时,就会由 STOP 转变为 TIDYING 状态。
- TERMINATED:线程池彻底终止。线程池在 TIDYING 状态执行完 terminated() 方法就会由 TIDYING 转变为 TERMINATED 状态。
守护线程
:为其他线程提供服务,thread.setDaemon(true)设置为守护线程.守护线程应该永远不去访问固有资源,如文件、数据库,因为它会在任何时候甚至在一个操作的中间发生中断。
并发的临界区操作
锁对象(ReentrantLock)和synchronized关键字,Semaphore等可以解决互斥问题.
如多个线程同时操作一个数:
public class UnsynchBankTest {
public static final int NACCOUNTS=100;
public static final double INITIAL_BALANCE=1000;
public static final double MAX_AMOUNT=1000;
public static final int DELAY=10;
public static void main(String[] args) {
Bank bank=new Bank(NACCOUNTS, INITIAL_BALANCE);
for (int i = 0; i < NACCOUNTS; i++) {
int fromAccount=i;
Runnable r=()->{
try {
while(true) {
int toAccount=(int)(bank.size()*Math.random());
double amount=MAX_AMOUNT*Math.random();
bank.transfer(fromAccount, toAccount, amount);
Thread.sleep((long) ((int)DELAY*Math.random()));
}
} catch (InterruptedException e) {
// TODO: handle exception
}
};
Thread t=new Thread(r);
t.start();
}
}
}
class Bank{
private final double[] accounts;
public Bank(int n,double initialBalance) {
accounts=new double[n];
Arrays.fill(accounts, initialBalance);
}
public void transfer(int from,int to,double amount) {
if(accounts[from]<amount)
return;
System.out.println(Thread.currentThread());
accounts[from]-=amount;
System.out.printf("%10.2f from %d to %d",amount,from,to);
accounts[to]+=amount;
System.out.printf("Total Balance:%10.2f%n",getTotalBalance());
}
private double getTotalBalance() {
double sum=0;
for(double a:accounts)
sum+=a;
return sum;
}
public int size() {
return accounts.length;
}
}
输出结果:
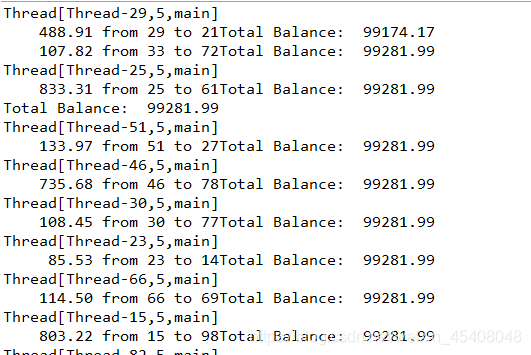
未同步时使总金额数不正确.
使用
对象锁
:
对象锁
class Bank{
private final double[] accounts;
private ReentrantLock bankLock=new ReentrantLock();
public Bank(int n,double initialBalance) {
accounts=new double[n];
Arrays.fill(accounts, initialBalance);
}
public void transfer(int from,int to,double amount) {
if(accounts[from]<amount)
return;
bankLock.lock();
System.out.println(Thread.currentThread());
accounts[from]-=amount;
System.out.printf("%10.2f from %d to %d",amount,from,to);
accounts[to]+=amount;
System.out.printf("Total Balance:%10.2f%n",getTotalBalance());
bankLock.unlock();
}
private double getTotalBalance() {
double sum=0;
for(double a:accounts)
sum+=a;
return sum;
}
public int size() {
return accounts.length;
}
}
运行结果:
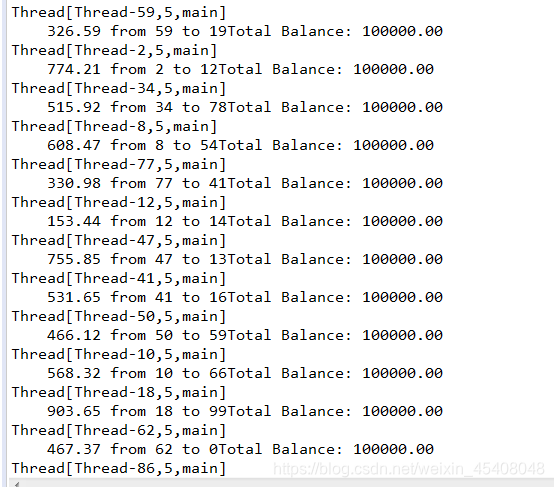
锁保证了同时只有一个线程操作数据.
lock.newCondition返回Condition对象(条件对象),为什么要条件对象?因为该线程获得锁后可能还需要满足其他条件才能继续工作(比如还要获取其他独占资源),如果一直等下去该线程又占着一个锁,所以需要条件对象来阻塞该线程并释放锁.condition.await()阻塞该线程并释放对象锁,被阻塞的线程只能被其他线程唤醒,使用condition.signalAll()企图唤醒所有线程,condition.signal()随机唤醒线程.如果所有线程都被阻塞了,就没有任何线程能用condition对象唤醒其他线程,此时产生了死锁.
- 锁用来保护代码片段,任何时刻只能有一个线程执行被保护的代码。
- 锁可以管理试图进人被保护代码段的线程。
- 锁可以拥有一个或多个相关的条件对象。
- 每个条件对象管理那些已经进人被保护的代码段但还不能运行的线程。
sychronized关键字
从1.0版开始,Java中的每一个对象都有一个内部锁。如果一个方法用synchronized关键字声明,那么对象的锁将保护整个方法。也就是说,要调用该方法,线程必须获得内部的对象锁。换句话说,
public synchronized void method(){
method body
}
等价于
public void method(){
this.intrinsiclock.lock();
try{
method body
}
finally { this.intrinsiclock.unlock(); }
}
使用wait()和notifyAll()阻塞和唤醒线程.
例如解决什么存取款问题可加synchronized:
public synchronized void transfer(int from,int to,double amount) {
...
}
synchronized不应该用在run方法上,否则失效,run方法随时可被中断.
有时使用一个对象的锁来实现额外的原子操作,实际上称为客户端锁定( clientside locking)。如:
public void transfer(int from,int to,double amount) {
synchronized(new Object()){
//临界区操作
}
}
Object的创建仅仅使对象获得锁.
对象锁和synchronized只是保证同时只有一个线程操作临界区,并不是原子操作,该线程还是可能在操作临界区时被剥夺运行权,但剥夺它运行权的线程无法操作该临界区,等线程又获取运行权后继续操作临界区.
volatile
保证了变量的可见性(visibility)、有序性。被volatile关键字修饰的变量,如果值发生了变更,其他线程立马可见,避免出现脏读的现象。但不能保证原子性操作.
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性:即程序执行的顺序按照代码的先后顺序执行,禁止指令重排。一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
指令重排对于单线程来说执行结果没什么影响,但如果是多线程可能会导致问题。
要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
使用volatile关键字会强制将修改的值立即写入主存;
使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
volatile在硬件层面保证线程间的数据一致性.
volatile实现原理:
使用volatile关键字后生成的汇编码会多出一个前缀指令lock。
lock前缀指令实际上相当于一个内存屏障(也称内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
原子操作
java.util.concurrent.atomic包中有很多类使用了很高效的机器级指令(而不是使用锁)来保证其他操作的原子性。例如,AtomicInteger 类提供了方法incrementAndGetdecrementAndGet,它们分别以原子方式将一个整数自增或自减。 这些操作可以认为不会被中断(虽然实际会被中断),原子操作可解决并发访问数据问题.
atomicInteger.compareAndSet(int expect, int update),如果atomicInteger是expect值则设置为update.
atomicInteger.get(),获取该值.
atomicInteger.updateAndGet(int x)更新并返回.
