一、Druid连接池参数配置
|
配置 |
缺省值 |
说明 |
|
name |
|
配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:”DataSource-” + System.identityHashCode(this) |
|
jdbcUrl |
|
连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto |
|
username |
|
连接数据库的用户名 |
|
password |
|
连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter |
|
driverClassName |
根据url自动识别 |
这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName(建议配置下) |
|
initialSize |
0 |
初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
|
maxActive |
8 |
最大连接池数量 |
|
maxIdle |
8 |
已经不再使用,配置了也没效果 |
|
minIdle |
|
最小连接池数量 |
|
maxWait |
|
获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 |
|
poolPreparedStatements |
false |
是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
|
maxOpenPreparedStatements |
-1 |
要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
|
validationQuery |
|
用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 |
|
testOnBorrow |
true |
申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
|
testOnReturn |
false |
归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能 |
|
testWhileIdle |
false |
建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
|
timeBetweenEvictionRunsMillis |
|
有两个含义: 1) Destroy线程会检测连接的间隔时间2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
|
numTestsPerEvictionRun |
|
不再使用,一个DruidDataSource只支持一个EvictionRun |
|
minEvictableIdleTimeMillis |
|
|
|
connectionInitSqls |
|
物理连接初始化的时候执行的sql |
|
exceptionSorter |
根据dbType自动识别 |
当数据库抛出一些不可恢复的异常时,抛弃连接 |
|
filters |
|
属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall |
|
proxyFilters |
|
类型是List,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
配置文件
spring.datasource.druid.filter.stat.enabled=true
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=10
spring.datasource.druid.name=123
spring.datasource.druid.keep-alive=true
spring.datasource.druid.pool-prepared-statements=true
spring.datasource.druid.validation-query=null
spring.datasource.druid.test-on-return=true
spring.datasource.druid.time-between-eviction-runs-millis=100
spring.datasource.druid.initial-size=1
spring.datasource.druid.min-idle=1
spring.datasource.druid.max-active=20
spring.datasource.druid.test-on-borrow=true
spring.datasource.druid.testOnReturn=false
spring.datasource.druid.stat-view-servlet.allow=true
spring.datasource.druid.min-evictable-idle-time-millis=300000
二、SqlUtils解析Sql
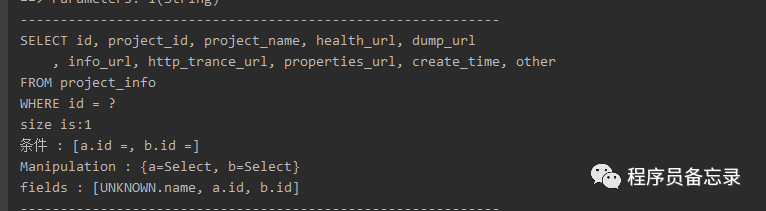
System.out.println("------------------------------------------------------------");
//格式化输出mysql
String result = SQLUtils.formatMySql(sql);
System.out.println(result); // 缺省大写格式
List<SQLStatement> stmtList = SQLUtils.parseStatements("select name from a,b where a.id=b.id order by name", dbType);
//解析出的独立语句的个数
System.out.println("size is:" + stmtList.size());
for (int i = 0; i < stmtList.size(); i++) {
SQLStatement stmt = stmtList.get(i);
MySqlSchemaStatVisitor visitor = new MySqlSchemaStatVisitor();
stmt.accept(visitor);
//获取表名称
System.out.println("条件 : " + visitor.getConditions());
//获取操作方法名称,依赖于表名称
System.out.println("Manipulation : " + visitor.getTables());
//获取字段名称
System.out.println("fields : " + visitor.getColumns());
}
System.out.println("------------------------------------------------------------");