锁优化
减少加锁时间
:获取锁后的业务代码尽量不要太复杂,把一些没必要锁的代码放到锁外面.
降低锁的粒度
:比如数据库中有数据库级,表级锁,页级锁,行级锁,属性锁.
锁分离
:比如读锁和写锁分离.
锁粗化
:如果一段代码需要不停地获得和释放一个锁,那应该在对象获取锁并释放后,下一次能优先获取该锁,即为可重入锁.因为获取和释放锁需要消耗性能.
锁消除
:单线程没必要使用锁,如在单线程下使用StringBuffer时jvm将去除锁.
死锁
死锁是这样一种情形:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
java 死锁产生的四个必要条件:
1、互斥使用,即当资源被一个线程使用(占有)时,别的线程不能使用
2、不可抢占,资源请求者不能强制从资源占有者手中夺取资源,资源只能由资源占有者主动释放。
3、请求和保持,即当资源请求者在请求其他的资源的同时保持对原有资源的占有。
4、循环等待,即存在一个等待队列:P1占有P2的资源,P2占有P3的资源,P3占有P1的资源。这样就形成了一个等待环路。
当上述四个条件都成立的时候,便形成死锁。当然,死锁的情况下如果打破上述任何一个条件,便可让死锁消失。下面用java代码来模拟一下死锁的产生。
解决死锁问题的方法是:一种是用synchronized,一种是用Lock显式锁实现。
而如果不恰当的使用了锁,且出现同时要锁多个对象时,会出现死锁情况
例如:
public class DeadLockTest {
static int resource1,resource2;//独占资源
static ReentrantLock lock1=new ReentrantLock();
static ReentrantLock lock2=new ReentrantLock();
public static void main(String[] args) {
new Thread(new ThreadA()).start();
new Thread(new ThreadB()).start();
}
}
class ThreadA implements Runnable{
@Override
public void run() {
System.out.println("thread A start");
DeadLockTest.lock1.lock();
System.out.println("thread A lock 1");
DeadLockTest.resource1=1;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
DeadLockTest.lock2.lock();
System.out.println("thread A lock 2");
DeadLockTest.resource2+=DeadLockTest.resource1;
DeadLockTest.lock1.unlock();
System.out.println("thread A unlock 1");
DeadLockTest.lock2.unlock();
System.out.println("thread A unlock 2");
System.out.println("thread A finish");
}
}
class ThreadB implements Runnable{
@Override
public void run() {
System.out.println("thread B start");
DeadLockTest.lock2.lock();
System.out.println("thread B lock 2");
DeadLockTest.resource2=1;
DeadLockTest.lock1.lock();
System.out.println("thread B lock 1");
DeadLockTest.resource1+=DeadLockTest.resource2;
DeadLockTest.lock1.unlock();
System.out.println("thread B unlock 1");
DeadLockTest.lock2.unlock();
System.out.println("thread B unlock 2");
System.out.println("thread B finish");
}
}
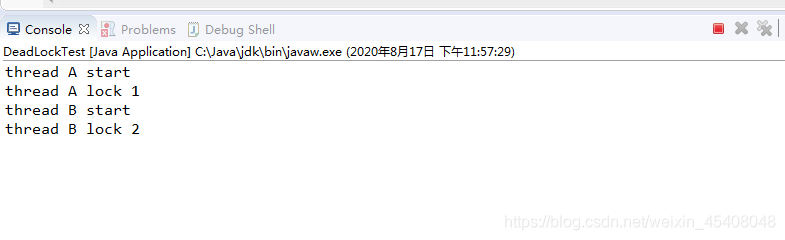
线程A锁住了1,线程B锁住了2,A等待B释放2,B等待A释放1,形成了永远等待的死锁.
解决以上问题的方法有多种,可以使用条件对象,信号量等.
使用条件对象
当没获取到其他锁时主动释放已获取的锁并等待.
使用条件对象可能又会产生死锁,当所有线程都被阻塞时就没有线程来执行condition.signal()来唤醒其他线程了,但其实死锁本身发生的概率就较小,有了condition.signal()后所有线程都被阻塞的概率就更小了.
public class DeadLockTest {
static int resource1,resource2;//独占资源
static ReentrantLock lock1=new ReentrantLock();
static ReentrantLock lock2=new ReentrantLock();
static Condition condition2=lock2.newCondition();
public static void main(String[] args) {
new Thread(new ThreadA()).start();
new Thread(new ThreadB()).start();
}
}
class ThreadA implements Runnable{
@Override
public void run() {
System.out.println("thread A start");
DeadLockTest.lock1.lock();
System.out.println("thread A lock 1");
DeadLockTest.resource1=1;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
DeadLockTest.lock2.lock();
System.out.println("thread A lock 2");
DeadLockTest.resource2+=DeadLockTest.resource1;
DeadLockTest.lock1.unlock();
System.out.println("thread A unlock 1");
DeadLockTest.condition2.signal();//唤醒阻塞的线程B,需要在2unlock之前调用,否则报错java.lang.IllegalMonitorStateException
DeadLockTest.lock2.unlock();
System.out.println("thread A unlock 2");
System.out.println("thread A finish");
}
}
class ThreadB implements Runnable{
@Override
public void run() {
System.out.println("thread B start");
DeadLockTest.lock2.lock();
System.out.println("thread B lock 2");
DeadLockTest.resource2=1;
if (DeadLockTest.lock1.isLocked()) {
try {
DeadLockTest.condition2.await();//如果获取不到1就阻塞,释放2
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
DeadLockTest.lock1.lock();
System.out.println("thread B lock 1");
DeadLockTest.resource1+=DeadLockTest.resource2;
DeadLockTest.lock1.unlock();
System.out.println("thread B unlock 1");
DeadLockTest.lock2.unlock();
System.out.println("thread B unlock 2");
System.out.println("thread B finish");
}
}
使用信号量
不使用lock,信号量可以指定去获取的超时时间,semaphore.tryAcquire(1, TimeUnit.SECONDS),如果超过一定时间还没获取到可以做一些处理:退出任务过一段时间再处理或先释放已占用的锁.
设置加锁时限
lock.tryLock(timeout, unit)可以设置加锁时限
顺序加锁
当多个线程需要相同的一些锁,但是按照不同的顺序加锁,死锁就很容易发生。如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就更不可能发生。
死锁检测
检测到死锁时回退所有相关线程,重新执行.
线程间的协作
阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。

常用的有PriorityBlockingQueue,LinkedBlockingQueue,ArrayBlockingQueue.
同步器
CyclicBarrier
允许线程集等待直至其中预定数目的线程到达一个公共障栅( barrier),然后可以选择执行一个处理障栅的动作.
cyclicBarrier.await()使该线程等待.
等待的线程达到一定数目时执行.
public class CyclicBarrierTest implements Runnable{
private CyclicBarrier barrier;
public CyclicBarrierTest(CyclicBarrier barrier) {
this.barrier=barrier;
}
public static void main(String[] args) {
CyclicBarrier barrier=new CyclicBarrier(5);
for (int i = 0; i < 5; i++) {
new Thread(new CyclicBarrierTest(barrier)).start();
}
}
@Override
public void run() {
try {
System.out.println(Thread.currentThread()+" waiting");
barrier.await();
System.out.println(Thread.currentThread()+" running");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (BrokenBarrierException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

对于一个CyclicBarrier对象barrier ,当barrier.await()调用次数达到指定数目之前将一直等待,直到barrier.await()调用次数达到后所有等待barrier对象的 线程开始执行.
CountDownLatch
一个或多个线程需要等待直到计数器为0时开始执行.
countDownLatch.countDown()计数器减一
countDownLatch.await()时线程一直等待直到计数器为0
public class CountDownLatchTest {
//建造完地板、墙、门后才能开始建造房顶
public static void main(String[] args) {
CountDownLatch finishCount=new CountDownLatch(3);
new Thread(new BuildDoor(finishCount)).start();
new Thread(new BuildFloor(finishCount)).start();
new Thread(new BuildWall(finishCount)).start();
new Thread(new BuildTop(finishCount)).start();
}
}
class BuildFloor implements Runnable{
private CountDownLatch finishCount;
public BuildFloor(CountDownLatch count) {
finishCount=count;
}
@Override
public void run() {
System.out.println("building floor....");
try {
Thread.sleep(3000);
System.out.println("floor finished");
finishCount.countDown();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
class BuildWall implements Runnable{
private CountDownLatch finishCount;
public BuildWall(CountDownLatch count) {
finishCount=count;
}
@Override
public void run() {
System.out.println("building wall....");
try {
Thread.sleep(3000);
System.out.println("wall finished");
finishCount.countDown();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
class BuildDoor implements Runnable{
private CountDownLatch finishCount;
public BuildDoor(CountDownLatch count) {
finishCount=count;
}
@Override
public void run() {
System.out.println("building door....");
try {
Thread.sleep(3000);
System.out.println("door finished");
finishCount.countDown();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
class BuildTop implements Runnable{
private CountDownLatch finishCount;
public BuildTop(CountDownLatch count) {
finishCount=count;
}
@Override
public void run() {
try {
System.out.println("waiting to build top");
finishCount.await();
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
System.out.println("building top....");
try {
Thread.sleep(3000);
System.out.println("top finished");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

Semaphore
允许线程集等待直到被允许继续运行为止,通常用来限制访问资源的线程总数。
semaphore.acquire()请求获取信号量,在获取到之前将一直等待.
semaphore.release()释放信号量.
public class SemaphoreTest {
//限制一个线程使用打印机
public static void main(String[] args) {
Semaphore semaphore=new Semaphore(1);
for (int i = 0; i < 10; i++) {
new Thread(new Print(semaphore)).start();
}
}
}
class Print implements Runnable{
private Semaphore semaphore;
public Print(Semaphore s) {
semaphore=s;
}
@Override
public void run() {
try {
semaphore.acquire();
System.out.println(Thread.currentThread()+" printing");
Thread.sleep(1500);
System.out.println(Thread.currentThread()+" finish");
semaphore.release();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
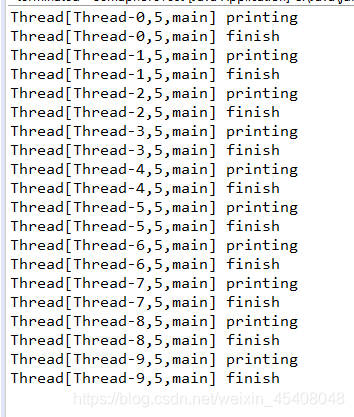
SynchronousQueue
同步队列.同步队列是一种将生产者 与消费者线程配对的机制。当一个线程调用SynchronousQueue的put方法时,它会阻塞直到另一个线程调用take方法为止。
take()将从队列中取出对象并返回,所以利用SynchronousQueue可以一个线程把对象交给另一个线程.
public class SynchronousQueueTest {
//生产面包,每生产一个要吃完后才能继续生产
public static void main(String[] args) {
SynchronousQueue<Bread> synchronousQueue=new SynchronousQueue<Bread>();
new Thread(new Produce(synchronousQueue)).start();
new Thread(new Customer(synchronousQueue)).start();
}
}
class Bread{}
class Produce implements Runnable{
private SynchronousQueue<Bread> synchronousQueue;
public Produce(SynchronousQueue<Bread> s) {
synchronousQueue=s;
}
@Override
public void run() {
// TODO Auto-generated method stub
for (int i = 1; i <= 10; i++) {
try {
Thread.sleep(500);
synchronousQueue.put(new Bread());
System.out.println("produced "+i);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
class Customer implements Runnable{
private SynchronousQueue<Bread> synchronousQueue;
public Customer(SynchronousQueue<Bread> s) {
synchronousQueue=s;
}
@Override
public void run() {
// TODO Auto-generated method stub
for (int i = 1; i <= 15; i++) {
try {
Thread.sleep(1500);
synchronousQueue.take();
System.out.println("eat "+i);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}

线程安全的数据结构
java.uilconcurrent包提供了映射、有序集和队列的高效实现: ConcurrentHashMap 、
ConcurrentSkipListMap、ConcurrentSkipListSet 和ConcurrentLinkedQueue。
HashMap是非线程安全的,高并发的put和get可能会出错,Hashtable使用synchronized来保证线程安全,但效率低下,ConcurrentHashMap高效有安全.
Hashtable的任何操作都会把整个表锁住,是阻塞的。好处是总能获取最实时的更新,比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。坏处是所有调用都要排队,效率较低。
ConcurrentHashMap 是设计为非阻塞的。在更新时会局部锁住某部分数据,但不会把整个表都锁住。同步读取操作则是完全非阻塞的。好处是在保证合理的同步前提下,效率很高。坏处是严格来说读取操作不能保证反映最近的更新。例如线程A调用putAll写入大量数据,期间线程B调用get,则只能get到目前为止已经顺利插入的部分数据。
应该根据具体的应用场景选择合适的HashMap。
CopyOnWriteArrayList和CopyOnWriteArraySet
CopyOnWriteArrayList和CopyOnWriteArraySet是线程安全的集合,其中所有的修改线
程对底层数组进行复制。写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种优化策略。其核心思想是,如果有多个调用者(Callers)同时要求相同的资源(如内存或者是磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者视图修改资源内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。
CopyOnWrite并发容器用于读多写少的并发场景。
lambda表达式
基础语法
lambda表达式可以将一个代码块传递到某个对象的方法.
lambda表达式形式:参数,箭头(->)以及一个表达式。如果代码要完成的计算无法放在一-个表达式中,就可以像写方法一样, 把这些代码放在{}中,并包含显式的return语句。例如:
(String first, String second) ->
{
if (first.1ength() < second.length() return -1;
else if (first.length() > second.length() return 1;
else return 0;
}
即使lambda表达式没有参数,仍然要提供空括号,就像无参数方法- -样:
()->{ for(int i= 100; i >= 0; i--) System.out.print1n(i); }
如果可以推导出一一个lambda表达式的参数类型,则可以忽略其类型。例如:
Comparator<String> comp
= (first, second) // Same as (String first, String second)
-> first.length() - second.length();
在这里,编译器可以推导出first和second必然是字符串,因为这个lambda表达式将赋给一个字符串比较器。
如果方法只有一个参数,而且这个参数的类型可以推导得出,那么甚至还可以省略小括号:
ActionListener listener = event ->
(System.out.println("The time is " + new Date()");
无需指定lambda表达式的返回类型。lambda表达式的返回类型总是会由上下文推导得
出。例如,下面的表达式
(String first, String second) -> first.length() - second.length()
可以在需要int类型结果的上下文中使用。
函数式接口
对于只有一个抽象方法的接口,需要这种接口的对象时,就可以提供- -个lambda表达
式。这种接口称为函数式接口(functional interface)。
所以lambda表达式还是很有局限性的,如果没有函数式接口就无法用了.
生成一个Runnable对象:
Runnable r=()->{
System.out.println("this is a thread");
};
Runnable接口只有一个run()方法.
这样就生成了一个Runnable对象,而不需写一个类实现Runnable接口再来创建对象.
方法引用
表达式System.out:println是- -一个方法引用( method reference),它等价于lambda表达式x -> System.out.println(x)。
从这些例子可以看出,要用:操作符分隔方法名与对象或类名。主要有3种情况:
●object::instanceMethod
●Class::staticMethod
●Class::instance Method
在前2种情况中,方法引用等价于提供方法参数的lambda表达式。前面已经提到,System.out:println等价于x -> System.out.println(x)。 类似地,Math::pow 等价于(x, y)->Math.pow(x, y)。
对于第3种情况,第I个参数会成为方法的目标。例如,String::compareTolgnoreCase 等同于(x, y) -> x.compare TolgnoreCase(y)。
构造器引用
构造器引用与方法引用很类似,只不过方法名为new。例如,Person:new 是Person构造
器的一个引用。哪-一个构造器呢?这取决于上下文。
JDBC
JDBC提供了一个驱动管理器,以允许第三方驱动程序可以连接到特定的数据库.
在执行SQL命令之前,首先需要创建一个Statement对象。要创建statement对象,需要使用调用DriverManager.getConnection(String url, String user, String password)方法所获得的Connection对象。
Statement stat =conn.createStatement();
PreparedStatement接口继承自Statement接口.
PreparedStatement是预编译的,使用PreparedStatement有几个好处
a. 在执行可变参数的一条SQL时,PreparedStatement比Statement的效率高,因为DBMS预编译一条SQL当然会比多次编译一条SQL的效率要高。
b. 安全性好,有效防止Sql注入等问题。
c. 对于多次重复执行的语句,使用PreparedStament效率会更高一点,并且在这种情况下也比较适合使用batch;
d. 代码的可读性和可维护性。
CallableStatement接口扩展 PreparedStatement,用来调用存储过程,它提供了对输出和输入/输出参数的支持。CallableStatement 接口还具有对 PreparedStatement 接口提供的输入参数的支持。
读写LOB
除了数字、字符串和日期之外,许多数据库都可以存储大对象,例如图片或其他数据。在SQL中,二进制大对象称为BLOB,字符型大对象称为CLOB。
要读取LOB,需要执行SELECT语句,然后在ResultSet上调用getBlob和getClob方法,这样就可以获得Blob和Clob类型的对象。要从Blob中获取二进制数据,可以调用getBytes或getInputStream。例如,如果你有一张保存图书封面图像的表,那么就可以像下面这样获取一张图像:
PreparedStatement stat = con.preparestatement("SELECT Cover FROM BookCovers WHERE ISBN=?");
stat.set(1, isbn);
Resu1tSet result = stat.executeQuery();
if (result.next()){
Blob coverB1ob =result.getB1ob(1);
}
Image coverImage= ImageIO.read(coverB1ob.getInputStream());
类似地,如果获取了C1ob对象,那么就可以通过调用getSubStr i ng或getCharacterStream来获取其中的字符数据。
要将LOB置于数据库中,需要在Connection对象上调用createB1ob或createClob,然后
获取一个用于该LOB的输出流或写出器,并将该对象存储到数据库中。例如,下面展示了如何存储-张图像:
B1ob coverB1ob = connection.createB1ob();
int offset=0;
OutputStream out = coverBlob.setBinaryStream(offset);
ImageI0.write(coverImage,“PNG", out);
PreparedStatement stat = conn.prepareStatement("INSERT INTO Cover VALUES (?, ?)");
stat.set(1, isbn);
stat. set(2, coverB1ob);
stat. executelUpdate();
反射
java.lang.reflect包中包含了反射相关的类
根据类名获取实例:
Class c = Class.forName("com.test.Test");
Test test = (Test) c.newInstance();//获取实例
一些常用方法:
public class Test {
public Test() {
}
public Test(Integer field1,Integer field2) {
this.field1=field1;
this.field2=field2;
}
public int field1=1;
private int field2=2;
public void func(Integer param) {
System.out.println("func of Test");
}
public static void main(String[] args){
Test testInstance = new Test();
Class<Test> testClass;
try {
testClass=(Class<Test>) Class.forName("test2.Test");//根据类型名获取Class
//testClass=testInstance.getClass();//根据实例获取Class
Method func = testClass.getDeclaredMethod("func", Integer.class);//获取方法
func.invoke(testInstance,0);//执行实例的方法相当于testInstance.func(0)
Field field1 = testClass.getField("field1");//获取属性,只能获取public的属性
Field field2=testClass.getDeclaredField("field2");//可以获取private
System.out.println(field1.get(testInstance));//获取实例的属性值
System.out.println(field2.get(testInstance));
System.out.println(testClass.getName());//获取类名
Class[] interfaces = testClass.getInterfaces();//获取所有接口
Constructor testConstructor=testClass.getConstructor(Integer.class,Integer.class);//获取有参构造函数
Test testInstance2 = null;
testInstance2 = (Test) testConstructor.newInstance(3,4);//调用有参构造函数
System.out.println(testInstance2.field1);
Class superClass = testClass.getSuperclass();//获取父类
}
引用对象(java.lang.ref.Reference)
强引用(StrongReference)
强引用是最传统的”引用”的定义,是指在程序代码中普遍存在的引用赋值,类似”Object obj=new Object()”这种引用关系.无论任何情况下,只要强引用关系还在,垃圾回收器就不会回收被引用的对象.
软引用(SoftReference)
用来描述一些还有用但非必须的对象.只被软引用关联的对象,在系统将要发生内存溢出前,会将这些对象列进回收范围内进行二次回收.如果此次回收后还内存不足才会抛出内存溢出异常.用SoftReference类实现.
public static void main(String[] args) {
Test test=new Test();
SoftReference<Test> testsrf = new SoftReference<Test>(test);
testsrf.get();//返回该对象的引用
}
弱引用(WeakReference)
也用来描述非必须的对象,强度比软引用弱一些.被弱引用关联的对象只能存活到下一次垃圾收集发生为止.在开始垃圾收集时,无论内存是否足够都回收弱引用的对象.用WeakReference类实现.
public static void main(String[] args) {
Test test=new Test();
WeakReference<Test> testwers=new WeakReference<Test>(test);
testwers.get();//返回该对象的引用
}
虚引用(PhantomReference)
也称为”幽灵引用”或”幻影引用”,是最弱的引用关系,一个对象是否存在虚引用不会对其生存时间有影响,无法通过虚引用获取对象实例.设置虚引用关联的唯一目的是为了能在这个对象被回收时收到系统通知.通过PhantomReference类来实现.
垃圾回收
当完成对某个对象的使用时,只需停止该对象的引用:将引用指向其他对象或null;或从方法中返回使局部变量被回收.都用到了垃圾回收机制.不再被引用的对象称为垃圾,查找并回收这些对象的过程称为垃圾回收.
垃圾对象的回收不需要我们介入,但回收垃圾会占用一定的系统资源.大量对象的创建和回收会降低效率,因此应谨慎处理对象创建的数量,减少要回收的垃圾数量.
如果内存不够我们将无法再创建对象.如果保持了大量无用对象的引用(如放到列表中),就会造成内存泄露.垃圾回收解决了很多但并非全部的内存分配问题.
垃圾回收在逻辑上可分为两个阶段:第一阶段将活对象和死对象区分开,第二阶段回收死对象的内存.
引用计数模型
:当对象X引用对象Y时,系统会增加Y的引用计数值,当X不再引用Y时,系统会递减Y的计数值,当计算值为0时即回收Y,同时递减Y引用的其他对象引用计算值.但引用计数模型不能解决循环引用问题,如果X和Y相互引用对方,那么这两个对象引用计数值永远不会为0,并且他们引用的其他对象也不能被回收.鉴于以上原因和其他原因,大多数垃圾回收器都不用此模型.
标记-清除模型
:首先找出活对象(比如列表中的对象),确定包含直接可达对象的根集合,垃圾回收器将这些对象标志为可达的,然后依次检查这些对象中的所有引用,如果这些引用所指对象已经被标为可达的,则忽略,否则就标为可达的,再继续检查其引用所指对象.这样一直进行下去,直到所有可达对象被标记.此时死对象为为标记可达的对象,再回收他们.
对于那些在标记处理开始阶段不可达的对象,如果在标记处理中间阶段将其赋值给了可达引用,那么标记处理就会漏掉这个对象,所以在运行标记-清除过程时需要冻结当前程序的运行.
标记-清除模型还存在其他问题,垃圾回收是一个复杂领域,不存在简单而通用的解决方案.
finalize()方法
类可以实现finalize()方法:
会在对象被回收之前执行.
可以在finalize()中让该对象被引用,而阻止回收.
但finalize()的调用具有不确定行,只保证方法会调用,但不保证方法里的任务会被执行完.
@Override
protected void finalize() throws Throwable {
// TODO Auto-generated method stub
super.finalize();
System.out.println("delete");
}
public static void main(String[] args) {
for(;;) {
new Test();
}
}
jvm方法调用
方法调用并不等同于方法中的代码被执行,方法调用阶段唯一的任务就是确定被调用方法的版本(即调用哪一个方法),暂时还未涉及方法内部的具体运行过程。在程序运行时,进行方法调用是最普遍、最频繁的操作之一,但 Class文件的编译过程中不包含传统程序语言编译的
连接步骤,一切方法调用在Class文件里面存储的都只是符号引用,而不是方法在实际运行时内存布局中的入口地址(也就是之前说的直接引用)。这个特性给Java带来了更强大的动态扩展能力,但也使得Java方法调用过程变得相对复杂,某些调用需要在类加载期间,甚至到运行期间才能确定目标方法的直接引用。
在Java语言中符合“编译期可知,运行期不可变”这个要求的方法,主要有静态方法和私有方法两大类,前者与类型直接关联,后者在外部不可被访问,这两种方法各自的特点决定了它们都不可能通过继承或别的方式重写出其他版本,因此它们都适合在类加载阶段进行解析。
调用不同类型的方法,字节码指令集里设计了不同的指令。在Java虚拟机支持以下5条方法调用字节码指令,分别是:
invokestatic。用于调用静态方法。
invokespecial用于调用实例构造器<init>()方法、私有方法和父类中的方法。
invokevirtual。用于调用所有的虚方法
invokeinterface。用于调用接口方法,会在运行时再确定一个实现该接口的对象。
invokedynamic。先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法。前面4条调用指令,分派逻辑都固化在Java虚拟机内部,而 invoked namic指令的分派逻辑是由用户设定的引导方法来决定的。
只要能被invokestatic和invokespecial指令调用的方法,都可以在解析阶段中确定唯一的调用版本,.Java语言里符合这个条件的方法共有静态方法、私有方法、实例构造器、父类方法4种,再加上被final修饰的方法(尽管它使用invokevirtual指令调用),这5种方法调用会在类加载的时候就可以把符号引用解析为该方法的直接引用。这些方法统称为“非虛方法”(Non-Virtual Method),与之相反,其他方法就被称为“虚方法”(Virtual Method)。
多态的实现机制
多态分为编译时多态和运行时多态.编译时多态有重载,在编译时即可确定调用哪一个方法;运行时多态要在运行时才能确定,重写就是运行时多态.
重载
:
public class StatitDispach {
public void sayHello(Human human) {
System.out.println("hello,guy");
}
public void sayHello(Man man) {
System.out.println("hello,gentleman");
}
public void sayHello(Woman woman) {
System.out.println("hello,lady");
}
public static void main(String[] args) {
Human man=new Man();
Human woman=new Woman();
StatitDispach sr=new StatitDispach();
sr.sayHello(man);
sr.sayHello(woman);
}
}
abstract class Human{
}
class Man extends Human{
}
class Woman extends Human{
}
输出结果:

编译器将根据传入参数来匹配最合适的方法来调用.
public class Overload {
public void sayHello(Object arg) {
System.out.println("hello,object");
}
public void sayHello(int arg) {
System.out.println("hello,int");
}
public void sayHello(long arg) {
System.out.println("hello,long");
}
public void sayHello(Character arg) {
System.out.println("hello,character");
}
public void sayHello(char arg) {
System.out.println("hello,char");
}
public void sayHello(char... arg) {
System.out.println("hello,char...");
}
public void sayHello(Serializable arg) {
System.out.println("hello,serializable");
}
public static void main(String[] args) {
Overload ov=new Overload();
ov.sayHello('a');
}
}
输出结果:
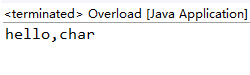
如果注释 sayHello(char arg),结果为:
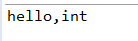
此时发生了自动类型转换,’a’代表Unicode数值.
如果继续注释sayHello(int arg),将输出:
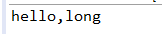
这里发生了两次类型转换,先转换为int再转换为long.如果有sayHello(short arg),将不会转为short,因为该转换是不安全的.
如果继续注释sayHello(long arg),将输出:
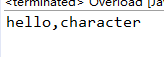
这时发生了自动装箱,将char封装为Character.
如果继续注释sayHello(Character arg),将输出:
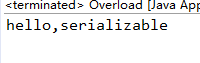
因为Character实现了Serializable接口,当装箱成Character后,未找到sayHello(Character arg),将继续自动转换为Serializable类型.
如果继续注释sayHello(Serializable arg),将输出:
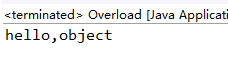
此时char装箱后转为父类了,如果有多个父类将从下往上搜索.此规则在传入参数为null时也适用.
继续注释sayHello(Object arg),结果为:
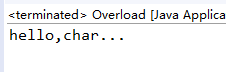
此时把’a’当成char[]数组元素.
重写
public class DynamicDispach {
public static void main(String[] args) {
Human man=new Man();
Human woman=new Woman();
man.sayHello();
woman.sayHello();
}
}
abstract class Human{
abstract void sayHello();
}
class Man extends Human{
@Override
void sayHello() {
System.out.println("man say hello");
}
}
class Woman extends Human{
@Override
void sayHello() {
System.out.println("woman say hello");
}
}
运行结果:

invokevirtual指令的运行时解析过程大致分为以下几步:
1)找到操作数栈顶的第一个元素所指向的对象的实际类型,记作C。
2)如果在类型C中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则返回这个方法的直接引用,查找过程结束;不通过则返回java lang IlegalAccessrror异常。
3)否则,按照继承关系从下往上依次对C的各个父类进行第二步的搜索和验证过程。
4)如果始终没有找到合适的方法,则抛出java lang AbstractM ethodError异常。
正是因为invokevirtual指令执行的第一步就是在运行期确定接收者的实际类型,所以两次调用中的invokevirtual指令并不是把常量池中方法的符号引用解析到直接引用上就结束了,还会根据方法接收者的实际类型来选择方法版本,这个过程就是Java语言中方法重写的本质。我们把这种在运行期根据实际类型确定方法执行版本的分派过程称为动态分派。
动态分派是执行非常频繁的动作,而且动态分派的方法版本选择过程需要运行时在接收者类型的方法元数据中搜索合适的目标方法,因此,Java虛 拟机实现基于执行性能的考虑,真正运行时一般不会如此频繁地去反复搜索类型元数据。面对这种情况,一种基础而且常见的优化手段是为类型在方法区中建立-一个虚方法表( Virtual Method Table,也称为vtable, 与此对应的,在invokeinterface执行时也会用到接口方法表一Interface Method Table,简称itable) ,使用虚方法表索引来代替元数据查找以提高性能。
虛方法表中存放着各个方法的实际入口地址。如果某个方法在子类中没有被重写,那子类的虚方法表中的地址入口和父类相同方法的地址入口是一致的,都指向父类的实现入口。如果子类中重写了这个方法,子类虛方法表中的地址也会被替换为指向子类实现版本的入口地址。
为了程序实现方便,具有相同签名的方法,在父类、子类的虛方法表中都应当具有一样的索引序号,这样当类型变换时,仅需要变更查找的虚方法表,就可以从不同的虛方法表中按索引转换出所需的入口地址。虚方法表一般在类加载的连接阶段进行初始化,准备了类的变量初始值后,虚拟机会把该类的虚方法表也一同初始化完毕。
方法
方法得到的是参数值的一个拷贝,在方法中改变参数并不会改变原值,如果传入的是一个引用并在方法中将引用指向了另一个对象,方法退出后该引用仍指向原对象.如果在方法中改变了引用指向的对象,那么方法结束后该对象也变化了,因为虽然该引用是拷贝但指向的都是同一个对象.
main方法要写在与文件同名的类中.
断言和异常
public static void main(String[] args) {
int a[]=new int[5];
int i=5;
assert i<a.length:"out of bound";
System.out.println(a[i]);
}
在命令行模式下运行Java程序时可增加参数-enableassertions或者-ea打开断言。可通过-disableassertions或者-da关闭断言.
eclipse打开断言:Run as -> Run Configurations -> Arguments -> VM arguments:敲入-ea即可。
当在代码中遇到assert时,第一个表达式将会被计算。如果返回值是true,则断言通过;如果是false,则断言失败,此时会构造一个AssertionError并抛出它。
断言的典型应用是确保在发生了“不能发生的”事情时可以引起人们的注意,这就是为什么失败的断言会抛出Error而不是Exception的原因。
异常
在Java程序设计语言中,异常对象都是派生于Throwable类的一个实例。
内置异常如果不满足要求,还可以自己创建异常类.
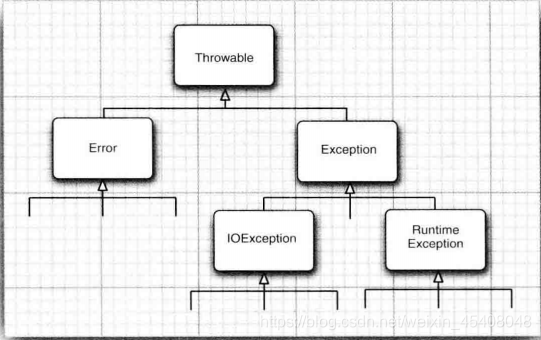
异常的继承结构:基类为 Throwable,Error 和 Exception 。实现 Throwable, RuntimeException 和 IOException 等继承 Exception
非 RuntimeException 一般是外部错误(不考虑Error的情况下),其可以在当前类被 try{}catch 语句块所捕获.
Error 类体系描述了 Java 运行系统中的内部错误以及资源耗尽的情形,Error 不需要捕捉
RuntimeException 体系包括错误的类型转换、数组越界访问和试图访问空指针等等,不要求使用 try{}catch 语句块捕获,因为比如数组越界即使捕获了也无法处理,这个要通过修改代码(不要越界访问)才能解决,没有必要捕获.导致这个异常的原因一般是程序员的疏忽.
非检查异常(编译器不要求处置的异常): 包括运行时异常(RuntimeException与其子类)和错误(Error)。
“如果出现RuntimeException异常,那么就一定是你的问题”是–条相当有道理的规则。
使用异常原则:
1.异常处理不能代替简单的测试
作为一个示例,在这里编写了一段代码,试着上百万次地对一个空栈进行退栈操作。在
实施退栈操作之前,首先要查看栈是否为空。
if (!s. empty()) s.pop();
接下来,强行进行退栈操作。然后,捕获EmptyStackException异常来告知我们不能这样做。
try{
s.pop();
}
catch (EmptyStackException e)
在测试的机器上,调用isEmpty的版本运行时间为646毫秒。捕获EmptyStackException的版本运行时间为21 739毫秒。可以看出,与执行简单的测试相比,捕获异常所花费的时间大大超过了前者,因此使用异常的基本规则是:只在异常情况下使用异常机制。
2.不要过分地细化异常
很多程序员习惯将每一条语句都分装在一个独立的try语句块中。
PrintStream out;
Stack s;
for (i =0; i < 100; i++)
{
try
{
n = s.pop();
}
catch (EmptyStackException e)
{
// stack was empty
try
{
out. writeInt(n);
}
catch (IOException e){
// problem writing to file
}
}
}
这种编程方式将导致代码量的急剧膨胀。
3.利用异常层次结构
不要只抛出RuntimeException异常。应该寻找更加适当的子类或创建自己的异常类。
不要只捕获Thowable异常,否则,会使程序代码更难读、更难维护。
4.不要压制异常
在Java中,往往强烈地倾向关闭异常。如果编写了一一个调用另一个方法的方法,而这个
方法有可能100年才抛出-一个异常, 那么,编译器会因为没有将这个异常列在throws表中产生抱怨。而没有将这个异常列在throws表中主要出于编译器将会对所有调用这个方法的方法进行异常处理的考虑。因此,应该将这个异常关闭:.
public Image loadImage(String s){
try{
// code that threatens to throw checked exceptions
}
catch (Exception e)
{} // so there
}
现在,这段代码就可以通过编译了。除非发生异常,否则它将可以正常地运行。即使发
生了异常也会被忽略。如果认为异常非常重要,就应该对它们进行处理。
5.在检测错误时,“苛刻”要比放任更好
当检测到错误的时候,有些程序员担心抛出异常。在用无效的参数调用一个方法时,返
回一个虚拟的数值,还是抛出一一个异常,哪种处理方式更好?例如,当栈空时,Stack.pop 是返回一个null,还是抛出一个异常?我们认为:在出错的地方抛出一个EmptyStackException异常要比在后面抛出一个NullPointerException异常更好。
6.不要羞于传递异常
很多程序员都感觉应该捕获抛出的全部异常。如果调用了一个抛出异常的方法,例如,
FileInputStream构造器或readLine方法,这些方法就会本能地捕获这些可能产生的异常。其实,传递异常要比捕获这些异常更好
finally
finally的语句块无论如何都会被执行,即使try或catch语句块中有return.
public class ExceptionTest {
public static void main(String[] args) {
System.out.println(test());
}
public static int test() {
int a[]=new int[2];
try {
a[10]=1;
} catch (Exception e) {
return -1;
} finally {
System.out.println("finally");
}
return 0;
}
}

可以看到,如果发生了异常,catch中又有return语句,将先执行finally语句块再执行catch中的return.
网络
Socket
public class SocketTest {
public static void main(String[] args) throws IOException {
Thread server=new Thread(new Server(),"server");
server.start();
for (int i = 0; i < 100; i++) {
Thread client=new Thread(new Client(),"client"+i);
client.start();
}
}
}
class Server implements Runnable{
@Override
public void run() {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8888);
while(true) {
Socket server = serverSocket.accept();
DataInputStream dis=new DataInputStream(server.getInputStream());
System.out.println(Thread.currentThread().getName()+":"+ dis.readUTF());
DataOutputStream dos=new DataOutputStream(server.getOutputStream());
dos.writeUTF("hello,this is server");
}
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
}
class Client implements Runnable{
@Override
public void run() {
Socket socket;
try {
socket = new Socket("127.0.0.1",8888);
DataOutputStream dos=new DataOutputStream(socket.getOutputStream());
dos.writeUTF("hello,server!");
DataInputStream dis=new DataInputStream(socket.getInputStream());
System.out.println(Thread.currentThread().getName()+":"+dis.readUTF());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
serverSocket.accept()将使线程处于阻塞状态,直到有收到客户端连接请求.
以上代码在收到一个socket连接后马上就开始处理,如果处理时间比较长就会错过别的客户端的连接请求,因为服务器端的处理时如果有别的客户端连接但此时还没有执行serverSocket.accept(),为了避免以上问题,应该写新建一个线程来专门处理与客户端的通信,主程序立马进入下一个while循环并执行accept().修改后代码:
class Server implements Runnable{
@Override
public void run() {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8888);
while(true) {
Socket server = serverSocket.accept();
new Thread(new HandleClient(server)).start();;
}
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
}
class HandleClient implements Runnable{
private Socket socket;
public HandleClient(Socket socket) {
this.socket=socket;
}
@Override
public void run() {
try {
DataInputStream dis=new DataInputStream(socket.getInputStream());
System.out.println(dis.readUTF());
DataOutputStream dos=new DataOutputStream(socket.getOutputStream());
dos.writeUTF("hello,this is server");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
URL
获取网页信息:
public static void main(String[] args) {
try {
URL url=new URL("https://www.baidu.com");
InputStream is = url.openStream();
Scanner scanner=new Scanner(is);
while (scanner.hasNext()) {
System.out.println(scanner.next());
}
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
下载网络资源:
public static void main(String[] args) {
try {
URL url=new URL("https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=2534506313,1688529724&fm=26&gp=0.jpg");
InputStream is = url.openStream();
FileOutputStream fos=new FileOutputStream("0.jpg");
byte[] bytes=new byte[1];
while (is.read(bytes)!=-1) {
fos.write(bytes);
}
fos.close();
is.close();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
图片已下载:

字符集和国际化
Unicode编码无论英文、中文还是其他字符每个都占用2字节。
假设数据库中的字符是GBK编码的,显示数据库的网页不一定要是GBK编码,因为java可以做编码格式转化,可以将GBK编码转化为utf-8格式。
java的char类型,通常以UTF-16 Big Endian的方式保存一个字符。
实现国际化应用常用的手段是利用ResourceBundle类。
分布式对象
所有分布式编程技术的基本思想都很简单:客户计算机产生一个请求,然后将这个请求通过网络发送到服务器。服务器处理这个请求,并发送回一个针对该客户端的响应,供客户端进行分析。一开始我们就必须要声明:这些请求和响应并不是在Web应用程序中看到的请求和响应。这里的客户端并非只是Web浏览器,它可以是执行具有任意复杂度的业务规则的任何应用程序。客户端应用程序可以与人类用户之间进行交互,但也可以没有这种交互。如果有这种交互,它可以拥有一个命令行或Swing用户界面。用于请求和响应数据的协议允许传递任意对象,而传统的Web应用程序只限于对请求使用HTTP协议,对响应使用HTML.
远程方法调用(RMI)
远程对象的接口必须扩展Remote接口,它位于java.rmi包中。接口中的所有方法还必须声
明抛出RemoteExcept ion异常,这是因为远程方法调用与生俱来就缺乏本地调用的可性,远程调用总是存在失败的可能。
interface ServiceOnServer extends Remote{
int add(int x,int y) throws RemoteException;
}
接下来提供服务端类:
class Server2 extends UnicastRemoteObject implements ServiceOnServer{
private static final long serialVersionUID = 1L;
protected Server2() throws RemoteException {
}
@Override
public int addService(int x, int y) throws RemoteException {
// TODO Auto-generated method stub
return x+y;
}
}
你可以看出这个类是远程方法调用的目标,因为它继承自UnicastRemoteObject,这个类
的构造器使得它的对象可供远程访问。“最小阻抗路径”是从UnicastRemote0bject中导出的.
有时候可能不希望服务器类继承UnicastRemoteObject,也许是因为实现类已经继承了其
他的类。在这种情况下,读者需要亲自初始化远程对象,并将它们传给静态的export0bject方法。如果不继承UnicastRemoteObject,可以在远程对象的构造器中像下面这样调用exportObject方法:
UnicastRemoteObject.export0bject(this, 0);
第二个参数是0,表明任意合适的端口都可用来监听客户连接。
创建远程对象并绑定:
public static void main(String[] args) throws RemoteException, NamingException, MalformedURLException, AlreadyBoundException {
ServiceOnServer serviceOnServer=new Server2();
LocateRegistry.createRegistry(8888);
Naming.bind("rmi://localhost:8888/serviceOnServer", serviceOnServer);
}
绑定后该端口将一直监听其他客户端的调用.
客户端获取该对象:
public class Client2 {
public static void main(String[] args) throws MalformedURLException, RemoteException, NotBoundException {
ServiceOnServer serviceOnServer=(ServiceOnServer) Naming.lookup("rmi://127.0.0.1:8888/serviceOnServer");
System.out.println(serviceOnServer.addService(1, 1));
}
}

常用方法
字符串转字符数组:string.toCharArray()
string.charAt(int index)取index处的字符
从字符串解析int:Integer.parseInt()
Math.random():返回大于等于0.0小于1.0的随机数
Math.round():四舍五入
Math.ceil():向上取整.
arr=Arrays.copyOf(original, int newLength):数组复制,复制指定长度.如果newLength>arr.length,arr数组的长度将被扩容为newLength.
Arrays.copyOfRange(original,int from,int to):数组复制,从…到…
Arrays.fill(arr, fromIndex, toIndex, val):数组填充.
Arrays.fill(arr, val):数组填充.
数组降序排序:Arrays.sort(Integer[] i,Collections.reverseOrder()),只能用Integer,Float等装箱类型,不能用int[].
获取对象类型:obj.getClass().
控制台读取输入:
Scanner sc=new Scanner(System.in);
while(sc.hasNext()){
sc.nextInt();//读取int
sc.next();//读取String
}
switch-case:如果case中不加break将执行后面的case代码:
switch(1){
case 1:
case 2:
case 3:
System.out.printlin("case3");
break;
case 4:
}
上面代码段将输出case3后结束switch.
List转int[]:
List<Integer> list1;
int[] arr1 = list1.stream().mapToInt(Integer::valueOf).toArray();
int[]转Integer[]:
int[] data;
Integer[] integers1 = Arrays.stream(data).boxed().toArray(Integer[]::new);
Integer[]转int[]:
Integer[] integers1;
int[] arr2 = Arrays.stream(integers1).mapToInt(Integer::valueOf).toArray();
常见问题
long和double都占64位存储空间.
java默认的整数为int,默认小数为double,小数后加f为float.
三元操作符类型的转换规则
:
1.若两个操作数不可转换,则不做转换,返回值为Object类型
2.若两个操作数是明确类型的表达式(比如变量),则按照正常的二进制数字来转换,int类型转换为long类型,long类型转换为float类型等。
3.若两个操作数中有一个是数字S,另外一个是表达式,且其类型标示为T,那么,若数字S在T的范围内,则转换为T类型;若S超出了T类型的范围,则T转换为S类型。
4.若两个操作数都是直接量数字,则返回值类型为范围较大者
如:
public static void main(String[] args) {
Object o=true?new Integer(1):new Double(1.1);
System.out.println(o);
}

将int转为范围更大的double.
对象的构造
public class Test6 {
public static void main(String[] args) {
new B();
}
}
class A{
public A() {
System.out.println("A");
}
}
class B extends A{
public B(){
System.out.println("B");
}
}
将输出A B.
构造类会先构造父类,先执行父类的构造方法再执行自己的构造方法.
如果父类只有一个有参的构造函数,子类必须用super()调用该父类构造函数.
class A{
int a;
public A(int a) {
this.a=a;
System.out.println("A");
}
}
class B extends A{
public B(){
super(0);
System.out.println("B");
}
}
==和equals的区别
==的作用:
1、基础数据类型:比较的是他们的值是否相等,比如两个int类型的变量,比较的是变量的值是否一样。
2、引用数据类型:比较的是引用的地址是否相同
equals可以重写来判断自定义类的对象是否相等,如果没有重写比较的还是引用地址是否相同.
hashCode()方法
Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值int.
两个不同的对象可能返回相同的hashCode.
final
1.修饰类
该类不能再被继承
2.修饰方法
该方法不能被覆盖
3.修饰变量
该变量需初始化或在构造器中指定值,之后不能再被改变.
如果是一个引用虽然引用值不能被修改但可以修改指向的对象.
Math.round(-1.5)
结果为-1,四舍五入的原理是在参数上加0.5然后做向下取整。Math.round(-1.6)则为-2.
java 中操作字符串都有哪些类?它们之间有什么区别?
String,String对象是不可变对象,对其进行修改会新建对象.效率较低.
StringBuffer,线程安全的,对其修改是对同一个对象修改,append方法可以添加字符串.delete方法可以删除子串.
StringBuild,非线程安全,其他和StringBuffer差不多.
String str=”i”与 String str=new String(“i”)一样吗
不一样,str=”i”将把”i”放在常量池,再把地址给str,而new String(“i”)将新建String对象,放在堆内存中,如果再来一个str2=”i”会把常量池中”i”的地址给str2,str和str2共享同一个对象.
public static void main(String[] args) {
String str1="i";//常量池中
String str2=new String("i");//堆内存中
String str3="i";
boolean b1=str1==str2?true:false;
boolean b2=str1==str3?true:false;
System.out.println("str1和str2是否同一个对象?"+b1);
System.out.println("str1和str3是否同一个对象?"+b2);
}

如何将字符串反转
使用StringBuffer或StringBuilder的reverse方法.
抽象类必须要有抽象方法吗
不一定,也可以有具体方法.
普通类和抽象类有哪些区别
普通类可以创建对象,抽象类不能
抽象类可以有抽象方法,普通类不能,抽象方法只能定义在抽象类中.
抽象类的子类必须实现抽象方法,否则该子类也是抽象类.
抽象方法不能声明为static和private,因为它最终要交给子类实现.
java 中 IO 流分为几种
按照流的流向分,可以分为输入流和输出流;
按照操作单元划分,可以划分为字节流和字符流;
按照流的角色划分为节点流和处理流。
字节流类
抽象父类: InputStream,OutputStream
实现类包括如下几种:du
BufferedInputStream 缓冲流zhidao-过虑流
BufferedOutputStream
ByteArrayInputStream 字节数组流-节点流
ByteArrayOutputStream
DataInputStream 处理JAVA标准数据流-过虑流
DataOutputStream
FileInputStream 处理文件IO流-节点流
FileOutputStream
FilterInputStream 实现过虑流-字节过虑流父类
FilterOutputStream
PipedInputStream 管道流
PipedOutputStream
PrintStream 包含print() 和 println()
RandomAccessFile 支持随机文件
字符流
抽象父类:Reader, Writer
子类:
FileReader,FileWriter
BIO、NIO、AIO 有什么区别
Java BIO : 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO : 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO(NIO.2) : 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理
阻塞和非阻塞:阻塞和非阻塞是指进程访问的数据如果尚未就绪,进程是否需要等待
同步:同时只允许一个线程访问共享资源
异步:与同步处理相对,异步处理不用阻塞当前线程来等待处理完成,而是允许后续操作,直至其它线程将处理完成,并回调通知此线程
Files类的常用方法
位于java.nio.file包.
Files.exists() 检查文件路径是否存在
Files.createFile() 创建文件
Files.createDirectory() 创建文件夹
Files.delete() 删除一个文件或者目录
Files.copy(path1,path2)复制文件
Files.move(path1,path2) 移动或修改文件
Files.size() 查看文件个数
Collection 和 Collections 有什么区别
Collection是Java提供的集合接口,存储一组不唯一,无序的对象。它有三个子接口List和Set,Queue。
Java中还有一个Collections类,专门用来操作集合类 ,它提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
如何决定使用 HashMap 还是 TreeMap
TreeMap<K,V>的Key值是要求实现java.lang.Comparable,所以迭代的时候TreeMap默认是按照Key值升序排序的;TreeMap的实现是基于红黑树结构。适用于按自然顺序或自定义顺序遍历键(key)。
HashMap<K,V>的Key值实现散列hashCode(),分布是散列的、均匀的,不支持排序;数据结构主要是桶(数组),链表或红黑树。适用于在Map中插入、删除和定位元素。
LinkedeList和ArrayList的区别
ArrayList是动态数组,LinkedList是链表
ArrayList访问效率更高,LinkedList访问效率低,LinkedList在增删效率更高.
ArrayList预留一定空间,开销更高.
如何实现数组和 List 之间的转换
数组转List:
Arrays.asList()
List转数组:
list.toArray()
ArrayList 和 Vector 的区别是什么
ArrayList线程不安全,Vector所有方法都是同步的,线程安全.
二者都有一个初始容量,常用线性连续存储空间,超过时Vector或翻倍,ArrayList会增加50%.
Array和ArrayList的区别
Array为数组.
定义一个 Array 时,必须指定数组的数据类型及数组长度,即数组中存放的元素个数固定并且类型相同。
ArrayList 是动态数组,长度动态可变,会自动扩容。不使用泛型的时候,可以添加不同类型元素。
怎么确保一个集合不能被修改
使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合,这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
多线程锁的升级原理是什么
JVM优化synchronized的运行机制,当JVM检测到不同的竞争状态时,就会根据需要自动切换到合适的锁,这种切换就是锁的升级。升级是不可逆的,也就是说只能从低到高,无锁——偏向锁——轻量级锁——重量级锁.
无锁:没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功,其他修改失败的线程会不断重试直到修改成功。
偏向锁:当一个线程访问同步块并获取锁时,会在对象头和栈帧的锁记录里存储偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需测试Mark Word里线程ID是否为当前线程。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要判断偏向锁的标识。如果标识被设置为0(表示当前是无锁状态),则使用CAS竞争锁;如果标识设置成1(表示当前是偏向锁状态),则尝试使用CAS将对象头的偏向锁指向当前线程,触发偏向锁的撤销。偏向锁只有在竞争出现才会释放锁。当其他线程尝试竞争偏向锁时,程序到达全局安全点后(没有正在执行的代码),它会查看Java对象头中记录的线程是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程,撤销偏向锁,升级为轻量级锁,如果线程1不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
偏向锁应用的场景是一个同步代码块只有一个线程频繁访问,使用偏向锁,就不需要频繁使用CAS获取锁和释放锁,只需要简单判断对象头中记录的偏向锁的线程ID是否是当期线程的就可以了,所以偏向锁在这种场景下可以大大提升效率。
轻量级锁:线程在执行同步块之前,JVM会先在当前线程的栈帧中创建用于存储锁记录的空间,并将对象头的MarkWord复制到锁记录中,即Displaced Mark Word。然后线程会尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁。如果失败,表示其他线程在竞争锁,当前线程使用自旋来获取锁。当自旋次数达到一定次数时,锁就会升级为重量级锁。
当线程存在竞争时,偏向锁的效率就会降低,因为当多条线程竞争同一个偏向锁时,会频繁产生偏向锁的撤销,所以此时应该升级为轻量级锁,轻量级锁当线程竞争锁失败时,线程不会阻塞进入自旋,继续获取锁,当竞争非常激烈时,持续自旋而获取不到锁会消耗大量CPU资源,此时就会升级为重量级锁,重量级锁当获取锁失败线程会阻塞,重量级锁的缺点是线程上下文会频繁的切换。
重量级锁:当有一个线程获取锁之后,其余所有等待获取该锁的线程都会处于阻塞状态。
重量级锁通过对象内部的监视器(monitor)实现,而其中 monitor 的本质是依赖于底层操作系统的 Mutex Lock 实现,操作系统实现线程之间的切换需要从用户态切换到内核态,切换成本非常高。